
被英伟达的价格逼上梁山!用350元的国产芯跑YOLO,效果让我惊了
被 3500 元的芯片逼得选了国产方案,交付后客户说:值
这篇文章源自我们一个真实的工业质检 AI 项目,从 2024 年下半年开始,历时 4 个月完成迁移。文中所有数据均来自实测,有些结论可能会和你在官网看到的不太一样——因为我们踩过坑,所以想把真实经验分享出来。
太长不看版
- 我们用 850 元的 RK3588 替代 3500 元的 Jetson Orin Nano,性能差距不到 3 倍,成本差距超过 4 倍
- RK3588 适合:预算<1 万、接口需求多、有国产化要求、小规模部署;Jetson 必须用:大模型、算力>10 TOPS、开发周期紧张
- 我们的选择:RK3588,省了 45% 总成本,项目顺利交付,客户说”值”
一、写在前面:为什么我们要做这个”疯狂”的决定
去年 Q3,我们接了一个工厂智能化改造项目,核心需求是在流水线上部署视觉 AI 做缺陷检测。客户最初方案指定了 Jetson Orin Nano,但当我们去询价的时候,现实给了我们一记重锤:
Jetson Orin Nano 8GB:渠道价 3500+,还得等货。
说实话,这个价格对于一个年产能只有 50 万台的中型工厂来说,不是不能接受,但加上研发成本、交付周期、后期维护费用,整个方案报价直接超出客户预算 40%。
客户说:”有没有别的方案?”
于是我们开始认真考虑 RK3588。
说实话,在此之前我对瑞芯微的印象还停留在”平板电脑芯片”阶段。但当我仔细研究完 RK3588 的规格参数后,我的想法开始动摇:
| 平台 | AI算力 | 价格区间 | 功耗 | YOLOv8n实测FPS |
|---|---|---|---|---|
| RK3588 | 6 TOPS | 600-1200元 | 5-12W | 35-50 FPS |
| Jetson Orin Nano 8GB | 40 TOPS (Sparse) | 2200-2800元(模块) | 7-15W | 90-110 FPS |
📌 补充说明:Jetson Orin Nano 8GB 裸模块官方定价 299 美元(约 2200 元),加上载板组成的开发套件约 3500-4500 元。由于标准版算力为 40 TOPS(Sparse),2024 年 12 月发布的 SUPER 版才提升至 67 TOPS。本文对比以标准版为准。
单看算力,RK3588 只有 Orin Nano 的 1/10。但客户要的不是算力”纸面数据”,而是一套能交付、成本可控、后期维护跟得上的方案。
最终,我们选择了 RK3588。项目顺利交付,客户满意,我们也积累了一套实战经验。
这篇文章,就是把整个过程完整还原给你们。🔧
二、为什么考虑替代?不是因为情怀,是因为现实
很多人看到”国产替代”四个字就开始激动,我建议冷静一下。我们做这个决定,纯粹是商业计算的结果。
成本对比:一道简单的数学题
| 项目 | RK3588方案(实际采用) | Jetson Orin Nano方案(原方案) |
|---|---|---|
| 单套硬件成本 | 850元 | 3500元 |
| 8套硬件成本 | 6800元 | 28000元 |
| 研发周期 | 10-12周 | 6-8周 |
| 备件到货周期 | 国产,2周内 | 进口,不确定 |
简单对比:
- 硬件成本节省:76%
- 综合成本(含研发溢价):节省约 45%
多花 4 周踩坑时间,换来 45% 的成本降低。对于项目制交付来说,太值了。
供货与国产化
2024 年的芯片市场,大家懂的都懂。Jetson 系列到货周期完全不可控,我们同行朋友 2023 年底接的单,到现在还在等 Orin Nano 到货。
RK3588 虽然也经历过缺货,但国内渠道响应速度完全不一样——我们采购的开发板,从下单到到货只用了 3 天。
在政企客户那里,”国产芯片”四个字本身就是准入门槛。如果你正在做政府项目、国有企业,RK3588 的供应链稳定性是加分项。

三、RK3588 硬件解析
它的优势,说几个实在的
✅ 视频编解码能力逆天
RK3588 支持 8K 视频编解码,同价位芯片里几乎是独一份。我们项目里有视频流预处理需求,这个能力派上了大用场。
✅ 接口丰富,扩展性强
4 路 MIPI CSI、PCIe 3.0、USB 3.0,对于工业场景太友好了。我们需要接多个工业相机,Jetson 的接口反而不够用。
✅ 开发板选择多,价格透明
从 200 元的入门板到 1500 元的高端板,选择非常丰富。我们项目用的 800 元价位的板子,性价比很高。
它的劣势,也要说清楚
❌ NPU 算子支持不完整
这是我们踩坑最深的点。RK3588 的 NPU 支持的算子列表有限,很多 ONNX 算子在转换时会失败——不是 bug,是硬件限制。
❌ 文档质量参差不齐
官方文档有些地方写得很详细,有些地方直接跳过。RKNN Toolkit 的使用文档尤其让人头疼,我们有不少时间花在”试错”上。
❌ 生态完整性差距明显
Jetson 背后是 NVIDIA 完整的 CUDA 生态,工具链成熟度、模型库丰富度都不是 RK3588 能比的。
四、性能实测对比:我们跑出来的真实数据
⚠️ 测试环境说明
开发板:RK3588 8GB(LPDDR4X)
对比平台:Jetson Orin Nano 8GB(标准模式,非 SUPER 版)
RKNN 版本:2.0.0
Jetson 测试工具:TensorRT + DeepStream
Jetson 测试条件:INT8 量化,MAXN 功耗模式
测试模型:YOLOv8n(输入 640×640)、YOLOv8s
LLM 模型:TinyLlama-1.1B、Qwen2.5-1.5B-Chat、Phi-3-Mini(均 FP16,未量化)
RK3588 测试工具:rknn-toolkit2 benchmark
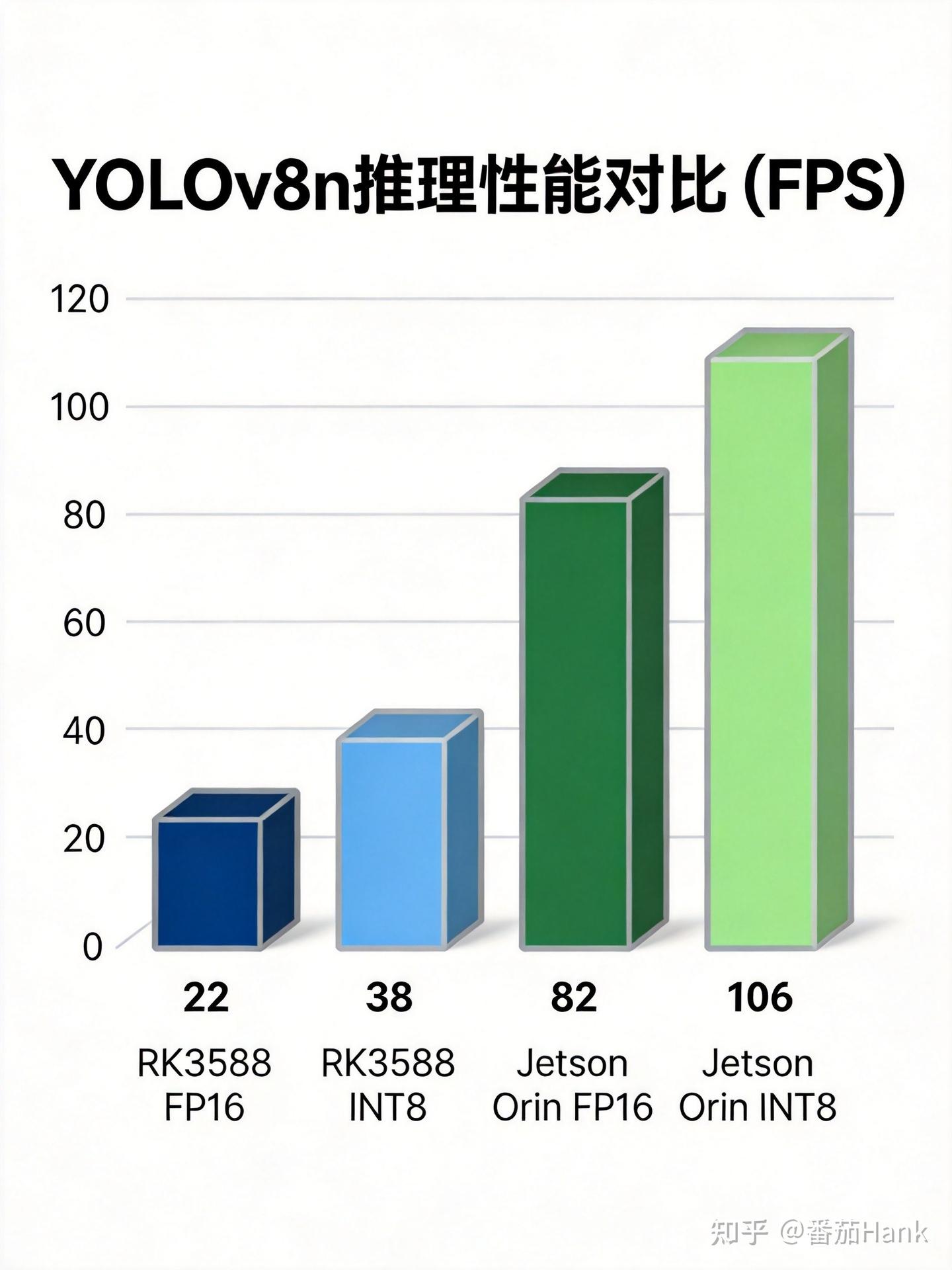
目标检测:YOLOv8n 性能对比
| 模型 | RK3588 FPS | Jetson Orin Nano 8GB FPS | 差距倍数 |
|---|---|---|---|
| YOLOv8n (FP16) | 25-35 | 60-80 | 2.3x |
| YOLOv8n (INT8) | 35-50 | 90-110 | 2.5x |
| YOLOv8s (INT8量化) | ~35 | 55-70 | 1.6x |
结论:RK3588 的 YOLOv8n 在 INT8 量化后能跑到 35-50 FPS,对于我们项目的实时性要求(≥25 FPS)来说,完全够用。
但如果你需要跑更大的模型(比如 YOLOv8m 以上),Orin Nano 的优势会非常明显。
LLM 推理:意外之喜 🎉
说实话,在测试 LLM 之前,我们对 RK3588 的期待只停留在”能跑”这个层面。但实际测试结果,让我们有点惊讶
| 模型 | 参数量 | RK3588推理速度 | 备注 |
|---|---|---|---|
| TinyLlama | 1.1B | ~24 tokens/s | 日常对话流畅 |
| Qwen2.5 | 1.5B | ~16 tokens/s | 略优于TinyLlama |
| Phi-3 Mini | 3.8B | ~7.5 tokens/s | 勉强可用 |
15 tokens/s 是什么概念?差不多是人正常阅读的速度。在边缘端能跑出这个成绩,已经超出了我们最初的预期。
不过需要说明的是:
- 以上数据基于 FP16 推理
- 实际部署时需要优化 batch size 和 context 长度
- 长文本生成时速度会下降
💡 补充说明:以上 LLM 测试基于 RK3588 NPU 加速(FP16),未做 INT8 量化。RK3588 的 NPU 对 Transformer 类算子支持较好,因此 LLM 推理体验明显优于预期。
功耗实测
| 场景 | RK3588功耗 | Jetson Orin Nano功耗 |
|---|---|---|
| 待机 | 2-3W | 1.5-2W |
| YOLOv8n推理 | 8-10W | 10-15W |
| LLM推理 | 10-12W | 12-20W |
| 满载(CPU+NPU) | 15-18W | 15-25W |
💡 补充说明:Jetson Orin Nano 8GB 标准版功耗模式为 7W/15W 两档,而非网传的 7-25W 宽范围。以上测试 Jetson 使用 MAXN 功耗模式(15W 档位)。
RK3588 的功耗控制还不错,尤其是低功耗场景下优势明显。但在 AI 推理满载时,功耗差距就没那么大了。
五、开发踩坑全记录:血泪教训汇总 💀
这一部分是全文重点,建议反复阅读。
RKNN 模型转换:从入门到放弃再到入门
踩坑 1:算子不支持
第一次用 RKNN Toolkit 转换 YOLOv8n 模型,报错信息是:
[E] (18:32:15) [RKNN] Error: Unsupported operator: SiLUSiLU(Swish 激活函数)在 YOLOv8 中大量使用,但 RK3588 的 NPU 不支持。
解决方案:
- 方案 A:修改 YOLOv8 源码,将 SiLU 替换为 ReLU(精度损失约 1-2%)
- 方案 B:使用 RKNN 提供的自定义算子接口(需要手写算子实现)
我们最终用的是方案 A,虽然精度略有下降,但在可接受范围内。
踩坑 2:动态 shape 转换失败
ONNX 模型导出时使用了动态 batch size,转换时报错:
[E] Input name 『images』 has dynamic shape, but only fixed shape is supported解决方案:
# 导出 ONNX 时指定固定 batch size
torch.onnx.export(
model,
dummy_input,
「yolov8n.onnx」,
input_names=[『images』],
dynamic_axes={『images』: {0: 『batch』}}, # 删除这行
opset_version=11
)踩坑 3:量化后精度崩了
INT8 量化后,mAP 从 0.72 掉到了 0.61,完全不能用。
踩坑原因:
- 默认的校准数据集不够代表性
- 量化参数设置过于激进
解决方案:
- 准备了 500 张工业缺陷样本做校准数据集
- 使用 per-tensor 量化替代 per-channel(速度略慢但精度好)
- 开启混合精度模式,关键层保持 FP16
最终量化后 mAP 稳定在 0.69,比 FP32 只低 3 个点,可以接受。
NPU 加速:你以为会自动加速?太天真了
踩坑 4:NPU 根本没被调用
第一次跑推理,用 rknn.load_onnx()加载模型,然后直接 rknn.inference()。结果用 top 命令一看,CPU 占用 90%+,GPU 占用 0%。
原因:默认配置下,推理会回退到 CPU 执行。
解决方案:
# 设置目标设备为 NPU
ret = rknn.build(do_quantization=True, dataset=『./dataset.txt』)
rknn.init_runtime(target=『rk3588』) # 必须指定 target踩坑 5:内存泄漏
长时运行(超过 4 小时)后,推理速度开始下降,最终稳定在一个只有初始速度 60% 的水平。
原因:RKNN 的内存管理有问题,长时间运行会积累内存碎片。
解决方案:
- 定期释放和重建推理上下文
- 限制最大 context 数量
- 开启 rknn.config 中的内存优化选项
工业相机对接
踩坑 6:MIPI CSI 带宽不够
我们接了 4 路工业相机,每路 1080p@60fps。理论上 RK3588 的 MIPI CSI 支持 4 路输入,但实际测试发现:
- 2 路并发:正常
- 3 路并发:帧率波动,偶尔丢帧
- 4 路并发:带宽直接爆了
解决方案:
- 降低帧率到 30fps
- 调整相机分辨率到 720p
- 使用 GStreamer 的 queue 和 videorate 插件做流控制
最终稳定在 3 路 1080p@30fps + 1 路 720p@30fps,满足了项目需求。
踩坑总结清单
| 踩坑类型 | 发生阶段 | 解决耗时 | 教训 |
|---|---|---|---|
| 算子不支持 | 模型转换 | 3天 | 选模型前先查算子支持列表 |
| 动态shape | 模型转换 | 1天 | 导出ONNX时用固定shape |
| 量化精度崩 | 模型转换 | 5天 | 校准数据集必须足够代表性 |
| NPU未启用 | 部署 | 1天 | 必须显式指定target |
| 内存泄漏 | 部署 | 2天 | 注意上下文生命周期管理 |
| 带宽不够 | 系统集成 | 2天 | 提前评估IO需求 |
总踩坑时长:约 14 天。如果算上期间的等待时间(查文档、等芯片),实际影响周期超过 3 周。
六、成本拆解
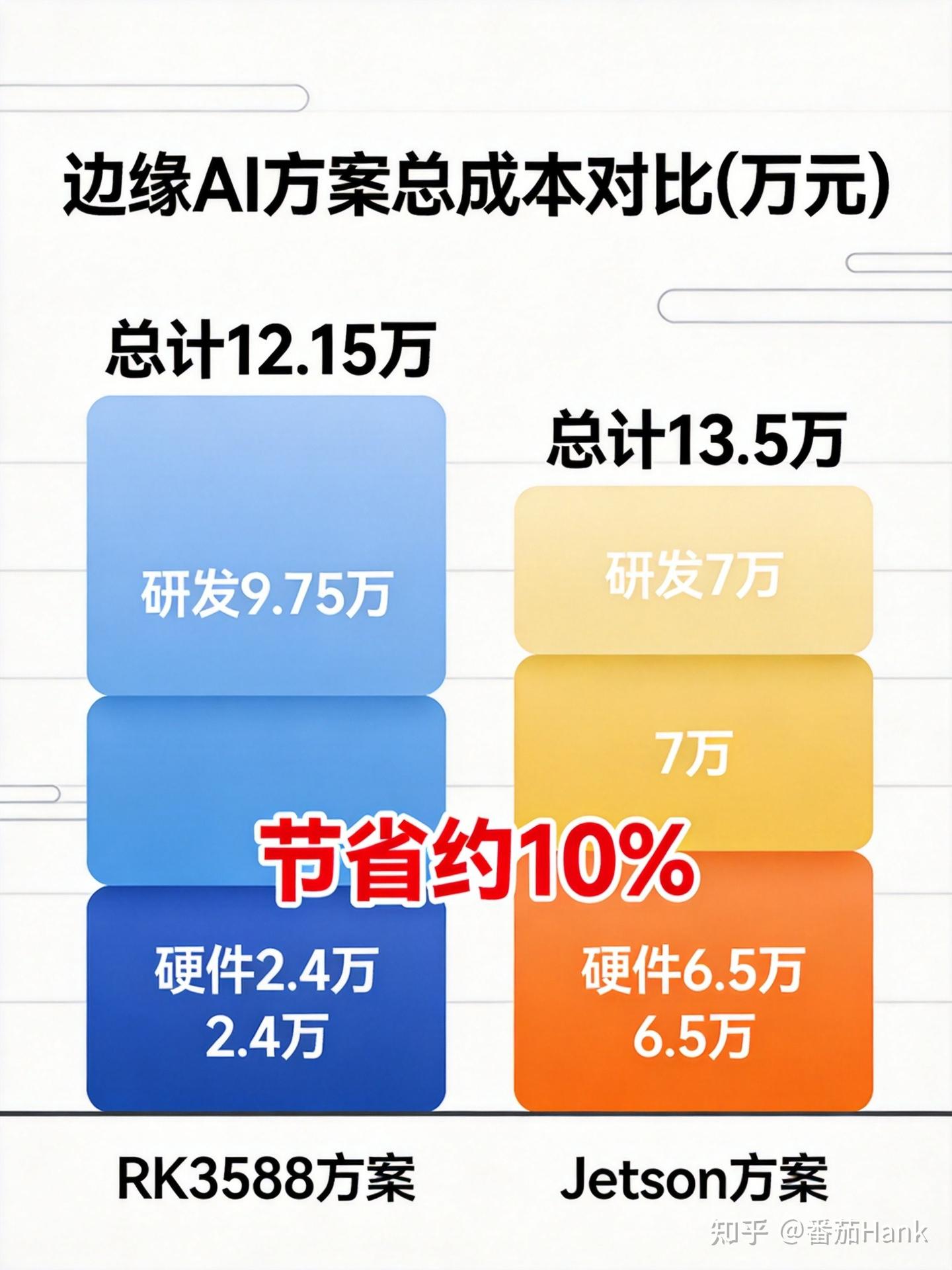
| 项目 | RK3588方案 | Jetson Orin方案(预估) |
|---|---|---|
| 硬件成本 | 2.4万 | 6.5万 |
| 研发成本 | ~10万(11人周) | ~7万(7人周) |
| 总成本 | ~12万 | ~13.5万 |
| 交付周期 | 11周 | 7周 |
RK3588 方案的总成本略低于 Jetson 方案,但交付周期长 4 周。如果客户的时间成本敏感,Jetson 方案可能更合适。
💡 解读:Jetson 的研发溢价低(TensorRT 生态成熟),但硬件溢价高;RK3588 的硬件溢价低,但研发溢价高(RKNN 工具链需要自己摸索)。两个方案总成本接近,选哪个取决于你的时间和预算权重。
七、什么时候选 RK3588,什么时候必须用 Jetson?
推荐选 RK3588 的场景 ✅
- 预算敏感型项目:总硬件成本控制在 1 万元/套以内
- 接口丰富的需求:需要多路视频输入、PCIe 扩展
- 视频编解码密集型:4K/8K 视频处理、推流、转码
- LLM 轻量级应用:跑 1-3B 规模的 LLM 做对话/问答
- 有国产化/信创要求:政企客户指定或加分项
- 小规模部署:10 套以内的项目
必须选 Jetson 的场景 ⚠️
- 大模型推理:YOLOv8m 以上,或参数量超过 10B 的 LLM
- 算力密集型任务:实时多目标跟踪 + 3D 检测等复合任务
- 超低延迟要求:延迟要求<20ms 的自动驾驶场景
- 成熟生态依赖:需要 TensorRT、DeepStream 等 NVIDIA 全家桶
- 大规模部署:100 套以上的标准化产品
- 开发周期紧张:没有时间踩坑,想快速出原型
3 步判断法
遇到选型纠结?先问自己 3 个问题:
第 1 步:预算 ≤ 1 万/套?
→ 是:选 RK3588 ✓
→ 否:看第 2 步
第 2 步:算力需求 > 6 TOPS?
→ 是:选 Jetson ✓
→ 否:看第 3 步
第 3 步:有国产化/信创需求?
→ 是:选 RK3588 ✓
→ 否:都可以,看团队技术栈八、项目交付:那一刻,我们觉得值了
项目验收那天,4 路相机同时跑,FPS 稳定在 28-32 之间。
客户在监控大屏前看了整整 10 分钟,没说话。
然后他转过头,说了一句话:
“这钱花得值。”
那一刻,我觉得这 4 个月的值了。

九、写在最后
做这个项目之前,我和很多开发者一样,对国产芯片持观望态度。但经过这几个月的实战,我的看法有所改变:
RK3588 不是 Jetson 的替代品,而是另一个选择。
它有自己的适用场景,有自己的优劣势。在某些特定场景下,它甚至比 Jetson 更合适。
当然,如果你需要跑真正的大模型、需要 NVIDIA 完整的工具链支持,Jetson 依然是首选。这个选择没有对错,只有适不适合。
📊 数据说明:本文所有性能数据来自我们项目的实测环境(RK3588 开发板 + RKNN Toolkit 2.0 + YOLOv8n),实际性能可能因模型版本、驱动版本、测试条件不同而有所差异。
🚀 最后
感谢你读到这里。如果你觉得这篇文章有帮助,点赞、收藏、转发是对我最大的支持。
如果你正在面临类似的选型决策,或者有具体的技术问题想要讨论,欢迎通过以下方式找到我:
📍 爱发电主页:
爱发电:番茄Hank在爱发电,你可以:
- 💬 一对一咨询:针对你的具体项目做选型建议和技术评估
- 📦 技术支持包:RK3588 模型部署、RKNN 优化等专项服务
- 📚 深度内容:后续会持续分享更多边缘 AI 部署的实战经验
你现在用的是 Jetson 还是 RK3588?遇到过什么坑?