如何评价6月9日小米MiMo-V2.5-Pro的UltraSpeed模式?1000tps是怎么实现的?
技术细节建议看小米官方的博客,讲的还是比较清楚的。主要是三点:FP4推理、新的投机解码方案以及内核Kernel优化。
Xiaomi MiMo, Explore and Love简单粗暴地理解的话,1T 参数的模型,如果要用 FP16精度,相当于需要占用 2TB 的显存,FP8 对应 1TB,FP4 则可以将显存占用压缩到 0.5TB。通过这种低精度量化的方案,可以显著降低显存占用以及带宽需求。我们都知道,大模型在 decoding 阶段是串行推理、自回归的方式,对于带宽的需求高于算力。因此,通过低精度量化就可以很大程度提高整体的吞吐量和速度。
当然,如果粗暴地进行全量低精度量化,很有可能因为精度丧失而影响性能。所以小米这次只对 MoE 的 Expert 部分进行了低精度量化,但维持了 Attention 等部分不变。通过这种方式,在有效降低显存和带宽需求的情况下,保证了模型性能不滑坡。
投机推理(MTP)其实也是现在比较常用的一种推理加速方案。通过一个小模型预测未来的 token 生成,可以减少每个 token 都需要通过全量模型生成的性能需求。
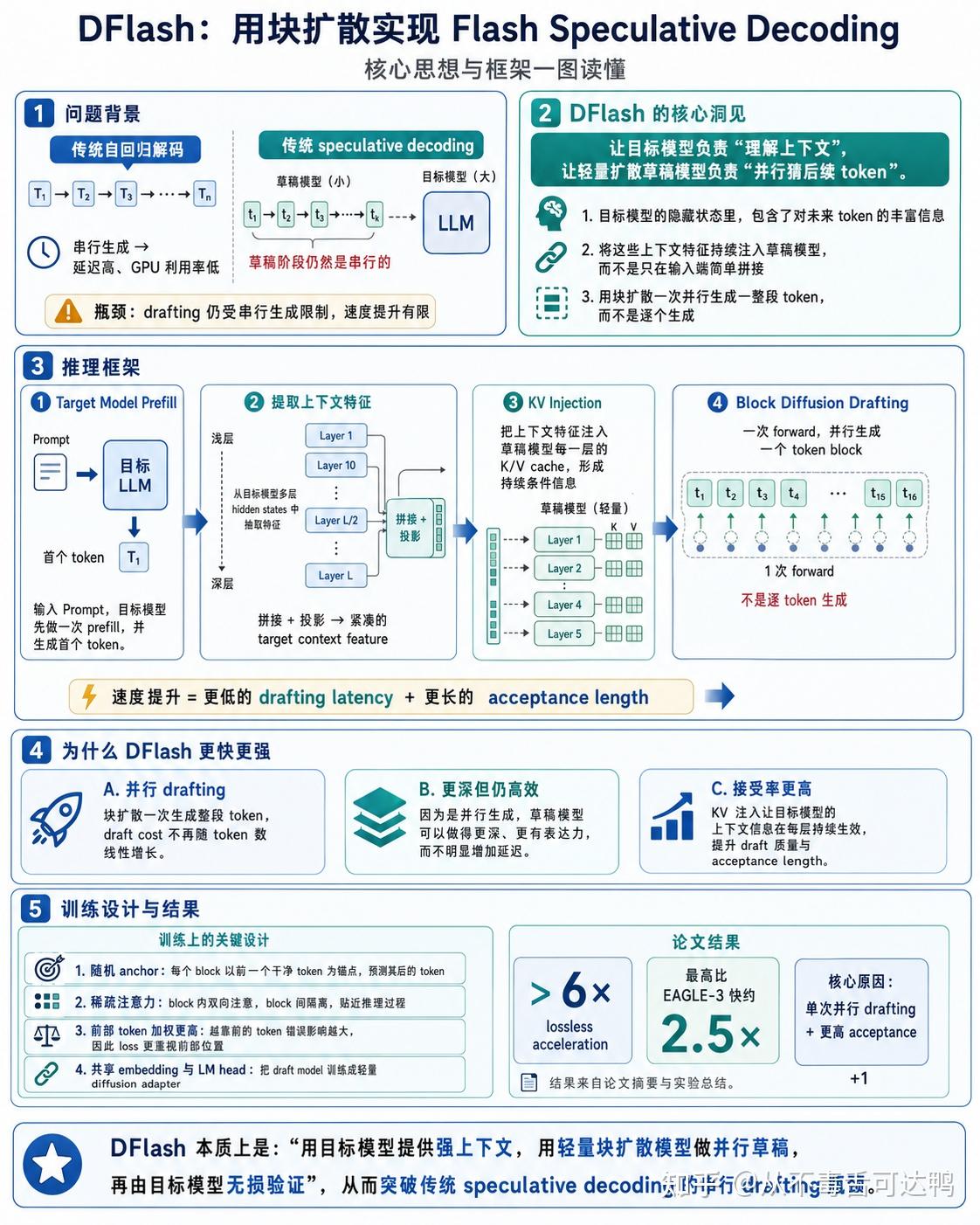
但是,现在主流的 MTP 也还是 token by token 的方式,即使做到MTP3收益也还是相对有限。这次UltraSpeed模式的投机推理用了DFlash的方法,DFlash技术细节我让GPT做了一张信息图,当然小米也针对自己的模型做了定制优化。简单来说就是基于扩散模型一次并行生成一个token block, 效率比串行MTP大大提升(Coding场景接受度能到6个token以上),也进一步加快了模型的吞吐速率。
最后是Kernel层面,进一步提升TPS意味着需要尽可能地降低任何可以压缩的开销,比如传统算子启动、硬件同步等的时间——通过跟TileRT团队的深度协同设计,对这一块的时延也做了最大化的压缩。TileRT团队的技术blog对这个话题有更详细的介绍,推荐读一读。
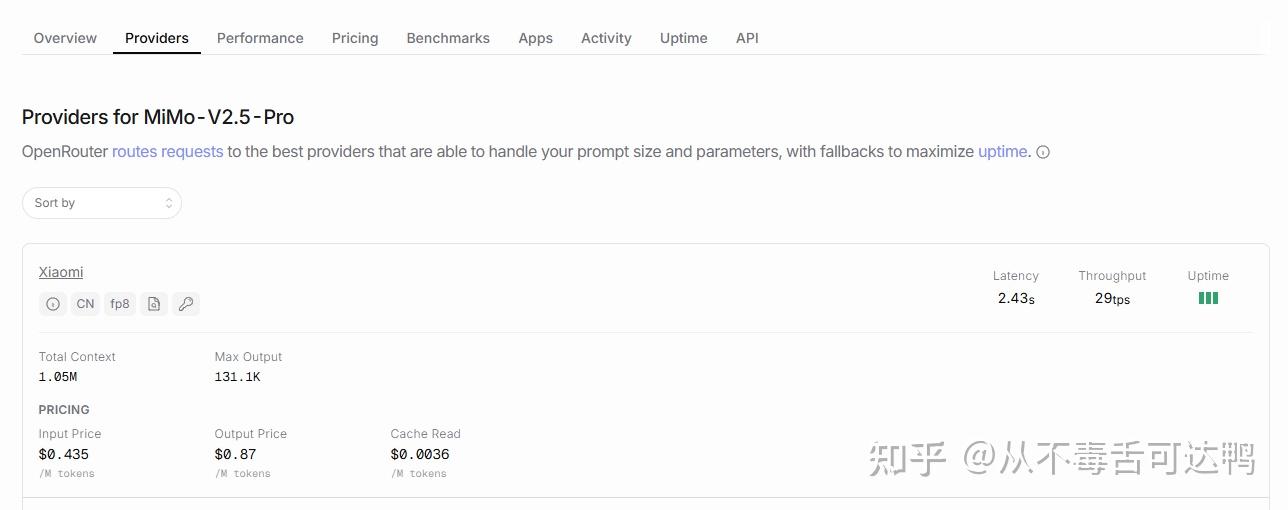
https://www.tilert.ai/blog/breaking-1000-tps.html如果你去看小米目前在 OpenRouter 上的官方 Provider 的 TPS 的话,基本上是在 30 TPS 左右。这其实也是当前 1T 左右参数的模型平均的推理速度水平。这个速度对于 Chatbot 来说其实是够了的,人再快也没法一目十行。但是对于 Coding Agent 这种场景来说就远远不够了。目前 Coding Agent 的 Token 消耗有大量是用在了工具调用、上下文阅读和推理上,30 TPS 其实会显著地降低工作效率。
这其实也就成了小米这次 UltraSpeed 模式的必要性之一。一方面,对于 Coding Agent 产品来说,极致的速度可以帮助用户进一步提高使用效率。另一方面,更低的时延(正如小米官方博客所说)能够帮助大模型在很多有 Low Latency 需求的场景中实现应用突破。更不要说,更高的 TPS 意味着模型可以同时并发多个请求,实现 Best-of-N 等不同的探索方式。这对于现在越来越成为热点话题的 AI 自迭代范式来说,也是很有帮助的。
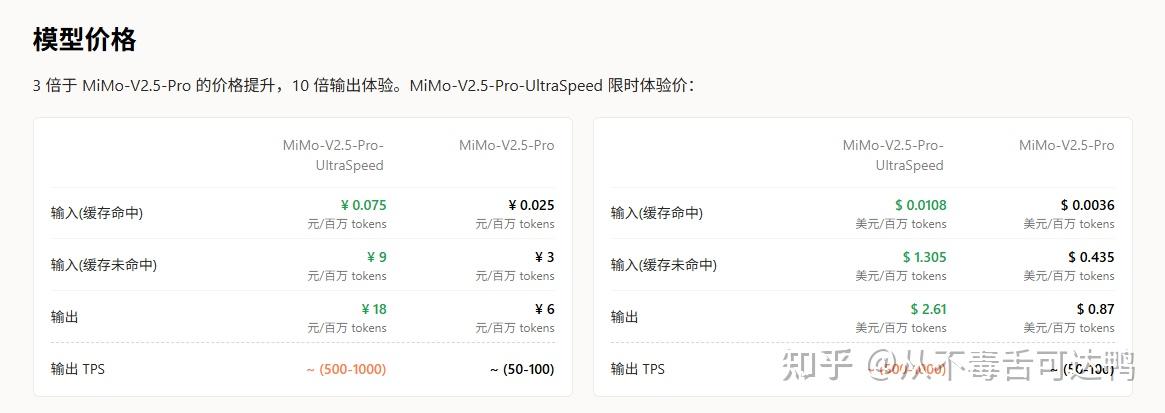
不过我个人认为,小米这里的 1000 TPS 更多是单节点单并发下的极限值。如果要在大规模集群下部署的话,根据官方在定价侧的表达,“10 倍输出体验”应该是 300 TPS 左右,也仍然是一个远超当前行业平均值的水平。
当然,更高的推理速度也意味着产品的价格相对来说要更高一些。目前看的话,3 倍的定价在 MiMo-V2.5-Pro 降价以后,仍然是非常有竞争力的。如果真的能够保证极高质量的 TPS,那么我认为这个定价也还是有它的合理性的。
毕竟最近跟很多行业内的朋友交流下来,大家对于 token 质量这个事情也开始有所评估。更好的 SLO 自然对应了更高的价格,无论在供给端还是需求端都是如此。