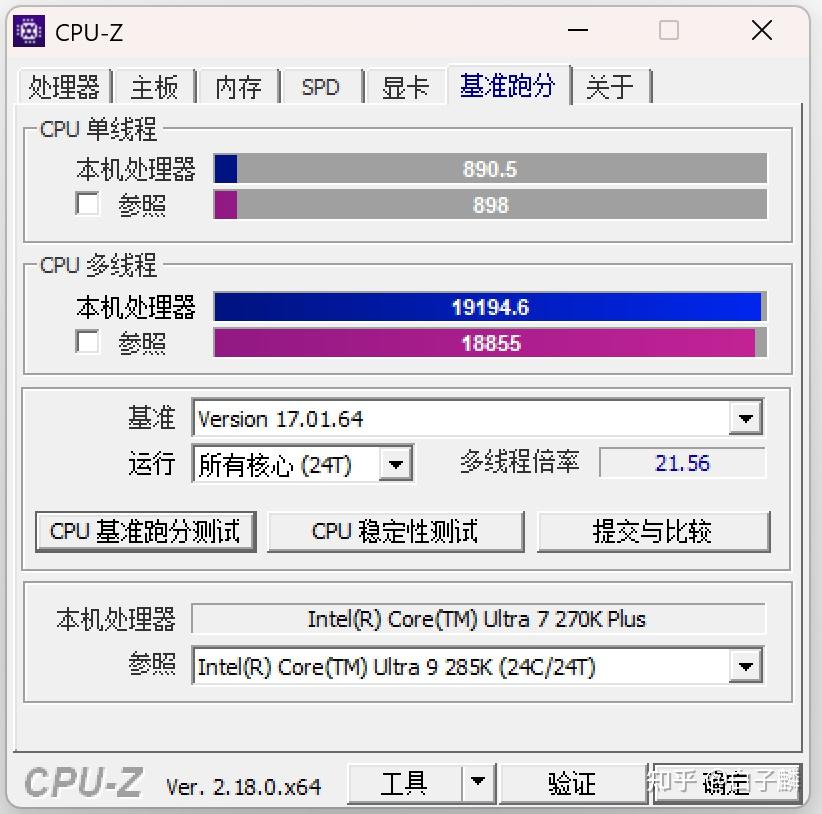
酷睿 Ultra 7 270K Plus 架构研判:次旗舰规格重塑与桌面计算平台的路线修正
一、产业语境:一代改款的逻辑转向
半导体领域的代际推进,长期以来遵循着一条相对稳定的路径:架构换代带来显著跃升,次年则以频率微调为主的“Refresh”版本维持市场热度。这套节奏在制程红利充沛的年代运转顺畅,但当晶体管尺寸逼近物理边界、单纯拉升频率的代价愈发高昂之后,“半代改款”的意义开始被重新审视。
2026 年 3 月下旬,英特尔将酷睿 Ultra 200S Plus 系列(代号 Arrow Lake Refresh)推至台前。与过往将工程资源集中于旗舰型号、靠一颗“KS”后缀产品争夺跑分榜的做法不同,这一次的方向发生了可见的偏移——次旗舰与中端产品线获得了更深层的物理规格重构。
酷睿 Ultra 7 270K Plus 便是这一转向的承载者。官方建议零售价划定在 2299 至 2699 元区间,这个位置并不试图与 AMD 仰仗 3D V-Cache 技术统治游戏帧率上沿的旗舰产品(如 Ryzen 9 9950X3D 或 Ryzen 7 9800X3D)正面交锋,而是将切入点置于 200 至 300 美元级别的主流性能地带——此处汇聚着大量进阶内容创作者、重度多任务用户以及对性能投入产出比颇为敏感的装机人群。
二、混合架构的再度演进:24C24T 与超线程的退却
2.1 核心规模膨胀的内在逻辑
计算平台的多线程吞吐,关键在于硅片层面的物理单元数量与调度效率。270K Plus 在核心配置上释放了 Arrow Lake-S 芯片的完整储备。相较其前代——2024 年问世的 Core Ultra 7 265K(8 性能核 + 12 能效核),270K Plus 将能效核数量增添四枚,构成 8 性能核与 16 能效核的阵型,总计 24 个物理核心。这一体量在规格表上已平齐上一代旗舰 Core Ultra 9 285K。
构架设计方面,Lion Cove 性能核与Skymont 能效核的组合传递了清晰的演进意图。一个值得留意的改动是 Lion Cove 性能核不再包含超线程单元。从技术沿革的角度审视,超线程诞生于执行单元偏窄、内存延迟偏高的时期,其职能是借助虚拟逻辑线程填补数据等待的间隙。但在当代处理器拥有宽裕的乱序执行资源、可观的片上缓存以及日益老练的分支预测器之后,单个物理核在单线程条件下已能达成相当的资源饱和度。
此次剥离超线程,并非以折损多任务能力为前提,而是通过增添能效核数量以及拉高两种核心的每周期指令吞吐来对冲。270K Plus 虽只提供 24 个线程,但这 24 个线程均对应独立的物理执行单元。从操作系统调度视角出发,这绕开了同核内两个逻辑线程争用缓存与执行端口所引发的延迟波动,有助于并发负载的连贯性与可预测性。
2.2 频率梯度与缓存配比
频率设定上,性能核基频 3.70 GHz,在 Turbo Boost 2.0 与 Turbo Boost Max 3.0 联合作用下,单核或少量核心负载时可触及 5.50 GHz。能效核的抬升幅度更为可观,基频 3.20 GHz,睿频上限较前代提升 100 MHz,来到 4.70 GHz。尽管该型号未纳入 Ultra 9 专属的 Thermal Velocity Boost 调节机制,但既有的频率梯度已可应对多数突发计算场景。
缓存子系统同样处于全规格启用状态:36 MB L3 智能缓存与总计 40 MB 的 L2 缓存。对照 265K(30 MB L3 + 36 MB L2),扩容后的片上存储有助于改善大规模数据在核心间的迁移表现,削减对主内存的往返访问。对于代码编译、数据库检索、高分辨率视频回放等场景,这一变动具备可量化的价值。
| 核心规格与架构对比参数 | Core Ultra 7 270K Plus | Core Ultra 5 250K Plus | Core Ultra 7 265K | Core Ultra 9 285K |
| 混合核心配置 (P核+E核) | 8P + 16E | 6P + 12E | 8P + 12E | 8P + 16E |
| 总物理线程数 | 24 | 18 | 20 | 24 |
| P核 基础频率 / 最高睿频 | 3.7 GHz / 5.5 GHz | 4.2 GHz / 5.3 GHz | 3.9 GHz / 5.5 GHz | 3.7 GHz / 5.7 GHz |
| E核 基础频率 / 最高睿频 | 3.2 GHz / 4.7 GHz | 3.3 GHz / 4.6 GHz | 3.3 GHz / 4.6 GHz | 3.2 GHz / 4.6 GHz |
| L3智能缓存 / L2缓存 | 36 MB / 40 MB | 30 MB / 30 MB | 30 MB / 36 MB | 36 MB / 40 MB |
| 官方基础热设计功耗 (TDP) | 125W | 125W | 125W | 125W |
2.3 生产力场景的实测比照
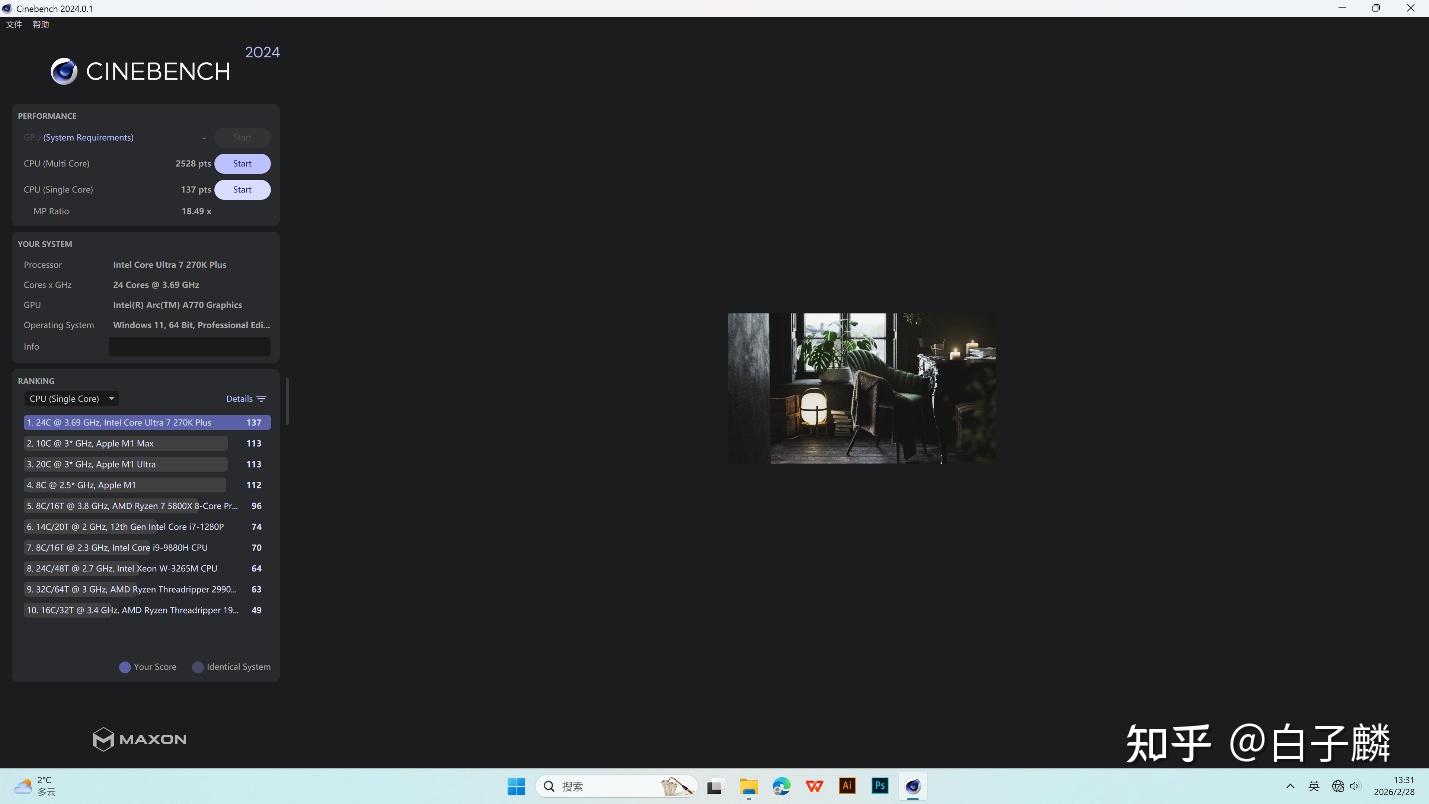
在 Cinebench 2024 的十分钟多核循环负载中,270K Plus 录得 2528 分。同价位区间的 Ryzen 7 9700X(Zen 5 架构)得分为 1307 分,Ryzen 5 9600X 为 943 分——核心数量的悬殊在此处直观转化为吞吐能力的差距。Cinebench 2026 多核测试中,270K Plus 越过万分门槛达到 10081 分,单核成绩落在 596 分。
这一势头在 Corona 12、KeyShot 2024、V-Ray 以及 Blender(BMW 27 场景)等渲染工具中同样可被观测。能效核集群在处理光线追踪计算网格时展现的并行密度,是构成此表现的重要支柱。
三、制程布局与能效路径:125W 框架内的模块化实践
3.1 解耦式封装的工艺分工
270K Plus 不再将所有功能单元收敛于单块硅片,转而采用基于功能模块(Tile)的分布式构造。各模块独立制造,经由硅中介层完成互联。
其中,承载 P 核与 E 核的计算模块采用台积电 N3B 工艺节点。横向衡量,这使其在制程基础上较 Ryzen 9000 系列所用的 4nm 节点占有一定优势。更紧缩的晶体管尺度带来开关能耗的下降与漏电流的收窄,为 125W 功耗框架内的性能输出提供了物理前提。
除计算模块外,SoC 模块(内存控制器、媒体引擎、基础 I/O)采用 6nm 工艺,集成图形模块(Xe LPG 架构)采用 5nm 工艺。这种将对性能与能效敏感的计算核心托付于更前沿节点、将外围逻辑保留于成熟节点的做法,在能效表现与成本控制之间寻得了平衡。
3.2 功耗管理与调节余地
200S Plus 系列在动态频率调节机制上有所精进。双 BCLK 调谐系统的纳入,使计算模块与 SoC 模块的时钟频率得以脱钩并各自独立微调,步进幅度为 16.6 MHz。辅以 OEM 层面的电压限制框架,用户在进行降压或超频操作时可获得更细腻的控制手感。
落脚到实际装机层面,这意味着无论是个人玩家还是渲染机群的运维方,使用常规等级的风冷或水冷散热即可让 270K Plus 在额定工况下长期平稳运作,周边散热开销与持续电能成本均得到压缩。
四、I/O 架构与平台延续性
4.1 LGA1851 的沿用与内存规格
270K Plus 继续使用 45mm × 37.5mm 的 LGA1851 封装。现有英特尔 800 系列芯片组(尤其是 Z890 主板)可直接承载该处理器,无需替换主板即可完成算力升级。部分板厂借此节点推出供电或网络配置微调的改款版本,但这属于市场区隔行为而非架构层面的硬性约束。
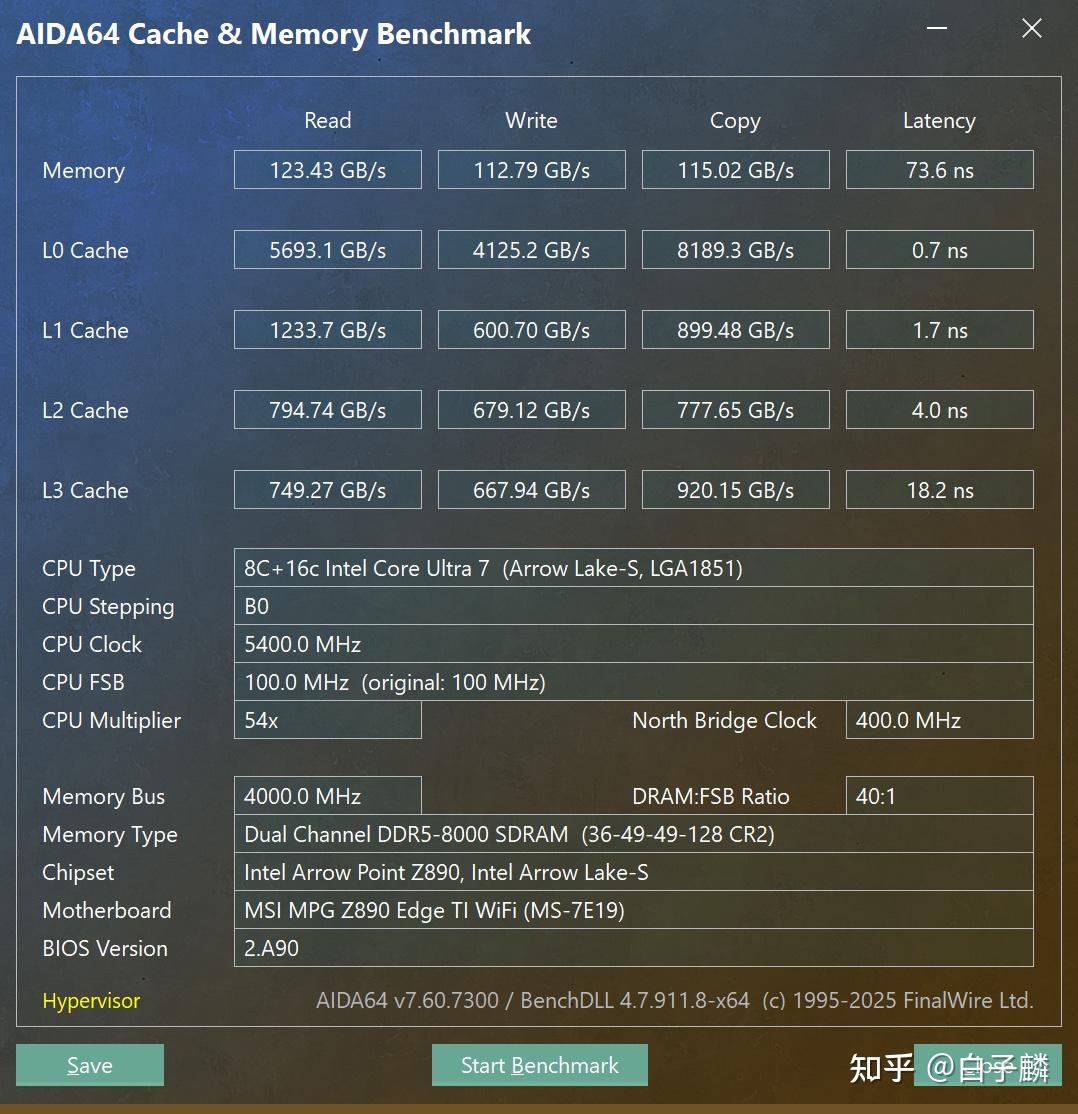
内存控制器一侧,原生支持的 DDR5 频率上界从 265K 的 6400 MT/s 抬升至 7200 MT/s,并加入对 4-Rank CUDIMM 技术的早期接纳。对于倚重内存带宽的应用(解压缩、内存数据库、部分内存敏感型游戏),这一提升具备直接的增益意义。
4.2 Die-to-Die 互联频率的上调
模块化设计中,不同硅片之间的数据交换路径是左右系统延迟的关键变量。初代 Arrow Lake 架构曾因模块分离导致内存访问与跨模块通信延迟有所上浮,在部分对延迟颇为介怀的电竞游戏中体现为帧率回落。
270K Plus 对此施行了底层修正:连接计算模块与 SoC 模块的 Die-to-Die 互联接口运行频率从 2.1 GHz 上调至 3.0 GHz。900 MHz 的内部总线频率增幅,扩展了模块间的数据传输截面,对前代架构中的延迟短板起到了填补作用。
4.3 PCIe 通道的物理分布与拓扑特点
在外部扩展一侧,Ultra 200S Plus 增添了 CPU 直出的 PCIe 5.0 通道数量,扩充了 PCIe 4.0 可用端口,并在芯片内集成雷电 4 控制器,同时预留了对离散式雷电 5 接口的支持空间。
有必要指出的是,由于 PCIe 通道被分配于不同的物理模块之上,存储设备的接入位置会对其底层表现产生扰动。当 NVMe 固态硬盘接入由 SoC 模块引出的 PCIe 通道时,数据须跨越模块互连总线,随机读写性能存在可观测的折损。若 M.2 插槽位置进一步后移(例如由单独 I/O 模块引出),数据路径需从计算模块出发,经 SoC 模块、I/O 模块内部环形总线,方可抵达 PCIe 控制器——多级节点的中转会在客观上累加接口延迟。这一现象是现阶段多芯片互连设计所面对的工程取舍,在日常使用中用户察觉有限,但它揭示了模块化架构在拓扑精进方向上仍有持续打磨的空间。
五、软件侧的补偿机制:APO 与 iBOT
5.1 APO:线程调度的接管逻辑
混合架构的调度繁复性,在 Windows 原生调度器面前时常体现为线程指派失序——物理碰撞运算的主线程被分配至能效核,或性能核被轻量级后台音频任务频繁唤醒。Intel Application Optimization (APO) 嵌于 DTT 驱动架构中,借助针对特定游戏定制的配置文件,在系统层面建立优先级接管。它能在游戏运行时识别并引导运算密集型线程锚定于性能核,绕开跨核心上下文切换的效能折损。在多数受支持游戏中,仅启用 APO 即可观测到 1% Low 帧的平顺化与平均帧率的回弹。
5.2 iBOT:二进制层级的指令重组
Intel Binary Optimization Tool (iBOT) 则走得更进一步。由于游戏需兼容跨世代的硬件底座,开发方在编译可执行文件时往往采用稳妥的通用编译器或较旧指令集,生成的机器码无法充分调用新架构中增设的执行端口、缓存预取策略与分支预测改进。
iBOT 运行于用户态,在程序加载入内存后的“后链接”阶段,直接对内存中的二进制指令序列施行动态重组。它不改动任何单条指令的运算结果,只调整指令进入流水线的次序,使其更适配 Arrow Lake 的缓存层级与执行特征。分支预测失准率下降、流水线空转减少,处理器的实际指令吞吐随之增长。
5.3 实测数据摘录
在 1080p 分辨率、搭配 RTX 5090 FE 以消除 GPU 瓶颈的测试条件下,iBOT 在受支持的游戏池中平均带来约 7.5% 至 8% 的帧率净增。
部分对指令排布颇为敏感的游戏中,效果更为醒目。以《古墓丽影:暗影》为例:仅开 APO 时平均帧率 293 FPS,1% Low 帧 205 FPS;启用 iBOT 后平均帧率升至 392 FPS(增幅约 35%),1% Low 帧达到 290 FPS(增幅约 41%)。
《漫威蜘蛛侠:重制版》开启该技术组合后平均帧率 218 FPS,1% Low 帧 214 FPS,帧生成曲线相当连贯。而在《赛博朋克 2077》中,iBOT 的介入只带来约 1.8% 的微小上扬,说明不同图形引擎对指令重组的响应幅度存在显著分化。这也解释了当前 iBOT 支持列表为何集中于经过实验室审慎验证的十余款作品。


| APO + iBOT 技术联合加速实测数据追踪 (1080p 分辨率基准) | 基础状态 (仅开启APO或关闭) (平均帧率 / 1%最低帧) | iBOT动态指令重排开启 (平均帧率 / 1%最低帧) | 实测性能增益预估 |
| 古墓丽影:暗影 (特定CPU密集测试场景) | 293 FPS / 205 FPS | 392 FPS / 290 FPS | 平均帧 +35% / 最低帧 +41% |
| 赛博朋克 2077 (高画质) | 146 FPS / 118 FPS | 149 FPS / 119 FPS | +1.8% ~ +2% |
| 无主之地 3 (高画质) | 206 FPS / 132 FPS | 211 FPS / 127 FPS | +2.4% |
| 漫威蜘蛛侠:重制版 (高画质) | - / - | 218 FPS / 214 FPS | 提供极其平滑的帧生成曲线 |
| 杀手 3 (迪拜场景 中画质) | 144 FPS / 104 FPS | 144 FPS / 108 FPS | 平均帧无变化 / 最低帧微升 |
六、定位评述与装机考量
酷睿 Ultra 7 270K Plus 可视为一份关于桌面计算平台前行方向的阶段性综述。它放下了以拉升频率换取账面指标的粗放做派,转而通过模块化封装、制程分工、内部互联调校以及软件层指令重构的复合手法,在 125W 功耗框架内搭建了一套兼顾多核产出与游戏发挥的方案。
在 Cinebench、Blender 等生产力基准中,24 核物理体量为其在同价位区间内争取到了相当扎实的多线程吞吐位次。LGA1851 接口的跨代沿袭、7200 MT/s 的内存接纳度、以及 Die-to-Die 互联频率的对症上调,一同构筑了平台的 I/O 底盘。PCIe 通道物理分布带来的局部存储性能折让,是现阶段多芯片互连设计的工程实情,但未动摇整体架构的可用根基。
APO 与 iBOT 的搭配则是这代平台较具辨识度的差异项。通过在内存层面截获并重排二进制指令,英特尔试探了一条绕开游戏制作方、由半导体原厂直接施行微架构靶向适配的路径。尽管当前与部分反作弊体系的兼容磨合仍在推进中,但《古墓丽影:暗影》等案例中逾三成的帧率跃升,已足以佐证“编译级适配”在后制程阶段的潜力。
面对 AMD 以 3D V-Cache 在游戏帧率板块构筑的壁垒,270K Plus 的回应是多向度的:它将物理多核体量、功耗管控策略与底层软件加速整合为一套差异化组合。对于使用场景横跨内容产出、重度多任务与游戏娱乐的装机群体而言,这颗处理器在其价格区间内提供了一个值得纳入考察范畴的选项。它同时释放了一个明确的信息——往后处理器性能的进一步挖潜,将不再单方面依赖制程的精进,硬件微架构与上层软件栈的协同纵深,正在成长为同等紧要的变量。