为什么2026年了却感觉电脑CPU性能与三年前对比没有明显进步?
一个有趣的数据:2025年2月,PassMark公布了自2004年有统计以来,全球PC CPU平均性能首次出现年度下降的数据。2024年全年桌面CPU平均测试成绩26436分,2025年同期样本降至26311分,笔记本端从14632跌到14130,跌幅3.4%。
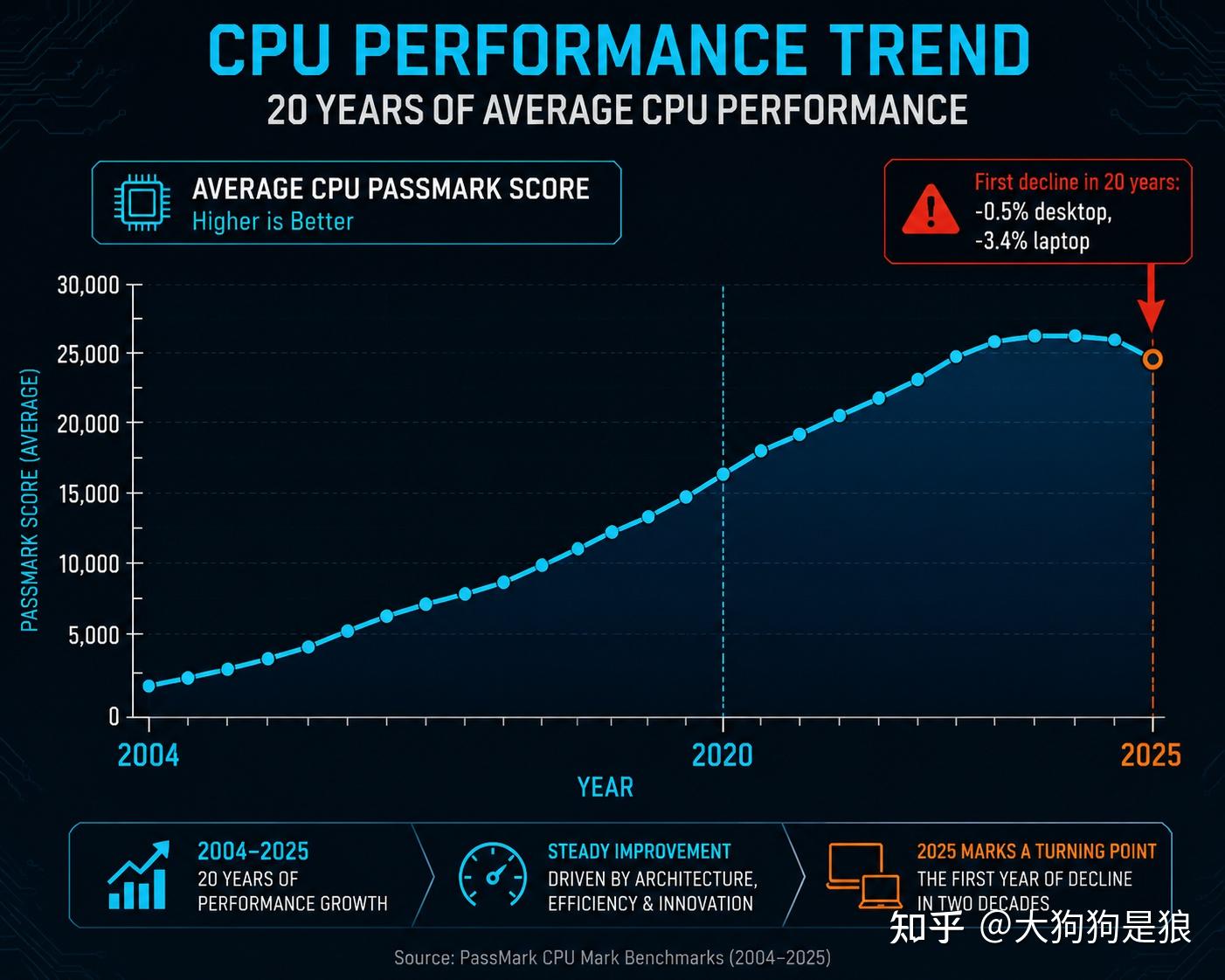
你的13900KF是2022年底买的。三年后的旗舰,9800X3D发布于2024年11月,8核16线程。technical.city的对比数据显示13900K的综合得分比9800X3D高约46%,当然那是24核堆出来的多核优势。但这也说明了一件事:过去三年,x86在核心架构层面几乎没有实质性的代际跨越,”更多核心数”这个数字游戏正在掩盖增长的停滞。
首先来说Zen 5,最有意思的是那颗双解码前端。AMD 在2024年 Hot Chips 上宣称 Zen 5 实现了平均 16% 的 IPC 提升,数字本身不差。但 Chips and Cheese 跟 AMD 工程师的场边对话揭了一个尴尬的细节:Zen 5 的双解码集群设计,单线程运行时只能激活其中一个。原因是把两条乱序指令流重新排序送入微操作队列时碰到了工程难题,而 Zen 5 的频率目标远高于 Intel 的 E-Core(后者确实能让单线程同时利用两个解码集群)。所以双解码前端对桌面用户跑单线程应用几乎无感。更大的执行后端、统一调度器、512位向量单元,确实让 AVX-512 和浮点密集型负载获益,但 Chips and Cheese 的分析指出,绝大多数实际应用的瓶颈卡在前端延迟和内存访问上,核心内部的执行能力早就不是短板了。
Intel 这边搞了更多小动作。Arrow Lake(Core Ultra 200S)是 Intel 桌面产品线自2002年以来首次移除超线程的一代,理由是异构核心设计下更多物理核心加上 E-Core 足够覆盖多线程需求。Apple 的 M 系列从来不做 SMT,Intel 认为自己也可以。问题是 Lion Cove P-Core 号称 IPC 提升 9%,但最高频率从 14900K 的 6.0GHz 降到了 285K 的 5.7GHz。IPC 涨的那点被频率的倒退吃掉了。 实测游戏性能不如上一代 14900K,Intel 自己公开承认了这一点。德国最大零售商 Mindfactory 的数据显示 Arrow Lake 上市一周后销量几乎归零。后来 Intel 的 Bartlett Lake 搞了个 12 纯 P-Core 的 Core 9 273PQE(虽然定位嵌入式/边缘计算),比 13900K 多 50% 的 P-Core,实测游戏仍然打不过一颗三年前的 13900K。
既然单核提不动了,多加几个核心总行吧?
装过 13900K 的人应该都有体会:360 一体水冷,默认电压,跑 Cinebench R23 直接撞温度墙。PL2 开放后随随便便跑到 300W,一块 RTX 4070 的 TGP 也才 200W。这颗 CPU 比一张中端显卡还费电。背后的物理根源是 Dennard 缩放定律在 28nm 之后就实质失效了:晶体管越做越小,但单位面积的漏电流和功耗不再等比缩小。结果就是”暗硅”效应,芯片上越来越多的晶体管无法同时通电,因为热密度不允许。13900KF 那颗 die 上塞了 24 个核心,但你很难让所有大核同时跑在 5.8GHz,电压加上了,但热量散不出去。

功耗墙逼着行业转向能效优化,而台积电和 Intel 的工艺进步近年来也越来越偏向”同性能降功耗”而非”同功耗提性能”。对手机和笔记本这当然是好事,对追求极限性能的桌面用户来说则意味着:制程进步的收益你几乎感觉不到,因为你的 CPU 本来就跑在功耗极限,省下来的电只能帮你少交点电费。
多核扩展还有另外一个限制:内存带宽和互联延迟。AMD 的 Chiplet 设计把 I/O Die 和 Compute Die 分开制造,灵活性和成本控制都上去了,但跨 Die 通信的延迟也跟着上去了。Intel 走的是 EMIB(嵌入式多芯片互连桥)加 Foveros 的路线,和 AMD 的 Infinity Fabric 在设计哲学上有本质区别,但两家在跨 Die 延迟上各有各的痛点。
9800X3D 在游戏场景中表现亮眼,靠的是第二代 3D V-Cache 堆叠的 104MB 缓存大幅降低了内存延迟敏感型工作负载的瓶颈。但 3D V-Cache 堆上去的 SRAM 层增加了热阻,反过来限制了最高频率。游戏性能的突破是用缓存换频率,把内存请求拦在 L3 而不是放出去跑 DDR5 的延迟。核心架构本身并没有变得更聪明。
那换更先进的工艺呢?
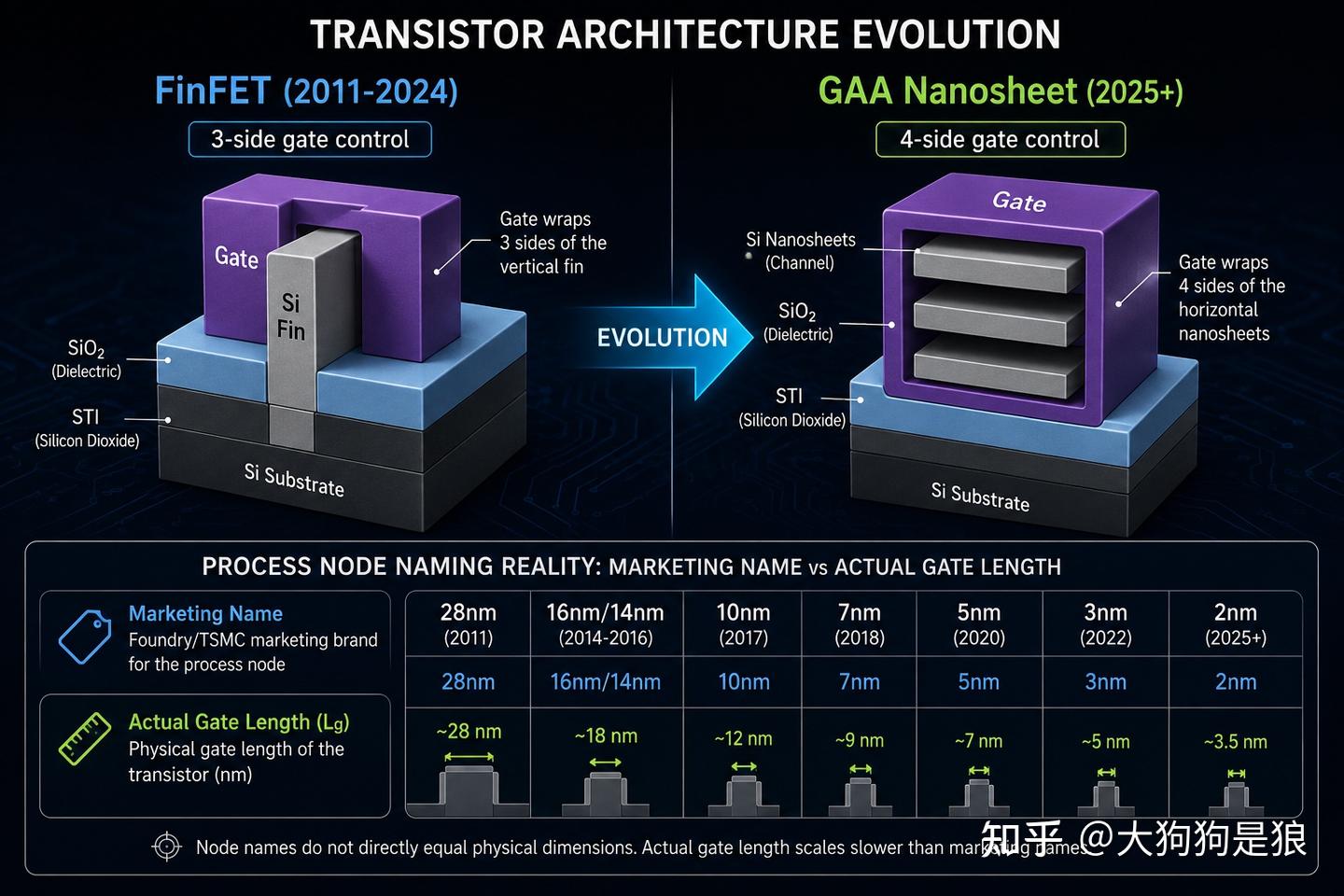
这里有个不太好意思说的事实:制程节点的纳米数字早就是个营销标签了。Intel 的”Intel 7”实际栅极长度在 10nm 级别,台积电的”N3”也不是 3nm。你的 13900KF 用的是 Intel 7 工艺,Arrow Lake 转用了台积电 N3B,但 Intel 自己的 20A 节点被取消了,集中资源开发更远的 18A。Intel 在制程追赶的关键一代出现了断档,甚至把旗舰桌面 CPU 的 Compute Tile 交给了台积电代工,这在 Intel 历史上是头一回。
台积电的 N2(2nm)已于2025年第四季度量产,采用 GAA 纳米片晶体管。相比 FinFET 三面栅极包裹,GAA 实现了四面全包裹,漏极感应势垒降低(DIBL)改善显著,这是 5nm 以下 FinFET 物理上无法企及的。但 GAA 引入了 4 到 5 个全新工艺模块,制造流程延长了约 20%。台积电官方数据:N2 在相同功耗下速度提升 10% 到 15%,或相同速度下功耗降低 25% 到 30%。听着不错?对比 2014 到 2017 年间每次制程迭代 30% 以上的速度提升,这个幅度已经相当温和了。而且每片晶圆的设备密集度增加了 30% 到 50%,意味着成本也在上涨。
更少人关注的是,先进封装已经成为比晶体管密度更紧迫的瓶颈。NVIDIA 独占了台积电 CoWoS-L 产能的绝大部分(各季度波动,但多数报告给出的数字在六到七成之间),Blackwell 处理器 2024 年的推迟就因为 CoWoS-L 良率问题,不同材料的热膨胀系数不匹配导致翘曲和连接故障。就算你做出了世界上最先进的计算芯片,封不到 CoWoS 中介层上就只是库存。Chiplet 市场 2024 年 58 亿美元,预计 2030 年增长到 794 亿美元,封装的复杂度和成本正在以惊人的速度吞噬制程进步的红利。

说到这里,一个被忽视的隐性因素值得提一下,安全补丁也在吃你的 IPC。
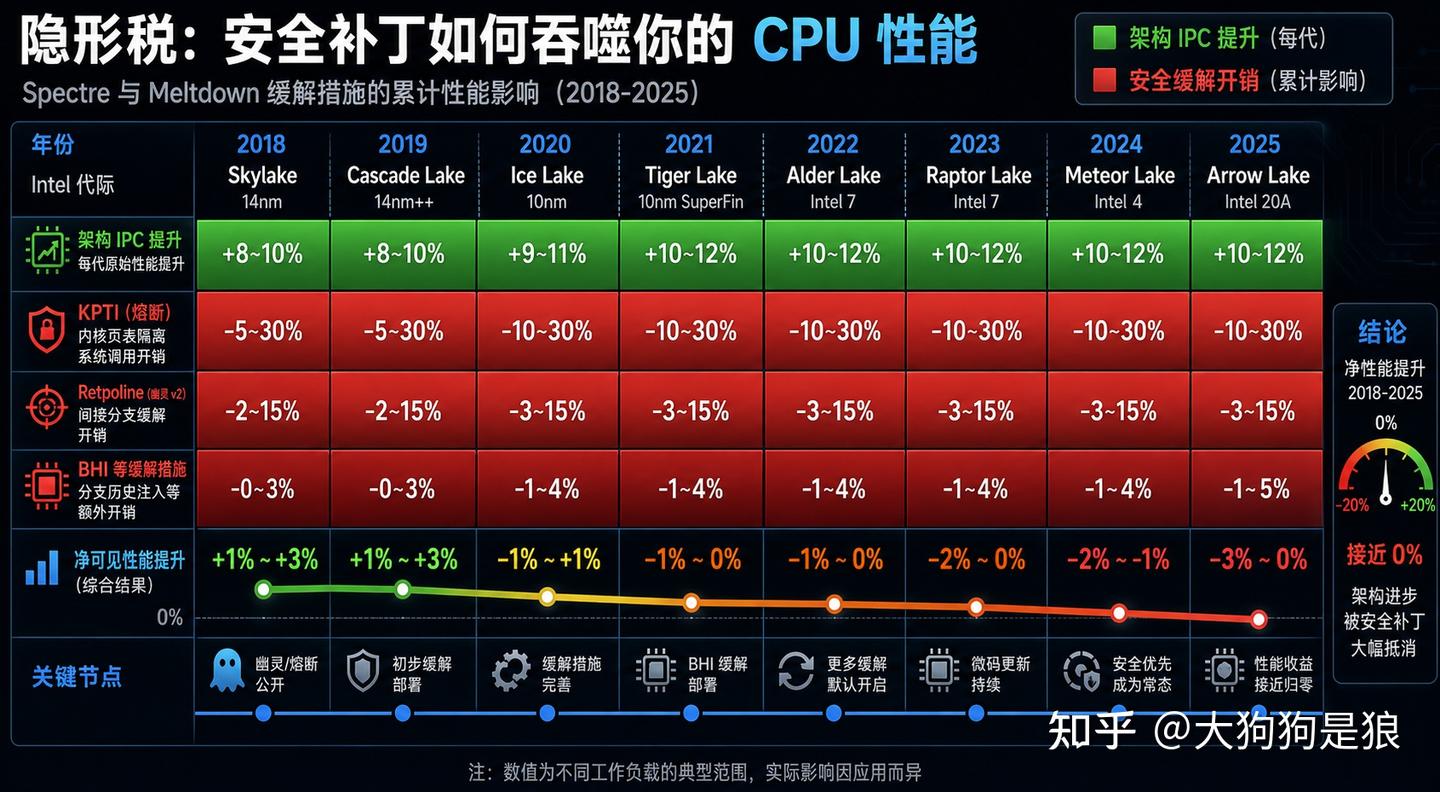
2018 年 Spectre 和 Meltdown 漏洞曝光以来,x86 处理器一直在为推测执行的副作用买单。Linux 内核文档记录的典型性能开销:
- KPTI(内核页表隔离)对系统调用密集型工作负载造成 5% 到 30% 的性能损失
- Retpoline(替换间接分支)的代价是 2% 到 15%,取决于间接调用频率
- 后续 Spectre v2 的 BHI(分支历史注入)变种的缓解措施进一步加重了负担
Intel 从 Skylake 到 Rocket Lake 的多代产品在硬件层面逐步修补这些漏洞,部分 IPC 提升被安全补丁的额外开销对冲掉了。跑分涨了 8%,安全补丁吃掉 3% 到 5%,你日常用着就是感觉没变化。 AMD 也受影响,程度略轻。
还有一个很少被讨论的碎片化问题:Intel 从 Alder Lake 开始在消费级平台禁用了 AVX-512,因为 E-Core 不支持这套指令。AMD Zen 4 和 Zen 5 则完整支持。同一段 x86 代码在 AMD 和 Intel 平台上的向量浮点性能可能差了两三倍。x86 生态内部的指令集割裂,让”跨平台性能一致性”这个 x86 最大的传统优势打了折扣。
但 ARM 和 RISC-V 怎么进步那么大?
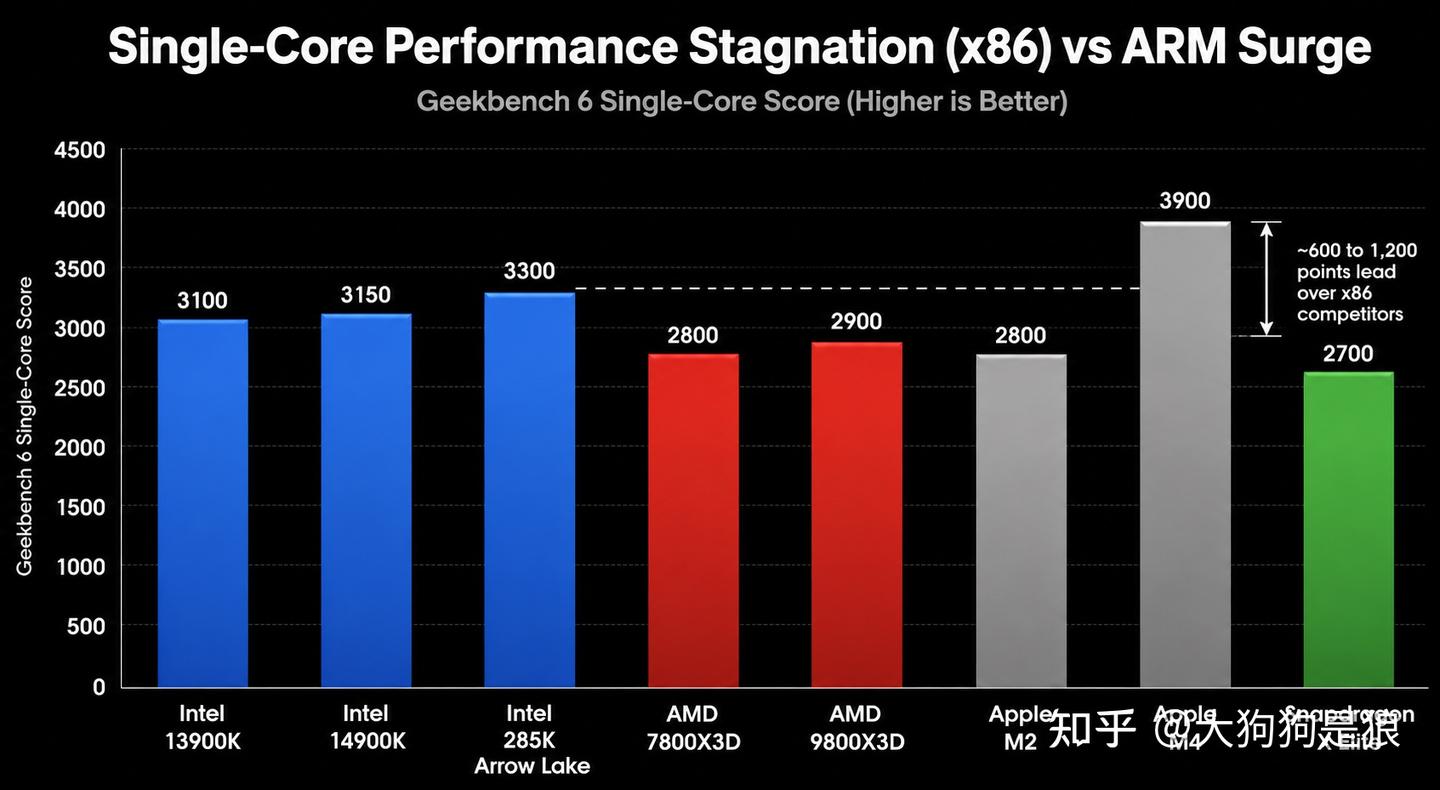
起点不同。ARM 在 2023 年的单核性能还明显落后,Apple M2 的 Geekbench 6 单核大约 2800,13900K 大约 3100。M4 直接跳到了 3800 到 4000,两代之间提升超过 35%,功耗不到 x86 旗舰的十分之一。
ARM 能做到这个速度,根子在于设计包袱轻。ARM 从第一天就是 RISC,4 字节定长指令编码,硬件解码复杂度远低于 x86 那套 1 到 15 字节变长指令。Intel 和 AMD 的 CPU 前端要花大量晶体管去猜测指令边界、解码变长指令流,而 ARM 的解码器面对的是规整的定长包,同等晶体管预算下可以分配更多资源给执行单元和缓存。
Apple 的 Firestorm 及后续核心架构做到了 8 宽度解码和巨大的 reorder buffer,这种设计放到 x86 上需要不成比例的面积代价。Geekbench 6 的 Mac Benchmark 数据显示,M4 Max 单核 4018,M4 基础版 3822,Mac Studio 2025 款搭载的 M4 Max 多核冲到 22000 以上。
高通 Snapdragon X Elite 的自研 Oryon 核心 12 核设计,单核性能已经逼近 Zen 4 水平。Windows on ARM 的软件生态仍然是短板,但硬件层面的效率优势无可争议。
RISC-V 的故事更值得单独看。它目前在高性能桌面和服务器市场还不构成直接威胁,但 SiFive 在 2026 年初宣布与 NVIDIA 达成 NVLink Fusion 合作,让 RISC-V CPU 直接连上 NVIDIA 的 GPU 互联协议。Tenstorrent 的 Ascalon 高性能核心路线图也在推进。RISC-V 的核心优势是指令集完全开放、可自由扩展,任何公司都可以基于 RISC-V ISA 设计核心并加入自定义扩展指令,无需向 ARM 支付授权费。这在 AI 芯片领域极具吸引力:CPU 核心中可以直接嵌入矩阵运算指令和专用张量处理单元。ARM 和 x86 都做不到这一点,后者的 ISA 扩展受制于单一控制方。
所以你的 13900KF 三年后还能打。
Intel 的 Nova Lake 桌面版据爆料将带来显著 IPC 提升,18A 工艺有望恢复制程竞争力。AMD 的 Zen 6 预计引入多层 3D 堆叠缓存。但更根本的问题是:x86 作为一门 1978 年诞生的指令集,变长编码带来的前端复杂度是 ARM 和 RISC-V 不需要承受的结构性负担。
真正的问题是:如果再等三年,你换的下一台电脑,CPU 还会是一颗 x86 吗?2027 到 2028 年,如果一台 ARM 笔记本能无痛运行你手头 90% 的 Windows 软件,功耗只有现在的一半,价格还更便宜,你换不换?
这不是个技术问题。是个时间问题。
参考来源:
- PassMark 年度 CPU 性能趋势(TechSpot 报道)
- technical.city:i9-13900K vs Ryzen 7 9800X3D 对比
- Chips and Cheese:Discussing AMD’s Zen 5 at Hot Chips 2024
- Wikipedia:Arrow Lake (microprocessor)
- 台积电先进封装瓶颈分析(腾讯新闻)
- Man Group:Bending Moore’s Law: Single-Core Stagnation and the Cloud
- Geekbench Mac Benchmark(browser.geekbench.com)
- Intel Core 9 273PQE 规格(Intel 官网)
- Linux Kernel Internals:Spectre and Meltdown 性能影响
- Reddit r/hardware:Bartlett Lake vs 13900K
- SiFive:RISC-V Software Progress in 2024