
苹果VisionPro R1 芯片分析报告解析
作为一位长期关注苹果芯片技术演进的硬件爱好者,最近我深入拆解分析了Apple Vision Pro中那颗神秘的R1协处理器。这颗芯片的设计思路之精巧、工艺之复杂,远超我的预期——它不是简单的“辅助芯片”,而是一次对移动SoC架构的颠覆性重构
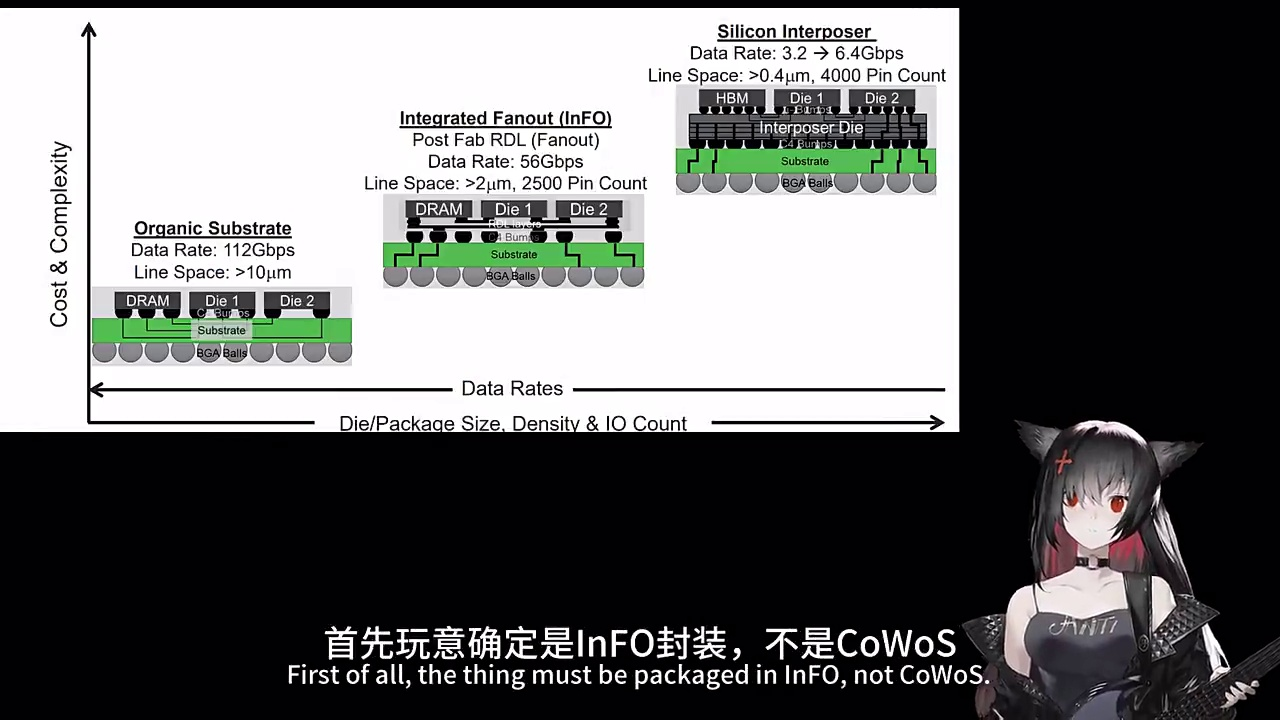
先说结论:R1是苹果首次在消费级产品中大规模采用InFO-OS(Integrated Fan-Out - Organic Substrate)封装技术的芯片,其设计时间可追溯至2020年1月之前。更关键的是,它并非为通用计算而生,而是专为实时空间感知与低延迟图像处理打造的“感官中枢”。
很多人误以为R1只是M2的简化版,但X光与金相分析揭示了截然不同的真相:R1采用11芯片集成方案,中央是主计算Die,周围环绕8颗Dummy Die(3种类型),以及2颗内存Die。其中Dummy Die总面积竟占封装的59.26%——这绝非单纯为了散热或填充。结合其长期移动、频繁碰撞的使用场景(头显需承受日常佩戴中的微小冲击),我推测这些Dummy Die承担着结构强化与应力缓冲的双重角色:硅基材料刚性高但脆性大,而Dummy Die中的硅胶填充物能有效吸收形变,提升整颗芯片在动态环境下的可靠性。

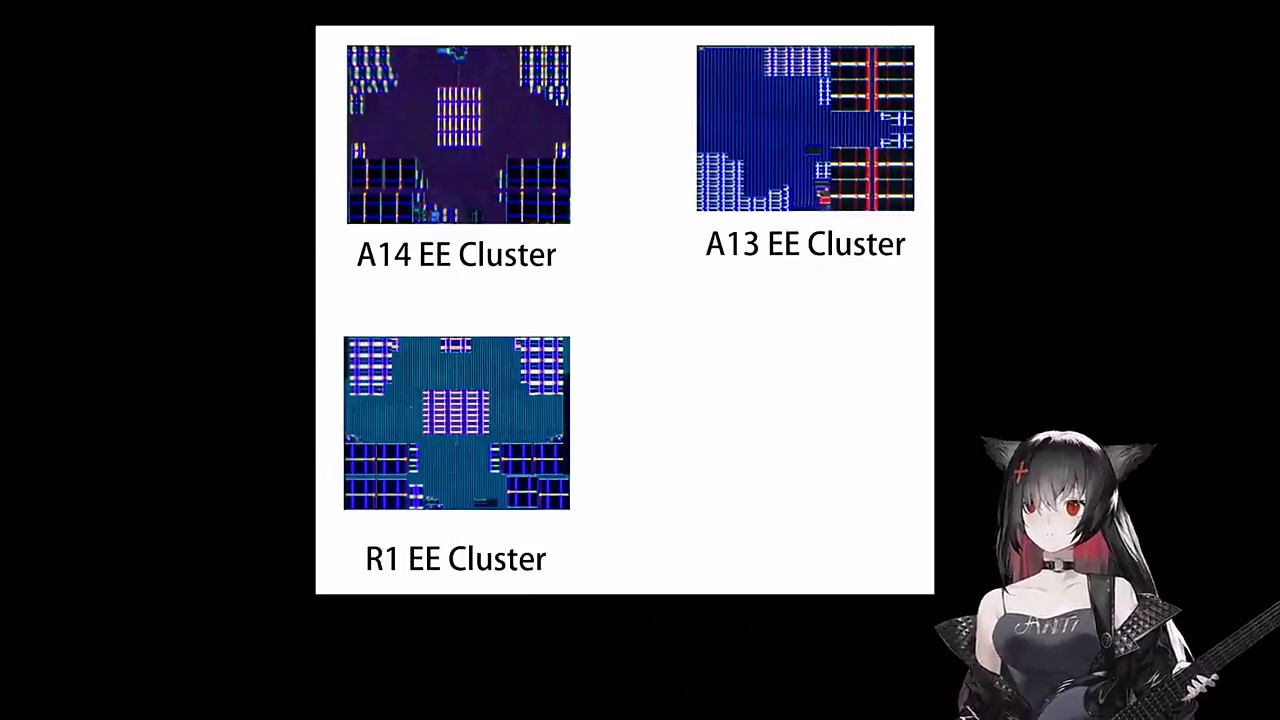
CPU部分的发现更令人意外。过去我一直以为R1的“小核心”是ISP或DSP单元,但Die Shot比对证实:它其实是两颗E Lite Core——一种比标准E Core更精简的能效核,缓存规模缩减、单元更紧凑。软件层面,R1被识别为Arm v8.4-A架构,与A14同代;硬件层面,其EE Core集群布局、L2缓存共享方式(512KB)均与A14高度一致。这意味着苹果复用了成熟IP,但做了针对性裁剪:牺牲部分通用算力,换取极致的能效比与确定性延迟——毕竟R1的任务是“永不掉帧地转发数据”,而非运行复杂应用。
最后是那个20MiB的SLC Cache。它位于芯片正中央,对称分布,明显为双目视觉计算协同优化。对比M2的缓存设计,R1的SLC在读写带宽上应与M2相当,但容量更大(M2为16MB),这直接服务于高分辨率、高帧率的空间视频流缓冲。考虑到Vision Pro每只眼睛需独立渲染4K×4K画面,如此大的片上缓存几乎是刚需。
回望整个分析过程:从X光定位、Decap去封装、金相成像到IP逆向,每一步都印证了一个事实——R1不是“妥协产物”,而是苹果为AR/VR时代量身定制的新物种。它用看似“浪费”的Dummy Die换取可靠性,用高成本InFO-OS实现超高密度互连,用定制化E Lite Core保障实时性。当行业还在争论“多芯片封装是否值得”时,苹果已用一颗330mm²的芯片,默默铺好了空间计算的底层基石。