
英特尔酷睿Ultra 5 245K处理器:市场定位、架构与综合效能评估
宏观计算模式的转移与底层微架构演进逻辑
在当代个人计算领域,桌面级处理器的设计哲学正经历一场深刻的革新。长期以来,集成电路行业的竞争焦点高度集中于时钟频率的绝对提升与放宽功耗墙(Power Limit)以换取单线程或多线程性能的线性增长。然而,随着硅基半导体工艺逼近物理极限,基于传统单片式(Monolithic)设计的芯片在热通量密度与良率上面临着不可逾越的瓶颈。在这一产业背景下,英特尔推出了代号为Arrow Lake-S的桌面级处理器产品线。作为该架构体系中的中流砥柱,Intel Core Ultra 5 245K不仅是一次简单的迭代,更代表了芯片设计理念向模块化、高能效与内建人工智能加速方向的全面重构。
通过引入台积电(TSMC)N3B先进制程节点进行计算模块的代工,并结合Foveros 3D先进封装技术,Ultra 5 245K实现了计算模块(Compute Tile)、图形模块(Graphics Tile,尽管KF版本将其物理屏蔽或未激活)、系统级芯片模块(SoC Tile)以及I/O模块的解耦与重组。这种设计从根本上改变了数据在硅片内部的传输拓扑。更为激进的是,该处理器在微架构层面彻底移除了历史上长期存在并被广泛依赖的同步多线程(SMT/Hyper-Threading)技术。工程决策层面的考量在于,通过大幅度增加Skymont能效核(E-Core)的物理数量与执行宽度,以及强化Lion Cove性能核(P-Core)的每时钟周期指令数(IPC),处理器能够在不引入逻辑线程调度开销与额外热密度的前提下,实现纯物理核心级别的并行计算。这一架构演进为随后探讨的多核生产力、能效表现以及小型化主机兼容性奠定了最核心的物理基础。
全球存储芯片周期与平台构建的成本效益评估
在评估计算平台的总体拥有成本(Total Cost of Ownership, TCO)时,核心处理器的价格往往仅占整体系统预算的一部分,内存、主板芯片组以及相关外围设备的市场波动同样起着决定性作用。自2023年末起,全球DRAM半导体供应链曾试图通过人为削减产能来结束长达数个季度的价格下行周期,并试图拉升新一代DDR5内存的现货与合约价格。然而,受制于宏观经济环境下终端消费电子市场复苏的迟缓,以及人工智能服务器对HBM(高带宽内存)产能的虹吸效应,普通桌面级DDR5内存市场迎来了意料之外的“暂缓涨价”乃至局部价格回调的平稳窗口期。
这种阶段性的存储市场供需博弈,为计划构建基于Ultra 5 245K(该系列全面摒弃了对DDR4的向后兼容,仅支持DDR5内存)平台的消费者释放了显著的预算红利。在主流6000MT/s至6400MT/s频率区间的DDR5双通道套装采购中,消费者能够以极具竞争力的价格获得大容量高频内存。这种预算的结余不仅降低了平台的准入门槛,更使得系统装配者能够将节省下来的资金重新分配至更高阶的主板、大容量NVMe固态硬盘或更高效的散热模组中,从而在系统层面实现资源的优化配置。
与此同时,Ultra 5 245K在价格策略上的下沉展现出了极强的市场穿透力。尽管其在海外市场的官方建议零售价(MSRP)定为209美元,但在特定区域市场(如中国大陆),结合电商大促节点、主板搭售套装以及渠道分销体系的让利,该处理器在实际成交端有望下探至1000元人民币左右的甜点价位段。在千元级市场提供拥有14个纯物理核心与14线程(14C14T,具体配置为6个性能核与8个能效核)的计算单元,这在X86桌面发展史上具有里程碑式的意义。这种定价策略不仅彻底重塑了主流价位段的性价比基准,更为预算有限的内容创作者、独立开发者以及硬核游戏玩家提供了一套无与伦比的多核生产力引擎。在这个价位段,传统的竞争对手往往只能提供6核或8核的配置,而14个物理核心在处理并行编译、多轨视频渲染以及复杂虚拟机环境时,展现出了明显的降维打击态势。
平台I/O拓扑与高速扩展性的深层剖析
现代计算任务对数据吞吐量和传输延迟的要求正呈指数级增长。无论是高达数TB的8K分辨率无损视频素材,还是采用了DirectStorage技术以实现材质无缝加载的次世代3A游戏,都对主板平台的底层I/O总线架构提出了严苛的考验。Ultra 5 245K所搭配的新一代LGA1851接口以及配套的800系列(如Z890、B860)芯片组,在周边组件互联组件(PCI Express)通道的分配上,实现了桌面级平台的跨越式升级。

处理器直连的PCIe通道不仅在数量上极为宽裕,在规格上也全面迈入PCIe 5.0时代。系统不仅能够为未来的旗舰级独立显卡提供完整的16条PCIe 5.0通道(达到单向64GB/s的恐怖带宽),还能够同时独立分离出4条PCIe 5.0通道专供主系统盘(NVMe M.2固态硬盘)使用。这种通道设计的先进性在于,即使在极高负载下,显卡与存储设备之间也不会发生带宽争抢或通道拆分降速的情况。此外,通过主板南桥芯片组的高速DMI总线扩展,系统还可额外挂载多块PCIe 4.0 NVMe硬盘。这种极其强悍的多硬盘扩展能力,使得平台能够轻易组建本地高速数据阵列(RAID),彻底消除了影视后期工作者和3D建模师在存储海量数字资产时面临的I/O瓶颈。
在外部接口协议层面,该平台原生集成了对雷电4(Thunderbolt 4)以及USB4标准的支持。雷电4接口以其高达40Gbps的双向对称带宽和极低的底层延迟,重塑了桌面外设的连接生态。对于生产力用户而言,这不仅意味着可以通过单一线缆同时驱动两台4K分辨率或一台8K分辨率的专业色彩显示器,还能够外接极其高速的直接附加存储(DAS)阵列。视频剪辑师可以直接在外置硬盘上实时拖拽并剪辑未经压缩的ProRes或RAW格式原始素材,而无需经历漫长的本地硬盘拷贝过程。在扩展性维度上,雷电4甚至为未来接入外置图形处理单元(eGPU)或专用的外置AI加速卡保留了充足的带宽冗余,极大地延长了基于Ultra 5 245K构建的系统生命周期。
电气性能重构与Intel UES小尺寸主机生态构建
在探究桌面级处理器的发展轨迹时,性能与功耗往往呈现出不可调和的正相关性。然而,Ultra 5 245K在电气特性上的调优,标志着高能效设计在桌面平台上的全面落地。这不仅是对电能转换效率的提升,更是推动现代桌面计算形态变革的底层引擎。
根据CMOS集成电路的动态功耗模型:
(其中α为翻转率,C为等效电容,V为工作电压,f为工作频率),制程工艺的进步与架构的改良能够显著降低工作电压与寄生电容。得益于先进制程的红利,Ultra 5 245K的基础热设计功耗(TDP,或称PL1)被稳稳压制在125W的基准线,而其最大睿频功耗(Maximum Turbo Power,或称PL2)则被严格限制在159W。与上一代动辄突破200W大关的同级别处理器相比,这种功耗的收敛具有极其重要的工程意义。这意味着用户在装机时,不再被迫采购体积庞大的双塔式风冷或昂贵且占据巨大空间的360mm/420mm一体式水冷散热器,中等规模的下压式风冷或紧凑的240mm一体式水冷即可确保处理器在持续满载运行中不发生热节流(Thermal Throttling)。
表1:典型高功耗系统与Intel UES系统在物理形态与能效特征上的对比
| 系统特性指标 | 传统高性能ATX塔式主机 | 基于245K的Intel UES主机 |
| 处理器峰值功耗 (PL2) | 普遍 > 200W | 159W (Ultra 5 245K) |
| 散热模组需求 | 360mm水冷 / 旗舰双塔风冷 | 240mm水冷 / 高性能下压式风冷 |
| 桌面投影面积 | 通常 > 0.15 ㎡ | < 0.06 ㎡ |
| 主板与电源规格 | ATX主板 / ATX电源 | ITX主板 / SFX电源 |
| 环境噪音水平 | 高负载时风扇噪音显著 | 极低(低发热带来低转速) |
| 空间整合度 | 突兀,占据大量视觉焦点 | 隐形,与现代家居/办公无缝融合 |
正是基于上述功耗与发热量的突破,英特尔创造性地提出了Intel UES(Ultra Elegant System)主机的概念定位。UES概念旨在打造极其优雅的高性能桌面计算平台,其核心工程挑战在于:如何在绝对保障散热效率与系统稳定性的前提下,实现主机物理形态的极致紧凑化。在这一框架下,行业引入了“桌面得房率”这一新颖的评估指标。该指标要求将主机的桌面投影面积严格控制在0.06平方米以内(大约等同于一张标准A4纸的面积或一个常规鞋盒的占地空间)。
通过将主机的三维体积浓缩至10升甚至更小,UES系统在最小化物理空间占用的同时,最大化了硬件配置密度与性能释放的比例。这种设计不仅彻底解决了传统“光污染”塔式机箱在桌面上显得笨重且突兀的痛点,更完美契合了当代城市居住环境与高端办公场所对空间美学的苛刻追求。对于居住在一线城市公寓的数字游民、创意工作者以及追求生活品质的极客而言,宝贵的桌面空间应当留给多屏幕矩阵、专业音频监听设备或各类灵感物件,而不是被一台庞大的铁箱子所吞噬。
UES主机生态的繁荣,进一步催生了被称为“早A晚G”(即“白天AI与办公,晚上Gaming电竞”)的全新全天候数字生活方式。这种模式深刻定义了现代PC的双重社会属性。“早A”(Art/Agility/Architecture/AI Productivity)描绘了在白天的专业工作时段,系统凭借极其安静的运行状态与Ultra 5 245K的14核算力,高效执行代码编译、复杂数据表单处理或是基于内建NPU的本地端侧AI推理任务。UES主机此时扮演的是一个低调、专注且隐形的生产力中枢。而到了“晚G”( Gaming)的下班后时段,这套看似温和的迷你系统能够瞬间解开束缚,通过多条直连的PCIe高速通道调用内置的独立显卡,为《三角洲行动》等高负载游戏提供源源不断的算力支持,化身为极具爆发力的电竞利器。这种兼具空间环境友好性与极致性能表现力的无缝切换,确立了搭载Ultra 5 245K的PC作为现代家庭与办公双核心组件的不可替代性。
端侧AI计算的崛起与樱桃助手(Cherry AI)深度解析
随着人工智能技术从云端大规模训练向边缘设备推理应用转移,X86桌面计算平台迎来了底层架构的又一次重要扩充。Ultra 5 245K作为首批将独立的人工智能矩阵运算加速器——神经网络处理单元(NPU)引入主流桌面端的核心处理器,标志着PC产业正式跨入端侧AI(Edge AI)时代。该处理器集成的NPU版本迭代至NPU3,其硬件逻辑专为深度学习中高频出现的张量(Tensor)运算和乘加(MAC)指令进行了深度定制。

传统的中央处理器(CPU)擅长处理复杂的逻辑控制与分支预测,图形处理器(GPU)则在海量并行浮点运算与图形渲染上具有绝对统治力。然而,NPU的引入使得系统能够以极低的功耗持续运行复杂的神经网络推理模型。将后台长驻的AI服务从CPU与GPU中卸载(Offload)至NPU,不仅大幅降低了整机功耗,避免了因为抢占系统资源而导致的前台应用卡顿,还为构建全天候响应的本地化AI交互引擎提供了硬件基础。
为了将这一硬件潜能具象化为用户可感知的价值,英特尔官方推出了革命性的本地AI语音交互工具——樱桃助手(Cherry Assistant,官方域名为http://cherry.pcelves.com)。该助手以“越用越好用的酷睿Ultra”作为其核心产品Slogan,旨在通过深度学习与用户习惯的融合,使PC成为一个能够伴随用户共同成长、持续进化的智慧体 2。其背后的宏大愿景被进一步提炼为“樱桃智控 随声启境”,意在通过“感知-决策-执行”的完整闭环,彻底重构未来的人机交互模式。
要释放樱桃助手的全部潜能,系统环境需要满足一系列严格的软硬件基准。基于前沿技术规范,该软件的AI推理引擎要求操作系统环境必须为Windows 11,且对于集成了NPU的处理器,其底层的NPU驱动程序必须更新至32.0.100.4297或更高的特定版本。此外,为了容纳复杂的本地大语言模型与多模态交互数据,系统需至少配备16GB的物理内存,并在磁盘中预留不低于20GB的存储空间。在这些硬件条件支撑下,结合英特尔针对端侧模型进行的先进量化(Quantization)与微调(Micro-tuning)技术,樱桃助手能够实现毫秒级的推理响应。更为关键的是,所有的感知与决策运算均在本地硬件闭环内完成,彻底断绝了敏感音频与个人操作数据向云端泄露的风险,在确保极致安全隐私的同时,也打破了对网络连接的依赖。
樱桃助手的核心竞争力在于其对系统底层的深度接管能力,绝非市面上简单的语音转文本外挂工具可比。它的应用场景全面覆盖了用户的日常生态: 在生产力维度,当用户口述“打开昨天的Excel预算表”或“开始屏幕录制”时,樱桃助手能够绕过繁琐的文件资源管理器路径,直接执行深度的系统级文件调用与程序启停操作,甚至能够模拟复杂的鼠标点击轨迹以完成一系列自动化宏操作。 在泛娱乐与创作维度,助手与国内主流PC应用市场实现了底层生态打通。用户能够通过多模态唤醒(包括语音指令、预设快捷键或鼠标悬停动作),直接调取必应(Bing)搜索引擎查找资料、在酷狗音乐中点播指定曲目,或者直接拉起Bilibili客户端播放视频。 在电竞游戏场景中,助手的价值得到了更淋漓尽致的体现。以热门射击游戏《三角洲行动》(Delta Force)为例,玩家可以在不切出全屏游戏画面、不中断激烈交火的前提下,直接通过语音唤醒樱桃助手,不仅可以实现游戏的快速启动,更能实时查询当前处理器的运行频率、核心温度阈值以及网络连接的底层延迟状态。这种伴随式的AI助理服务,不仅极大丰富了玩家的掌控感,也印证了“越用越好用”的智能化设计初衷。
生产力维度的架构博弈:Ultra 5 245K对比Ryzen 5 9600X
在主流桌面级处理器的市场角逐中,Ultra 5 245K面临的最直接且强劲的竞争对手,是基于AMD Zen 5架构的Ryzen 5 9600X。对两款处理器在不同负载环境下的横向对比与归因分析,是评估其购买价值的核心环节。在纯粹的生产力效能与多线程并发任务测试中,Ultra 5 245K凭借其微架构层面的非对称物理核心优势,展现出了压倒性的统治力。
AMD Ryzen 5 9600X采用的是经典的单片CCX(Core Complex)设计理念,提供6个物理核心与12个逻辑线程(6C12T),其基础热设计功耗标称为极为节能的65W 。而在另一侧,Ultra 5 245K(包含不包含核显的KF变体版本)则搭载了由6个性能核与8个能效核组成的14核心14线程(14C14T)庞大算力矩阵。物理核心数量上的巨大鸿沟,在极度依赖并发吞吐量的现代生产力应用中得到了直观反映。
表2:核心计算规格与基准测试参考对比
| 参数与性能维标 | Intel Core Ultra 5 245K/KF | AMD Ryzen 5 9600X |
| 核心与线程拓扑 | 14核心 (6P + 8E) / 14线程 | 6核心 / 12线程 |
| 基础与加速频率 | 4.2 GHz / 5.2 GHz | 3.9 GHz / 5.4 GHz |
| 三级缓存 (L3 Cache) | 36 MB | 32 MB |
| 热设计功耗评估 | 125W (基准) / 测试峰值 ~205W | 65W (基准) /测试峰值 ~180W |
| Cinebench 2024 (多核) | 1530(超越AMD 8核产品) | 942 (存在较大差距) |
| 价格) | 约1100元 | 约1200元 |
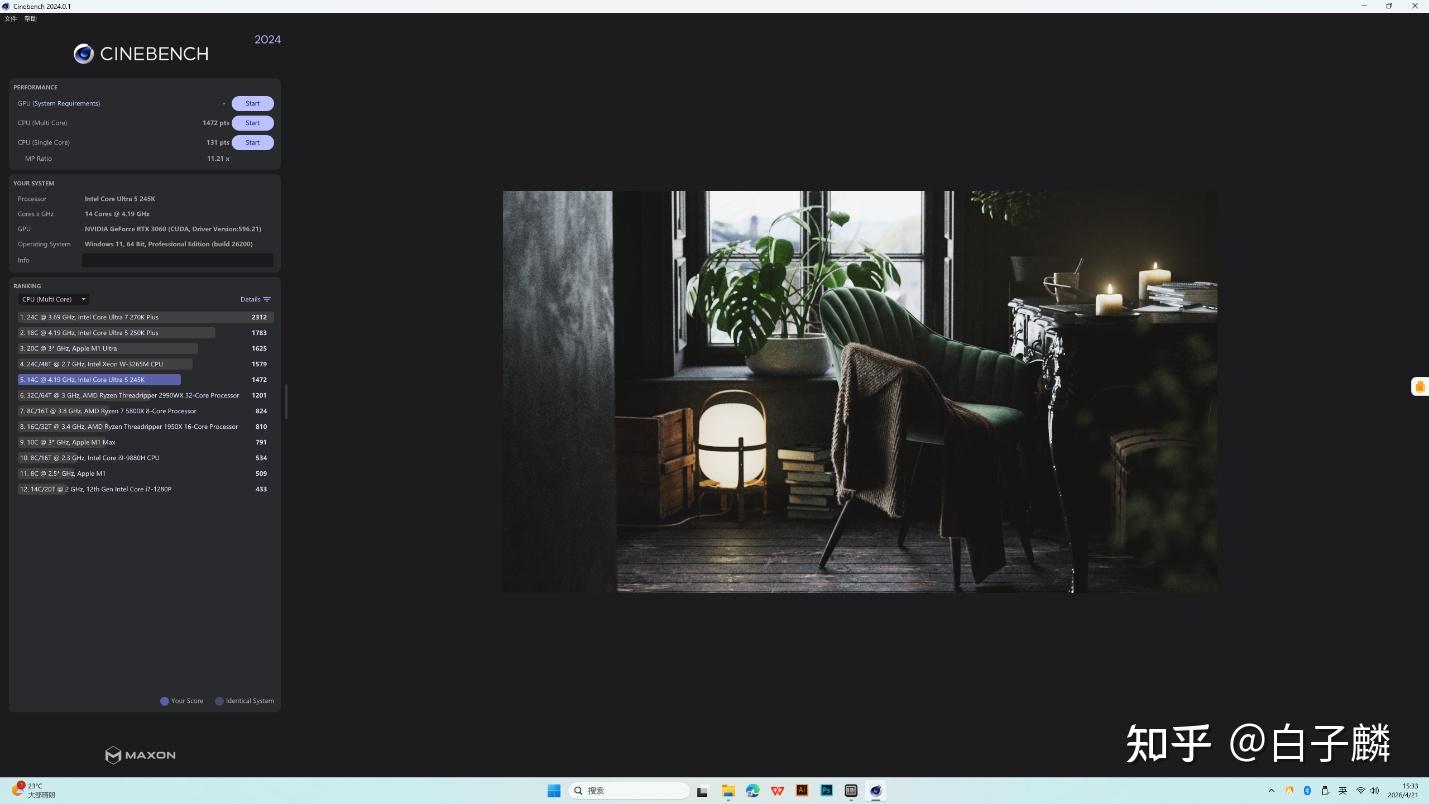
在极具行业公信力的3D渲染引擎基准测试Cinebench 2024中,Ultra 5 245K不仅毫无悬念地击败了同级别的对标产品Ryzen 5 9600X,更是完成了越级挑战,其多核渲染得分比AMD更高阶的8核心处理器Ryzen 7 9700X还要高出惊人的23%。这一数据背后的物理机制在于,在处理诸如Blender 3D渲染、Adobe Premiere Pro多轨视频导出或大规模代码并行编译时,操作系统的任务调度器会将庞大的计算任务切割为无数个微小的线程区块。此时,Ultra 5 245K中那8个具备极高IPC的Skymont能效核全速介入,与性能核协同工作,提供了极度密集且高效的浮点运算支持。
然而,物理定律的客观性决定了算力的提升必然伴随着能量交换的增加。在极致的多核满载压榨下,Intel处理器的功耗呈现出显著的增长。根据详尽的工程测试数据,Ultra 5 245K在极限拷机状态下的封装功耗峰值达到了约205瓦特。相比之下,基于Zen 5架构的高能效特性,AMD Ryzen 5 9600X维持了低功耗运转,即使是性能更强的9700X,在执行Cinebench测试时所消耗的绝对电能也比Intel芯片更低。但从生产效率与总体时间成本的宏观视角来看,英特尔以瞬时功耗的增加为代价,换取了渲染与编译时间的几何级缩短。在商业应用环境中,时间往往是最昂贵的成本,这种通过庞大多核架构“暴力”缩短任务耗时的策略,使得245K在专业工作站与创作者主机领域具备了不可比拟的性价比。
多引擎下的游戏效能验证与物理瓶颈剖析
与在生产力维度的摧枯拉朽之势不同,Ultra 5 245K在游戏绝对帧率这一单一指标上,面临着由于架构重构期带来的物理限制与客观挑战。行业深度的游戏基准测试表明,在与竞争对手的直接对话中,Ultra 5 245K在绝大多数游戏场景中的表现,也就能与Ryzen 5 9600X打成平手。
探究其游戏性能折损的底层逻辑,核心症结在于Foveros 3D多模块拼接封装带来的交叉通信延迟。在传统单片式设计中,CPU核心与内存控制器被蚀刻在同一块硅片上,数据交换的物理距离极短。而Arrow Lake架构将核心模块与SoC模块(包含内存控制器)物理分离,数据必须穿过封装基板进行跨模块互联。这种Inter-Tile Latency在对内存延迟极其敏感、且主要依赖单线程高频的传统老旧游戏引擎中,直接导致了1% Low帧率(反映游戏卡顿程度的指标)的下降。同时,为了将功耗压制在极佳的范围内,其最高5.2GHz的睿频也略显保守。
然而,若将视野从极限跑分软件拉回至玩家日常接触的具体游戏生态中,Ultra 5 245K所提供的实际沉浸体验依然是非常卓越的。不同的游戏引擎对硬件资源的榨取方式有着本质的区别:
在以《三角洲行动》(Delta Force)和《无畏契约》(Valorant)为代表的高帧率电子竞技射击游戏中,游戏引擎高度依赖处理器的单核IPC性能与巨大的三级缓存容量。Ultra 5 245K配备了高达36MB的L3缓存,结合Lion Cove微架构的大幅IPC提升,在《三角洲行动》拥有海量玩家同屏大乱斗的超大规模地图中,

在2K极高画质下依然能够提供150-200FPS的绝对流畅体验,足以喂饱甜点级用户常用的180Hz高刷新率电竞显示器。特别是,此时底层引擎需要进行极其复杂的弹道计算与物理碰撞演算,245K的14个物理核心能够有效地分担后台进程负荷,确保在爆炸与密集交火的瞬间帧率不会出现灾难性断崖下跌。
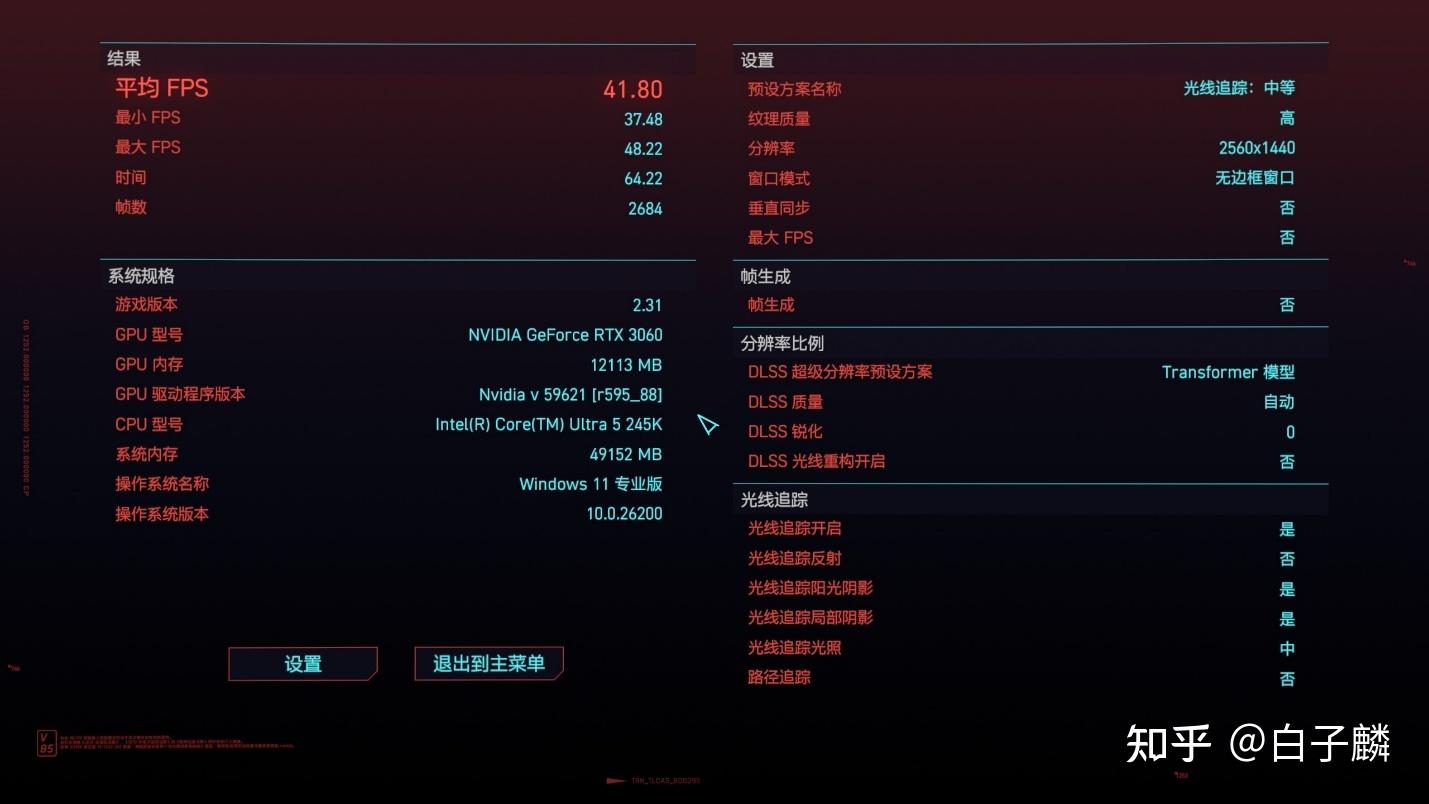
对于像《赛博朋克 2077》(Cyberpunk 2077)这样被业界公认为“CPU杀手”的开放世界3A大作,由于夜之城中密集的NPC人工智能寻路系统以及光线追踪边界体积层级(BVH)结构的实时构建需求,游戏引擎经过CDPR的长期优化,已经能够极其优秀地调用处理器的所有可用线程。在此类重度并行化的游戏场景下,245K凭借核心数量的压制力,有效弥合了单核延迟的劣势,哪怕是搭配RTX3060,仍然可以提供不低于45FPS的次世代漫游体验。
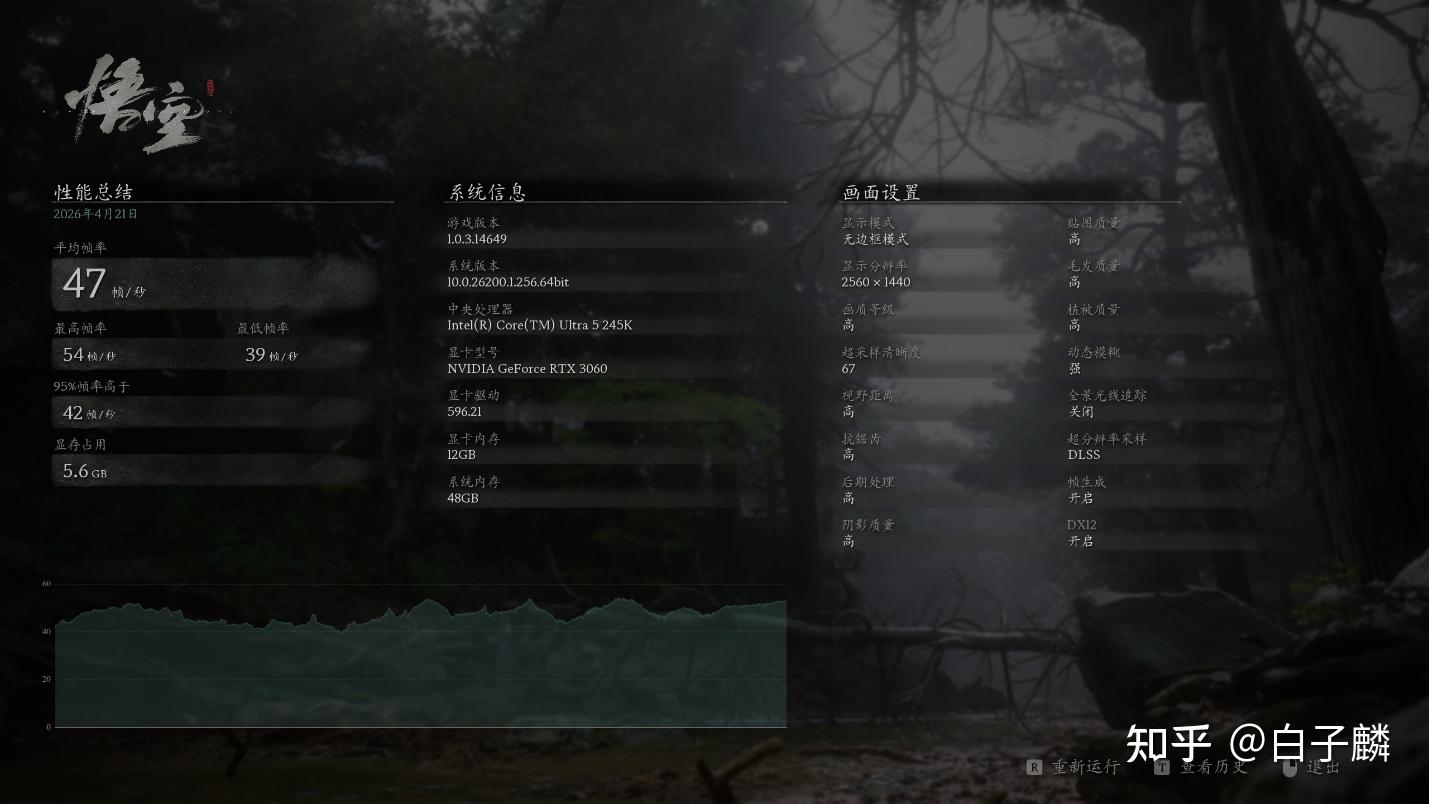
当测试场景切换至由虚幻引擎5(Unreal Engine 5)打造的《黑神话:悟空》(Black Myth: Wukong)以及高度依赖图形贴图的《古墓丽影》(Tomb Raider)时,硬件的性能瓶颈发生了根本性转移。在这类极其吃重GPU算力的游戏中,尤其是在玩家普遍采用的2K或4K超高清分辨率下运行Lumen全局光照和Nanite虚拟微多边形几何体技术时,系统的整体帧率几乎百分之百受到独立显卡性能的制约(即GPU Bound状态)。在这样的渲染压力下,处理器之间那原本存在于理论评测中的5%到9%的基准性能差距,会被高分辨率带来的图形瓶颈彻底抹平。玩家在面对“黑猴”中震撼的法术特效或“古墓”中宏大的遗迹场景时,人类肉眼根本无法感知到Ultra 5 245K与其他中端处理器在帧率表现上的任何差异。
综合评估而言,对于绝大多数希望兼顾高分辨率3A大作享受、日常电竞娱乐以及偶尔开启后台录制与直播串流的综合型玩家而言,Ultra 5 245K在游戏端的表现完全达到了主流高阶水准,不存在任何影响实际体验的短板。
618电商大促节点的市场策略与全景选购建议
随着年度最重要的电商购物狂欢节“618”即将拉开帷幕,各大半导体制造商、主板厂商以及PC整机品牌必将展开一轮极其强势的价格博弈与促销攻势。将前述针对架构、存储周期、扩展协议、功耗形态、端侧AI以及具体应用效能的所有宏微观分析进行交叉验证后,本报告强烈推荐将英特尔酷睿Ultra 5 245K作为今年618期间值得投资的核心处理器组件。这一结论建立在其具备的极其深厚的“非对称系统优势”基础之上。
首先,从投资回报率(ROI)的角度审视,在618期间各类跨店满减、百亿补贴以及主板厂商“板U套装”捆绑销售的加持下,Ultra 5 245K极有可能稳稳扎根于1200元人民币这一黄金价位段。在该预算区间内,获取一颗采用当前最顶尖N3B制程代工、拥有14核心14线程且多核性能完胜更高阶竞品的处理器,堪称年度最佳的硬件红利。叠加当前DDR5内存价格的阶段性疲软,装机者可以省下极其可观的预算去升级PCIe 5.0固态硬盘或更高级别的显卡,实现整机木桶效应的彻底根除。
其次,从现代物理空间美学与环境友好的维度来看,该处理器优秀的125W/159W功耗控制曲线,使其成为构建Intel UES(极致优雅系统)主机的完美心脏。借助于618期间丰富多样的ITX主板与高质感SFX电源的促销,用户能够以远低于平时的组建成本,打造出一台占地面积不足0.06平方米、高度静音且性能澎湃的桌面艺术品。这台微型系统将完美贯彻“早A晚G”的生活理念,白天安静地输出卓越的多线程生产力,夜晚释放强大的游戏潜能,完全融入现代城市公寓的审美语境。
最后,站在PC产业发展的历史维度上,NPU3硬件单元的内建不仅是对现有硬件规格的补充,更是通往未来五年软件生态的船票。借助樱桃助手(Cherry AI)所展示出的“越用越好用”的深度系统控制力与基于“感知-决策-执行”的毫秒级本地交互机制 2,平台已被赋予了真正的智慧属性。随着微软Windows系统以及各类第三方开发者持续将更多的AI生成与推理功能部署至本地计算端,缺乏独立NPU的老旧架构处理器将无可避免地面临迅速贬值与体验断层的风险。
综上所述,英特尔酷睿Ultra 5 245K并非是一颗在单一维度上盲目追求极限跑分的偏科产品,而是一款深刻洞察了现代数字创作者、居家办公群体以及高阶游戏玩家复杂需求的六边形多面手。在今年618的选购清单中,它无疑是构建下一代兼顾空间优雅、强大算力与全天候AI生态的高性能桌面的核心基石。