mac mini M4(16GB+256GB) 本地跑一个 7b 模型,辅助一些日常任务可行吗?
小Case!
这个问题很简单,以deepseek为例,直接看deepseek-r1不同参数规格的模型大小,基本就能直接算出来系统内存和显存的需求了。
对于Windows电脑来说,系统内存和显存其实是两个东西,即便是集成显卡,显存往往也是独立划分出来的。
所以对于Windows电脑来说,显存基本就是运行大语言模型的主要瓶颈。
以deepseek-r1:14b为例,模型大小是9GB,这就要求显存VRAM不得小于9GB,对应的独立显卡基本就得是12GB显卡内存了。多说一句,这里的模型大小实际上并不准确,下载到本地会略小于这个值。
而系统内存的要求略微不同于显卡内存,你可以大致理解为系统内存需求为模型大小,加上留给系统和其它软件的内存之和。虽然系统内存要求更大,但是Windows笔记本这边显卡内存才是绝对瓶颈,系统内存很容易满足。基本只要保证系统内存大于模型大小加上5GB就可以了!
而Apple Silicon M系列芯片以后的Mac有一个绝对的优势,那就是统一内存不仅都可以用来加载模型,甚至还能利用SWAP搞出翻倍的内存容量。16GB的Mac mini,基本有11GB物理内存可以当成显存啊!实际内存负载能上32GB!
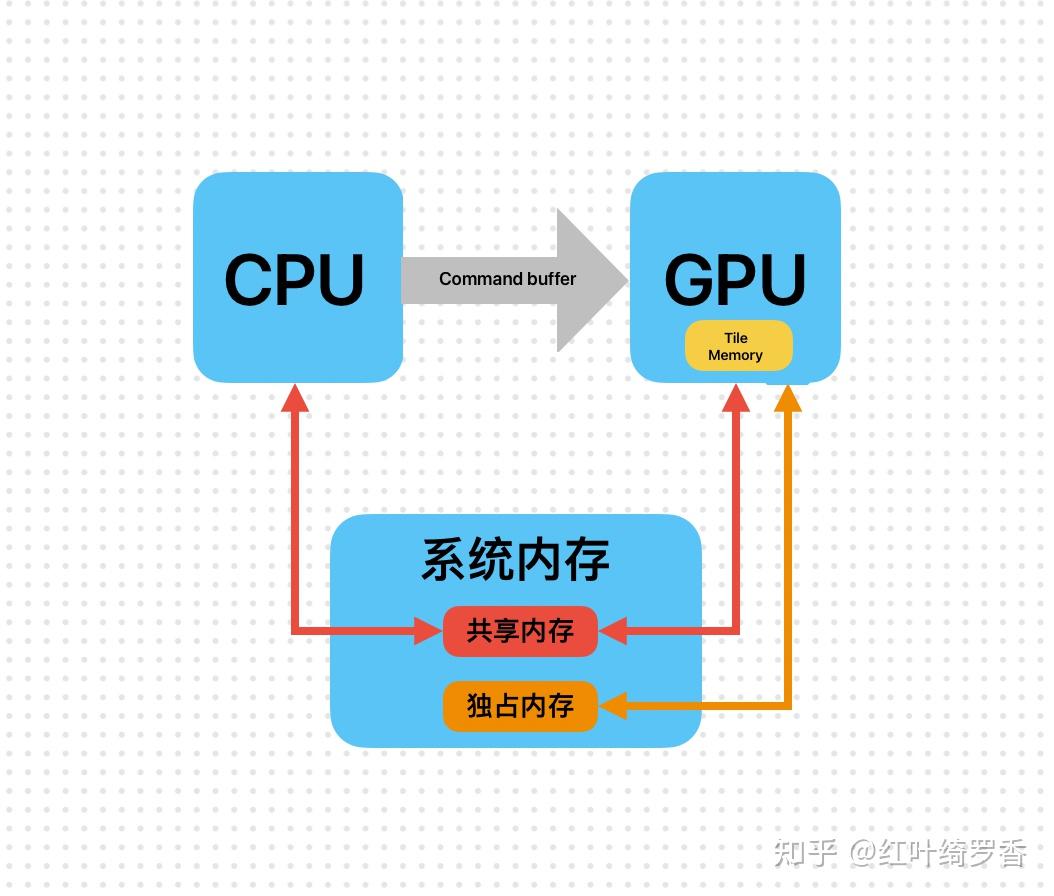
很显然,不是集显就能充分利用系统内存的,只有配合UMA统一内存架构,才能实现以上这种高效的处理哇!不妨参考一下Apple Silicon M系列芯片的内存架构设计。
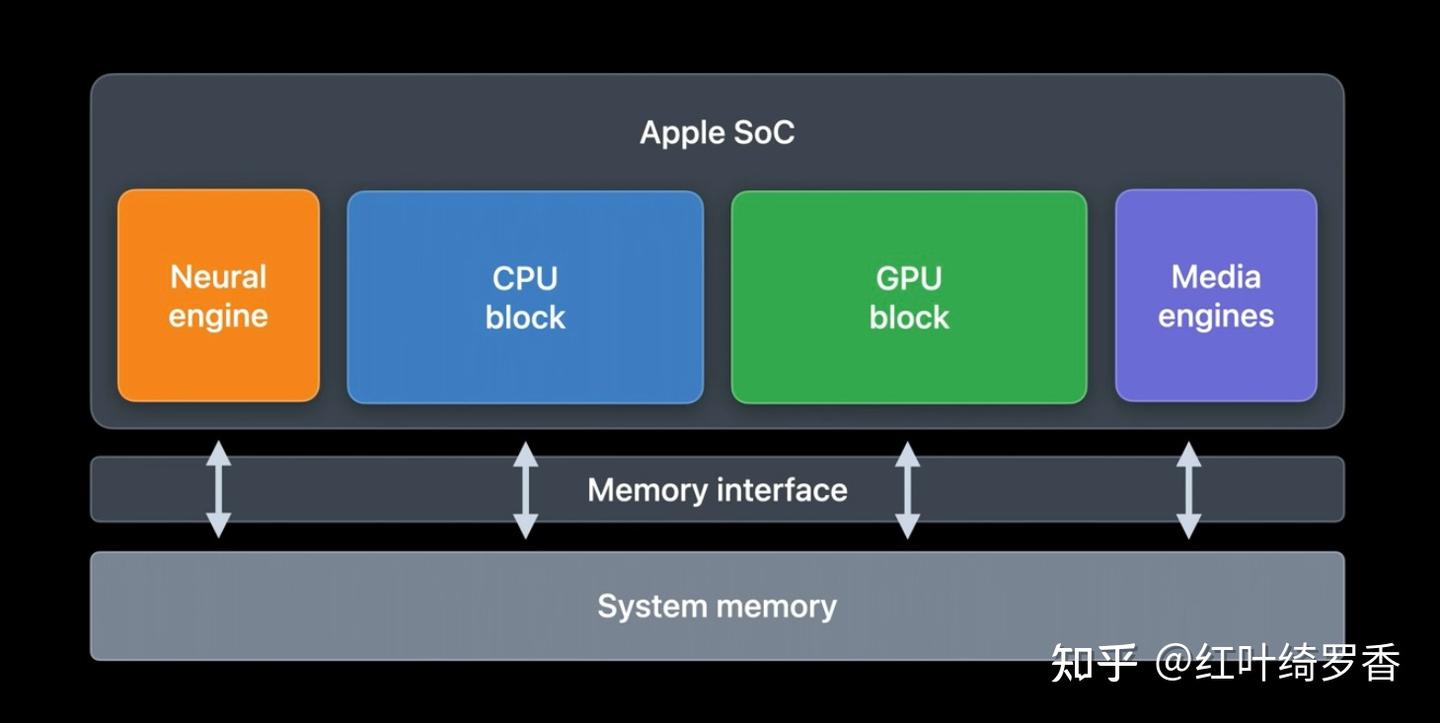
UMA架构下,GPU就是直接拿系统内存当显存用的。一旦意识到这一点,其实基本也就不会吐槽苹果的金子内存了!
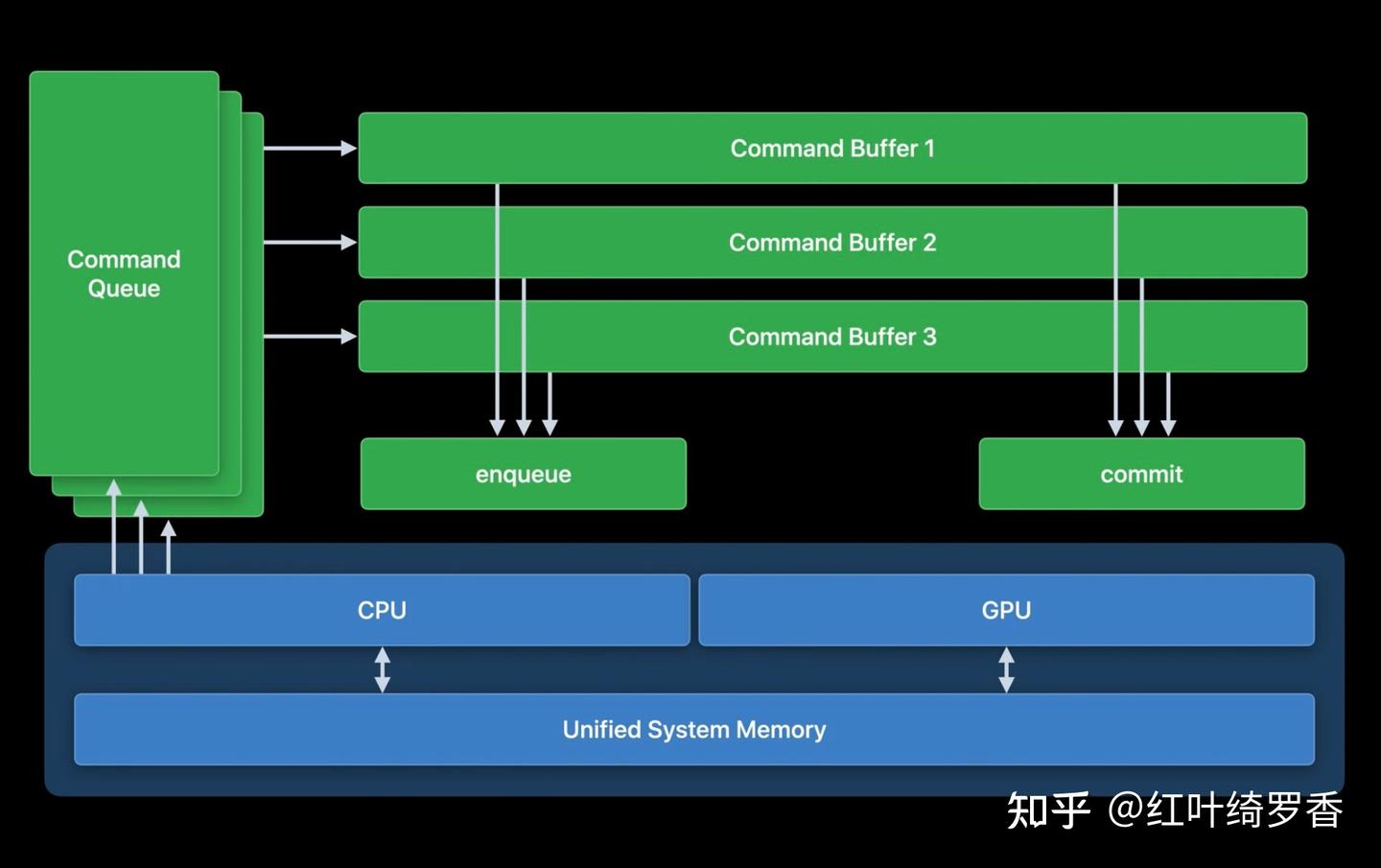
因为当你把它当显存用的时候,那可比给显卡加内存便宜太多了。而且更关键的是,对于Apple Silicon M系列芯片而言,DRAM可以做到拿出2/3以上当成显存使用。比如32GB版本的MacBook,可以拿出21GB当成显存,64GB则可以拿出48GB当显存。
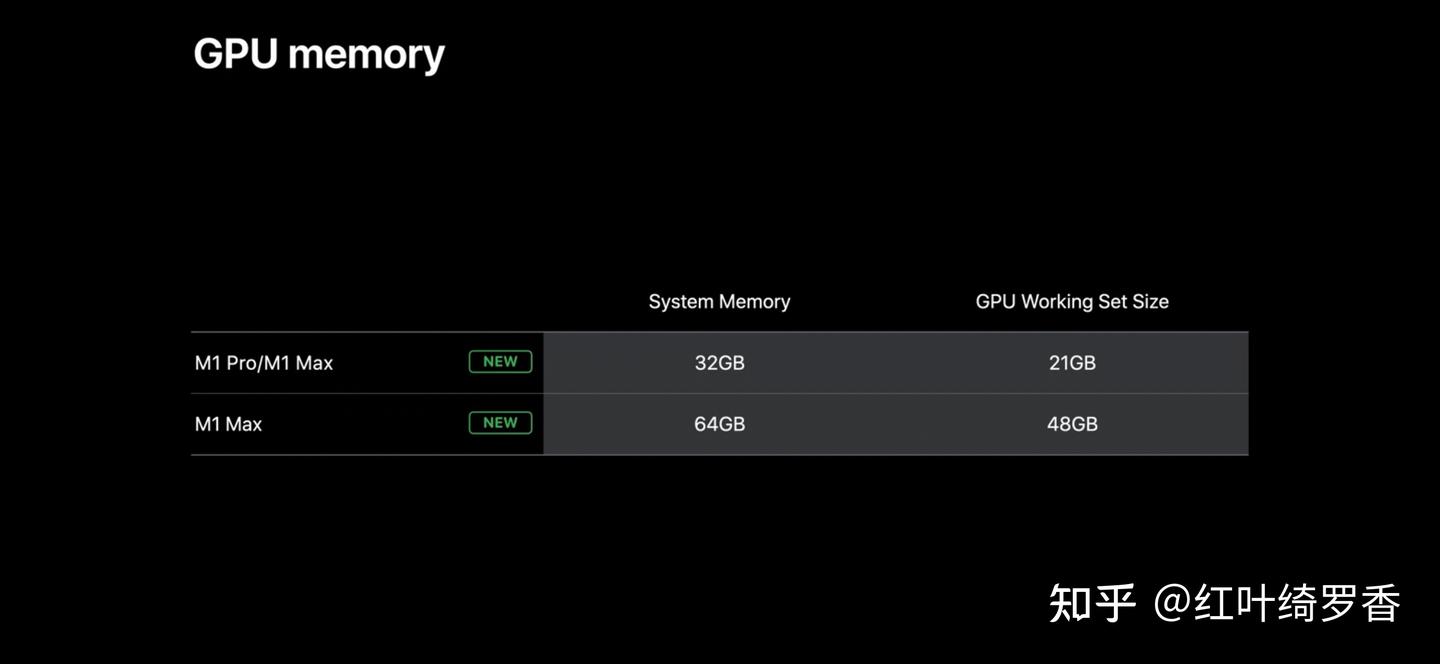
这就使得Mac mini 16GB运行deepseek-r1:14b真的是轻轻松松,内存压力都上不来的节奏。而Windows这边基本就需要RTX 4080和RTX 4090了!
模型运行基本都在GPU上,哪怕是M2,deepseek-r1:14b基本也就是思考5~10秒就已开始快速吐字了。
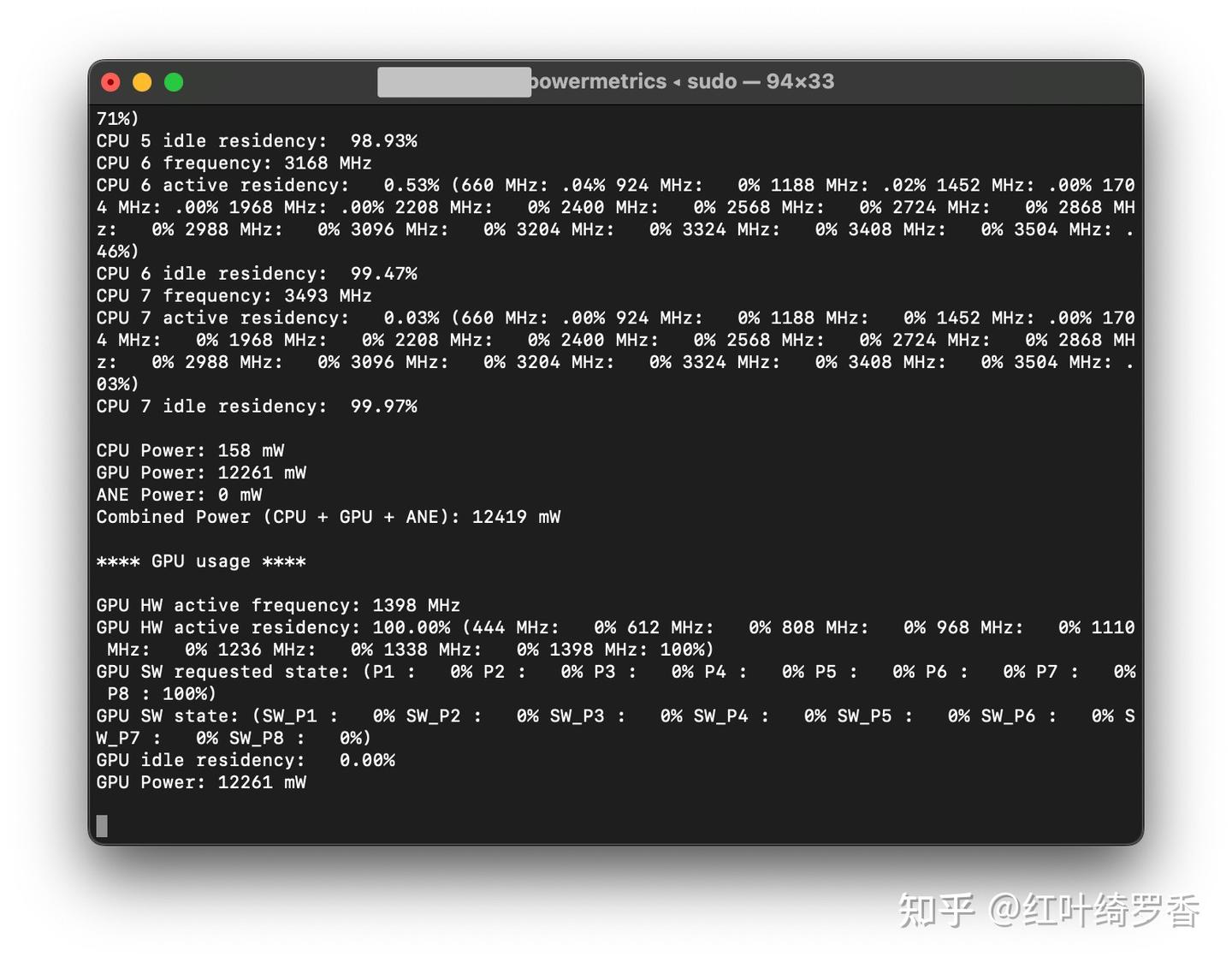
实际上,我也尝试加载了deepseek-r1:32b,你还别说,借助SWAP还真就运行运行起来了。这个模型显卡内存需求就得是20GB左右了。
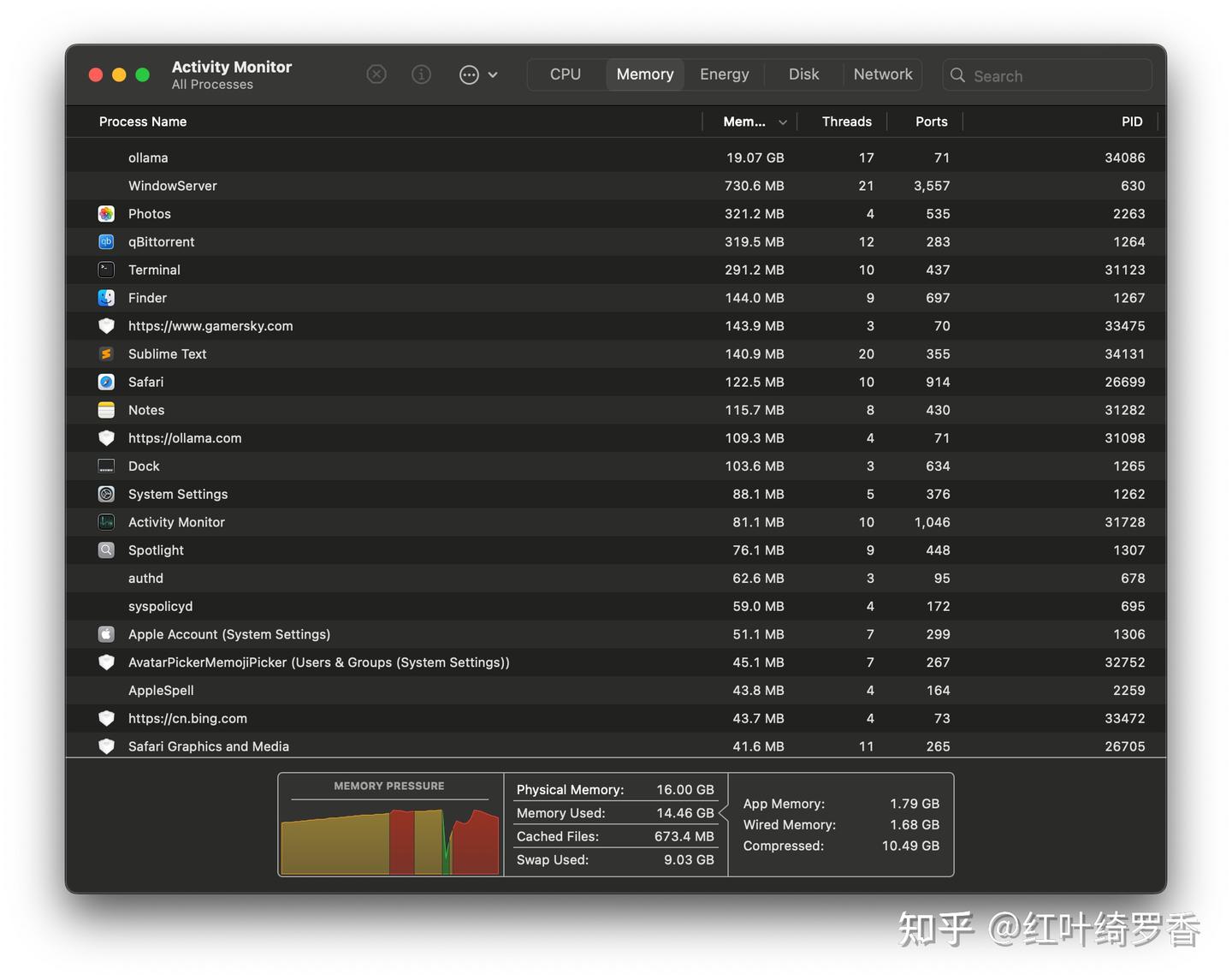
只不过几分钟一个Token的速度确实是没法用的,没办法,这种情况下GPU基本一直在打酱油,都是CPU在倒腾内存数据了。
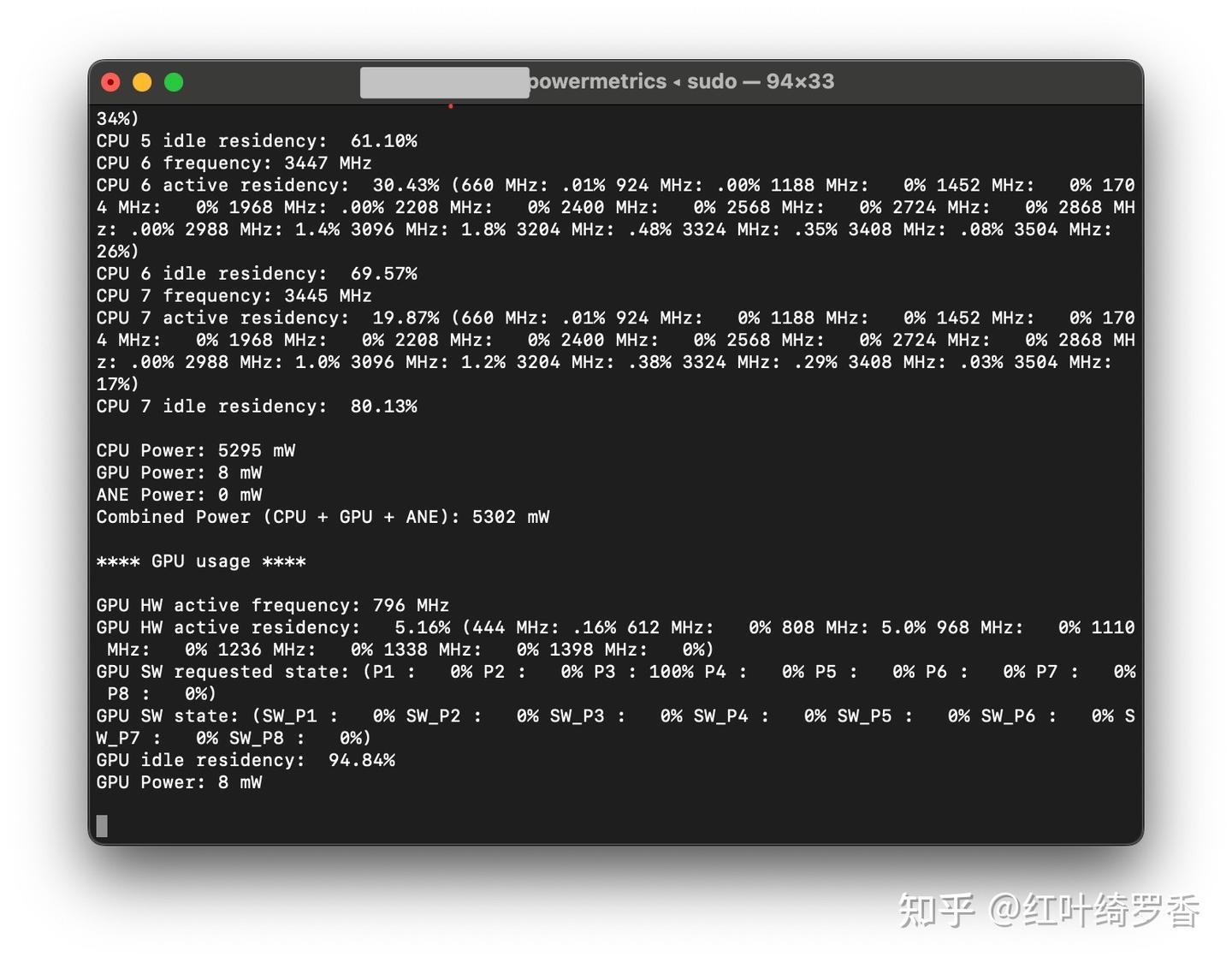
我也试了一下deepseek-r1:70b,内存占用到27GB以后,工具直接崩溃了,这基本已经是上限了。
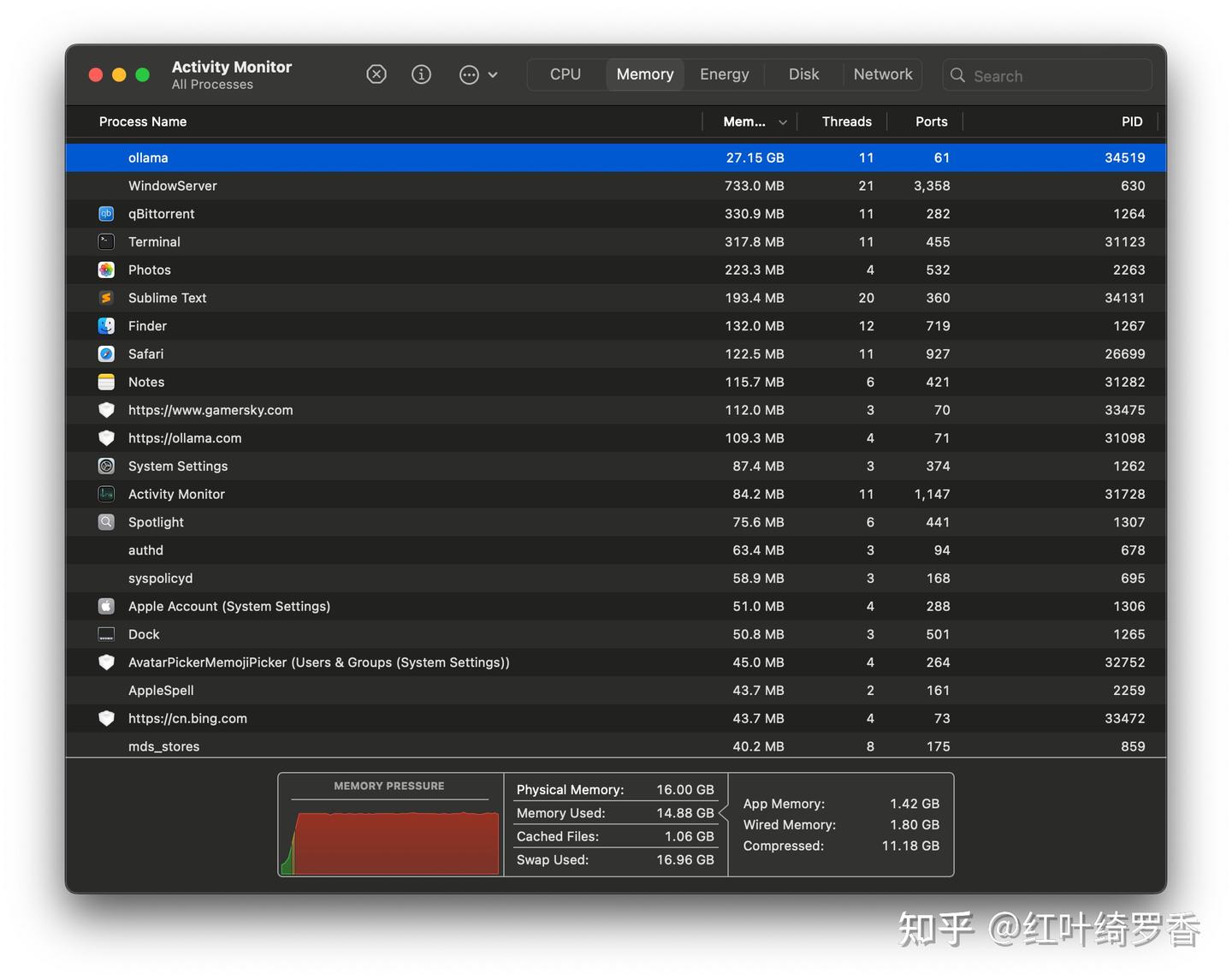
所以对于Apple Silicon M系列芯片以后的Mac,只要保证内存大于模型大小,基本就都可以流畅运行了。
最后聊聊如何部署本地模型。
部署本地大语言模型如今已经相当简单了,访问ollama.com,下载ollama应用。
目前支持macOS、Linux以及Windows,下载应用后安装一下就可以了,这个软件没什么用户界面,因为它本质上就是把工具框架安装到系统的终端里面。
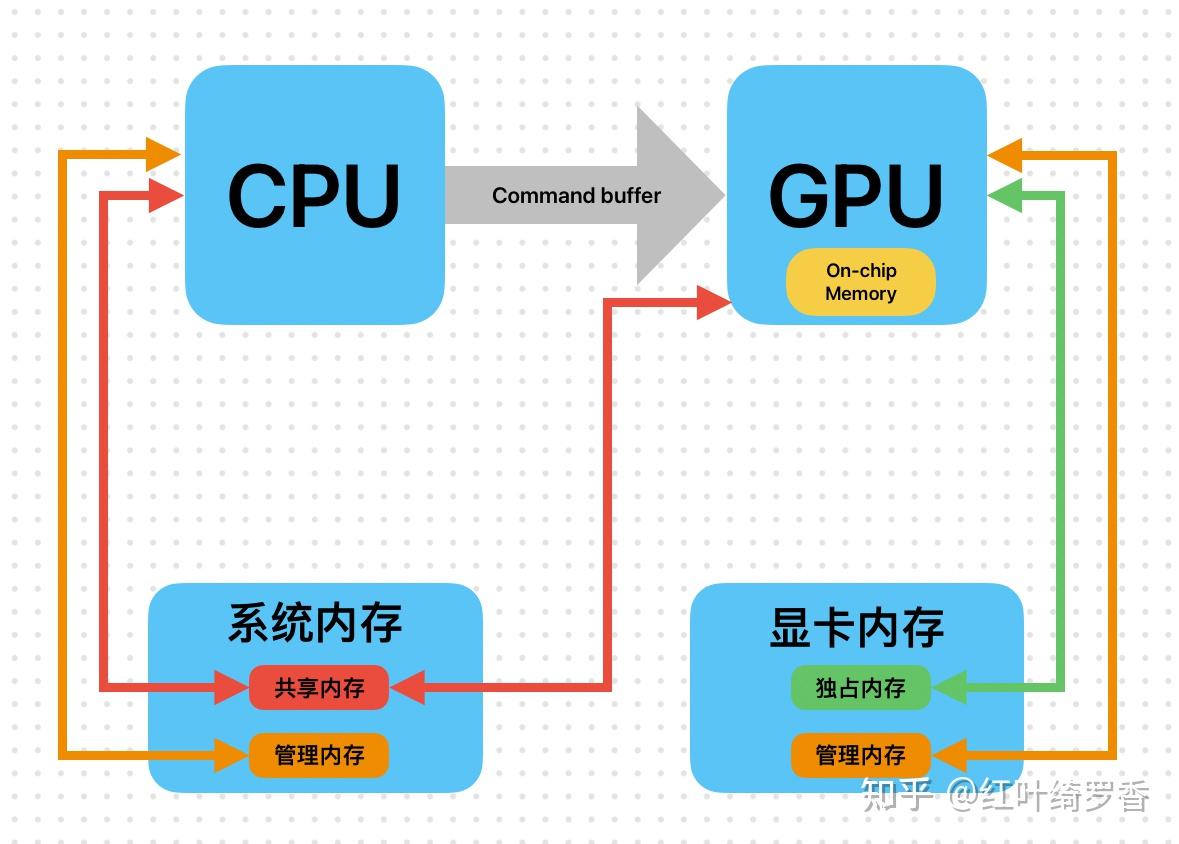
安装完软件你就可以选择适合自己的模型了,还是在这个网站上,找到适合自己的模型,这里可不只是有deepseek-r1哈!一定要注意参数规模,那种特别大的没有本地工作站就不要折腾了。
deepseek-r1提供了1.5b~671b等7个模型,大部分用户的电脑基本只适合搞一下14b以内的规模,其它折腾的意义不大。
找到模型以后下载很简单,打开终端应用,直接运行下面的命令就可以了。
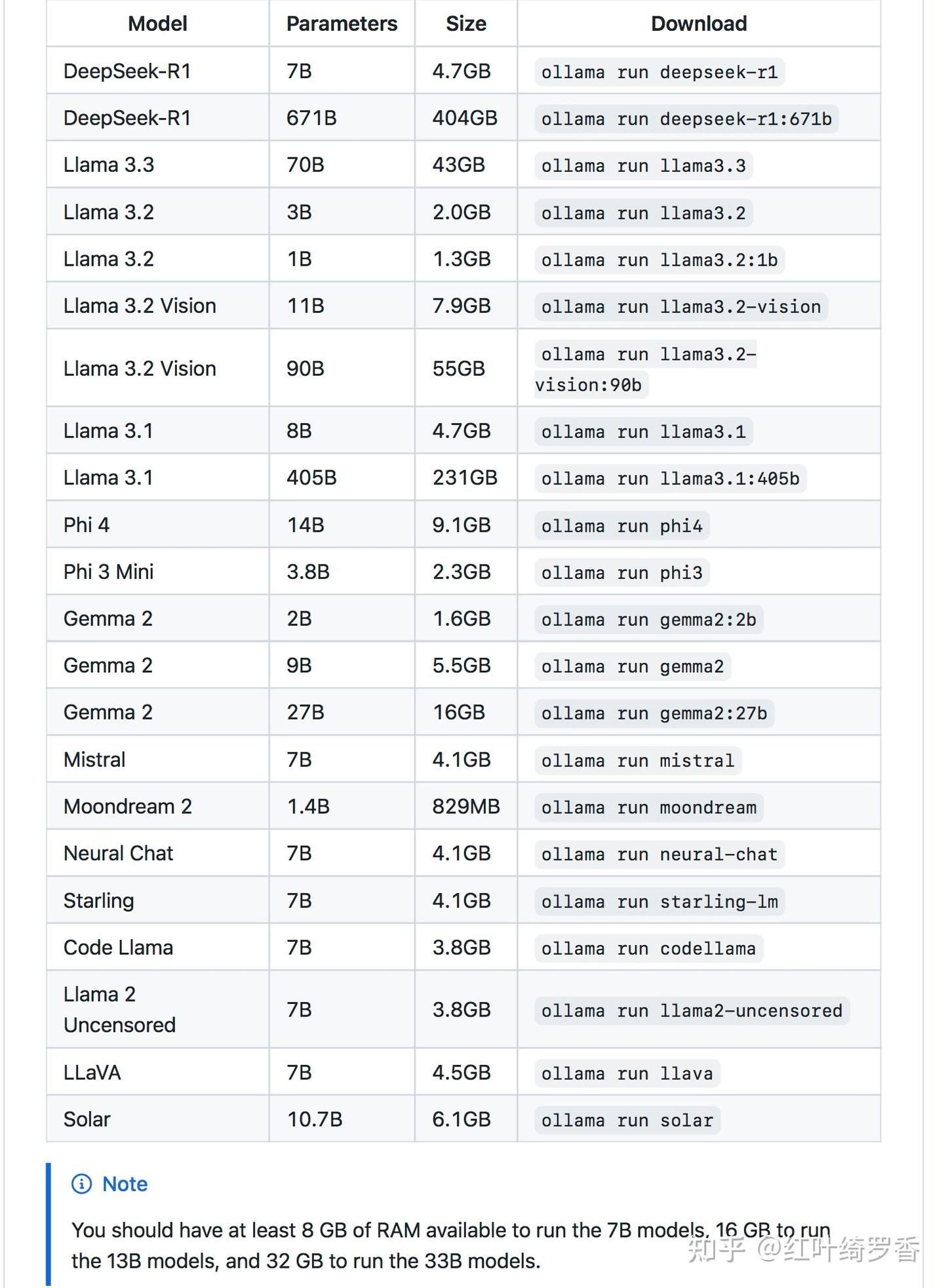
当然啦,个人电脑基本就只能考虑运行Distill这种蒸馏模型了。
DeepSeek-R1-Distill-Qwen-1.5B
ollama run deepseek-r1:1.5bDeepSeek-R1-Distill-Qwen-7B
ollama run deepseek-r1:7bDeepSeek-R1-Distill-Llama-8B
ollama run deepseek-r1:8bDeepSeek-R1-Distill-Qwen-14B
ollama run deepseek-r1:14bDeepSeek-R1-Distill-Qwen-32B
ollama run deepseek-r1:32bDeepSeek-R1-Distill-Llama-70B
ollama run deepseek-r1:70bDeepSeek-R1
ollama run deepseek-r1:671b以部署deepseek-r1:14b为例,终端输入ollama run deepseek-r1:14b即可。首次运行会自动下载模型,一般前半段下载速度很快,后半段要是特别慢就关闭电脑网络,等到下载速度变成零再开启网络,下载速度基本就能恢复了。
以后每次在终端里面使用,也是输入同样的命令ollama run deepseek-r1:14b。删除不用的模型则使用ollama rm deepseek-r1:14b命令。
我建议你先在终端里面尝试一下,很可能尝鲜之后就不玩了。而如果你觉得本地大模型有搞头,那就可以进一步折腾一下UI界面了,比如像ChatX这类软件,可以接入本地模型,避开使用终端。
对于大语言模型这玩意,我还是建议你优先考虑使用在线的解决方案,能够选择付费的优质模型就更好了。
这个逻辑其实很简单,当你有一个重要问题需要解决的时候,有A、B、C三个都不错的专家,A的知识储备明确高于B、C,随时随地都能咨询,而且很少不懂装懂。而B、C不仅知识库还是一两年前的,还需要你搭进去硬件资源和时间成本,更夸张的是B、C还可能经常胡说八道,那你会选择问谁呢?