
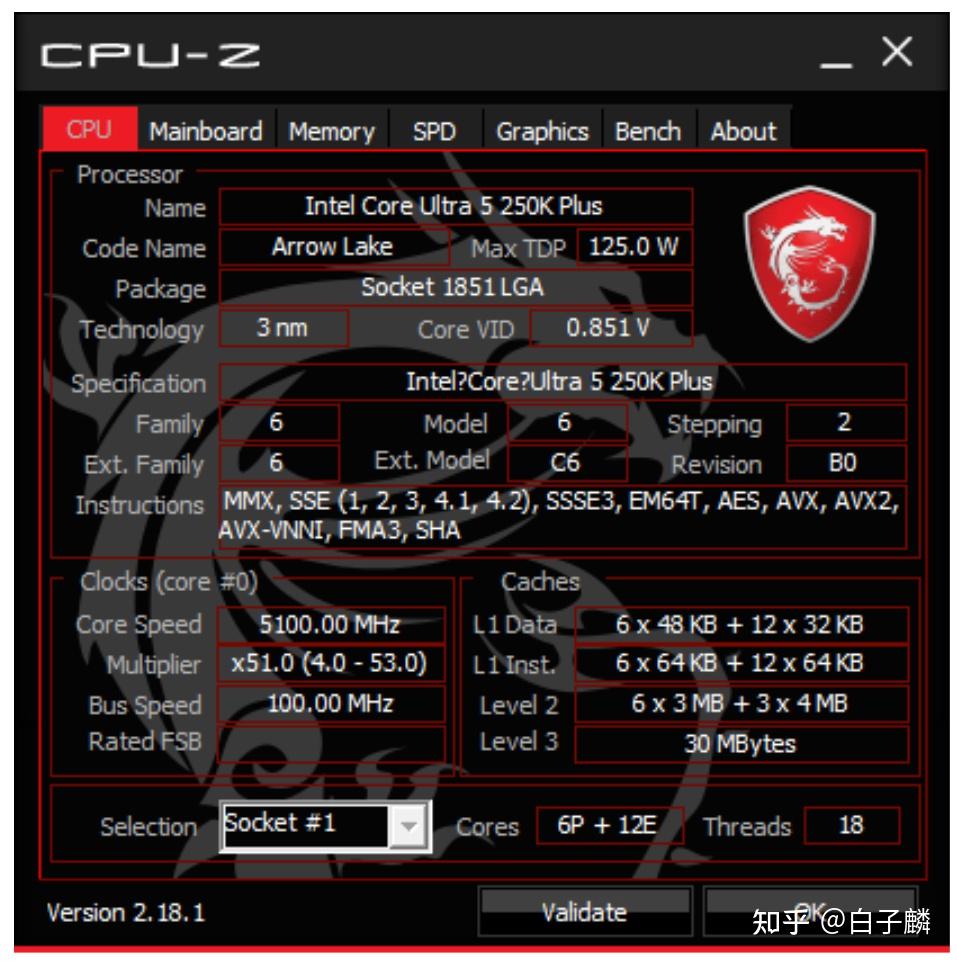
英特尔酷睿Ultra 5 250K Plus的架构演进以及生态协同
分离式模块化架构的战略转移与市场定位
微处理器半导体行业目前正经历一场结构性的演进,传统的单片硅(Monolithic)设计正在向分离式、基于平铺模块(Tile-based)的封装架构进行进化。处于这一消费级桌面市场转型最前沿的,是英特尔酷睿Ultra 5 250K Plus处理器。
作为Arrow Lake Refresh(酷睿Ultra 200S Plus)家族中的中端主力与性能标杆,该款处理器从底层的核心规格、互联频率到上层的软件生态均完成了全方位的深度优化与升级。在以199美元这一极具侵略性的官方建议零售价(MSRP)发布后,该处理器通过将高核心数计算集群、深度硬件与软件协同优化能力以及专用的人工智能(AI)计算硅片引入此前由传统六核架构主导的细分市场,从根本上颠覆了传统的预算与性能收益比。
酷睿Ultra 5 250K Plus在物理制造层面充分利用了英特尔先进的Foveros 3D封装技术,战略性地将不同的功能组件隔离到特定的模块(Tile)中。其中,容纳物理计算核心的计算模块(Compute Tile)采用了台积电(TSMC)最为先进的3纳米(3nm)工艺节点进行制造。这一制造决策代表了一项关键的战略布局,因为该节点在晶体管密度和能效比上甚至领先于竞争对手AMD在Zen 5架构处理器上所采用的台积电4纳米节点。此外,负责内存控制器、神经网络处理单元(NPU)以及PCIe根复合体的系统级芯片模块(SoC Tile)采用6纳米节点制造,而集成显卡模块则建立在5纳米节点之上。这种分离式的晶圆制造策略实现了成本与性能产出的最佳平衡,但也为不同模块之间的数据传输引入了潜在的延迟挑战。为此,英特尔在“Plus”更新周期中,通过对非核心(Uncore)频率架构进行激进的底层时钟频率优化,正面解决了这一物理限制带来的性能折损问题。
18核18线程(18C18T)的微架构创新与强劲多核性能
在核心拓扑结构上,酷睿Ultra 5 250K Plus采用了一套前所未有的18核18线程(18C18T)配置矩阵。这不仅是英特尔在“5”系列级别桌面处理器产品线中所部署的最高物理核心数量,同时也标志着相较于其直接前代产品(酷睿Ultra 5 245K),它在保持相同功耗设定的前提下,暴力增加了四个能效核心(E-Cores),从而在多线程吞吐量上实现了质的飞跃。
Lion Cove与Skymont微架构的协同计算机制
该处理器的计算模块由两种具备完全不同设计哲学和指令集吞吐能力的微架构组成,它们通过英特尔硬件线程调度器进行动态任务分配。首先是六个基于“Lion Cove”架构的性能核心(P-Cores),这些核心的基础运行频率为4.2 GHz,并且能够在热余量允许的情况下,通过睿频加速技术达到最高5.30 GHz的时钟频率,相较于前代产品提升了100 MHz。Lion Cove架构设计中最为显著的结构性偏离,是英特尔在桌面级性能核心上彻底移除了超线程技术(Hyper-Threading / SMT)。这一工程决策从微观角度有效缓解了同一物理核心内两个逻辑线程对缓存、执行端口和分支预测器的竞争冲突,同时显著减小了单个核心的物理占用面积,使得工程师能够为每个P核配置更宽的乱序执行引擎和更大容量的私有二级缓存(L2 Cache)。
其次,处理器集成了十二个基于“Skymont”架构的能效核心(E-Cores),其基础频率设定为3.3 GHz,最大加速频率可达4.60 GHz。Skymont架构代表了英特尔在每时钟指令数(IPC)性能上的一次重大跨越,其执行效率的大幅跃升实质上已经弥合了传统能效核心与过去几代性能核心之间的绝对算力差距。当处理大规模并行计算负载时,十二个E核能够以极低的功耗代价提供持续的高吞吐计算能力,在不闲置时始终稳定在4.6 GHz的频率区间运行。这十八个物理核心共享高达30 MB的L3大容量缓存,这也是该级别前代产品中配置的最大容量,极大地降低了在执行内存密集型任务时因缓存未命中(Cache Miss)而产生的数据获取延迟。
多线程拓扑架构的二阶性能推演与基准验证
部署无超线程的18个纯物理执行线程具有深远的战略和算力意义。在传统的处理器架构中,逻辑线程在单个物理核心内竞争执行资源,当处理重度浮点运算或密集型整数计算时,往往会导致流水线停顿(Pipeline Stalling)或资源饥饿。通过提供18条完全独立的物理执行流水线,酷睿Ultra 5 250K Plus确保了在代码编译、3D渲染、数据压缩解压以及服务器端计算等高度并行化工作负载中,性能扩展呈现出近乎线性的确定性比例。
| 处理器微架构参数对比 | 英特尔 Core Ultra 5 250K Plus | 英特尔 Core Ultra 5 245K | AMD Ryzen 5 9600X |
| 物理核心/线程总数 | 18C (6P + 12E) / 18T | 14C (6P + 8E) / 14T | 6C / 12T |
| 性能核心(P核)最高频率 | 5.30 GHz | 5.20 GHz | 5.40 GHz (综合最高) |
| 能效核心(E核)最高频率 | 4.60 GHz | 4.60 GHz | 无 |
| 共享L3缓存容量 | 30 MB | 24 MB | 32 MB |
| 首发官方建议零售价(MSRP) | $200 | $310 | ~$279 |
在应用基准测试的实证环节中,当面对其主要市场竞争对手——拥有12线程的AMD Ryzen 5 9600X时,酷睿Ultra 5 250K Plus展现出了压倒性的多核统治力。例如,在Cinebench R23的多线程渲染基准测试中,250K Plus的渲染速度比Ryzen 5 9600X快了惊人的85%。
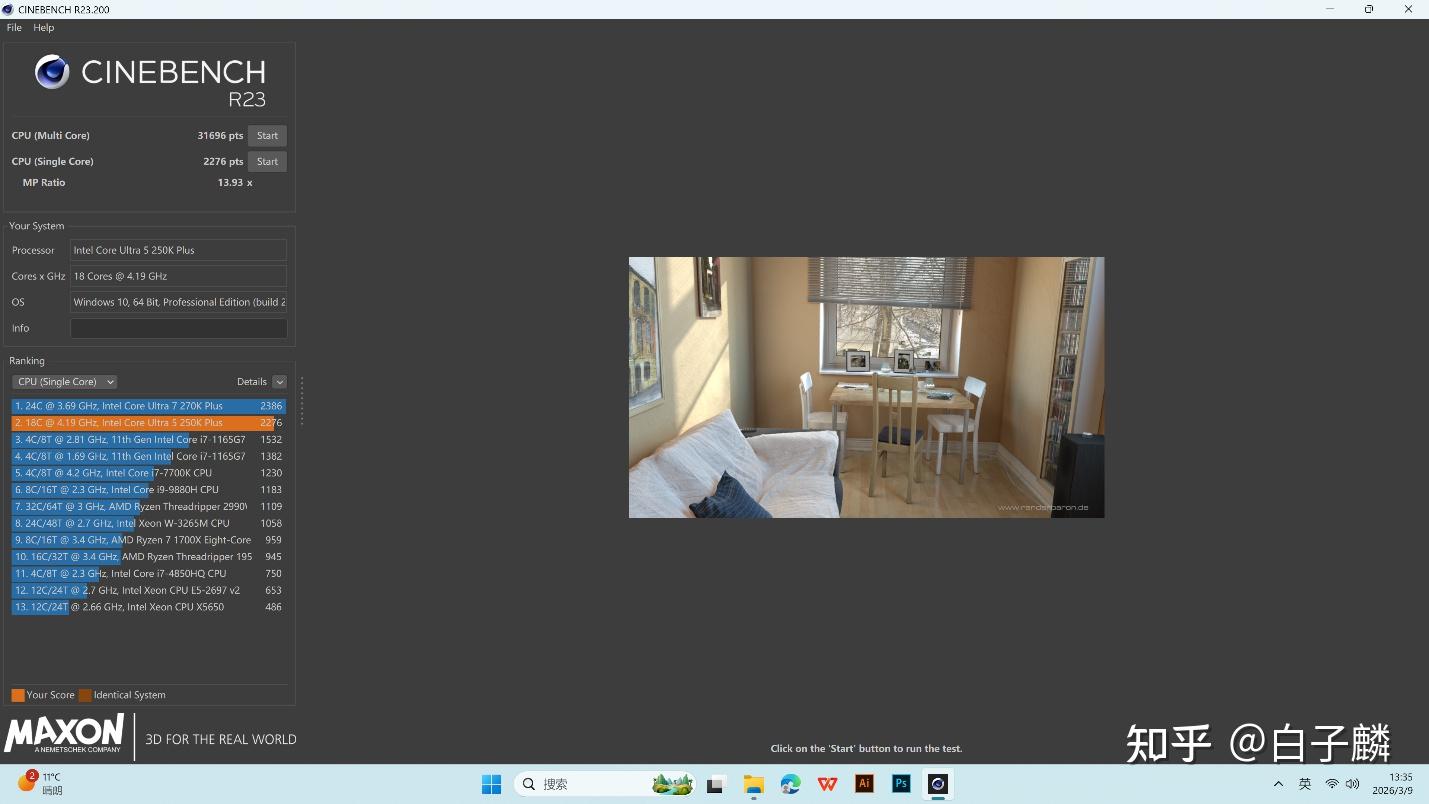
在7-Zip文件解压缩等重度依赖多线程吞吐的指令集中,其性能跑分达到了151K MIPS,相较于Ryzen 5 9600X拥有超过45%的性能优势,甚至比上一代主打性能的酷睿i5-14600K也高出了约9%。这种跨级别的多线程算力碾压,证明了“Lion Cove + Skymont”异构设计在当前操作系统线程调度器配合下的绝对高效性。
SoC互联结构的底层优化:NGU与D2D频率的显著提升
早期基于平铺模块(Tile-based)架构的处理器面临的一个基础性工程漏洞,是当数据包需要在计算模块、SoC模块和图形模块之间横向传输时,所产生的互联延迟惩罚(Latency Penalty)。在处理对内存延迟高度敏感的工作负载(如高帧率电子竞技游戏)时,这种微秒级的延迟会直接转化为帧生成时间的波动(Frame-time Spikes)。英特尔在酷睿Ultra 200S“Plus”系列中,通过对互联结构的硬件级频率机制进行深度再造,彻底纠正了这一架构缺陷。
酷睿Ultra 5 250K Plus出厂即内置了极其激进的Die-to-Die(D2D)互联架构时钟频率,将其直接锁定在3000 MHz(3.0 GHz),同时将下一代非核心(Next-Gen Uncore, NGU)架构时钟频率大幅推高至3200 MHz(3.2 GHz)。为了将这一数据置于历史架构的背景中进行考量,初代的Arrow Lake酷睿Ultra 5 245K其D2D运行频率仅为保守的2100 MHz(2.1 GHz)。这意味着250K Plus在不改变物理封装走线的前提下,将核心间的数据传输带宽和响应速度提升了高达43%。
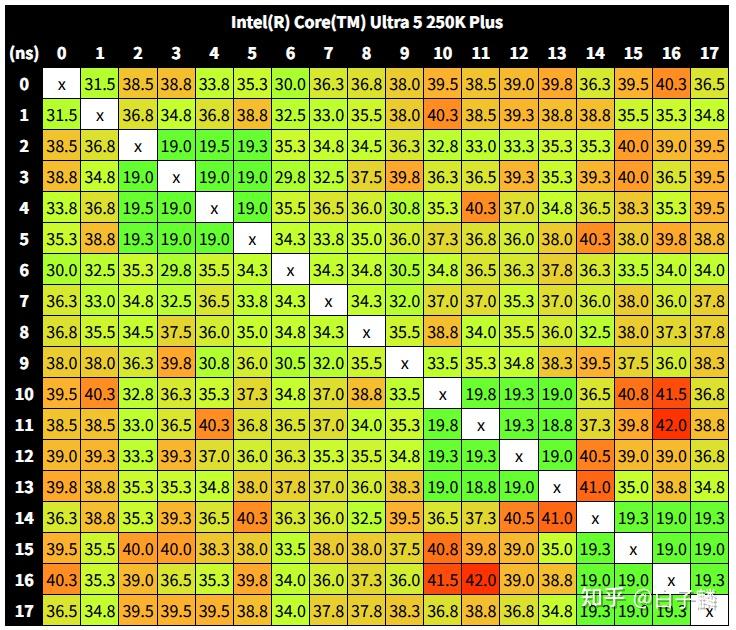
这种提升使得E-E和P-P核心延迟都大幅缩短至40ns以及20ns左右。
此外,处理器的环形总线(Ring Clock)频率也获得了额外的200 MHz提升,最终达到了3.9 GHz。
这种互联频率的指数级提升,在数学和物理机制上直接导致了数据遍历时间的缩短。如果用微分模型来表达,数据在不同硅片间传输的延迟周期与互联频率成严格的反比关系。通过将互联频率从2.1 GHz提高至3.0 GHz,计算核心向位于SoC模块上的内存控制器发出读取请求到获取数据的等待周期被急剧压缩。
这种此前仅能通过发烧友在主板BIOS中手动调节选项才能获得的性能红利,现在已被作为标准状态固化在了250K Plus的硅片逻辑中。在实际的软件层面上,这一底层硬件频率的跃升转化为了显著的游戏帧率收益。在《霍格沃茨之遗》和《反恐精英2》等对内存子系统访问极其频繁的测试场景中,这种D2D和NGU的优化直接带来了相较于未优化版本(如245K)高达12%至18%的平均帧率提升,并显著收窄了1% Low(最低1%帧率)的方差,证明了封装技术的物理局限性完全可以通过极为精准的频率和电源状态管理来进行软性规避。
125W/159W的节能低功耗特性以及UES小主机
尽管在物理核心数量和互联频率上实现了双重的大幅跨越,英特尔对酷睿Ultra 5 250K Plus的功耗边界设定却展现出了极强的工程自律性。该处理器严格遵守125瓦(125W)的处理器基础功耗(Processor Base Power, 简称PBP或PL1)标准,并将其最大睿频功耗(Maximum Turbo Power, 简称MTP或PL2)封顶于159瓦(159W)。
功耗限额治理与真实负载下的能效表现
159W的PL2硬性阈值将这款处理器精准地定位为一台高能效的计算引擎,尤其是当业界回溯至上一代Raptor Lake架构(如i5-14600K或更高级别处理器)在重负载下动辄突破200W甚至250W热设计功耗的时代,这种能效层面的倒退式优化实际上是向合理计算密度的回归。
在真实的渲染测试(如Cinebench多核满载)中,其系统功耗仪测定值为154W左右,虽然略高于具有6个核心的AMD Ryzen 5 9600X,但考虑到其提供了高达85%的性能领先幅度,其每瓦性能(Performance-per-Watt)比值实际上实现了代际碾压。在更为典型的游戏场景(如《星际战士2》)中,处理器的遥测数据显示其平均功耗仅为91瓦,与以节能著称的9600X完全持平,同时却提供了更为稳定和卓越的帧数输出曲线。
高效能小主机形态的生态协同及散热策略
正是得益于其原生的159W MTP能效上限,酷睿Ultra 5 250K Plus成为了构建小型化尺寸桌面系统的理想计算核心。在体积通常小于15升甚至10升的ITX机箱内,空气动力学的物理限制是系统性能发挥的最大瓶颈。高发热量芯片在这种密闭空间内会将机箱变成一个微型烘烤箱,导致其他组件(如PCIe Gen 5固态硬盘)出现连带的热降频现象。
为了进一步推动这一趋势,英特尔推出了Intel UES(Ultra Elegant System)主机概念。顾名思义,这是一套“极致优雅的高性能桌面计算平台”,通过架构创新,在保障散热效率的前提下实现主机形态的极致紧凑化。UES概念创新性地引入了“桌面得房率”概念,将主机桌面投影面积控制在0.06 ㎡以内,在最小空间占用的同时,最大化硬件配置密度与性能释放。这既满足了极客对硬件性能的严苛需求,又完美适配现代桌面、家居环境的空间与审美需求,使搭载如250K Plus处理器的PC成为兼具空间友好性与性能表现力的家庭及办公(早A晚G)的核心组件。
为了在这种严苛的环境下驯服250K Plus,平台架构和主板支持引入了全新的机械设计方案。LGA 1851插槽的Z轴高度与上一代LGA 1700保持一致,因此能够向下兼容现有的散热扣具。更为关键的是,针对ITX主板空间狭小且经常需要挂载重型下压式散热器或定制AIO水冷冷头的情况,部分高端ITX主板(如ASRock Phantom Gaming B860I Lightning Wi-Fi)独家配备了“降低负载独立加载模块”(Reduced Load ILM, 简称RL-ILM)。这种改良型金属支架专门通过降低对CPU封装基板的安装下压克数,有效防止了由于压力不均导致的芯片PCB弯曲,从而确保集成散热器(IHS)与冷排底座之间能实现最完美的硅脂涂抹与热传导耦合,这是极限ITX散热环境中的核心保障 18。
在软件调试层面,经验丰富的系统集成商和爱好者在使用ITX主板搭载250K Plus时,必须在BIOS中执行以下纠正程序,以重构最佳的能耗比:
1. 重置官方电源参数:手动将长时功耗限制(PL1)锁定为125W,短时功耗限制(PL2)锁定为159W(若水冷散热良好可宽泛至253W),并将维持时间(Tau)设定为标准的56秒 16。
2. 异构降压(Undervolting):由于Arrow Lake架构支持对P核和E核进行完全独立的电压偏移调整,玩家可以通过Offset模式进行动态降压操作。这一过程能在不牺牲任何实际计算性能(或仅损失微弱性能)的前提下,实现断崖式的温度下降和风扇噪音抑制。通过这套电源控制组合拳,250K Plus能够在Mini-ITX环境中长期保持在安全温度阈值内满血运行。
系统I/O拓扑结构:多PCI-e通道带来的无界扩展性
在现代发烧级个人计算机与生产力工作站中,算力瓶颈往往不在于中央处理器,而在于如何将海量数据高速输入和输出(I/O)到GPU加速器和高速非易失性存储阵列中。作为对计算生态演进的回应,英特尔在Arrow Lake Refresh平台上构建了极其宽阔的PCI-Express数据总线基础设施,打破了中端处理器的I/O通道壁垒。
酷睿Ultra 5 250K Plus原生直接由CPU封装内部输出高达24条下行PCI-Express通道,全面覆盖并兼容PCIe 5.0和PCIe 4.0协议规范。
24条CPU直连通道的物理拓扑拆解
这种慷慨的通道分配策略在结构上进行了高度优化,旨在彻底消除周边设备之间的带宽争夺与瓶颈效应:
1. 核心图形扩展(PEG通道):处理器保留了完整的16条PCIe Gen 5超高速通道,独占分配给主要显卡接口(x16插槽)。这意味着未来的下一代旗舰显卡将拥有双倍于Gen 4的理论带宽,不存在任何数据拥堵。
2. 直连主存储通道:处理器额外拨出了独立的4条PCIe Gen 5通道,专门绑定给CPU直连的M.2 NVMe SSD。这是一个革命性的通道分离设计——在过往的许多架构中,一旦用户安装了Gen 5的固态硬盘,系统就会自动窃取(Bifurcate)并拆分原本属于显卡的x16通道。但在250K Plus上,GPU和Gen 5 SSD能够同时满带宽运行,互不干扰。
3. 高速外设与辅助存储通道:除上述20条Gen 5通道外,CPU还直接输出额外的4条PCIe Gen 4通道。这一部分总线不仅可以布线为第二个直连的M.2插槽,更具备驱动高带宽主板载设备的潜能,例如直接接入独立的Thunderbolt 5(雷电5)主控芯片。事实上,处理器内部已经完全集成了一个原生的Thunderbolt 4控制器,能够直接对外输出数个带宽高达40 Gbps的高速物理接口。
芯片组连接性与拆分支持的深远影响
在南桥芯片的交互层面,处理器通过一条高带宽的DMI(直接媒体接口)4.0 x8总线与底层的800系列主板芯片组(如Z890或B860)进行全双工通信,其通信吞吐量完全等同于PCI-Express 4.0 x8的物理带宽 18。经由这一桥接,Z890芯片组能够进一步向系统下游广播扩散出多达24条PCIe Gen 4通道。相较于前代Z790芯片组仅能输出16条Gen 4和8条Gen 3通道的妥协方案,800系芯片组在纯粹的数据交换容量上实现了爆炸性的增长 18。
| PCI-e 通道类型与分布矩阵 | 通道数量与协议规范 | 系统拓扑应用场景映射 |
| CPU 直连显卡 (PEG) | 16x PCIe Gen 5 | 独显满血输出,不与存储共享带宽 |
| CPU 直连主存储 | 4x PCIe Gen 5 | 极致读取速度的NVMe系统盘 |
| CPU 直连辅助/外设 | 4x PCIe Gen 4 | 备用M.2存储或Thunderbolt主控接入 |
| 处理器与芯片组桥接 | DMI 4.0 x8 | 实现等效PCIe 4.0 x8的南北桥通信 |
| Z890 芯片组下行扩展 | 24x PCIe Gen 4 | 无线网卡、额外RAID卡、万兆网卡扩展 |
更为关键的是,为了满足极客与小型工作站的专业需求,该平台内置了对复杂PCIe通道分拆(Bifurcation)的原生支持。处理器允许将PEG通道自由拆分为 1x16+2x4、2x8+2x4 甚至 1x8+4x4 等多种电气布局拓扑。这赋予了用户极大的灵活性,无论是深度学习研究者试图在单板上插载多块推断加速卡,还是视频后期剪辑师需要构建规模庞大的基于阵列卡(RAID)的NVMe存储集群,酷睿Ultra 5 250K Plus都能从底层架构上完美支撑这种以往仅见于HEDT(发烧级桌面)或至强工作站级平台的极致扩展能力。
软硬件协同定义的算力:APO与IBOT技术的颠覆性优化
在酷睿Ultra 200S Plus系列的迭代中,最具技术突破性的里程碑并非单纯的晶体管堆砌,而是英特尔从纯粹的硬件算力驱动向“软件与硬件联合定义计算”的底层范式转移。这种转移的核心载体是一个被称为“英特尔平台性能套件”(Intel Platform Performance Package, 简称IPPP)的全能型系统级软件框架 9。该套件在系统层级上的地位类似于竞争对手的芯片组驱动程序,全面接管了操作系统的线程调度机制、核心休眠(Core Parking)逻辑以及空闲状态电源行为。
正是在IPPP框架的统筹下,英特尔部署了两个具有核弹级威力的游戏底层优化引擎:原有的应用程序性能优化技术(Application Performance Optimization, APO)以及首次亮相、令人惊叹的英特尔二进制优化工具(Intel Binary Optimization Tool, 简称IBOT)。

IBOT机制的编译器级别深度剖析
IBOT技术在发布初期由200S Plus系列处理器(包含250K Plus、250KF Plus及270K Plus等)所独占,它在中央处理器的运行逻辑上,相当于图形学领域中GPU执行“着色器替换与重编译”的CPU翻版。
在传统的软件执行流程中,游戏引擎的代码在经过编译器打包生成二进制执行文件后,为了兼容市面上广泛的最低标准x86架构设备,往往使用的是基础且效率低下的标量(Scalar)指令序列。这些老旧的指令序列无法有效填满现代处理器(如Lion Cove架构)内部极宽的乱序执行端口,也无法有效利用大容量缓存,从而在CPU内部形成流水线气泡,导致严重的性能瓶颈。
IBOT则作为一个后链接时期(Post-link)的用户态运行时(User-mode Runtime)优化器介入这一过程 23。当游戏或应用程序被操作系统加载入内存时,IBOT在后台利用校验和(Checksum)匹配以及二进制哈希(Binary Hashing)算法,实时侦测并识别特定的、经过英特尔实验室预先分析白名单认证的软件执行程序 23。
一旦识别成功,IBOT的动作不仅限于重新排序指令以防止流水线停顿,它更采取了侵入式且激进的重构机制:它会在内存运行态中,直接找到那些执行效率低下的机器码序列,并将它们“替换”为高度优化的、特定于英特尔架构的替代指令。最核心的替换逻辑,就是将低效的标量指令批量转换为支持AVX(高级矢量扩展)的向量化指令(Vectorized Code)。通过将数据组织结构重新排列(英特尔官方形象地将其比喻为玩俄罗斯方块般的无缝拼接),IBOT极大地降低了分支预测失误率(Branch Misinterpretations),并最大限度地减少了L2和L3缓存的未命中次数。
实测环境下的帧率跃升
独立技术媒体利用底层遥测工具进行逆向分析后发现,被IBOT注入优化的应用程序,其执行向量指令的数量比未经优化的原生版本高出了惊人的14.6倍。在广泛的实测数据汇总中,抛开任何硬件变动,单凭IBOT软件层的“魔法”转换,就能在两款处理器(Ultra 7 270K Plus与Ultra 5 250K Plus)上实现平均8%的纯渲染帧率提升。

而在某些优化效果极佳的3D引擎架构下,例如在《古墓丽影:暗影》(Shadow of the Tomb Raider)的测试场景中,这种依靠二进制机器码替换带来的帧率增长峰值甚至达到了18%。这相当于用户在不支付任何额外费用的情况下,通过系统驱动白嫖到了相当于一整代微架构IPC提升的性能红利。
跨显卡层级的游戏性能表现矩阵:从主流到旗舰的算力释放
要对一款售价仅为200美元的处理器进行准确的市场估值,绝对不能仅仅停留在生产力软件或合成基准测试的图表上。酷睿Ultra 5 250K Plus的真正战场在于复杂的游戏渲染管线。其高达5.3 GHz的睿频以及18个实体线程的庞大并发吞吐量,确保了它既能够完美适配主流显卡,也拥有足够的单核性能和多核调度余量去喂饱那些处于性能金字塔顶端的发烧级显卡,而不产生任何木桶效应中的短板瓶颈。
驱动主流市场的生态基本盘:搭配RTX 3060的性能下限测试
根据最新的Steam硬件调查数据,Nvidia GeForce RTX 3060依然牢牢占据着全球最受玩家欢迎显卡榜首的位置。在搭配这一具有庞大受众基础的中端显卡时,酷睿Ultra 5 250K Plus的作用在于彻底消除因为CPU渲染指令提交缓慢(Draw Call Bottleneck)而导致的显卡闲置。测试结果清晰地表明,在1080p和1440p分辨率下,这套配置能够让RTX 3060的GPU使用率始终锁死在99%的满载状态。
在《CS2》中,这种搭配可以在2K高画质预设下稳定输出大约320 FPS的电竞级电竞帧率;
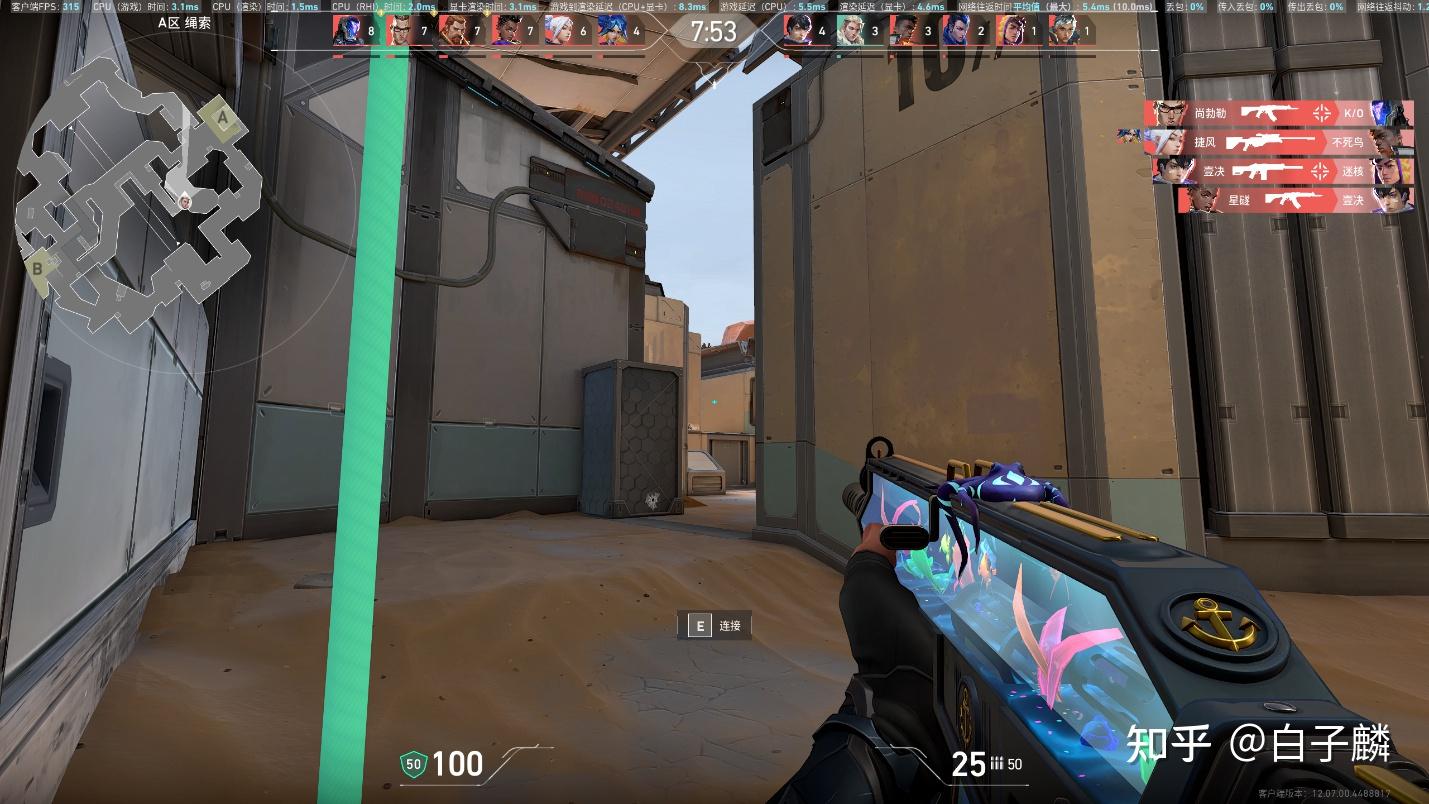
同样的《无畏契约》也保持了321fps这种良好的成绩;
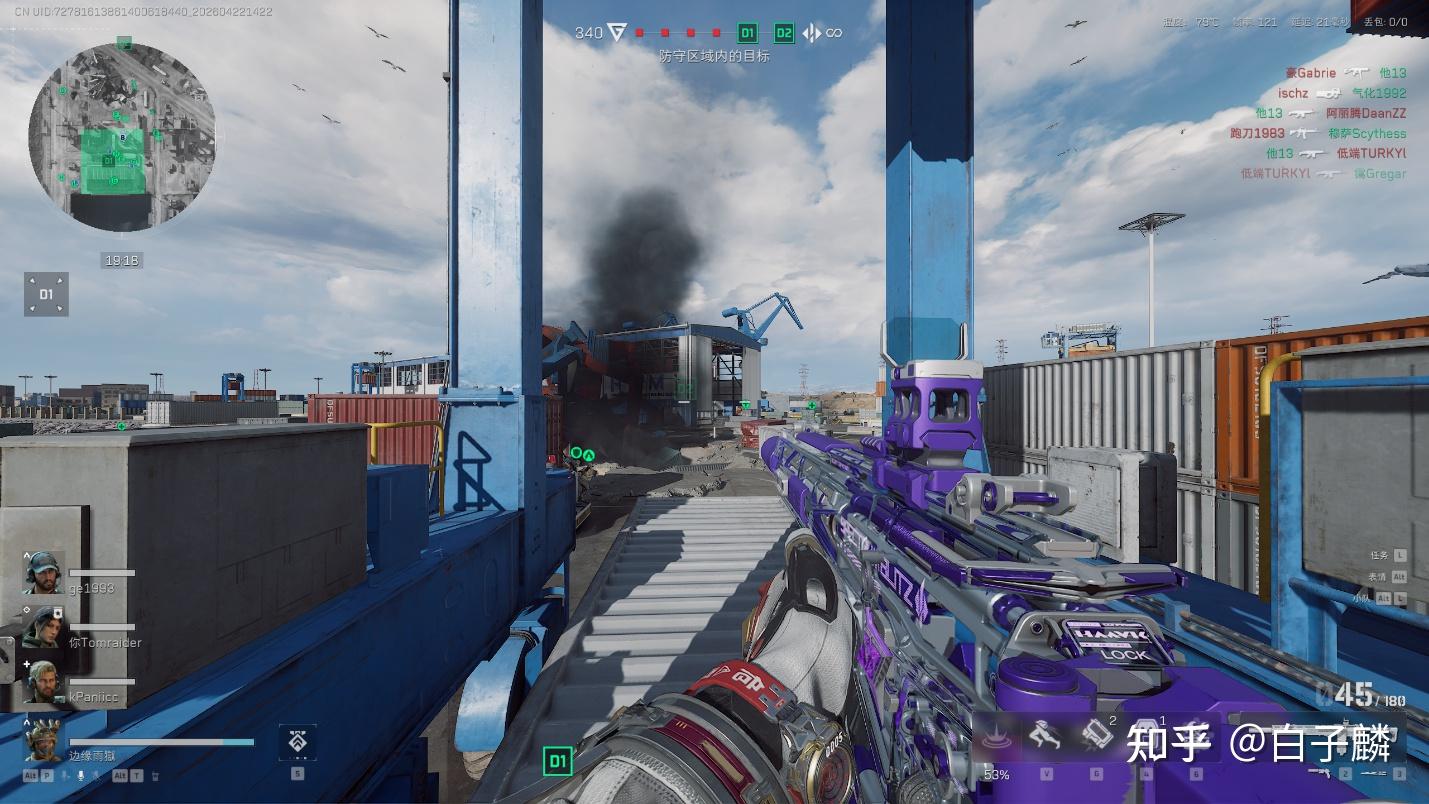
高画质下的《三角洲行动》也能稳固在120 FPS的刷新率阈值。
更重要的是,250K Plus所拥有的30 MB大容量L3缓存,在复杂多人对战环境(如大量弹道计算、物理破坏演算)中发挥了决定性作用。在大型多人射击游戏《战地6》(Battlefield 6)的测试场景中,250K Plus虽然在平均帧率上仅领先Ryzen 5 9600X约11%,但在极其影响玩家手感和画面撕裂感的1% Low(最低1%帧率)指标上,却取得了令人瞩目的33%的巨大领先优势。这意味着在爆炸物密集出现的瞬间,英特尔平台完全消除了卡顿(Micro-stutters),确保了绝对平滑的视觉输出。
挑战性能天花板:搭配RTX 5070 Ti与RTX 5080的高端适配性验证
验证一款中端CPU真实架构弹性的最佳方式,是将其与跨越多个价格层级的下一代旗舰显卡(如Nvidia RTX 5070 Ti和RTX 5080)进行匹配。这种极限测试旨在探测CPU内部数据传输结构在面对每秒数以百计的4K级高清画面渲染请求时,是否会发生热力学失控或频率雪崩。
当酷睿Ultra 5 250K Plus与这两款怪兽级GPU搭档时,处理器本身并未成为整个系统的降速降频触发器。尤其是在最新的视觉大作(如《赛博朋克2077》中,一旦玩家开启DLSS 4(深度学习超级采样技术第4代)以及多帧生成(Multi-Frame Generation, MFG)技术,RTX 5080能够轻易将4K画质下的游戏体验推升至190 FPS以上的恐怖境界。
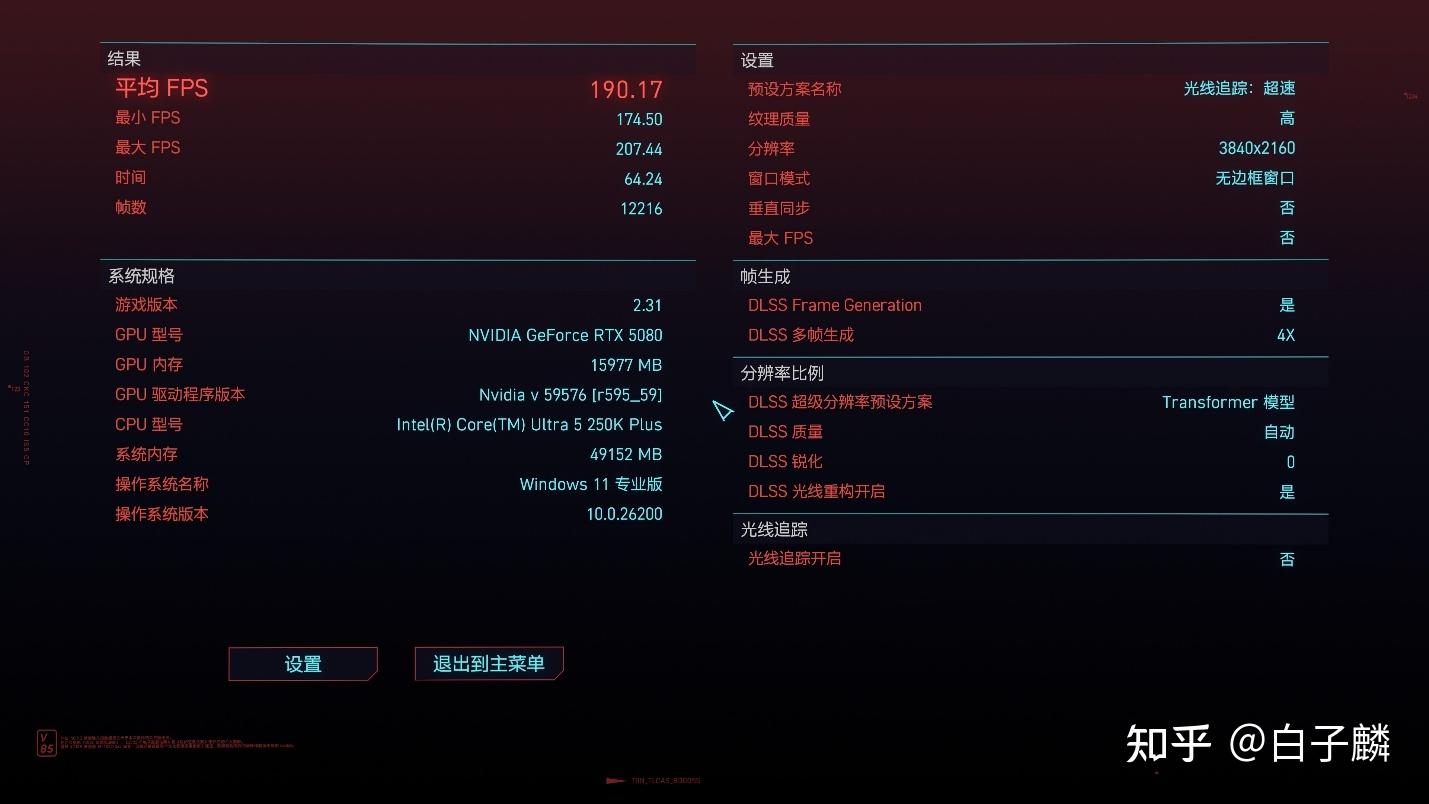
这种利用AI插帧技术的游戏环境,实际上对CPU内部的异步计算处理能力提出了极高的要求。250K Plus凭借其宽阔的前端调度器设计和改良后的D2D互联频率,展现出了卓越的数据承载余量,能够持续稳定地向显卡提交渲染指令,从而维持这些由AI生成的虚拟帧而不引入任何输入延迟或处理管线停滞。
因此,从市场经济学的“边际效用递减”规律和实际装机性价比(Price-to-Performance Ratio)的角度进行综合分析,业界一致认为,将这款标价200美元的酷睿Ultra 5 250K Plus处理器与华硕TUF等版本的RTX 5070 Ti显卡组合,达到了目前装机市场上的绝对“甜点位”与价值平衡点。这种搭配赋予了处理器恰到好处的操作空间,让其既能把5070 Ti的架构极限压榨到极致,又能为一套定位于1440p高刷新率(144Hz+)或4K标准刷新率(60Hz)的沉浸式游戏主机实现商业投资回报率的最大化。
战略生态的深度绑定:成为《三角洲行动》的官方合作赞助商
英特尔在消费市场的统治力,长期以来并非单纯依靠硅片物理性能的更迭,更依赖于其与全球顶尖软件开发商及游戏工作室在底层生态系统上的战略级联合研发。这一软件与硬件的强强联动,在英特尔与Team Jade工作室关于经典战术射击游戏《三角洲行动》(Delta Force)重启之作的深度商业与技术合作中得到了淋漓尽致的展现。
作为《三角洲行动》官方指定的合作赞助商与硬件技术伙伴,英特尔针对该游戏的开发周期和引擎特性进行了极高优先级的资源倾斜。《三角洲行动》拥有着极其复杂的物理引擎。该游戏主打的大规模“全面战场”(Warfare)模式复刻了极具标志性的海陆空多维度模拟对抗,不仅包含了海量的参战载具、高密度可破坏的环境几何模型,同时还在另一模式中深度重制了经典的2003版“黑鹰坠落”战役。这种包含宏大场景演算和高并发网络数据包收发的现代3D战争引擎,无疑会对GPU的光栅化流水线以及CPU底层的物理计算线程造成双重极限施压。
在早期的Alpha和Beta技术测试阶段中,专业社区与开发团队共同定位了影响玩家体验的几处渲染顽疾:特别是在极其激烈的战术交火区域,当场景内同时叠加大量体积烟雾(Volumetric Smoke)和爆炸物粒子光影效果时,系统会出现严重的帧生成时间骤增及视觉卡顿现象 34。通过后台深度的性能遥测(Telemetry)分析发现,在出现这些剧烈卡顿的瞬间,显卡的GPU占有率异常偏低,这明确指向了一个经典的驱动级渲染管线阻塞(Driver-level Bottleneck)或CPU Draw Call瓶颈,而非硬件本身的温度或算力极限。
得益于这种深入骨髓的赞助商合作关系,英特尔迅速响应。酷睿Ultra 5 250K Plus本身强悍的18核心设计为其提供了海量的冗余处理能力,能够硬扛这种未完善代码带来的多余开销,从底层规避了游戏引擎自身的代码瑕疵,彻底缓解了体积烟雾演算造成的CPU线程拥堵,保障了玩家在电竞对战中“平稳度(Playability)优于绝对帧率”这一最为核心的竞技诉求,真正做到了“沉浸式游戏”的需求。英特尔也成为了《三角洲行动》烽火联赛的行业合作伙伴。

步入AIPC纪元:NPU底层算力与樱桃AI生态闭环的重构
将专用的神经网络处理加速器(AI Accelerator)硬性集成至消费级桌面处理器之中,标志着整个个人计算机产业正式迈过分水岭,全面跨入所谓的“AIPC”(人工智能个人电脑)纪元。酷睿Ultra 5 250K Plus极具前瞻性地在采用6纳米工艺的SoC模块上,物理植入了一块专门的Intel AI Boost神经网络处理单元(NPU)。
NPU的硬件规范与边缘侧计算使命
这块嵌入式NPU的核心设计理念,是为了承载那些需要长时间持续运行、功率需求敏感且具有高度专门化特征的人工智能推理工作负载。在传统架构下,这些后台AI计算如果由传统的CPU核心去执行,将极大地占用多核并发资源,进而拖慢前台应用的响应速度;如果将这些推理丢给独立显卡(GPU)去处理,则又会频繁唤醒高达数百瓦的高功耗设备,造成极大的能源浪费。
此次集成的NPU3能在INT8精度下提供高达13 TOPS(每秒13万亿次操作)的物理峰值算力。在底层软件框架接口层面,它原生兼容并支持一系列主流量化及推理运行库,包括OpenVINO、WindowsML、DirectML、ONNX RT以及WebNN等,同时在硬件级别支持针对AI模型的网络稀疏性(Sparsity)优化以及Windows Studio Effects(如视频通话背景虚化、智能降噪)等系统原生AI特性。
樱桃AI(Cherry AI)平台:感知、决策与执行的本地化革命
要完全释放这种NPU算力的潜能,硬件生态系统必须依赖于同样出色的软件级载体。在这一语境下,樱桃AI(Cherry AI)平台(官方生态入口 樱桃AI语音助手 )成为了这颗处理器展现AI价值的最佳切入点。樱桃AI是一款专为AIPC深度定制开发的本地化人工智能语音交互助理,其核心设计哲学在于通过构建一套完全在本地设备上运行的“感知-决策-执行”封闭循环链条,彻底重塑人机交互(HCI)的体验模式,同时规避了依赖云端API调用所带来的严重网络延迟以及隐私数据泄露等合规性风险。
为了驱动樱桃AI顺畅运行,系统配置有着极其严格的软硬件门槛规范:
1. 系统内核要求:因为NPU的底层调用与线程调度机制高度依赖新一代Windows驱动模型,因此樱桃AI基于NPU的加速功能强制要求运行在Windows 11操作系统之上。
2. 内存容量带宽:考虑到系统需要在本地内存中驻留并加载经过量化压缩的大语言模型(LLM)权重矩阵文件,系统强制要求最低装配16 GB以上的系统运行内存。
3. 驱动协议规范:为了打通操作系统与物理NPU硬件之间的指令传输链路,搭载该处理器的平台必须安装版本号为32.0.100.4297或更高的英特尔官方NPU驱动程序。
在上述运行环境就绪后,樱桃AI通过融合英特尔提供的最新量化微调机制与推理技术模型,实现了惊人的毫秒级别极速响应体验。最关键的二阶影响在于,所有对自然语言的处理以及后续的语义推演,都直接被路由并卸载到了那颗拥有13 TOPS算力的专用NPU芯片上。这种算力的物理隔离,意味着250K Plus内部那18个真正负责渲染管线和系统操作的物理核心,在面对后台繁重的AI运算时,可以保持完全的零负担状态。
本地AI集成的第三阶生态影响与游戏内联动机制
樱桃AI生态的边界绝不仅限于像传统语音助手那样执行简单的问答或搜索任务。该系统通过获得操作系统的极高权限,已经与Windows底层的API钩子(Hooks)以及广大的国内PC应用市场建立了极其深度的融合控制机制。用户现在可以通过最为自然的口语化语音指令(甚至支持悬浮光标或快捷键等无感多模态唤醒机制),执行跨软件平台的复杂操作流。例如,这不仅涵盖了日常办公中对Microsoft Excel表格的语音调参或Word文档控制、以及录屏软件的起停动作,更延伸至娱乐领域的深度点播交互(如命令酷狗音乐检索冷门曲目,或唤醒并操作Bilibili视频客户端),甚至可以直接控制Windows的深层系统配置文件操作。
尤为值得一提的是,这种以NPU为底座的人工智能覆盖层,史无前例地打破了游戏执行进程与系统硬件监测软件之间的系统壁垒,带来了极其硬核的生态联动玩法。在一个典型的玩家使用场景中,当玩家正处于前文所述的《三角洲行动》(Delta Force)等节奏极快、高度紧张的第一人称竞技对抗环境中时,若感觉到画面出现异常掉帧,无需再像过去那样承担极高的风险切出游戏全屏画面,或者费心安装各种容易引发游戏反作弊引擎(Anti-Cheat Mechanisms)警报封号的第三方在屏显示(OSD)性能监控插件。玩家只需直接对着麦克风唤醒樱桃AI,提出类似于“当前处理器温度是多少?”或“现在的网络延迟极高吗?”的自然语言问题。樱桃AI会在后台调用硬件遥测传感器,通过语音或侧边栏的形式实时播报当前处理器的运行频率、封装温度以及实时的网络通信延迟。
这种无缝嵌入式的软硬件协同工作流完美诠释了NPU架构引入桌面端的核心价值。在没有NPU参与的情况下,倘若让CPU核心一边负责《三角洲行动》的高负荷渲染指令分发,一边同时在后台持续运行庞大的大语言推理模型,必然会导致CPU调度线程在瞬间发卡,从而不可避免地引发影响瞄准手感的严重帧时间抖动(Frame-time Spikes)。通过将所有感知、推理和执行的AI负载统统隔离在SoC模块内部专职的NPU管线中,酷睿Ultra 5 250K Plus做到了鱼与熊掌兼得——在赋予电脑本地全知全能的AI控制能力的同时,绝对不损失系统前台应用的一帧画质与一毫秒的计算响应,这种近乎完美的动态负载均衡能力,标志着个人计算机向真正智能化迈出的最坚实的一步。
总体而言,英特尔酷睿Ultra 5 250K Plus处理器绝非一次为了升级而升级的简单迭代;它通过架构革命与定价策略的重构,彻底重新校准了整个性能级桌面市场的价值衡量基准。凭借台积电3纳米的制程红利,英特尔将极极具前瞻性的模块化分离式架构塞入了一颗售价仅两百美元的芯片中;其18C18T的非对称异构集群提供了无与伦比的多核算力,而通过大幅拉高NGU与D2D频率至3.2GHz与3.0GHz,曾经困扰模块化设计的通信延迟被彻底粉碎。该芯片在提供159W超凡能效与Mini-ITX极致兼容性的同时,赋予了平台超越级别的24条PCIe扩展能力,确保其与从主流RTX 3060到发烧级RTX 5080等各类显卡的完美协作。再辅以通过《三角洲行动》赞助展示的底层生态支持、APO与IBOT技术带来的神奇软件驱动性能狂飙,以及由樱桃AI领衔、原生13 TOPS NPU提供算力底座的跨时代AIPC边缘智能交互体验,这款处理器无疑已成为该细分市场上最具破坏力且最无法被忽视的里程碑式产品。