为什么英特尔和 AMD 不用类似苹果的统一内存而是坚持把内存单独出来?
"统一内存主机"这个品类,在过去一年从技术概念变成了京东货架上的真实商品。CPU和GPU共享同一池内存,不再需要手动管理数据搬运——这个听起来很美好的设想,AMD和NVIDIA给出了两套截然不同的答案。
AMD推出了AI Max+395(Strix Halo),把Zen 5 CPU核心和RDNA 3.5 GPU核心封装在一起,共享最高128GB LPDDR5X内存。NVIDIA则拿出了DGX Spark(Grace Blackwell GB10),用ARM架构的Grace CPU搭配Blackwell GPU,同样配备128GB统一内存,但走的是纯AI开发生态路线。
京东上这两类产品已经超过10款,价格从两万到三万七不等。算上政府补贴,最便宜的128GB统一内存AI工作站只要两万出头。128GB统一内存到底够不够用?AMD和NVIDIA的方案各自适合谁?
本文所有产品数据均来自京东实时售价(2026年6月1日),技术资料来自统一内存架构分析。
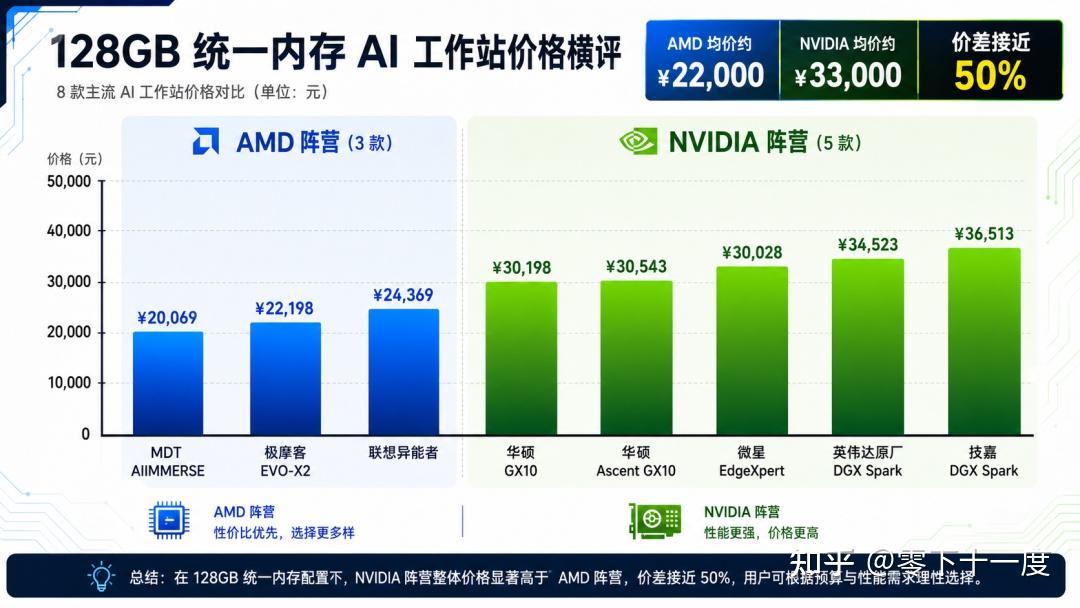
本文数据来源:京东搜索"128GB AI 工作站"结果页(2026年6月1日),涵盖极摩客、MDT、联想异能者、华硕、微星、技嘉、英伟达原厂共8款产品。AMD平台3款,NVIDIA平台5款。
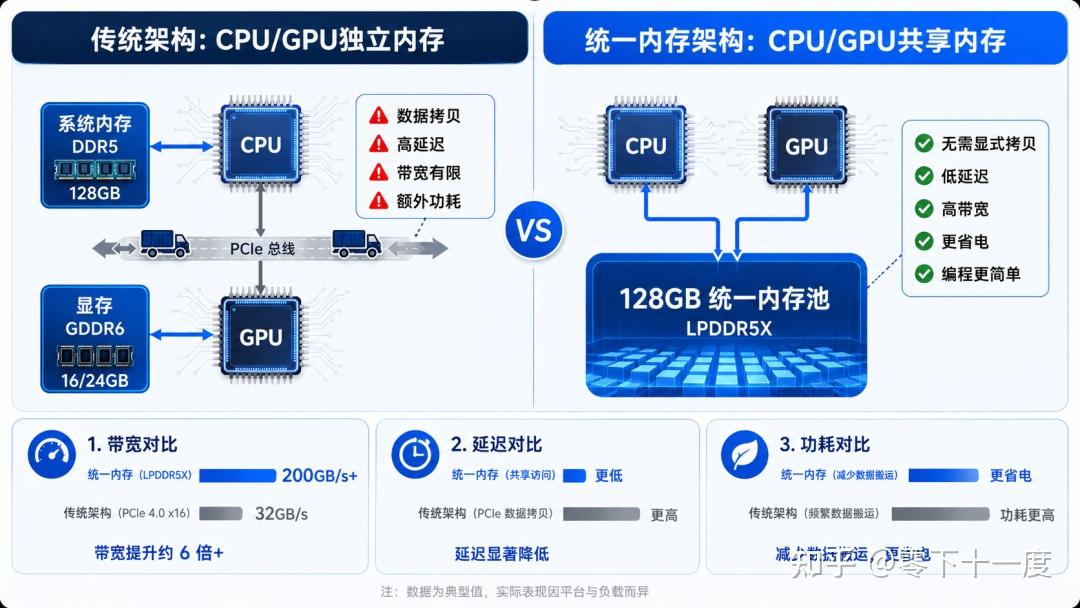
统一内存是什么,为什么突然火了
统一内存主机这个概念听起来有些抽象,但原理并不复杂。传统电脑里,CPU用自己的内存条(DDR),GPU用自己的显存(VRAM),两者之间通过PCIe总线传输数据。相当于两个仓库之间靠一辆小卡车来回运货——带宽有限、延迟高、还费电。AI大模型时代,模型参数动辄几十GB,在内存和显存之间搬运一次的时间成本不可接受。
统一内存(Unified Memory)打破了这种隔离。CPU和GPU共享同一个物理内存池,谁需要数据谁直接访问,不再需要显式拷贝。编程上也更简单——开发者不需要写cudaMemcpy之类的数据传输代码,代码更简洁,维护成本更低。
AMD AI Max+395(Strix Halo)集成了Zen 5 CPU和RDNA 3.5 GPU,支持最高128GB LPDDR5X-8533内存,GPU可直接访问全部128GB容量。这意味着70B参数级别的大模型可以在本地流畅运行。
NVIDIA的DGX Spark(Grace Blackwell GB10)走的是另一条技术路线。Grace CPU采用ARM架构,Blackwell GPU集成了最新的Tensor Core和Transformer Engine。同样是128GB统一内存,但NVIDIA的方案更侧重AI推理性能,FP4精度下可达1000 TOPS。
从功耗角度来看,统一内存减少了数据搬运的开销。传统PCIe传输在密集计算场景下可能消耗数十瓦的功耗,统一内存架构让CPU和GPU直接访问同一块内存,这部分能耗就省下来了。
统一内存对普通用户意味着"买一台就够了"——不需要分别纠结内存大小和显存大小,128GB足够从日常办公到AI开发一机搞定。
128GB统一内存能跑什么模型?70B参数模型量化后大约需要40-50GB,加载后还有70-80GB剩余用于系统和数据处理。你可以同时运行一个70B模型做推理,再跑几个小型模型做辅助任务。相比之下,16GB显存的传统显卡连70B模型的量化版本都装不下。
统一内存的另一个容易被忽略的优势是数据安全。所有数据在本地内存中处理,不需要上传到云端。对于金融、医疗等涉及敏感数据的企业用户,本地部署大模型不仅消除了数据泄露的风险,也规避了合规审查的复杂性。
AMD AI Max+395阵营:性价比之选
AMD方案的统一内存主机目前有三款主力产品在京东销售,全部搭载AI Max+395(Strix Halo)平台。基础配置出奇一致:128GB LPDDR5X + 2TB SSD,差异主要体现在品牌、形态和定价策略上。
极摩客GMK EVO-X2定价¥22,198,是AMD阵营中体积最小的产品。采用迷你主机形态,大约是两台Mac mini叠放的大小,散热设计扎实。适合桌面空间有限的个人用户。
MDT AIIMMERSE AI智能体一体机政府补贴价仅¥20,069,是目前京东上最便宜的128GB统一内存产品。原价¥25,999,配备16核32线程CPU,8533MHz高频内存,自带屏幕开箱即用。
联想异能者AI大模型工作站定价¥24,369(国补后),是AMD阵营中最贵的。品牌溢价带来了更好的售后保障和BIOS优化,企业采购倾向这个选择。
极摩客 EVO-X2:¥22,198,体积最小,适合桌面空间有限的个人用户
MDT AIIMMERSE:¥20,069(补贴价),性价比最高,自带屏幕适合首次尝试
联想异能者:¥24,369(国补后),品牌可靠,适合企业采购
AMD三款产品的价格区间为¥20,069-¥24,369。全部配备128GB LPDDR5X-8533内存和2TB NVMe SSD,AI综合算力约50-60 TOPS。
AMD方案的最大优势是"够用且便宜"。50-60 TOPS的算力覆盖了大多数AI推理场景——本地运行7B到70B参数的开源模型、做RAG应用、跑SD图片生成,都没有问题。如果你不是每天训练模型的专业AI开发者,AMD方案可能是更理性的选择。

NVIDIA DGX Spark阵营:生态为王
NVIDIA的DGX Spark系列目前有5款产品在京东销售,全部基于GB10 Grace Blackwell平台。相比AMD阵营的三款产品,NVIDIA的选择更丰富,价格跨度也更大。
华硕有两款产品:GX10便携式AI开发者迷你主机到手价¥30,543(128GB+1TB),以及Ascent GX10 DGX SPARK定价¥30,198。两款核心配置接近,差别体现在散热设计和外观上。
英伟达原厂DGX Spark定价¥34,523(128GB+4TB),搭载DGX操作系统,基于Ubuntu Linux深度定制,预装了NVIDIA AI Enterprise套件。从开机到开始训练模型,全程不需要折腾驱动和库版本。
微星EdgeXpert DGX Spark到手价¥33,028(128GB+4TB),散热模组用料扎实,适合长时间高负载运行。技嘉DGX Spark定价¥36,513,是京东上最贵的128GB统一内存产品。
最便宜方案
华硕GX10
¥30,198
最贵方案
技嘉DGX Spark
¥36,513
NVIDIA阵营的核心竞争力是CUDA生态。经过近二十年的积累,几乎所有主流AI框架都在CUDA上做了深度优化。写好的代码可以直接推到云端A100/H100集群继续训练,本地开发和云端生产环境完全一致。
CUDA生态近二十年积累,几乎所有主流AI框架都做了深度优化。DGX Spark的开箱体验远超通用硬件自己装系统的方案。

价格与性能横评:一张表看清差异
如果你正在寻找一台128gb内存电脑,AMD和NVIDIA的方案是目前市场上最主流的两条路线。现在我们把两个阵营拉到一起做横向对比。虽然两边都叫"128GB统一内存",但从产品定位到目标用户都有明显差异。
从价格来看,AMD方案有明显优势。MDT AIIMMERSE补贴价¥20,069,比最便宜的NVIDIA方案(华硕GX10的¥30,198)便宜了整整一万元。三款AMD产品的均价约¥22,000,五款NVIDIA产品的均价约¥33,000,价差接近50%。
AMD方案均价
¥22,000
NVIDIA方案均价
¥33,000
从AI算力看,NVIDIA方案在纸面上遥遥领先。DGX Spark的FP4精度算力为1000 TOPS,远高于AMD方案的50-60 TOPS。但这个对比需要谨慎看待——FP4是NVIDIA Blackwell架构引入的低精度推理格式,在FP16/FP32精度下差距会显著缩小。
从内存规格看,AMD的LPDDR5X-8533提供了更高的理论带宽(超过200GB/s),NVIDIA方案更注重低延迟。从存储看,AMD三款产品都标配2TB SSD,NVIDIA阵营从1TB到4TB不等。从功耗看,统一内存架构整体功耗远低于同性能水平的独立CPU+GPU组合。
从扩展性来看,统一内存主机不如传统DIY台式机——内存焊在主板上的LPDDR5X不能后期升级。从软件生态看,NVIDIA的CUDA有近二十年积累,AMD的ROCm虽然进步很快但部分冷门模型兼容性仍需验证。从二手保值看,NVIDIA产品通常更保值,二手市场需求更旺盛。
应用场景怎么选
大内存工作站的价值,最终由你的使用场景决定。AMD和NVIDIA的方案各有擅长领域,选错了可能多花冤枉钱或者性能不够用。
AI推理用户 → AMD方案:本地运行DeepSeek R1、Llama 3等开源模型,或者做RAG应用,50-60 TOPS的算力配合128GB统一内存完全够用。省下的一万多元可以购买更多云服务时长。
AI开发者 → NVIDIA方案:需要训练和微调模型的话,CUDA生态的兼容性优势是最大的效率提升。DGX操作系统预装了AI开发工具链,本地开发后直接推到云端集群训练,工作流无缝衔接。
数据科学 → 两者均可:128GB统一内存可以加载大型数据集到内存处理,Pandas、NumPy运行效率远超传统电脑。AMD方案的性价比在此场景更有吸引力。
视频剪辑/3D建模 → NVIDIA优势:Adobe Premiere、DaVinci Resolve等软件对CUDA有深度优化,Blender、Unreal Engine等3D软件在NVIDIA上渲染速度和稳定性更优。
如果你是个人AI爱好者,平时玩玩Stable Diffusion、跑跑开源模型,偶尔做点内容创作——AMD方案是更平衡的选择。性能够用、价格实惠、功耗低噪音小,放在家里书房不突兀。
从软件兼容性来看,AMD需要额外注意。虽然ROCm生态在快速进步,但确实有一些冷门框架只支持CUDA。购买前建议先列出你日常使用的AI工具清单,确认它们对ROCm的支持情况。

选购建议:从预算出发
目前这些128GB统一内存产品都采用了迷你主机工作站形态。迷你主机 128g内存这个细分品类正在成为AI工作站的标配——体积只有传统台式机的十分之一,功耗只有一半甚至更低,性能却足以运行70B参数的大模型。
没有绝对的"更好",只有"更适合"。AMD用更低的价格提供了足够强的AI推理能力,NVIDIA用成熟的生态锁定了专业开发市场。
预算两万出头 → AMD AI Max+395
极摩客 EVO-X2(¥22,198):体积最小,适合桌面空间有限的个人用户
MDT AIIMMERSE(¥20,069补贴价):性价比最高,自带Win11和配套平台适合首次尝试
联想异能者(¥24,369国补后):品牌可靠,适合企业采购有售后需求
预算三万以上 → NVIDIA DGX Spark
华硕 GX10(¥30,198):性价比最高,适合入门AI开发者
微星 EdgeXpert(¥33,028):散热均衡,适合高负载长期运行
英伟达原厂 DGX Spark(¥34,523):系统优化最好,适合追求完整体验
技嘉 DGX Spark(¥36,513):配置最旗舰,适合预算充裕的用户
ARM架构兼容性需要留意。NVIDIA DGX Spark的Grace CPU是ARM架构,虽然大多数AI工具已支持ARM Linux,但部分x86软件可能无法运行。AMD的x86架构兼容性无任何顾虑。
购买渠道方面,建议优先选择京东自营或官方旗舰店购买,售后更有保障。重视品牌和售后选联想或英伟达原厂,重视性价比选MDT或华硕,重视做工选极摩客或技嘉,重视散热选微星。
这个品类还在快速迭代中。从2025到2026年,统一内存AI工作站从概念走向量产,价格逐步下探。如果你现在就有明确需求可以直接入手,如果需求不迫切可以再观望半年——随着竞争加剧,产品会更丰富,价格也更友好。