目前性能最强大的核显相当于哪个独显?
现在是 2026 年 6 月 30 日。
GB20B(GB10B) 是目前最强的“核显”。
它的浮点性能相当于独显里的 RTX 5070,实测稀疏化 FP4 浮点性能是 1000+ TFLOPS,采用台积电 5nm 节点里的 4N 制程,基于 NVIDIA RTX Blackwell 微架构,计算能力为 CC 12.1,和 Grace CPU 之间用 600GB/s 的 NVLink 连接,SoC 内存带宽达到 300GB/s。
拥有第四代光线追踪内核,第五代张量内核,这两个东西完爆所有非 NVIDIA 系的“核显”。
支持 AV1 硬件编解码、HEVC 4:2:2 硬件编解码。
无论是渲染性能还是 AI 运算、多媒体编辑,在目前的核显中无出其右。
例如 AI 计算,跑 Diffusion 的话,没有任何核显能与之匹敌,跑 LLM 的话,内存带宽不如苹果顶配,但是现在有 DiffusionGemma、DSpark、MTP 等各种越来越多依赖算力的 LLM 加速方案,GB20B 这样的方案跑 LLM 也不遑多让,而且因为支持 CUDA,很多 AI 方案出来基本上能做到 day0 部署,例如 DSpark 基本上当天就能看到双 DGX Spark 用 DSpark 跑 Deepseek V4 Flash,生成速度达到每秒 65 Toks。
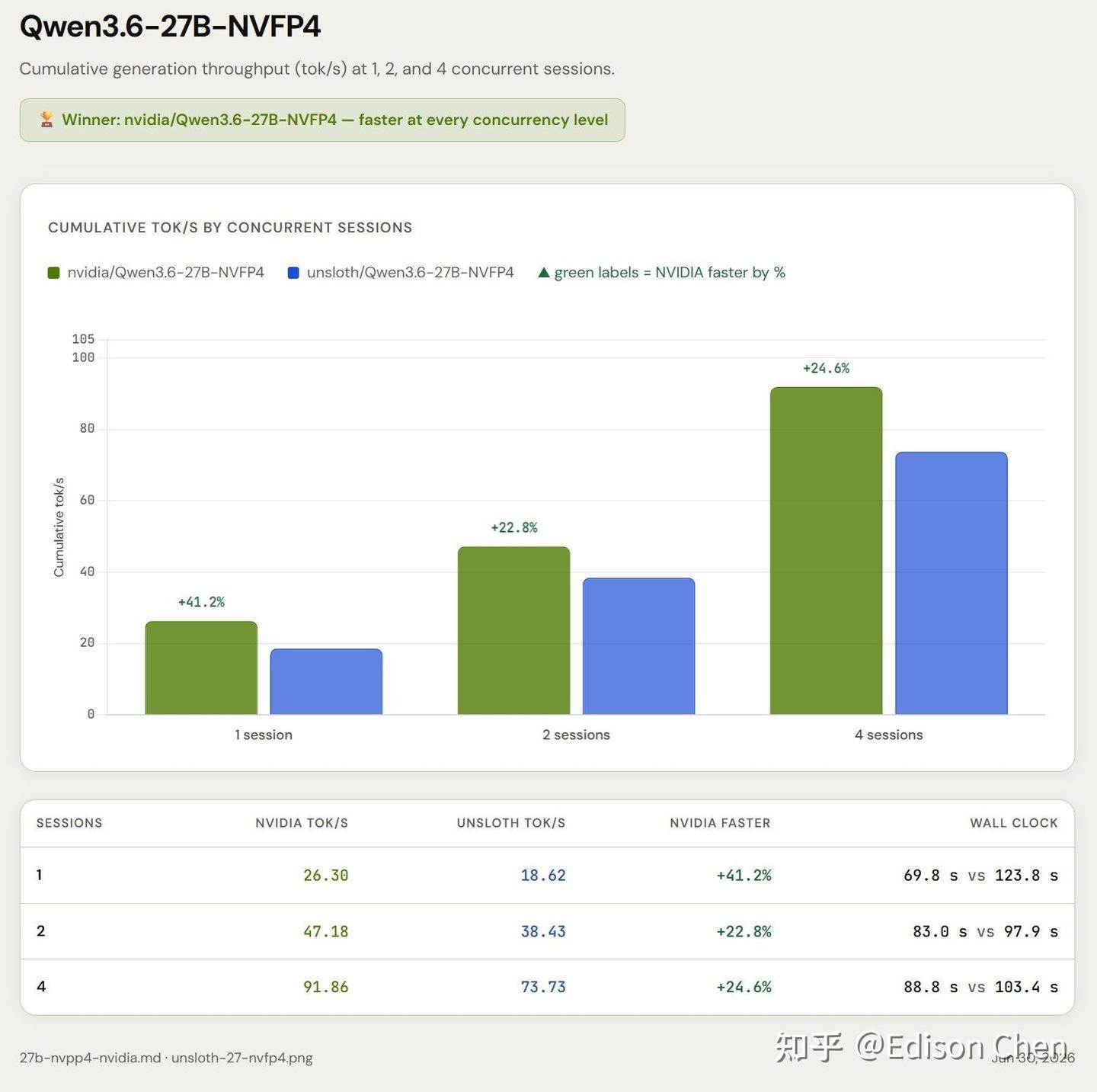
至于像 Qwen 3.6 27B 这样的稠密模型,使用 NVFP4 效果显著,能做到单 DGX Spark 单用户每秒 26.3 的生成速度(四用户能达到 92 Toks/s),这应该是理论值的 1.3 倍了:
至于 DiffusionGemma,GB10B 面对所有核显就好像欺负小孩一样,US 里随随便便都每秒 800~1000 Toks/。
编辑于 2026-07-01 · 著作权归作者所有