
重磅!苹果 M 芯片全系 LLM 性能排行榜
昨天 Apple 发布了新款 M5 芯片全系 (除了 Ultra) ,趁着热乎劲儿,今天跟大家理性捋一下本地 LLM 部署,该如何选 Mac。
M5 系列使用 3nm 制程,优势明显,在每个 GPU 加了矩阵计算单元,LLM 推理 prefill 阶段对比 M4 提速 大概 3 到 4倍。但是 Decode 阶段速度只有大概 1.3 倍左右提速 (等级森严,不至于越阶碾压)。M5 系列要评价的话:加量也加价 (低配 m5 pro 直接 1T 起),我等等党誓守 M6 换 2mn 制程。
先上结论,具体表格数据往后看:
只需要少数几轮对话:选 pro 芯片(弃坑 m3 pro, 带宽拉胯,还不如 m1 pro 和 m2 pro)起,内存至少 16GB,随便玩一玩 AI 的话选 M2 芯片起。
需要多轮次对话,以 20k 上下文为准,等待时间 30 秒以内:至少要选 Max 芯片,如果需要跑 32B 的模型,至少 32 GB 内存起步。
如果真要靠 LLM 干点生产力的活:至少 64GB 内存起步,可以放进 80B Q4 模型。目前 M1 ultra 64GB (64 核 GPU 版本最好,48 核版本跟 AMD AI Max + 395 相当) 最具性价比没有之一 Best Mac for LLM[1] (目前闲鱼在 1.2 万上下,但是有涨势) ,800 GB/s 带宽的 plddr5 就真的 “Only Apple Can Do”。另外一款 M1 Max (32 核 GPU) 性价比也是很好,完全不输 M2 Max。
下面以 Llama 7B 模型为例,Q8 和 Q4 量化下,基于 llama.cpp 推理对比各个 Mac 版本在 prefill 和 decode 的速度。柱状图越高越好。欢迎大家在评论区分享自己的 Mac 推理速度。
Apple Mac 全系 Decode 速度对比 (最重要的)
整体看来,采用 Q4 量化会比 Q8 量化有 1.5 到 2 倍提速
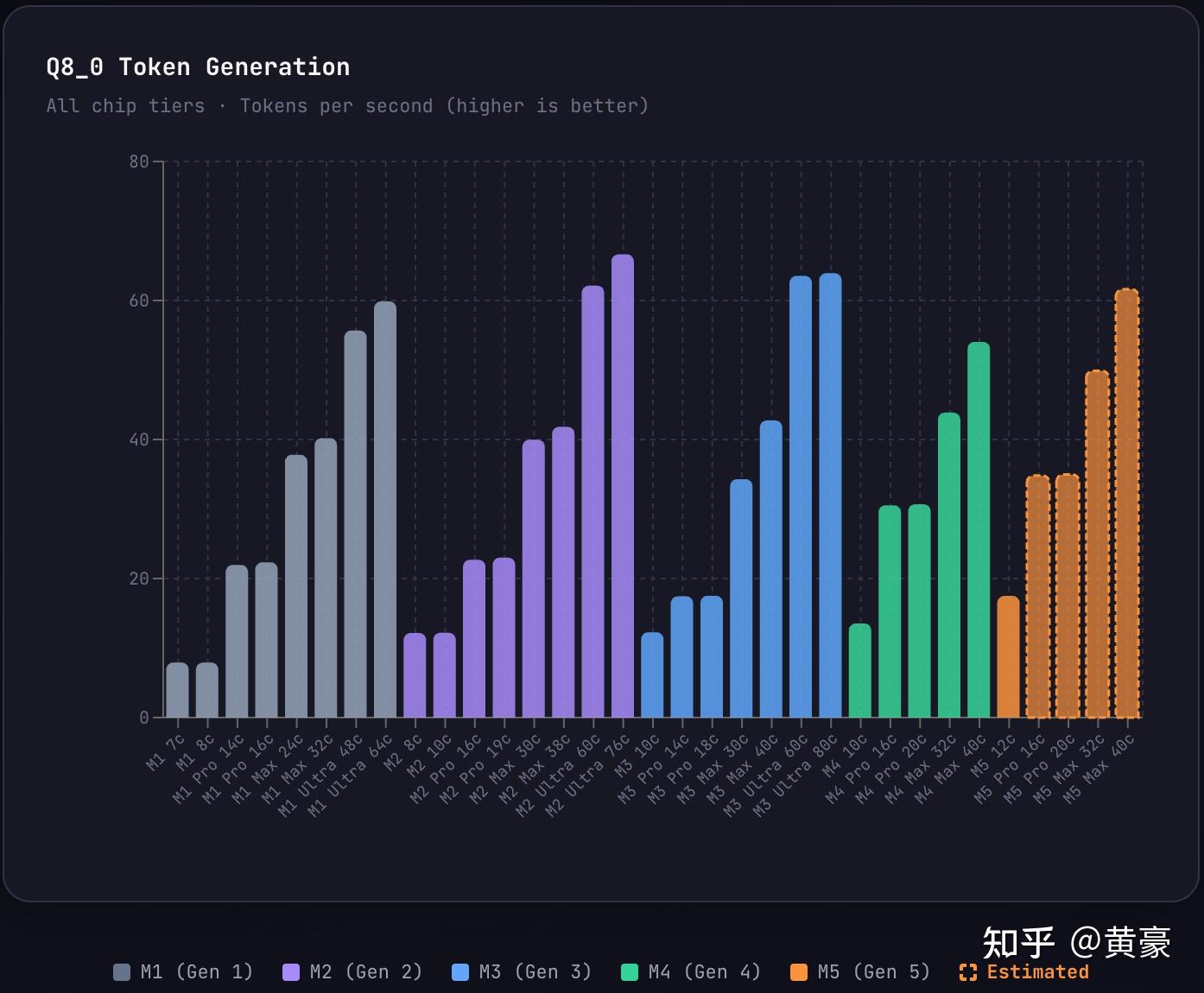
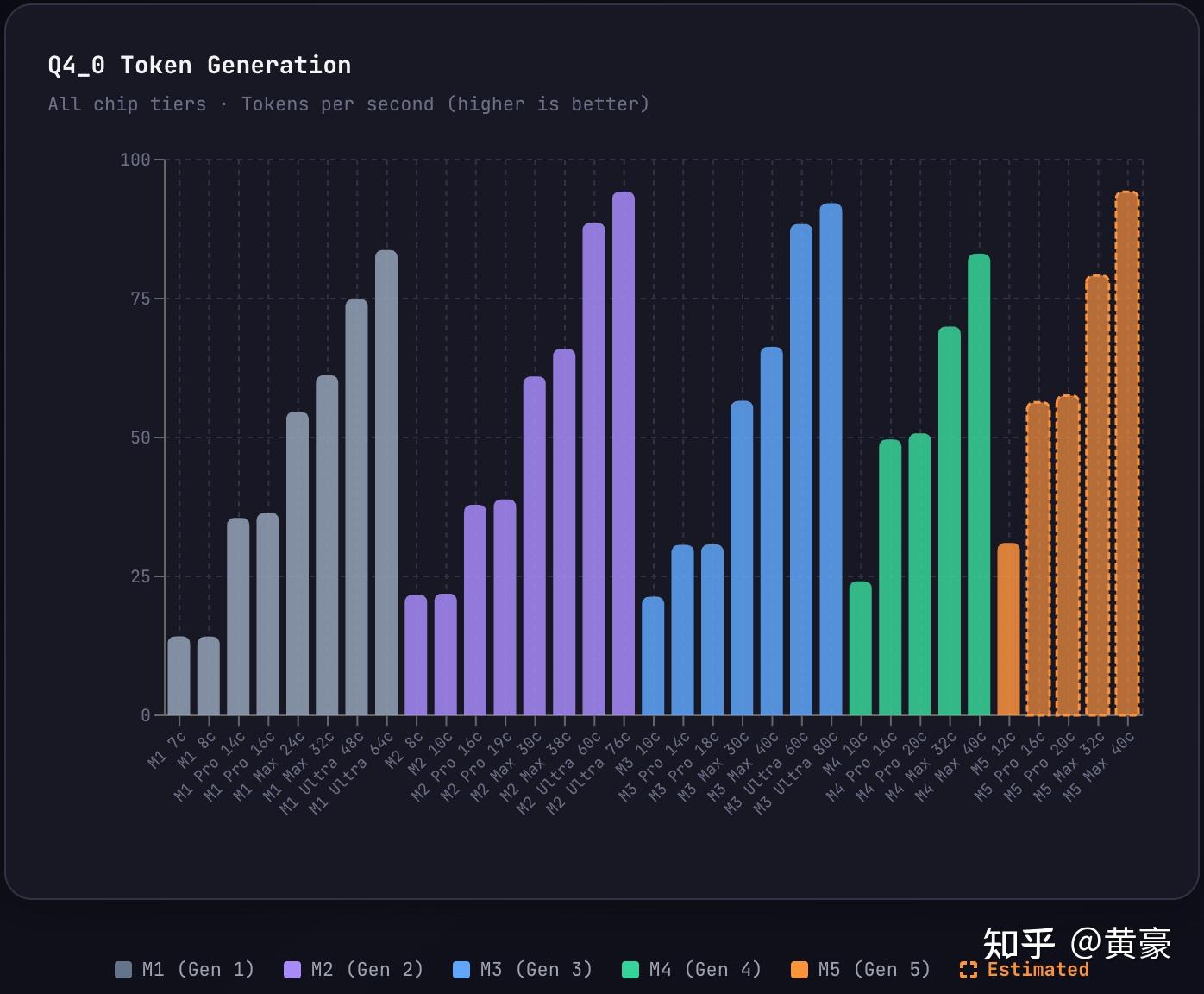
这里提一下,这里的表现都是基于 llama.cpp,如果采用果子的 mlx 框架模型,速度会有 7% 到 10% 的提速。顺便提一个 m3 pro 这个坑,由于果子砍了内存带宽 (200GB/s 砍到 150GB/s),导致 Decode 速度甚至不如 m1 pro 和 m2 pro。
Apple Mac 全系 Prefill 速度对比 (长上下文)
因为 LLM 每次回答你的问题要把之前跟你的聊天记录都读一遍 (上下文),随着问答轮次增加,LLM 思考的时间明显增长,从而影响整体回答问题的速度。因此这个指标对于多轮对话是重要的。
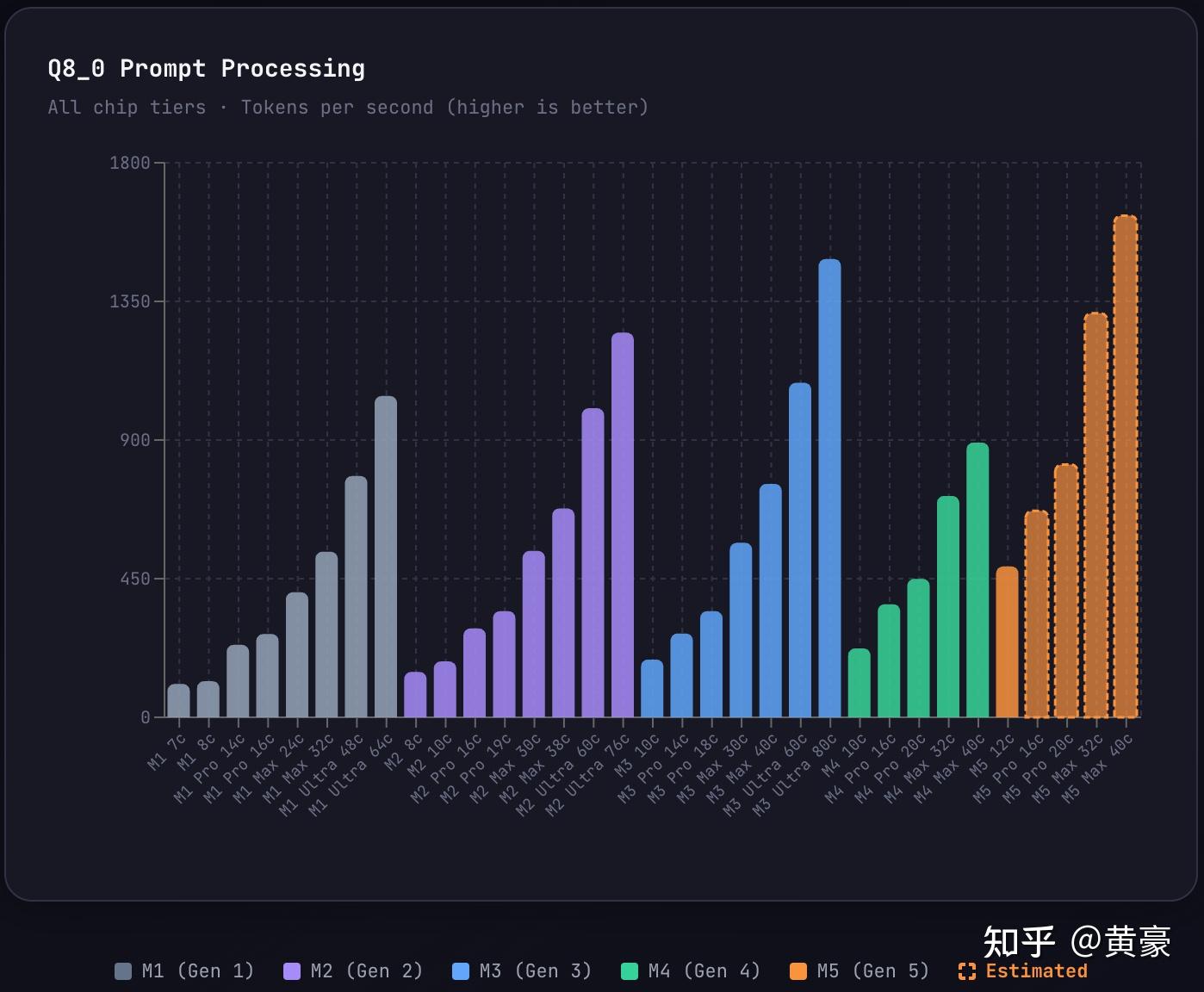
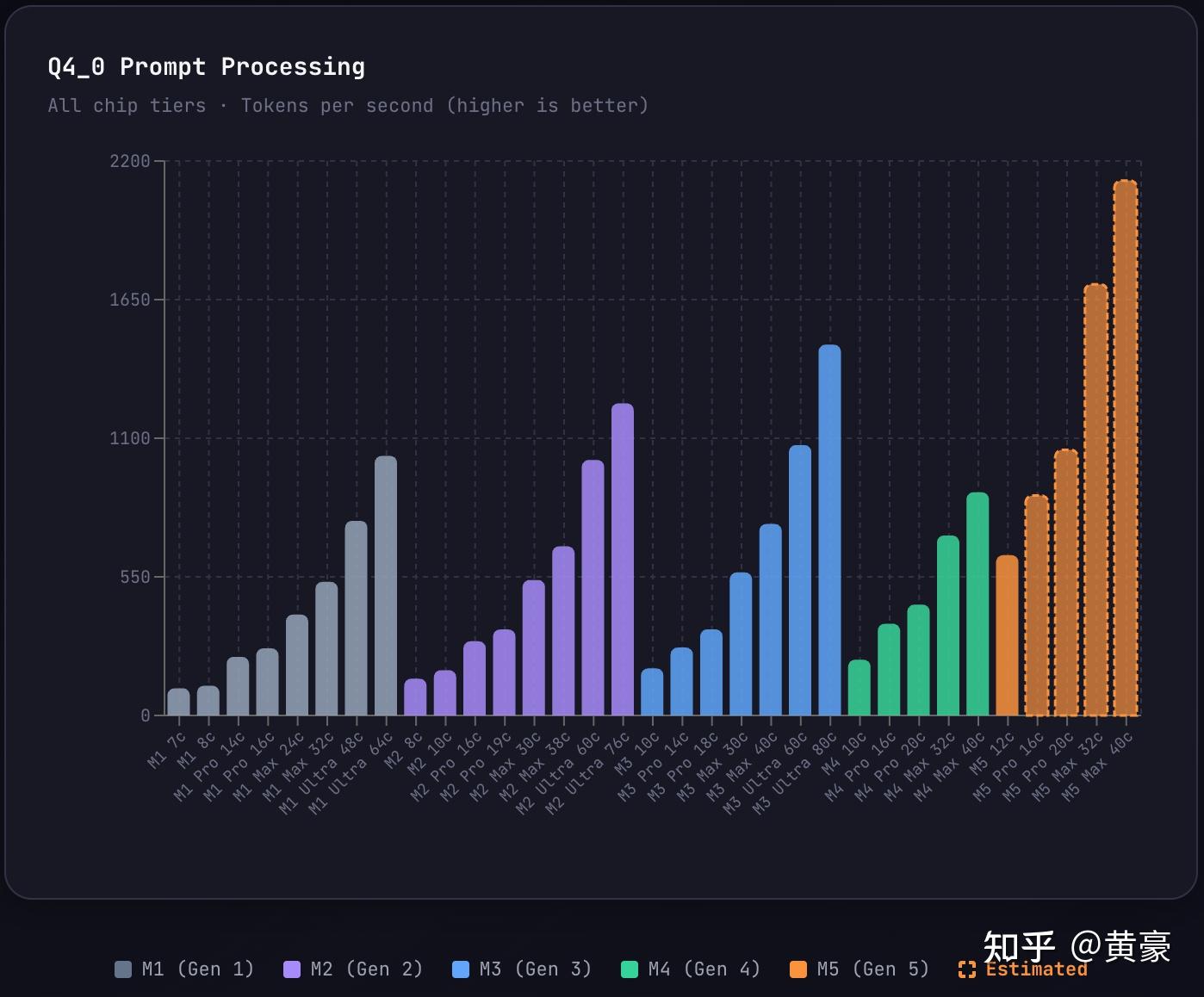
这里解释下,用户跟 AI 交互的两个阶段:prefill 是 LLM 处理用户输入,反应 AI 听你说话脑子理解的速度;decode 是 LLM 向用户输出,反应 AI 回答你问题的速度。
根据这篇论文 So much to read, so little time: How do we read, and can speed reading help?, Psychological Science in the Public Interest 17.1 (2016): 4-34.[2] 研究显示,人类阅读英文每秒在 4 到 11 个单词范围内,中文大概在 6 到 18 个单词。那么,根据这个分分析,选定 LLM 模型之后,你要购买的机器要支持在每秒 20 tokens 的 decode 速度,否则就无法满足个人需求。
当然模型的选择也重要,介于篇幅,我们以后再谈怎么选模型。今天主要关注怎么选 mac。
整个数据表格 (包含 F16, Q8, Q4 量化下 Llama 7B 模型的表现)
| Chip | Gen | BW [GB/s] | GPU Cores | F16 PP [t/s] | F16 TG [t/s] | Q8_0 PP [t/s] | Q8_0 TG [t/s] | Q4_0 PP [t/s] | Q4_0 TG [t/s] |
|---|---|---|---|---|---|---|---|---|---|
| M1 | 1 | 68 | 7 | 108.21 | 7.92 | 107.81 | 14.19 | ||
| M1 | 1 | 68 | 8 | 117.25 | 7.91 | 117.96 | 14.15 | ||
| M1 Pro | 1 | 200 | 14 | 262.65 | 12.75 | 235.16 | 21.95 | 232.55 | 35.52 |
| M1 Pro | 1 | 200 | 16 | 302.14 | 12.75 | 270.37 | 22.34 | 266.25 | 36.41 |
| M1 Max | 1 | 400 | 24 | 453.03 | 22.55 | 405.87 | 37.81 | 400.26 | 54.61 |
| M1 Max | 1 | 400 | 32 | 599.53 | 23.03 | 537.37 | 40.20 | 530.06 | 61.19 |
| M1 Ultra | 1 | 800 | 48 | 875.81 | 33.92 | 783.45 | 55.69 | 772.24 | 74.93 |
| M1 Ultra | 1 | 800 | 64 | 1168.89 | 37.01 | 1042.95 | 59.87 | 1030.04 | 83.73 |
| M2 | 2 | 100 | 8 | 147.27 | 12.18 | 145.91 | 21.70 | ||
| M2 | 2 | 100 | 10 | 201.34 | 6.72 | 181.40 | 12.21 | 179.57 | 21.91 |
| M2 Pro | 2 | 200 | 16 | 312.65 | 12.47 | 288.46 | 22.70 | 294.24 | 37.87 |
| M2 Pro | 2 | 200 | 19 | 384.38 | 13.06 | 344.50 | 23.01 | 341.19 | 38.86 |
| M2 Max | 2 | 400 | 30 | 600.46 | 24.16 | 540.15 | 39.97 | 537.60 | 60.99 |
| M2 Max | 2 | 400 | 38 | 755.67 | 24.65 | 677.91 | 41.83 | 671.31 | 65.95 |
| M2 Ultra | 2 | 800 | 60 | 1128.59 | 39.86 | 1003.16 | 62.14 | 1013.81 | 88.64 |
| M2 Ultra | 2 | 800 | 76 | 1401.85 | 41.02 | 1248.59 | 66.64 | 1238.48 | 94.27 |
| M3 | 3 | 100 | 10 | 187.52 | 12.27 | 186.75 | 21.34 | ||
| M3 Pro | 3 | 150 | 14 | 272.11 | 17.44 | 269.49 | 30.65 | ||
| M3 Pro | 3 | 150 | 18 | 357.45 | 9.89 | 344.66 | 17.53 | 341.67 | 30.74 |
| M3 Max | 3 | 300 | 30 | 589.41 | 19.54 | 566.40 | 34.30 | 567.59 | 56.58 |
| M3 Max | 3 | 400 | 40 | 779.17 | 25.09 | 757.64 | 42.75 | 759.70 | 66.31 |
| M3 Ultra | 3 | 800 | 60 | 1121.80 | 42.24 | 1085.76 | 63.55 | 1073.09 | 88.40 |
| M3 Ultra | 3 | 800 | 80 | 1538.34 | 39.78 | 1487.51 | 63.93 | 1471.24 | 92.14 |
| M4 | 4 | 120 | 10 | 230.18 | 7.43 | 223.64 | 13.54 | 221.29 | 24.11 |
| M4 Pro | 4 | 273 | 16 | 381.14 | 17.19 | 367.13 | 30.54 | 364.06 | 49.64 |
| M4 Pro | 4 | 273 | 20 | 464.48 | 17.18 | 449.62 | 30.69 | 439.78 | 50.74 |
| M4 Max | 4 | 410 | 32 | 736.25 | 24.29 | 718.56 | 43.87 | 713.93 | 69.95 |
| M4 Max | 4 | 546 | 40 | 922.83 | 31.64 | 891.94 | 54.05 | 885.68 | 83.06 |
| M5 | 5 | 153 | 12 | 374.35 | 9.67 | 489.78 | 17.50 | 636.36 | 31.02 |
| M5 Pro* | 5 | 307 | 16 | 516.6 | 19.7 | 670.0 | 34.8 | 872.5 | 56.3 |
| M5 Pro* | 5 | 307 | 20 | 629.5 | 19.7 | 820.6 | 35.0 | 1053.8 | 57.5 |
| M5 Max* | 5 | 460 | 32 | 998.0 | 27.8 | 1311.4 | 49.9 | 1710.8 | 79.2 |
| M5 Max* | 5 | 614 | 40 | 1250.6 | 36.3 | 1627.9 | 61.6 | 2122.3 | 94.2 |
带 * 号的数据是根据 M4 和 M5 数据对比的比率估计的。参考链接 Llama.cpp M 芯片 LLM[3]
欢迎大家测试一下自己的 Mac 的 LLM 表现,打在留言区👇🏻,
格式: Mac + 框架 + 模型 + 量化 + Prefill + Decode
比如我的测试:m1 ultra (64核 GPU) + mlx + Qwen3-Coder-Next 80B-A3B + int4 + 未知 + 40 tokens/s
引用链接
[1] Best Mac for LLM: https://ai.oldpan.me/t/topic/467[2] So much to read, so little time: How do we read, and can speed reading help?, _Psychological Science in the Public Interest_ 17.1 (2016): 4-34.: https://scholar.google.com/scholar_url?url=https://journals.sagepub.com/doi/abs/10.1177/1529100615623267&hl=en&sa=T&oi=gsb&ct=res&cd=0&d=17910175235598534089&ei=dPanabbrMs-NieoPi7X7-A4&scisig=AFtJQiwfvPBZorbjwIIoB9ZlmNWi[3] Llama.cpp M 芯片 LLM: https://github.com/ggml-org/llama.cpp/discussions/4167