如果黄仁勋愿意,凭借英伟达目前造算力卡的技术,最高可以造出什么水平的游戏显卡?
如果要做到可以大规模铺货,贩售,5090几乎就已经是游戏显卡的顶点,如果你说不计成本只做最好的,那恐怕瓶颈已经不在显卡上,而在软件上和游戏厂商了。
由于从40系到50系几乎没有任何制程红利和架构升级,性能提升几乎依赖暴力提升规模和显存。
从die size来看,5090的GB202核心面积高达750mm²,仅比历史上最大的TU102小了4mm²,由于tsmc工艺的光罩最大只能做850mm²级别,继续扩大规模已经非常困难,GB100核心也就800+的核心面积,继续扩大规模,给核心堆到850mm²最多最多也只能给5090带来10%左右的提升。
比5090规模大11%,几乎满GB202规模的RTX Pro 6000 96G在游戏表现中平均比5090强5%都做不到,许多场景下平均只有2-3%提升,再扩大20%的规模能获得10%左右的提升已经非常乐观了。
同时从算力来说,光栅化游戏主要需要fp32算力,由于游戏卡boost机制的存在实际跑出来的峰值已经比B200还要高了,5090可以轻松跑到110-120TFlops的单精度浮点,相比之下B200只有90左右。
B100/200的单die性能已经基本达到了目前技术水平的上限,如果游戏卡想更进一步,那就只有也上chiplets或者多卡并行。
但问题是现在的游戏天生就不适合多卡并行...
无一例外,历史上所有用于游戏和实时渲染多显卡技术在2026年已经全部进了垃圾桶...
sli和用于Geforce的nvlink几代的折腾最后也没有解决多卡并行的问题。
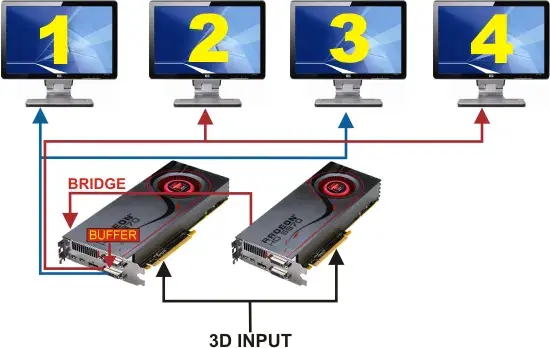
sli和cf最常见的模式是AFR,也就是两张显卡进行交替渲染,一张显卡渲染一帧,这在dx9和dx10的年代还行得通,因为大部分游戏引擎还在固定管线,后处理也不积极。
但从dx11时代开始,这些全都变了,越来越多的后处理技术被塞进来,越来越多的情况下,两帧之间存在关联或者依赖(比如TAA抗锯齿就是典型),这导致渲染帧序列的并行程度越来越低,到现在已经基本不存在理想并行的可能了。就算理论行得通,双卡也极其依赖游戏厂商的适配和调度开发,如果不适配这个弱智AFR渲染模式,那不光没奖励,还有额外惩罚......
多卡的副作用在这种情况下越来越严重,因为存在后帧等前帧等一系列同步问题,所以多卡的帧生成时间很糟糕,也和帧生成技术一样面临输入延迟增加,帧生成时间极不稳定等许多严重问题,到dx12时代多卡生态已经完全崩溃。
多卡互联的表现肯定是1+1<2的,这是常识,但由于上述问题的存在,用于游戏的多卡技术很容易出现1+1<1。在sli和30系这种末代nvlink游戏卡的多卡技术后期,1+1<1反而成了常态...
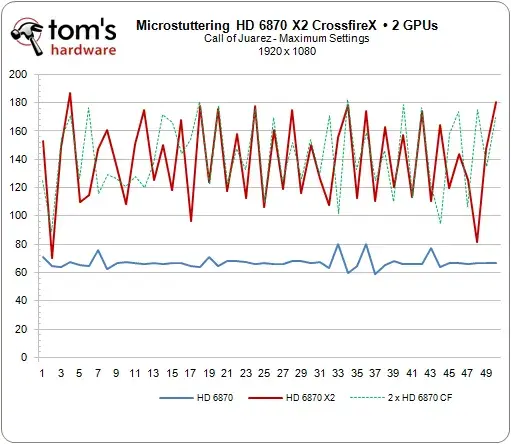
上图是AMD的6870 X2,sli当时情况也差不多,多卡跑出来的平均帧数很好看,但帧生成时间几乎全是抽风的状态——要知道这还是dx10的时代...
还记得我第一次也是最后一次用多卡,双路GTX1080,那时候其实1+1<1已经就是不少游戏的常态了,不光帧数增加基本忽略不计,还经常卡顿掉帧,我的评价是根本用不下去。
这种问题是不管用多先进的chiplets封装工艺,多高的互联带宽都很难解决的问题,别在想着你那多gpu了......
以后游戏gpu的确可能出现多个计算tile的设计,但这个比计算卡难度更大,现在的英伟达还做不到,双芯或者chiplets并不能给现在的游戏gpu带来本质提升,甚至可能带来1+1<1的负优化,所以把B200的技术下放对游戏卡的提升未必很大,5090距离理论上目前最强游戏卡大致也只有10%左右的差距了。