如何评价小米6月9日发布的MiMo-V2.5-Pro-UltraSpeed模式?
小米MiMo Ultra-Speed,“秒速1000T” 大概有多快?
拿最近的高考举个例子:
想象一下,你在考场中,刚拿到卷子,卷子还没展平,旁边的哥们已经交卷拿满分走人了。
MiMo的成绩:2025年卷
语文:思考2.8秒,答题10.7秒,总计13.5秒,148/150分。(作文象征性扣了2分。)

数学:思考105秒,答题8.8秒,竞赛技巧满屏乱飞,爆杀高考,最后潇洒离场。124/124分(跳过了几道几何视图题)。

注:阅卷的是Gemini 3.1 Pro,不是我,人还能有Gemini聪明?2026卷有小米官方高考保护,所以做不了,这也挺好的,保护考生人人有责。

目前测到的速度:
自然语言:400 - 700 token/s
代码Think:600 - 700 token/s
代码Write:飙到 1000 - 1200 token/s
多轮不降速,考虑到这个模型未来的一个实战领域基本都会在泛代码领域,1000 Token/s就是一个典型速度,与小米官报是类似的。
(我在想这自然语言是不是有毒啊,笑死个人。)
 https://www.zhihu.com/video/2047704303360537846
https://www.zhihu.com/video/2047704303360537846这里有段录屏,可以看到 MiMo 实时推理的速度。
MiMo 原汤化原食。我的浏览器没有录屏插件,直接让MIMO Ultra Speed用几十秒手搓了一个录屏插件。
MiMo 在一次Response 中把所有代码按分段写完,扔给Hermes打了个包,总耗时2分钟就搞定一个插件。这才是人过的日子 —— 心一想,事就成。
继续测试,是否降智?
(这必须要实战一下)

在银行Python代码风控和流程测试中,MiMo Ultra Speed拿到了和Qwen3.7 Max,Gemini 3.1 Pro一样的分数,96分。
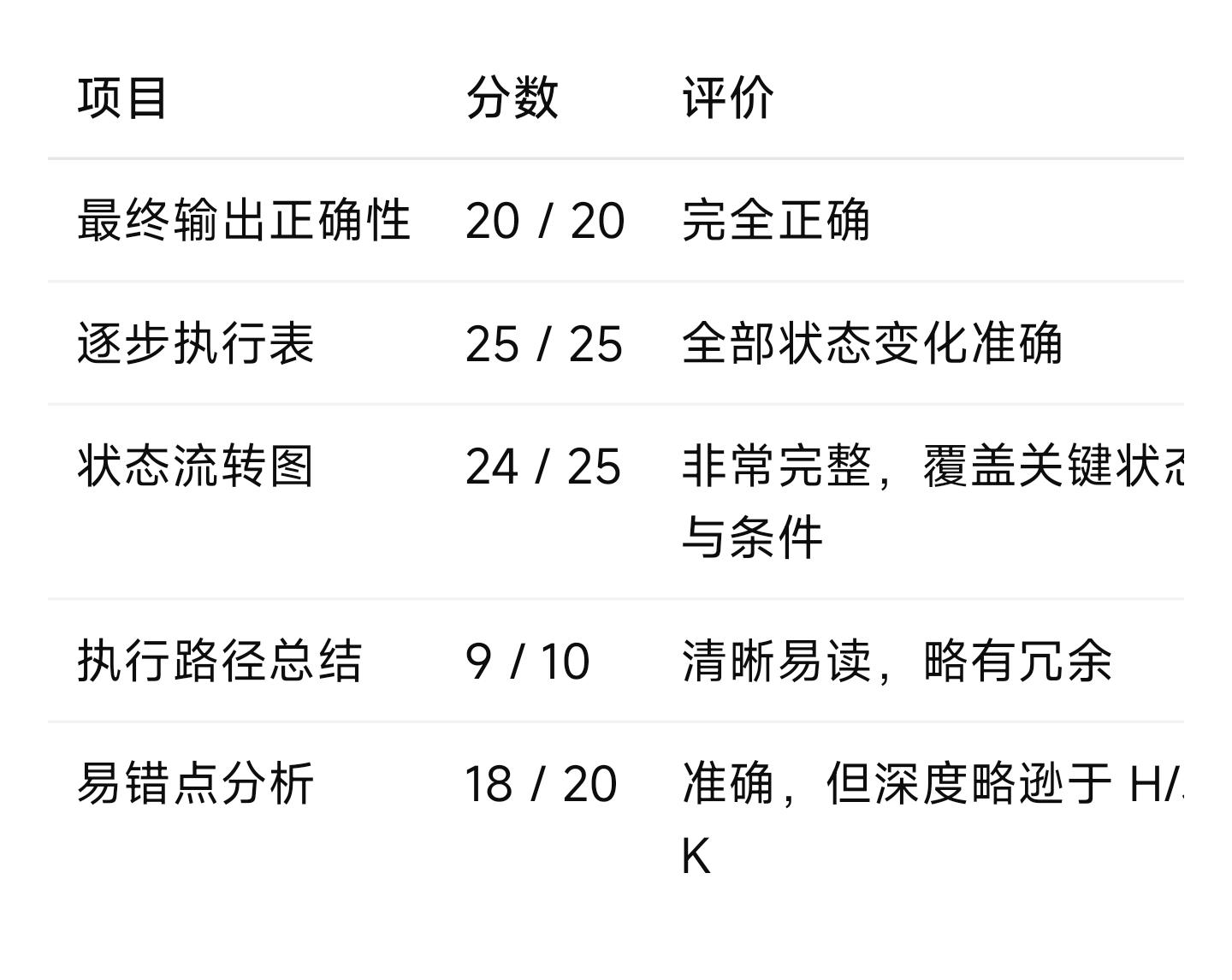
这道题Deepseek V4 pro,豆包专家版是94分。(阅卷者是GPT 5.5)
看起来,速度提上去了,的确没有降智。如果降智了,就可能就达不到90分,更达不到 95 分以上。
当然,我最喜欢的MiMo Ultra Speed的,并不仅仅是智商和速度,而是它的审美——包括2D平面设计和声效美学,这部分表现,也并没有因为速度的提升而降低。
小号模型MiMo-V2.5也有,属于MiMo的家族特性。每次提到MiMo我都会提到这件事的,纯粹是有趣的灵魂做出来的模型。
只需要告诉它,你要什么,不需要手把手指导细节,它就可以把所有元素通盘考虑,统一到一起,不产生东一块西一块的违和感。 这还要毛线个Design skills.
来听听 MiMo “秒速 1000T”做的完整音乐。我非常惊讶于它在 3 分钟的时长里,可以用纯代码手搓出一段标准音乐结构,有起势、推进、高潮、回落,而且很符合那种未来朋克的味道,多声轨有机融合。这个东西全靠模型的泛化理解能力。
 https://www.zhihu.com/video/2047710524058740477
https://www.zhihu.com/video/2047710524058740477(手机录屏时画质、音质有损失。)

这是我见过用纯代码手搓出来的、细节最“保熟”的马里奥。只有一处明显bug(而且还能正常玩,这哪儿说理去。)
小米到底是如何实现,这种“秒速1000T、同时不降智”的效果?
我的第一反应,是他们用SRAM了,因为量化肯定要降智的,会出现张冠李戴,细节错乱的问题。但SRAM这个技术,国内是没有的。这件事就非常费姐了。
从目前的技术揭秘来看,MiMo只用到了通用GPU。而他们手法,就是最擅长的——深度理解稀疏、榨干模型。
原理大概是:
① 深度理解MoE:
万亿 MoE 模型里,绝大部分体积都是只会搬运计算的 Expert 模块,真正管思考、做决策的是 Router 和注意力模块。小米只给冗余的 Expert(专家) 做 FP4 压缩,核心决策模块全程保留原精度,还搭配量化感知训练补全损耗,简单说就是只减赘肉、不伤大脑。
② DFlash 草稿机制:
改写了大模型的干活方式。传统大模型比较耿直,生成一个字,就要完整跑一次全程运算。小米直接加了个轻量级 Drafter,一次性草拟 8 个候选 token,主模型只需要一次性批量验证。 coding 场景下,8 个草稿能命中 6 到 7 个,效率直接翻倍。
③ TileRT 算子优化:
直接把算子衔接间隙压到微秒级。以前模型运算,每完成一道工序就要重启一次生产线,特别浪费时间。现在优化完直接一次开线、持续运转。
所以,秒速1000T,是精准量化、草稿推理、算子优化三件技术叠加的结果,单靠任何一项都做不到。
这对小米来说,有什么意义?
一次投入,反复受益:这次为了提速所做的大量工程改造,并不是那种“头痛医头”的临时方案,而是沉淀成了一套可以反复复用的底层能力。以后再上新模型、接入新场景,直接就能用,不用再折腾一遍。
换硬件也不怕:就算下一代换了新的通用 GPU,小米也不用从零开始重新适配、重新做优化。在现有能力的基础上做个适配升级,速度和成本的优势,照样能平滑地迁移到新平台上。
模型越多,用得越久,优势就越大:随着小米自己的模型越来越多,落地的业务场景越来越广,这套底层能力会被越来越多的产品反复调用。这么一来,成本会越摊越薄,效果会越放越大,技术优势和成本优势会形成一种“雪球效应”,越滚越强。
“秒速1000T”,的意义,不只是推理跑得快了一点,而是真正打开了大量应用场景的想象空间:
很多以前因为速度不够快、成本下不来的场景,现在头一次能被用起来了。
比如高频量化交易,金融实时反欺诈风控里毫秒级的风险评估,企业级代码助手里几十轮的实时交互一点都不卡,还有广告 RTB 竞价中 100 毫秒窗口内的全套决策……这些场景,现在都跑得通了。
我产生了一个新问题:
中国的稀疏之王,是梁文锋,还是罗福莉?
事情正在变得,越发的有趣。