为什么很多人宁愿用手机语音输入,也不用 Windows 自带语音识别?
为什么很多人宁愿用手机语音输入,也不用 Windows 自带语音识别?
前段时间,我发现一个有意思的现象。
很多人坐在电脑前工作时,明明 Windows 已经自带了语音输入功能,但他们还是会拿起手机,对着手机说话,然后再把内容发到电脑上。
刚开始我觉得这有点奇怪。
后来观察得多了,才发现原因并不简单。
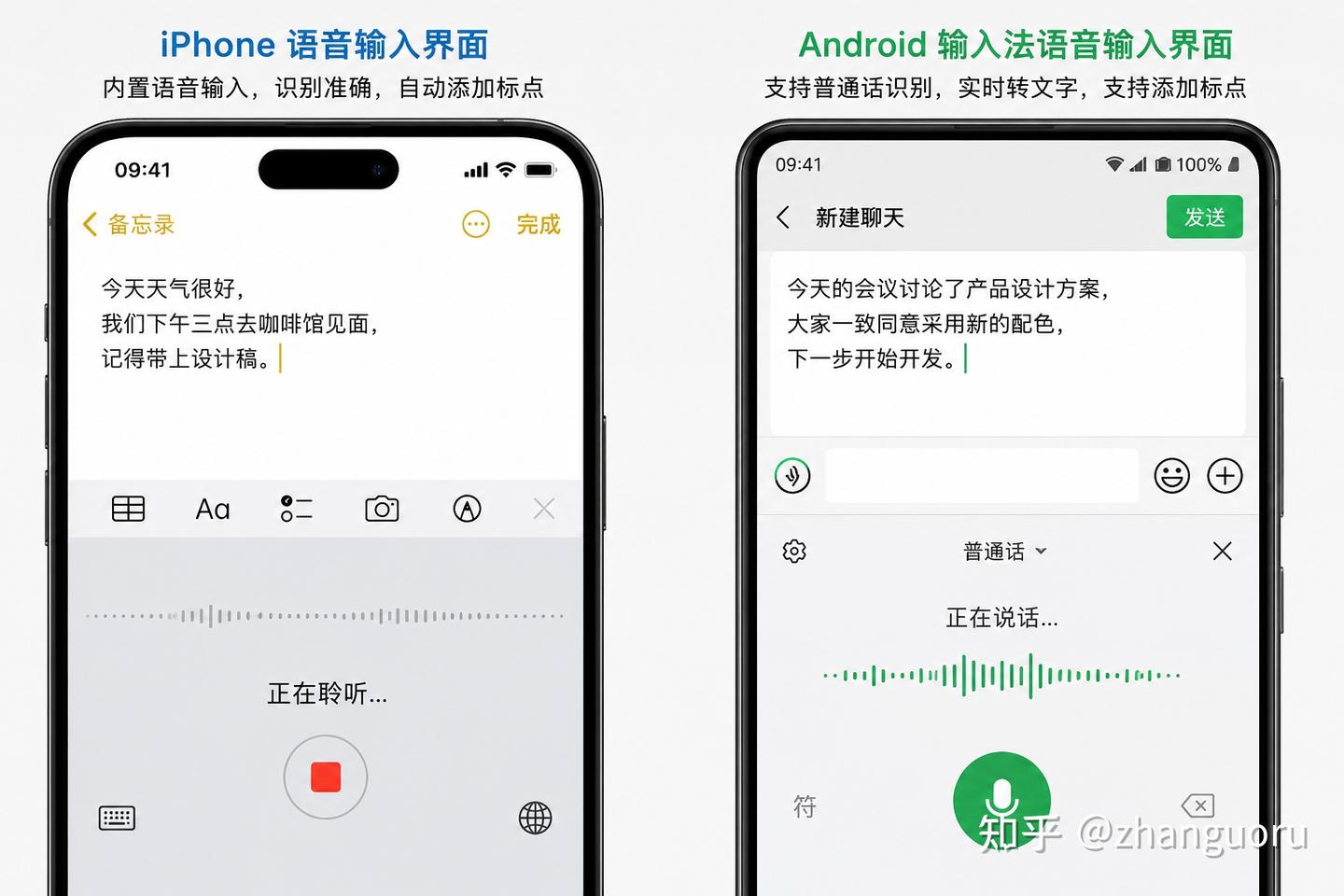
手机语音输入,已经进化了很多年
很多人对电脑语音输入的印象,还停留在:
- 识别错误很多
- 断句混乱
- 标点符号不准确
- 必须一字一句慢慢说
但实际上,现在大部分人每天使用的语音输入,并不是电脑上的。
而是手机上的。
苹果、华为、小米、OPPO、vivo 等厂商,每年都在投入大量资源优化手机输入法。
对于很多用户来说:
发微信语音转文字、
搜索内容、
回复消息、
记录想法,
早已经成为习惯。
- iPhone 语音输入
- Android 输入法语音输入
这些功能经过了数亿用户的长期使用和反馈。
所以很多时候你会发现:
同一句话,
手机能够准确识别,
电脑却可能出现多个错误。
Windows 语音输入的问题在哪里?
这里并不是说 Windows 的语音输入不能用。
事实上,现在的 Windows 语音输入已经比几年前好了很多。
但是对于普通用户来说,仍然存在几个明显问题。
1. 使用场景不连续
很多人平时已经习惯了:
拿起手机说话。
让他们切换到电脑麦克风输入,
反而增加了学习成本。
2. 麦克风环境复杂
电脑麦克风的位置并不固定。
有的人使用:
- 笔记本内置麦克风
- USB麦克风
- 蓝牙耳机
不同设备的识别效果差异很大。
而手机的麦克风阵列通常经过专门优化。
在降噪和拾音方面往往更稳定。
3. 多设备办公越来越普遍
现在很多人的办公桌面上同时存在:
- 手机
- Windows电脑
- Mac
- 平板
语音输入并不是唯一问题。
更大的问题是:
如何让内容快速出现在当前工作的设备上。

- 手机
- 电脑
- 平板
同时工作的场景。
真正的问题其实不是语音识别
后来我发现一个事实。
大多数人需要的并不是:
更好的语音识别软件。
而是:
如何把已经识别好的文字快速送到电脑。
这是两个完全不同的问题。
如果手机已经能够准确识别语音,
为什么还要重新在电脑上识别一次?
举个简单例子。
假设你要写一封500字的邮件。
方案A:
打开电脑语音输入。
对着电脑说话。
等待识别。
检查错误。
修改内容。
方案B:
直接使用手机语音输入。
识别完成。
一键发送到电脑。
直接粘贴。
继续工作。
很多用户最终选择了第二种方式。
原因很简单:
他们更相信自己每天都在使用的手机输入法。
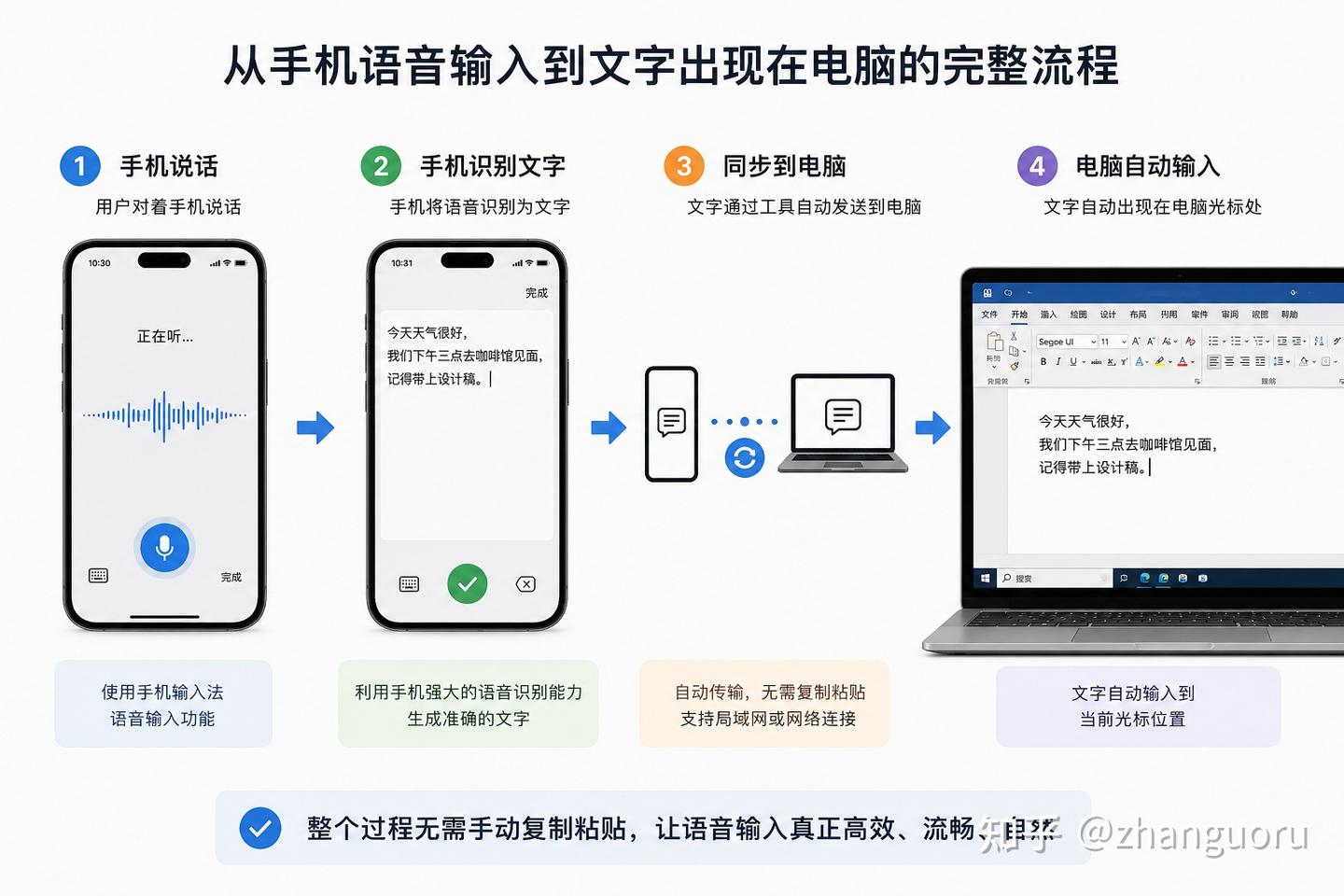
手机说话
↓
手机识别文字
↓
同步到电脑
↓
直接输入
我后来做了一个小工具
正是因为这个原因。
我后来写了一个小工具。
它并不尝试重新发明语音识别。
也不训练新的 AI 模型。
思路反而非常简单:
既然手机已经能够很好地完成语音转文字,
那就直接利用手机已有的能力。
把手机变成电脑的输入设备。
用户需要做的事情只有三步:
- 手机语音输入
- 自动发送文字
- 电脑自动接收
整个过程不需要复制粘贴。
也不需要频繁切换设备。
http://192.168.2.51:58721/?device=ba75a2f5eebff5634e72b0d07c95eeac84f9d18c5dce19e06bc0c07e261a947e&token=190e7f82e993d63fcd3043c6964fa1f0 (二维码自动识别)
手机端输入-手机扫码即可,不需要安装APP
- 电脑端自动出现文字
技术越来越复杂,但工具应该越来越简单
这些年我们看到很多 AI 产品不断出现。
模型越来越大。
参数越来越多。
功能越来越强。
但对于普通用户来说,
他们真正关心的问题其实一直没变。
不是:
这个模型有多少参数。
而是:
我能不能更快完成工作。
有时候最好的解决方案,
并不是再造一个新的系统。
而是把已经存在的工具连接起来。
让用户少点一次鼠标。
少按一次键。
少切换一次设备。
这往往比增加一个新功能更有价值。
如果你平时也习惯使用手机语音输入,
或许会发现:
真正高效的不是语音识别本身。
而是让文字出现在正确的地方。