
TCA 51%,MFU 不足 8%——GPU 的隐藏性能损耗
更好的阅读体验:https://blog.recsys-frontier.com/article/tca-mfu-gap
TCA 是 GPU 的核心算力部件 Tensor Core 的时间周期的激活比率,它和 MFU 理论上应当非常接近,日常中会出现 10%~20% 的 GAP,相对稳定,我们就以观察 TCA 为准了。
本文的契机是,当我尝试优化 MFU,拿TCA 作为一个辅助的观察指标,我发现他们之间的 GAP 在一些特殊情况下是不稳定的。由此开始拆解MFU 和 TCA 的 GAP,发现了GPU 的时钟频率在变,矩阵维度不是cuBLAS选择的 kernel shape 的整数倍导致的padding 计算浪费,以及最诡异Flash Attention 2 的 TCA 是 51%,MFU 不到 8%,时钟频率矫正后TCA稳定的是 MFU的 4 倍!
跟随我“破案的过程”,可以深入了解到:GPU 的硬件组成——SM/block thread/Warp/SRAM/寄存器/Tensor Core 直接的协调关系;Tensor Core的物理机制,A100 到 B200 的架构和指令变革,NCU 还原下Flash Attention2 的并行枯竭问题,TCA 的指标的物理含义。
GPU架构简述
在开始这个“破案”故事前,先对 GPU 的一些核心部件做一个说明,有利于后面的问题理解。偏科普,大牛可以直接跳过,或者读到后面再折回来。
一个 GPU 由多个 SM(Streaming Multiprocessor) 组成,B200 包含 148 个 SM。SM 才是真正对标 CPU core 的单元——它拥有完整的”三件套”:寄存器和缓存、计算单元、调度器。
最外层是 SM 级共享资源。 顶部的 L1 Instruction Cache 供整个 SM 取指令。底部两样:TMA(Tensor Memory Accelerator)负责异步搬数据,256 KB L1 Data Cache / Shared Memory 是片上高速存储,程序员可以手动管理其中的 Shared Memory 部分。
中间 4 个相同的方块就是 4 个 Sub-Partition(SMSP)或叫Sub-Core。 每个 SMSP 从上往下看:
- Warp Scheduler + Dispatch Unit:每 cycle 为 1 个 warp 选一条指令并派发执行
- Register File(16,384 × 32-bit = 64KB):thread 私有的高速存储,所有局部变量住在这里
- 计算单元:图中每一行就是一组执行管道——INT32 做整数、FP32 就是传统”CUDA Core”、蓝色 FP64 做双精度、底部 LD/ST 负责读写内存、SFU 做 sin/cos/exp等科学计算。
- Tensor Core:右侧那个大方块,每个 SMSP 一个,AI 算力的绝对主力,也是下面有介绍的核心主角
Tensor Core
CUDA Core 每个 cycle 做一次标量运算——一个浮点数乘加。Tensor Core 每个 cycle 做一次矩阵运算——D = A × B + C,一条指令算出一整块小矩阵的乘加结果。这就是 AI 算力爆炸的来源:同样一个 cycle,标量 vs 矩阵,产出差了几个数量级。
**一个小矩阵的数据量远超单个 thread 的寄存器容量,所以 Tensor Core 的操作数不是由一个 thread 提供的,而是整个 warp(32 个 thread)协作提供**。每个 thread 持有矩阵的一个 fragment(碎片),32 个 thread 的 fragment 拼起来才是完整的 A、B、C、D。
发射一条 MMA 指令时,硬件从 32 个 thread 的寄存器中收集所有 fragment,组装成完整矩阵,送入 Tensor Core 计算。这打破了 CUDA 原始模型中”寄存器对 thread 私有”的语义——Tensor Core 指令会跨 thread 读写寄存器。
而且这个协作粒度在逐代增大:A100 上是 1 个 warp(32 threads),H100 上是 1 个 warp-group(4 warps = 128 threads),B200 上虽然回到了单线程发射语义,但操作数已经不在寄存器里了,而是从 Shared Memory 和 TMEM 直接喂给 Tensor Core。
GEMM
AI 训练和推理的计算量,绝大多数来自矩阵乘法(GEMM:General Matrix Multiply)。线性层是矩阵乘,Attention 的 Q@K^T 和 Score@V 是矩阵乘,Embedding 之后几乎每一步都是矩阵乘。
一个大 GEMM :(A 是 M×K,B 是 K×N,C 是 M×N)的计算量是 2MNK FLOPs。直接算是不现实的——矩阵太大,放不进片上存储。所以实际做法是tiling:把输出矩阵 C 切成很多小块(tile),每个 tile 分配给一个 Thread Block,Block 内的 threads 协作把对应的 A、B 小块加载到 Shared Memory,然后在片上用 Tensor Core 做矩阵乘加累加。
MFU 总比TCA 低一些
MFU 是 Model FLOPs Utilization,模型算力利用率。算法是:你的模型实际做了多少 FLOPs,除以这段时间内 GPU 理论上能做的最大 FLOPs(wall_time × peak_TFLOPS)。这是一个应用级指标,需要你自己算模型的计算量。一般系统监控上是看不到的,它是应用级别的。
TCA = Tensor Core Activity,Tensor Core 活跃率。算法是:采样周期内 Tensor Core 处于激活状态的时钟周期占比。这是一个硬件级指标,GPU 的性能计数器自动统计,不需要你算任何东西。
GPU 的算力peak_TFLOPS一般我们就是用 Tensor Core 的总算力,而 Tensor Core 激活率基本就代表了核心算力输出(仅仅记录TensorCore 的运算时间,不包含等数据的时间)。这两个基本成改是差异很小的指标,有的时候不方便精确计算 MFU,就用 TCA 来替代。
我在计算 MFU 的时候,为了 double check自己的计算方式是否正确,就拿 TCA 进行参照,大多数时候他们会有个 10%~20% 的 GAP,而我在特定的情况下观察到了 50%+ 的 GAP,层层剥茧探究发现 Flash Attention 上会出现TCA 是 51%,MFU 不到 8%的不可思议的 GAP。
认知和观察的 GAP 驱动我必须深入,起初怀疑是不是我的 MFU 计算出错了。
MFU 的测算方式是:
wall_time其实就是你程序的执行计时,peak_TFLops是硬件的峰值算力(B200 FP16)是2,250TFlops,而counted_FLOPS就是实际你自己的程序里计算出来的实际有效 Flops,这里容易出错,但无论是基于所有矩阵运算进行拆解测算,还是利用 pytorch 原生的from torch.utils.flop_counter import FlopCounterMode ,两者的结果一样。
并且也仔细核对了 Flash Attention 的实际 Flops,它在反向传播的时候额外做了一次 recompute,总 Flops 是前向的 4 倍,而一般情况的 。
所以,这些 GAP 真实存在,是 MFU 和 TCA 的 GAP,也是我对 GPU 底层理解的GAP。
功率墙和padding浪费
为了搞清楚这件事,我选择用最简单的矩阵乘,它结构简单,如果 MFU 和 TCA 一致,那么就是非矩阵乘在搞鬼。
这么一算,还真的见鬼了!大矩阵乘下,MFU比 TCA 低一截,并且是矩阵越大,低的越多!并且 MFU 似乎有一个极限——83.22%,无论矩阵多大都涨不上去了!
这实际是 Claude Code 先发现的:“有一个惊人的发现!” 它用nvidia-smi 监控了GPU 的时钟1643 MHz,而不是峰值对应的1965 MHz,GPU似乎主动降频了,我从监控上也能看到功率是顶着1kw 的,远不到峰值 1.2kw。
这是由于 B200 是以风冷的形式部署的,基线功率就是 1kw。TCA 是根据降频之后的时钟算的,也就是它会自然标高,MFU 始终在以 B200 的物理峰值在做分母计算。
如果差距全来自降频,那在不触发功率墙的轻负载下,MFU 应该精确等于 TCA。验证了一下,果然如此:1024³ matmul,功耗仅 409W,GPU 满频运行 1965 MHz,MFU = 9.66% = TCA = 9.6%。
| Config | MFU | TCA (Monitoring) | Avg Clock | Power | 矫正 MFU | GAP |
|---|---|---|---|---|---|---|
| 1024×1024×1024 | 9.66% | 9.6% | 1965 MHz | 409W | 9.66% | -0.06% |
| 2048×2048×2048 | 46.63% | 50.0% | 1939 MHz | 964W | 47.26% | 2.74% |
| 4096×4096×4096 | 58.50% | 74.25% | 1586 MHz | 984W | 72.48% | 1.77% |
当时这些剩余的 GAP 我认为就是一些统计误差和可能存在的padding 浪费,其实我是最后折回来又重新做了验证。因为后面了解到,TCA 是硬件层面的计数器,监控上那条线不存在统计误差,我也认为这里必须对地几乎严丝合缝。
换了一块 H100 继续测算:
| Config | MFU | TCA (监控) | NVML Clock | 矫正 MFU | GAP |
|---|---|---|---|---|---|
| 4096³ | 62.36% | 90.26% | 1517 MHz | 81.39% | 8.87% |
| 16384×4K×16K | 63.07% | 94.70% | 1473 MHz | 84.75% | 9.95% |
这次开的矩阵都比较大,用 H100 主要是因为他可以逼近它的功率上限,同时也想看看它的 MFU 能飙到多少。但是从这个结果上看,这个 Gap 比在 B200 上大得多,似乎又出了新的问题。
时钟频率测不准:nvidia-smi 的采样频率 5Hz,测定一个1k 多 MHz 的时钟,那必然有巨大的误差。用 NVML 200Hz 高频采样替代旧方案,依然对不上。为测量真实 SM 运行频率,使用 CUDA clock64() 内联函数 —— 直接读 SM 的硬件 cycle counter。GAP 又回到了个位数。
| Config | NVML 报告 | clock64 实际 | 偏高 | TCA (监控) | 矫正 MFU | GAP |
|---|---|---|---|---|---|---|
| 4096³ | 1515 MHz | 1376 MHz | 10.1% | 90.26% | 89.68% | 0.58% |
| 16384×4K×16K | 1471 MHz | 1340 MHz | 9.8% | 94.70% | 93.07% | 1.63% |
剩下的我怀疑是 tile 浪费:矩阵乘法做 tiling 时,如果矩阵维度不是 tile 大小的整数倍,cuBLAS 会把矩阵补零(pad)到 tile 的整数倍,多出来的部分照样送进 Tensor Core 计算,算完扔掉。这就是 padding 浪费——TC 确实在干活,TCA 会计入,但这些 FLOPs 对你的模型没有任何贡献,MFU 不会计入。
但是常识是如果 M 和 N 的维度是128 的倍数,它不会存在 tile 尾波的,但这 1.63% 的 GAP 仍然不理想,实验 NCU 对实际使用的 tile padding进行测定:4096 的使用了256×128,0 padding 浪费;16384的神奇地选择了320×128的 tile,使得实际计算是有限计算的1.01563。
| Config | Kernel | Tile | tensor_active | 理论值 (FLOPs/FPC) | Ratio | 矫正 MFU | GAP |
|---|---|---|---|---|---|---|---|
| 4096³ | nvjet_tst_256x128 | 256×128 | 134,217,728 (=2^27) | 134,217,728 | 1.000000 | 89.68% | 0.58% |
| 16384×4K×16K | nvjet_tst_320x128 | 320×128 | 2,181,038,080 | 2,147,483,648 (=2^31) | 1.01563 | 94.52% | 0.18% |
大矩阵反而更加对的严丝合缝了!
规律:
- 功耗越接近 TDP,clock stretching 越严重,软件时钟偏差越大,MFU 还有有一个降频后的无法逾越的功率墙。
- cuBLAS 内部的 kernel 选择器并不是追求padding 整除不浪费:选的tile 越大,每个 tile 的 compute/memory 比越高。一个 tile 的计算量正比于 M_tile × N_tile × K_tile,但它需要加载的数据量只正比于 M_tile × K_tile + N_tile × K_tile。tile 变大,计算量按体积增长(三次方方向),数据加载按面积增长(二次方方向),所以算数强度(AI)更高,Tensor Core 更容易被喂饱,而不是等数据。
Flash Attention 2让TCA 虚高
最基础的矩阵运算让我摸清了规律,但换到 Transformer 上,这个规律全然没有了!
| Config | Attn占比 | MFU | TCA | MFU/(TCA×0.588) | Clock |
|---|---|---|---|---|---|
| d=1024, seq=512 | 7.7% | 19.91% | 24.45% | 0.814 | 1965 |
| d=256, seq=1024 | 40% | 7.13% | 14.36% | 0.496 | 1965 |
| d=256, seq=2048 | 57% | 8.20% | 20.68% | 0.396 | 1965 |
| d=128, seq=2048 | 73% | 6.49% | 18.19% | 0.357 | 1965 |
不同尺寸的 Transformer 下,MFU 和 TCA 的 GAP 也不同,能找到的规律是似乎 Attention 的 Flops 占比越高,TCA 和 MFU 的 GAP 越大,TCA 的虚高越是严重。
这时的数据不足以支撑这个猜想,需要单独来跑 Attention 部分,因为已经证明过大矩阵 MFU 和 TCA 的 GAP 不大。大矩阵是指 FFN,QKVO 等部分,那单独跑的部分就是 Q@K^T,Softmax@V。
| 组件 | MFU | TCA | Ratio |
|---|---|---|---|
| bmm Q@K^T (N=512) | 9.28% | 15.7% | 1.005 |
| bmm P@V (N=64) | 11.67% | 39% | 0.509 |
| softmax BF16 | N/A | 0% | — |
| scale + softmax | N/A | 0% | — |
| Q@K^T + scale + sm | 1.52% | 2.5% | 1.034 |
| sm + cast + P@V | 2.04% | 6.6% | 0.526 |
| Full manual attn | 2.67% | 6.5% | 0.699 |
| Flash Attention | 7.65% | 51% | 0.255 |
做了时钟矫正之后,Q@K^T没问题,Softmax@V 是 0.5,这让我走了一段弯路,最后是定位到 B200 的 tile 是 128 的,64 的半填充实际只有一半的 TCA 是有效的。
直到我看到了 Flash Attention (FA2)在监控上飙出了一个 51% 的 TCA,而实际的 MFU 只有 7.65%,时钟频率矫正后,差了整整 4 倍。
为了验证这不是巧合,我换了各种形状来跑,结果都是严丝合缝的 4 倍!与 D、S、H、B 完全无关。FA2 的 TCA 永远是 MFU 的 4 倍!那么一开始Transformer 的 TCA 虚高问题就有了模糊的答案,就应该是 Flash Attention 引起的!
| Config | D | B×H | MFU | TCA | Ratio |
|---|---|---|---|---|---|
| S512_D64_H16 | 64 | 512 | 7.63% | 51% | 0.254 |
| S512_D128_H8 | 128 | 256 | 8.81% | 59% | 0.254 |
| S512_D32_H32 | 32 | 1024 | 5.81% | 39% | 0.253 |
| S256_D64_H16 | 64 | 1024 | 6.68% | 45% | 0.252 |
| S1024_D64_H16 | 64 | 256 | 8.57% | 57% | 0.256 |
| S2048_D64_H8 | 64 | 64 | 8.75% | 58% | 0.257 |
| S4096_D64_H4 | 64 | 16 | 7.92% | 53% | 0.254 |
| S1024_D128_H8 | 128 | 64 | 8.32% | 56% | 0.253 |
| S2048_D128_H4 | 128 | 16 | 8.33% | 56% | 0.253 |
| flash_attn_v2 (Dao) | 64 | 512 | 8.49% | 57% | 0.253 |
| pytorch_sdpa_flash | 64 | 512 | 7.63% | 51% | 0.254 |
陷入LLM的幻觉
错误的 TCA 计算理解
当我把这样的结果丢给了 Gemini,它把我一同带入了它的幻觉里,爬了半天的坑。
他的解释是这样的:
在现代 NVIDIA GPU的物理架构中:
每个 SM 被划分为 4 个 Sub-core(子核心或处理块)。
每个 Sub-core 拥有独立的 Warp Scheduler 和 1 个 Tensor Core。
1 个 SM = 4 个 Tensor Core。
GPU 硅片内部布满了被称为 PMON (Performance Monitor) 的硬件计数器。每个时钟周期(Clock Cycle),硬件都会进行极其简单的布尔逻辑判断:
检查 Sub-core X 的 Tensor Pipe 是否有指令在执行?(Yes/No)
这里出现了第一个致命的“宽容度”: 对于整个 SM 来说,只要这 4 个 Sub-core 中 有任何 1 个 回答了 Yes,硬件计数器sm__pipe_tensor_active就会在这个周期 +1。
4 个全开,+1。
只有 1 个开,另外 3 个闲着,依然 +1。
放到平时我可能不会信,但是当我看到了 TCA 是 MFU的 4 倍,不得不相信了这个观点:这是 FA2 kernel 的结构性常数——occupancy 不足导致 4 个 sub-core 里恒定只有 1 个有效工作(这句话是错的,我把我当时的想法记录了下来)
那为什么是 Flash Attention 呢?对比下其他的 FA 呢?
| Backend | ms/step | 修正前MFU | TCA | 修正后Ratio |
|---|---|---|---|---|
| FA2 (PyTorch SDPA) | 0.200 | 7.63% | 51% | 0.254 |
| FA2 (Dao flash_attn) | 0.180 | 8.49% | 57% | 0.253 |
| cuDNN Attention | 0.100 | 15.25% | 26% | 0.997 |
| Efficient (xFormers) | 0.425 | 3.59% | 48% | 0.127 |
这里数据非常清晰,似乎 Flash Attention V2 出了问题,而 cuDNN Attention 则完全正常,并且它有着两倍的速度和两倍的 MFU。
那似乎只要我理清楚了为什么 FA2 会有这样的问题,一切就清楚了。
FA2 TCA 虚高归因(错误的)
受到了上面 TCA 计算的错误理解的影响,我认为一个 SM对应的4 个Sub-Core同时应当只有一个在进行计算,实际统计了 4 个,才造成了TCA 是 MFU 的 4 倍。
那首先联想到的就是 FA2 的并行枯竭问题。
Attention 如果要保留 [B, L, L] 维度的 Attention Map,当 L 较大时,它会撑爆显存,而读取写入时会消耗巨大的带宽。Flash Attention 利用一个Online Softmax 算法,它避免把完整的[B, L, L]给算出来,既然是要算的是 Softmax@V,那么是不是只需要把 V 一块一块地累加起来即可。它的算法核心就在做这个,第一避免了 Softmax 完整的算出来,第二是每一块计算所需的数据放在高速缓存SRAM,避免了 HBM 的巨大带宽占用。
在标准 GEMM(大矩阵乘法 )中,所有的乘加操作在数学上是完全无依赖的。你可以把它切成一万个小块,扔给全 GPU 的所有 Sub-core 同时算,最后加起来就行。 但 FA 不行。FA 的核心是 Online Softmax。
这意味着:
- 为了算出当前这块
的权重,你必须知道当前的 Softmax 分母(需要
的行最大值)。
- 为了把新算出的结果加进最终答案,你必须把上一步算出的旧答案
拿出来重新缩放。 这个连环依赖,彻底锁死了并行的维度。 负责计算某一行
的线程,必须把这一行的
死死抱在自己的寄存器里,然后按着 Sequence 的顺序,串行地、一块一块地遍历
和
SRAM 撑爆 :为了不让频繁缩放的 和庞大的
块去读写缓慢的 HBM,FA 把它们全塞进了 SRAM 和寄存器。代价就是:Occupancy 极低,一个 SM 物理上只能塞下 1 个 Thread Block(线程块)。在标准 GEMM 里,一个 SM 里会塞进十几二十个 Thread Block,哪怕每个 Block 内部因为串行等数据卡住了,调度器立刻换下一个 Block 顶上。4 个 Sub-core 永远被不同 Block 的指令填满。但在 FA2 里,整个 SM 只有一个 Thread Block 的孤军奋战。
现在,整个 SM 的 4 个 Sub-core 的命,全系在这 1 个 Thread Block 身上了。 由于 Online Softmax 的串行约束,加上 维度非常小,这个 Thread Block 在执行一次内循环的矩阵乘指令时,其指令并发量(Warp 活跃数量)在物理映射上,刚好只能填满 1 个 Sub-core 的发射带宽!
经验上,一个 Warp 对一个 Tensor Core 是打不满它的,按照 H100 上 WGMMA 命令是 4 个 Warp 对一个 Tensor Core。
基于 NCU 进行校验
NCU 是NVIDIA Nsight Compute,这是 NVIDIA 提供的 GPU kernel 级别的性能分析工具。
我需要校验的事项如下:
- Tensor Core 在是不是在 SM上只有一个被激活了(对应”错误的 TCA 计算理解“)
- SM 里每一个 Sub-Core 的 Warp 数量,是不是只有 1 个(对应“FA2 TCA 虚高归因”)
假设 :每个 Tensor Core 一个 Warp 不对
NCU 数据显示 FA2 可以放 2 个 block/SM:
| 限制因素 | 每 Block | SM 总量 | 可放 Block 数 |
|---|---|---|---|
| Registers | 255 × 128 = 32,640 | 65,536 | 2 |
| Shared Memory | 66,560 B | 233,472 B | 3 |
| → Occupancy Limit | 2 blocks |
FA2 grid = 256 blocks, 160 SMs × 2 slots = 320。部分 SM 跑 2 blocks(2 warps/SMSP),部分只跑 1 block(1 warp/SMSP)。NCU 同时给了 min 和 max,提供了同一 kernel 内的 1-warp vs 2-warp 对照实验:
| SMSP 指标 | min (1-block SM) | max (2-block SM) | 比值 |
|---|---|---|---|
| TCA | 37.75% | 75.50% | 2.0x |
| Warps Active | 0.66 | 2.04 | 3.1x |
| Tensor Instructions | 8,192 | 16,384 | 2.0x |
| HMMA FLOPs | 134,217,728 | 268,435,456 | 2.0x |
2-warp 的 SMSP:TCA 翻倍,FLOPs 也翻倍。但 MFU/TCA = 0.25,在两种情况下完全一致。
之前的叙事是 “shared memory 锁死了 warp,导致 1 warp/SMSP → 1⁄4”。这是不准确的。
新发现:计算命令的差异
| Counter | FA2 | cuDNN |
|---|---|---|
| ops_path_tensor_op_hmma (per-warp) | 34,359,738,368 | 0 |
| ops_path_tensor_op_utchmma (per-warp-group) | 0 | 34,359,738,368 |
同样 34.4B FLOPs。FA2 全部来自 HMMA,cuDNN 全部来自 UTCHMMA。零交叉。
| FA2 (HMMA) | cuDNN (UTCHMMA) | Ratio | |
|---|---|---|---|
| Tensor Instructions | 8,388,608 | 65,536 | 128x |
| FLOPs/Instruction | 4,096 | 524,288 | 1⁄128 |
| TC Active Cycles | 67,108,864 | 16,777,216 | 4x |
| FLOPs/Active-Cycle | 512 | 2,048 | 1⁄4 |
HMMA m16n8k16 = 4,096 FLOPs,UTCHMMA tile = 524,288 FLOPs。 每个 TC-active cycle,UTCHMMA 的吞吐恰好是 HMMA 的 4 倍。
| FA2 | cuDNN | |
|---|---|---|
| Block Size | 128 (4 warps) | 512 (16 warps) |
| Registers/Thread | 255 | 128 |
| SharedMem/Block | 66,560 B | 233,472 B |
| SMSP Warps Active (avg) | 1.64 | 3.99 |
| SMSP Warps Active (min) | 0.66 | — |
| SMSP Warps Active (max) | 2.04 | — |
这一个表格最说明问题,FA 的 SMSP上平均1.64 个激活Warp,这说明 FA2 的并行枯竭是确实存在的。而 cuDNN的SMSP 上稳定 4 个 Warp 激活,可以打满Tensor Core 的全部算力。
这里面最大的问题是,如果它是 1.64,而非严格的 1.0的话,那么前面“shared memory 锁死了 warp,导致 1 warp/SMSP → 1/4”是彻底不对了。
| FA2 | cuDNN | |
|---|---|---|
| Tensor Inst Rate | 65.25% | 1.89% |
| TCA | 65.25% | 60.67% |
| Ratio | 1 : 1 | 1 : 32 |
FA2 的 Inst Rate = TCA。这证明 HMMA 执行期间 TC 不是间歇性闲置(时间模型),而是 持续 active 但只有 1⁄4 通道在计算。如果 TC 在 HMMA 期间有 3⁄4 时间停摆,TCA 会远低于 Inst Rate。
这说明上面的假设“SM 里的 4 个Sub-Core里只激活了一个Tensor Pipe”,这个也是彻底不对了,Gemini 那一段是纯幻觉了。
1⁄4 的魔法数根因:错误的指令
1⁄4 来自 HMMA 指令本身,不来自 warp 数量。
FA2 使用的 HMMA 是一条 per-warp 指令(源自 Ampere 架构, 如A100),每条 HMMA 只能驱动 Tensor Core 内部 4 组计算通道中的 1 组。无论 SMSP 上有 1 个 warp 还是 2 个 warp,每条 HMMA 都只产出 1⁄4 的峰值 FLOPs。更多 warp 只是让 tensor pipe 更忙(TCA 更高),不会让每条指令更高效。
cuDNN 使用的 UTCHMMA 是一条 per-warp-group 指令(Blackwell 原生,如B200),4 个 warp 协同驱动 TC 全部 4 组计算通道,每条指令产出满额 FLOPs。
FA2 的代码源自 Ampere (SM80) 时代。在 Ampere 上,TC 是为 HMMA 设计的——1 个 warp 的 HMMA 就能打满 TC,不存在 1⁄4 问题。
Hopper (SM90) 引入了 WGMMA(warp-group MMA)指令。HMMA 通过兼容层继续工作,但只能驱动新 TC 的 部分容量。Blackwell (SM100) 延续了这个架构,WGMMA 演变为 UTCHMMA。
FA2 → FA4 的升级本质上就是 HMMA → UTCHMMA 的迁移,需要完全重写 kernel:
- 操作数 B 从寄存器搬到 shared memory
- 线程组织从 per-warp 改为 4-warp group 协同
- 同步模式从 warp-level 改为 warp-group level
- 数据传递走 tensor memory path 而非寄存器文件
TCA 的计算方式,它确实细化到了每一个独立的 Tensor Core,与 SM 无关,它是所以 Tensor Core 的激活平均值,上面有个有趣的数字:FLOPs/Active-Cycle=2048,也就是只要 TC 是活跃的,每个时钟周期的 FLOPs 产出是恒定的,和执行的命令的 Tile Shape 没有关系。
做一个反算验证:
B200 FP16 Tensor Core Dense Peak = 2,250 TFLOPS SM 数量 = 148,每个 SM = 4 个 Sub-Partition(SMSP),每个 SMSP 有 1 个 Tensor Core
一共是592 个 TC
如果每一个 cycle 的输出都是 2048,那么时钟频率是
这非常接近我们上面算出来的数字1965MHz, 查了下这叫Boost Clock,是GPU功耗和温度有余量时自动提升到的更高频率。
B200 兼容了 Ampere架构下的 HMMA 命令,这个命令在 B200 上只能打满 Tensor Core 的 1⁄4 算力,实际全通电在空算,但是有效输出就是 1/4。
tk-link 在 24 年测试 H100 时,WGMMA 指令——这是 H100 新增的异步矩阵乘法指令,如果不使用它,GPU 利用率会封顶在 63% 左右。而我测出来,仅仅使用 HMMA 命令, FA2在 B200 上只能发挥出 25%的算力,在H100 上发挥出 2⁄3 的算力,非常接近它的 63%。
这给我们提了一个醒,从 A100→H100→B200,是 GPU 的架构级别的变更,底层的 MMA 命令实证在变,要想发挥出GPU 的 100% 算力,有先看是不是再使用最新的指令和硬件机制。
GPU 的架构和指令演变
很多人把 GPU 升级理解成”算力翻倍、带宽翻倍”。不是的,从 A100 到 B200,Tensor Core 的编程模型发生了三次断代,每一代的指令粒度、协作方式、数据通路都不一样。
A100(Ampere, SM80):Thread 为王
A100 时代的 MMA 指令叫 HMMA,粒度是 per-warp。一个 warp(32 个 thread)独立发射一条 mma.sync m16n8k16,做 4,096 FLOPs。每个 thread 持有矩阵的一个 fragment,存在自己私有的寄存器里,32 个 thread 的 fragment 拼起来就是完整的操作数。
这条指令在 A100 的硬件上就能打满 Tensor Core——因为 A100 的 TC 就是按这个粒度设计的。编程范式清晰:任务拆到 thread,数据放 register,warp 是调度的最小单位。一条 HMMA 延迟几十个 cycle,Tensor Core 很快消化完,所以你需要大量 warp 排队——occupancy 越高越好,靠 warp 之间的切换来掩盖延迟。
H100(Hopper, SM90):Warp-Group 协作
H100 把 Tensor Core 扩容了约 4 倍,同时引入了全新的 WGMMA(warp-group MMA)指令。4 个 warp 组成一个 warp-group(128 个 thread),协同发射一条异步指令,tile 从 m16n8k16 跳到 m64n256k16,单条指令 524,288 FLOPs——比 A100 一条 HMMA 多了 128 倍。
关键变化不只是 tile 更大,而是执行模型变了:
异步发射。 wgmma 发出去之后 warp-group 不阻塞,可以立刻去做下一件事——比如通过 TMA(Tensor Memory Accelerator)预取下一个 tile 的数据。TMA 是 Hopper 新增的专用硬件单元,一条指令就能把整块 tile 从 global memory 搬到 shared memory,不占 CUDA Core 算力,不占 register。于是一个 warp-group 自己就能形成 compute/memory 的流水线。
这意味着 occupancy 的重要性被削弱了——你不需要靠大量 warp 切换来掩盖延迟,一个 warp-group 的内部流水就够用了。Hopper 上的高性能 GEMM kernel 可能只有个位数的 occupancy,照样跑满 Tensor Core。但在 A100 上低 occupancy 是真的疼:HMMA 延迟 ~30 cycles,Little’s Law 告诉你需要 ~30 个 warp 才能饱和。
B200(Blackwell, SM100):Tensor Memory 解放寄存器
B200 的 MMA 指令演进到了 tcgen05.mma(编译后的 SASS 指令叫 UTCHMMA),tile 更大(M 可达 256),延迟更低,甚至回到了单线程发射语义——一个 thread 就能发起一条 MMA,硬件自动从 shared memory 读取操作数。
但最根本的变化是引入了 Tensor Memory(TMEM)。
在 tiled matmul 中,累加器矩阵 D 是被访问最频繁的操作数——K 维度切成 K_t 个 tile 迭代,D 每次迭代都要读出来、累加、写回去,总共 2K_t 次读写。而 A 和 B 沿 K 维度滑动,每个 tile 只读一次。所以 D 必须一直驻留在高速存储里。在 Hopper 及之前,D 放在通用 register file 里。但 NVIDIA 的 register file 从 2012 年 Kepler 起就是 64KB/SM,12 年没变。随着 tile 越来越大,register file 成了瓶颈——大 tile 的 accumulator 挤占了大量 register,要么限制 tile 大小,要么压低 occupancy。
Blackwell 的 TMEM 是 Tensor Core 旁边的 256KB 专用存储,专门给 accumulator 住。D 不再经过 register file,Tensor Core 直接在 TMEM 上做 in-place accumulate。Register 被彻底解放,可以用更大的 tile 而不用担心寄存器压力。实测数据也印证了这一点:B200 在 FP64 大矩阵乘上达到了峰值算力的 80.7%,而 H200 只有 55.6%——同样的算法,架构层面的效率差了 25 个百分点。
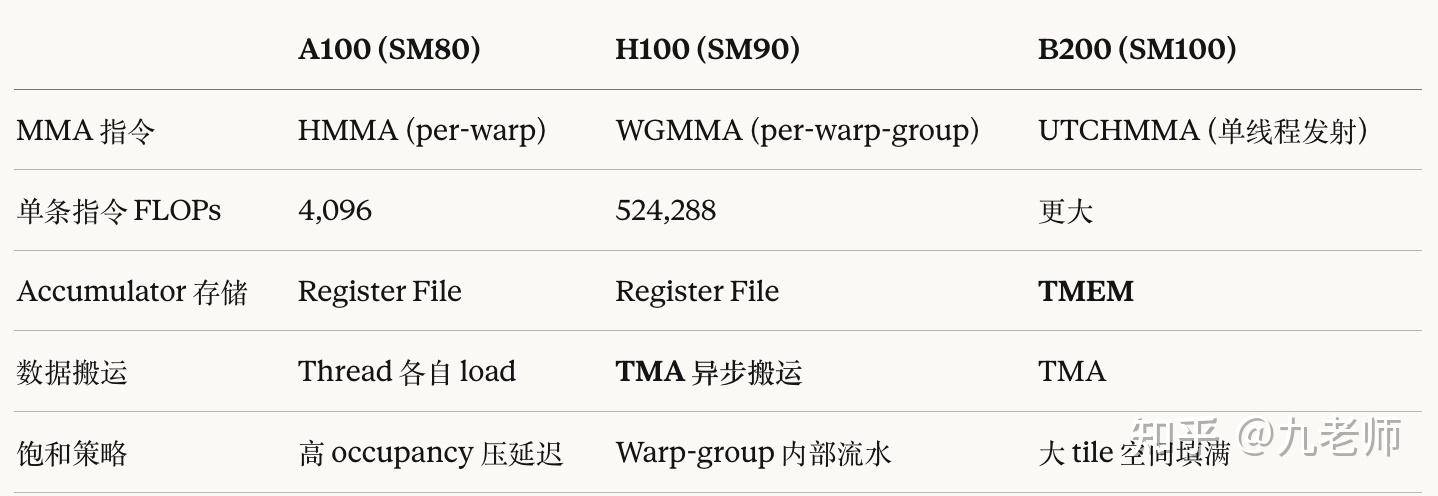
每一代的老指令都能在新卡上跑——NVIDIA 保持了向后兼容。但兼容不等于高效。HMMA 在 A100 上打满 TC,在 H100 上只能发挥 ~63%,到了 B200 上只剩 25%。这是因为新硬件的 TC 容量扩大了,老指令只能驱动其中一小部分。
FA2 是最典型的例子。它的 kernel 写于 Ampere 时代,NCU 实测显示它在 B200 上全部走 HMMA 指令,每个 TC active cycle 只产出 512 FLOPS,而 cuDNN Attention 用 UTCHMMA 达到了 2,048 FLOPS/cycle——正好差 4 倍。同样的计算量,cuDNN 快 2 倍,MFU 高 2 倍。FA2 → FA4 的升级本质就是 HMMA → UTCHMMA 的迁移,需要重写整个 kernel。
所以换卡的时候,不只是看 TFLOPS 和带宽翻了几倍。你的 kernel 用的是哪一代指令?有没有用上 TMA?Accumulator 是不是还挤在 register file 里? 这些才决定了你能发挥出新硬件几成功力。纸面参数再漂亮,指令不对,75% 的硅片可能在空转。
附上Attention的横评
在同一 B200 上系统对比 7 种 attention 实现,4 组配置,测量 MFU、吞吐量(TFLOPS)、延迟(ms)和峰值显存(MB)。
MFU 对比:
| Backend | S=512 D=64 | S=1024 D=128 | S=2048 D=128 | S=4096 D=128 |
|---|---|---|---|---|
| cuDNN | 23.98% | 40.98% | 43.80% | 47.64% |
| FA4 (CuTe-DSL) | 16.84% | 16.82% | 16.90% | 33.53% |
| FA2 (Dao) | 14.03% | 15.06% | 15.46% | 16.01% |
| SDPA Flash | 12.73% | 13.80% | 14.06% | 14.48% |
| Flex (Triton) | 12.50% | 12.73% | 13.55% | 14.52% |
| Efficient | 5.97% | 7.04% | 6.16% | 6.21% |
| Math (unfused) | 0.78% | 1.20% | 1.24% | 1.25% |
延迟 (ms/step):
| Backend | S=512 D=64 | S=1024 D=128 | S=2048 D=128 | S=4096 D=128 |
|---|---|---|---|---|
| cuDNN | 0.064 | 0.037 | 0.035 | 0.064 |
| FA4 (CuTe-DSL) | 0.091 | 0.091 | 0.090 | 0.091 |
| FA2 (Dao) | 0.109 | 0.101 | 0.099 | 0.191 |
| SDPA Flash | 0.120 | 0.111 | 0.109 | 0.211 |
| Flex (Triton) | 0.122 | 0.120 | 0.113 | 0.210 |
| Efficient | 0.256 | 0.217 | 0.248 | 0.492 |
| Math (unfused) | 1.955 | 1.276 | 1.232 | 2.450 |
峰值显存 (MB):
| Backend | S=512 D=64 | S=1024 D=128 | S=2048 D=128 | S=4096 D=128 |
|---|---|---|---|---|
| 所有 fused 实现 | 224-225 | 120 | 64 | 64 |
| Math (unfused) | 1608 | 808 | 696 | 1272 |
为什么没有 FA3?
FA3(Flash Attention 3)专为 Hopper 架构 (SM90) 设计,核心创新是 warp specialization:producer warps 做 TMA 异步数据搬运,consumer warps 专注 tensor core matmul,两组 warps 通过 pipeline 重叠。这利用了 Hopper 独有的 TMA(Tensor Memory Accelerator)硬件。
结论
所有观察到的 MFU < TCA 差距,有三个来源:
- 功率墙降频:
actual_clock / max_clock(大矩阵时显著,B200 从 1965→1460 MHz) - FA2 或一些老组件仍然在实验老的 HMMA 命令,导致Tensor Core 仅发挥出 1⁄4 的算力。
- Tile padding waste:维度未对齐tile倍数时,cuBLAS pad 到 tile 边界 → TC 计算了 padding FLOPs,TCA 计入但 MFU 不计
如果没有用错指令,没有离谱的 padding。可以把 TCA 当MFU 来看,毕竟时钟频率也是不好控制的。
references
《Nsight Compute Kernel Profiling Guide》
这是 Nsight Compute (NCU) 的官方使用指南,是解释所有 TCA、MFU 等性能监控指标的“终极法典”。
- 搜索重点:查找 “Metrics Structure” 章节。官方在这里明确定义了
sm__(整个 SM 级别的聚合)和smsp__(Sub-core 级别的精细统计)这两种指标前缀的本质区别。 - 必读章节:仔细阅读 “Pipeline Utilization” 部分。文档会向开发者发出警告:
active仅仅代表管线通电工作了,并不代表管线达到了最大吞吐量,它会教你如何用pct_of_peak_sustained_active来折算真实的吞吐率(这就完美解释了你那个 1⁄4 的产出断层)。
《CUDA C++ Programming Guide》
想要理解为什么 SRAM 撑爆会导致 Warp 数量暴跌,你需要查阅 CUDA 官方编程指南。
- 必读章节:直接翻到附录 “Hardware Implementation” 和 “Compute Capabilities” 章节。
- 核心看点:这里详细讲解了 SIMT Architecture 和 Multiprocessor Level 的资源分配逻辑。它用明确的公式告诉你,SM 是如何根据 Shared Memory (SRAM) 和 Registers 的消耗量,来严格限制驻留的 Thread Block 和 Warp 数量的(即 Occupancy 的计算法则)。
《FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision》
这是 2024 年由 Tri Dao 团队与 NVIDIA 官方深度合作发布的论文及同名 PyTorch 官方博客文章。
- 核心看点:这篇文章简直就是为你量身定做的。文章开篇就直接承认了老版本 FA 在硬件层面存在严重的算力闲置问题。
- 终极解法:文章用极其清晰的插图,详细讲解了如何利用 Warp-specialization(Warp 特化) 机制,将“搬砖的 Warp”和“做计算的 Warp”彻底分离,从而消灭
__syncthreads()带来的流水线气泡,让 4 个 Sub-core 重新全速轰鸣。
https://hazyresearch.stanford.edu/blog/2024-05-12-tk
- WGMMA 指令:这是 H100 新增的异步矩阵乘法指令,如果不使用它,GPU 利用率会封顶在 63% 左右。但它的文档有误且内存布局极其复杂。
- 共享内存(Shared Memory)限制:虽然很快,但访问延迟(约 30 个周期)已经跟不上 Tensor Core 的计算速度了。
- 地址生成成本:在极高速的计算下,仅仅计算内存地址本身就会消耗大量算力。因此必须使用 TMA(Tensor Memory Accelerator) 来异步搬运数据。
- 占用率(Occupancy):虽然异步特性减少了对高占用率的依赖,但高占用率仍是掩盖同步开销和逻辑错误的利器。
https://x.com/_xjdr/status/1913703210004648385
《Microbenchmarking NVIDIA’s Blackwell Architecture: An in-depth Architectural Analysis》
- 1. 延迟骤降:访问性能提升 58%:微基准测试显示,B200 在处理缓存缺失(Cache-misses)时的内存延迟比 H200 降低了 58%。这解决了大模型计算中常见的“数据等待”瓶颈。
- 2. 吞吐飞跃:计算能力增强 1.56 倍。凭借第五代张量核心(Tensor Core)和新增的张量内存(TMEM),B200 在混合精度任务下的实测吞吐量达到 H200 的 1.56 倍,尤其优化了 FP4 等极低精度运算。
- 3. 能效突破:单位功耗性能提升 42%。通过引入硬件级解压缩引擎,B200 在执行 Transformer 训练与推理时的能效比(Performance-per-watt)比 H200 高出 42%,实现了更省电、更高效的 AI 算力。