Intel 核显编年史:从Gen 6到Xe3的破茧之路,量变引起的质变
趁着Panther Lake发布热度还在,已经为了麻痹今天黄金跌麻了的心情,特此肝一篇文章整理下Intel的核显发展。记得关注我的公众号“weibo_mebiuw”。
Gen6/HD3000 时代:开创核显时代
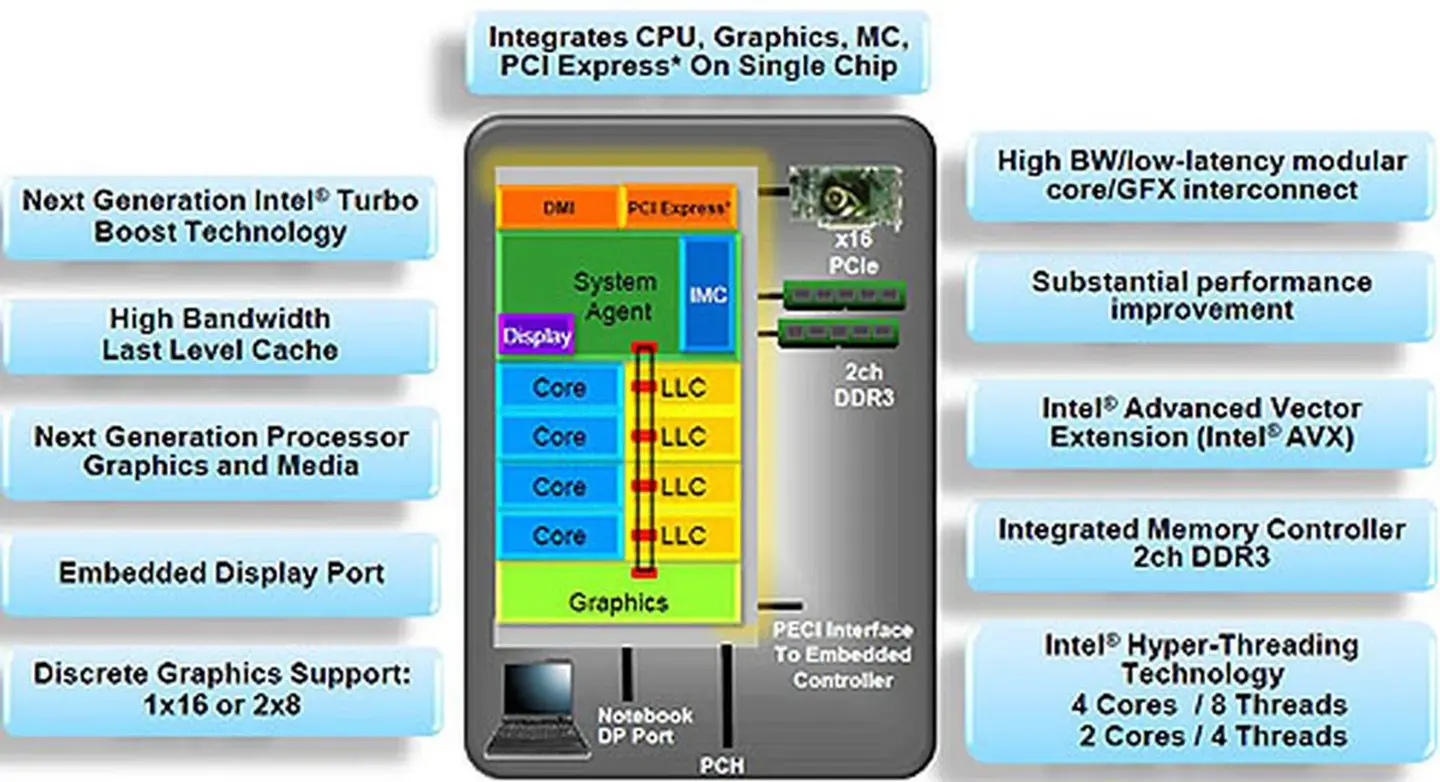
在2011年,Intel发布了全新的32nm 处理器Sandy Bridge 处理器,这款处理器不但开启了Intel的Ringbus的互联基础,也将整个消费级的CPU彻底SoC化。 从Sandy Bridge 开始,Intel的CPU不仅仅将IMC、PCIE等高速总线加入到CPU中,也将GPU核心引入到了同芯片的CPU中,所以此时“集成显卡”得以改名“核心显卡”。
Sandy Bridge 这一代的核显是Intel的第六世代架构,也就是我们俗称的Gen 6。 很多人在说核显是AMD的APU开创的,但从Sandy Bridge的发布时间来看,二者实际上同期的产物,在CPU内集成显卡并不是真的AMD开创。 而APU开创的东西,AMD自己都还没实现,甚至Intel的实现进度更高。
从现在开始,Intel的主流端核显(GT2)已经开始挑战低端独显,开始和AMD互相争斗了。自此以后,X86这边的核显一直是打的你来我往。
Gen7-8/HD Iris 4000-6000时代:大核显鼻祖、X3D鼻祖
在Gen 6之后Intel 在22nm Ivy Bridge 引入了 Gen 7架构的GPU,但这一代实际上没什么值得说到的地方,比较平稳的一次性能提升。而真值得说道的是给Haswell 用的Gen 7.5架构核显。
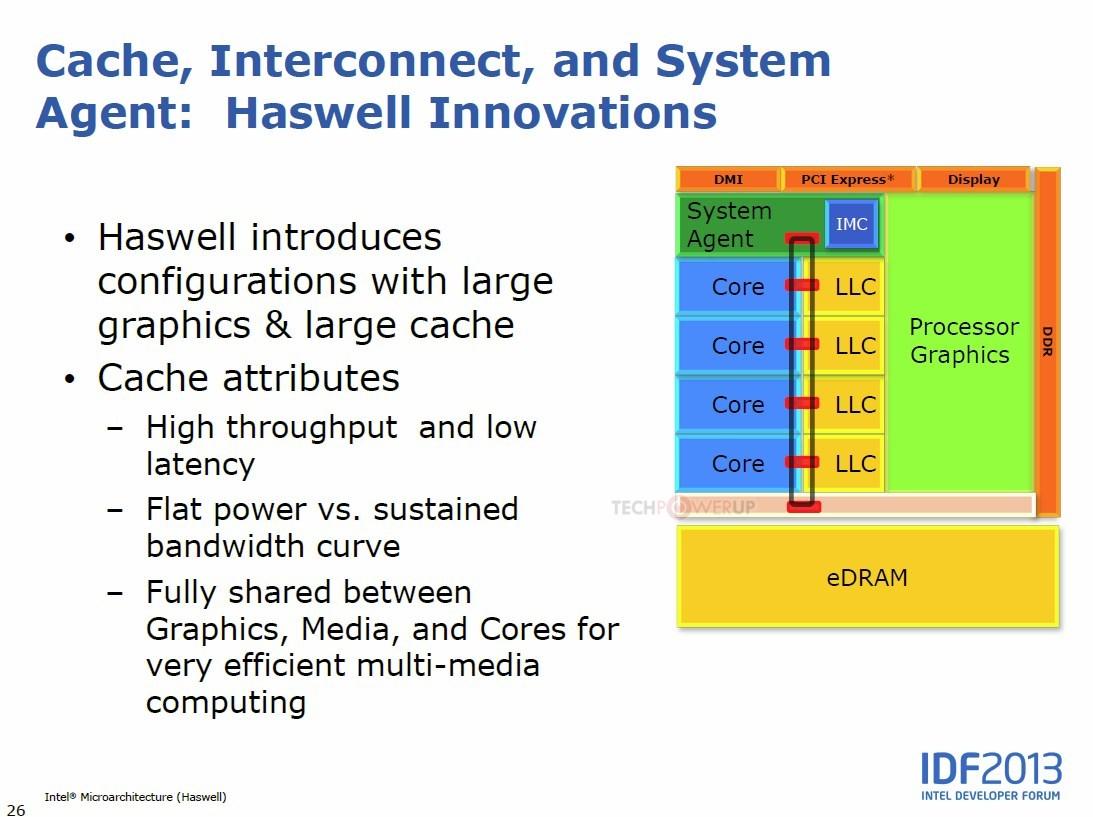
当年得益于Apple MacBook和Intel的高度绑定,Intel在Haswell 上引入了Iris 核显 GT3和GT3E,是Intel传统显卡HD Graphics GT2的两倍规模。 Intel和GT2核显一般和当前的内存带宽极限绑定,因此在规模翻倍的GT3上Intel 就开始遇到了内存带宽瓶颈。 这个时候,Intel也学习当初的XBOX主机,外挂了一个EDRAM上去做缓存。注意这里的EDRAM还不是完全意义上的L4。 从这个时候开始,Intel的GT3E已然成为X86的第一个大核显,妥妥的鼻祖。而且这个外挂额EDRAM也能被CPU使用,实际已然成为L4缓存。 现如今,从搭载EDRAM的Broadwell R来看,这个L4对于CPU游戏性能帮助非常显著,就如同当今的X3D一样。
而Gen 8时代是Intel 转向14nm的时间,可能受制于良率问题,Intel并没有在这代芯片上做太多规模升级。 Gen 8主要就是工艺和特性设计,最高GPU规模上仍然沿用GT3E的设计,整体不算显著也不持久。
Gen 9/ HD500/600 时代:又大又持久
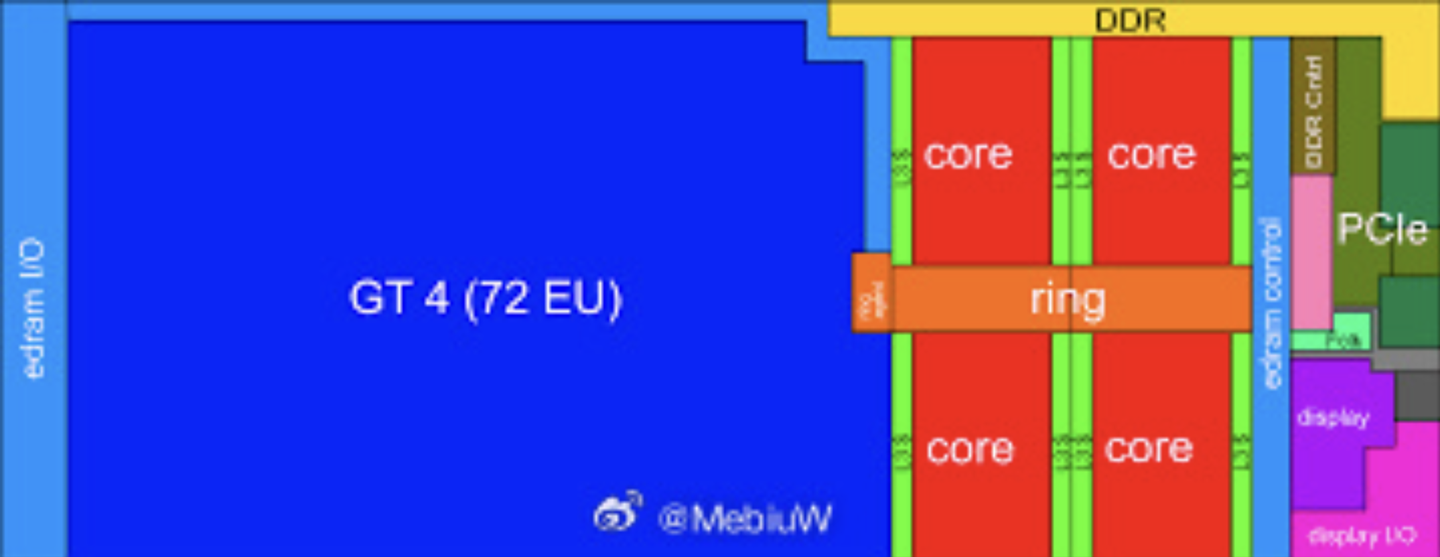
如果说Intel的Gen 8 GPU的雄起时间并不持久,那么Gen 9绝对是持久的让各个机友大呼救命受不了。因为,Gen 9 和Intel 名声赫赫的14nm Skylake是完全绑定的,有几代Skylake就有几代Gen 9。
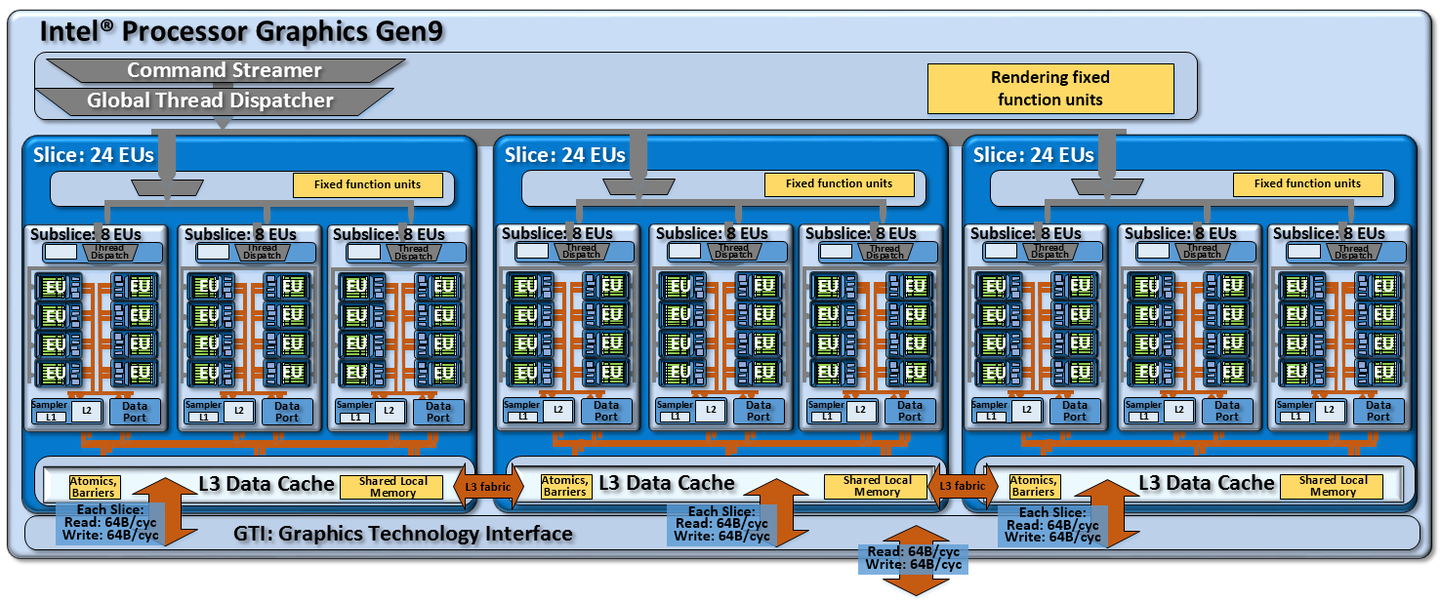
而且Intel的Gen 9的威力还不仅仅是持久那么简单,这也是Intel GPU最大的一次。因为在Gen 9里,Intel 第一次也是最后一次推出了相当于GT2三倍规模的GT4e核显,算起来比例是远超如今的Strix Halo的。不过也就是这个又大又持久的Intel Gen 9 GPU,也成为了Intel 大核显之路的绝唱。 Apple也因为受不了Intel Skylake + Gen 9 + 14nm这个大宝贝组合,开启了自个研芯片之路。
Gen 10:Intel的老六 GPU

给葫芦娃拍照,那么之后拍到6个葫芦娃,因为老六会隐身。 Intel的Gen 10 GPU实际上也是老六~ 因为这是10nm Cannon Lake官配的GPU架构。 Cannon Lake 虽然后面被Intel剔除族谱,但至少还出来过。 而Cannon Lake的 Gen 10 GPU 则直接被屏蔽,至今查无此GPU。
Gen 11:开启GT2的战斗模式
Gen 11 GPU是Intel 10nm Icelake的官配GPU,虽然这时候10nm依旧不堪用,Intel 的芯片也即将被Apple抛弃~ 但也正是开启了Intel的GT2核显战斗模式。Icelake 开始,Intel不再推出自带缓存的GPU,上限也止步GT2。但也是从Icelake开始,Intel的GT2核显开始得到史诗级加强。

Icelake的GT2核显一下子就给干到了64EU,已经超过之前Gen 9 GT3的48EU,非常接近GT5的72EU了~ 也正因此, Intel不再需要用GT3 GT4和AMD 的核显斗法,GT2开始就和AMD的高端核显你拉我扯了,基本上谁家推出新一代GPU,那么就是谁家的GPU更强。
Gen 12:又一个持久的临时工
Intel自Gen 11 GPU之后,就不再主动使用Gen x去代表GPU架构了,并且此时开始说Xe 核显了。 但从后面的情况来看,这时候的Gen 12 Xe 并不具备正式编制,就和Core 、Core 2并不是第一代、第二代酷睿一样,Xe 也并不是我们之后说的 Xe 1~

Gen 12 实际上应该被叫做Xe LP,首发于Icelake的小幅迭代版Tiger Lake,而且也被搭载在后续的14nm Rocket Lake,以及整个Alder Lake、Raptor Lake。 所以实际上如今大家还在用的14代酷睿,也依然还在用这个Xe LP架构。 Tiger Lake 首发的GT2 Xe-LP规模达到了96EU,当初性能还是非常不错的,又一次领先同期AMD。 但无奈就是这东西后面一直止步不前,Alder Lake和Raptor Lake 都维持了96EU,所以现如今很多人都忘了这代GPU的辉煌时刻。
Xe LPG的炼金术士时代(Alchemist):开启Core Ultra的智能未来
Intel 在即将进入14代酷睿的时候,突然宣布移动端的Meteor Lake系列SoC将会换用全新的Core Ultra 品牌。 与此同时,Intel 也正式开启了自己的独立显卡之路,Xe 架构 也终于有了正式品牌ARC品牌。

Meteor Lake首发的ARC核显为Xe LPG架构,虽然在Intel的归类里折也还是Gen 12的一员(12.7),但已经发生了翻天覆地的变化。 Meteor Lake的ARC Xe-LPG核显已经脱离了Sandy Bridge 开创的挂在Ringbus上的模式了,转而采用了胶水Tile 模式。而且此时,Intel的Xe LPG+也率先放弃了Intel的工艺启用了台积电的工艺,更高的密度也容许了8Xe核显128EU的规格。 得益于这些改变,Meteor Lake的GPU性能翻倍,爆杀AMD的Radeon RDNA2 12CU核显。
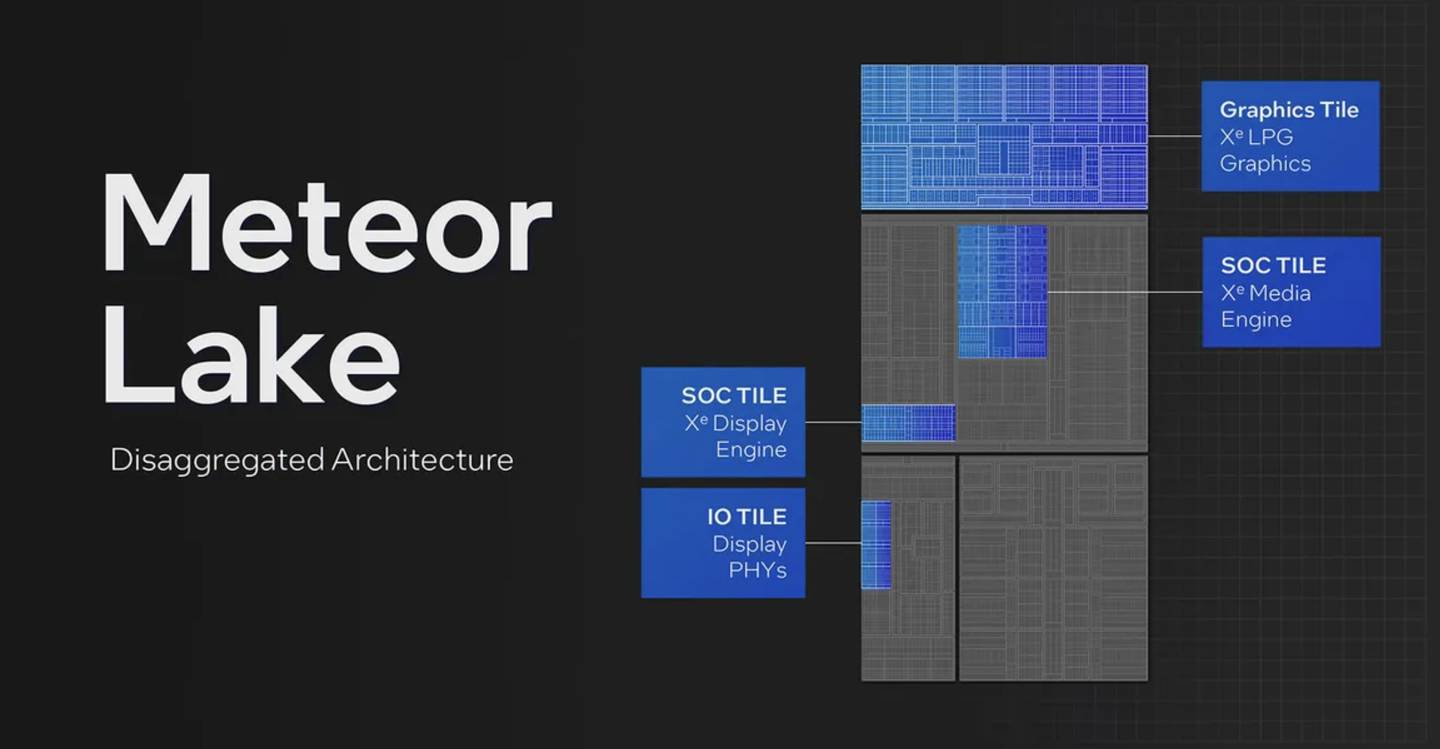
Xe LPG的GPU其实远不止上面的性能变化,Xe LPG架构也拥有非常强大的计算能力,能够很好地支持Intel XeSS这样的类DLSS技术。而且后面在Core Ultra 200 Adler Lake 时代,Xe LPG还小幅进化到LPG+,补全了矩阵计算性能,彻底开启了Intel核显的AI智能化时代。
Xe LPG虽然看着已经是N-2的产品,但最新的产品实际也是去年的Alder Lake,基本上Xe LPG的光栅GPU性能算是略低于AMD的RDNA3.5 16CU(Strix Point)高于12CU的RDNA2,但在光追 AI 媒体解码这些地方花式吊打AMD。所以自这个时候开始,哪怕别人吐槽Intel核显高分低能,我也推Intel的核显。
Xe 2的战斗法师时代(Battlemage):OK NEXT
Xe 2 核显首发于Intel的绝代Lunar Lake,也绝代于Lunar Lake。 从IP层面,Xe 2其实改进挺多的,我也夸赞过挺多,但问题是Xe 2在移动端核显上的应用实在有限,其主战场在独显上。 所以这里我不想多说。

简单来说,Xe 2核显在各个方面都得到了强力增强,换用了台积电N3B工艺,但只有Lunar Lake搭载且功耗限制严格,低功耗下至今仍是战神,高功耗下和Xe LPG+差不多上不去。
Xe3时代(Celestial):优势从未如此之大

Xe 3则是刚刚发布不久还未正式上市的Panther Lake所使用的GPU架构,其表现相信已经有目共睹了,在高效率架构、先进工艺、以及堆料的三重Buff下,AMD老掉牙的RDNA3.5 是被全方位无死角的吊打。
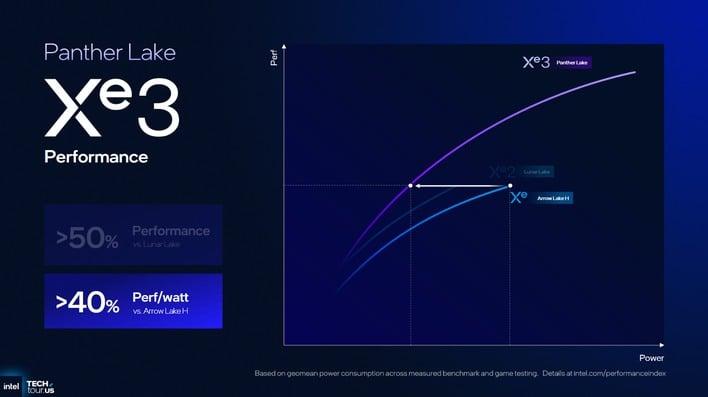
不知道Intel是有意还是无意,在Panther Lake的早期预览中,Intel对于Xe 3的性能表述可谓相当挤牙膏,对比一代的Xe LPG+也就提升40%,一点对不起增加了50%的规模以及N3E工艺。我当时甚至立下豪言说要喷Xe 3一波,直到我发现了Xe 3 PPT里的猫腻~
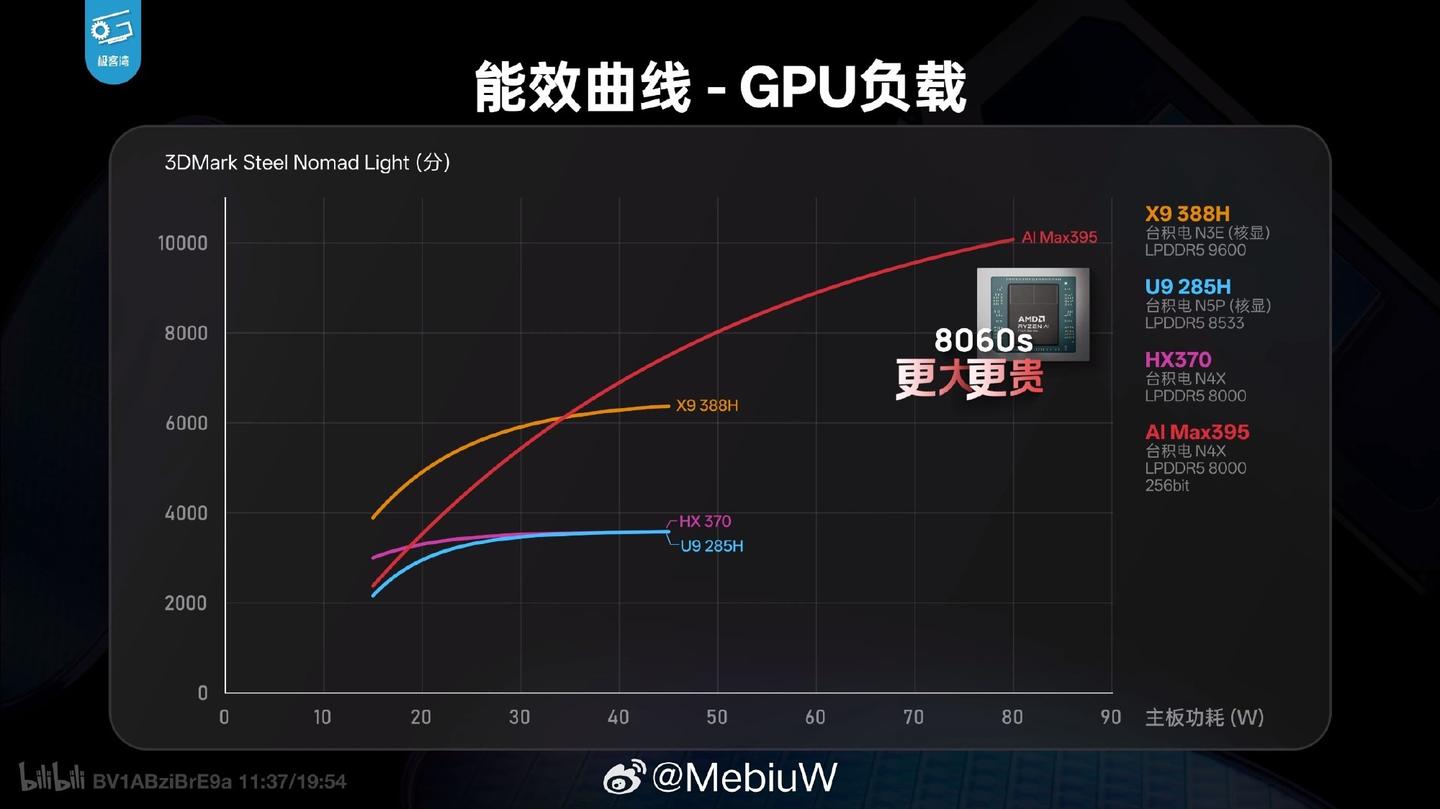
后面的故事大家也都知道了,Panther Lake的GPU在H45这个标准定位区间里无懈可击,勉强能“黑”的只有不考虑GPU性能和HX370比价格,不考虑定位和Strix Halo GPU比性能。
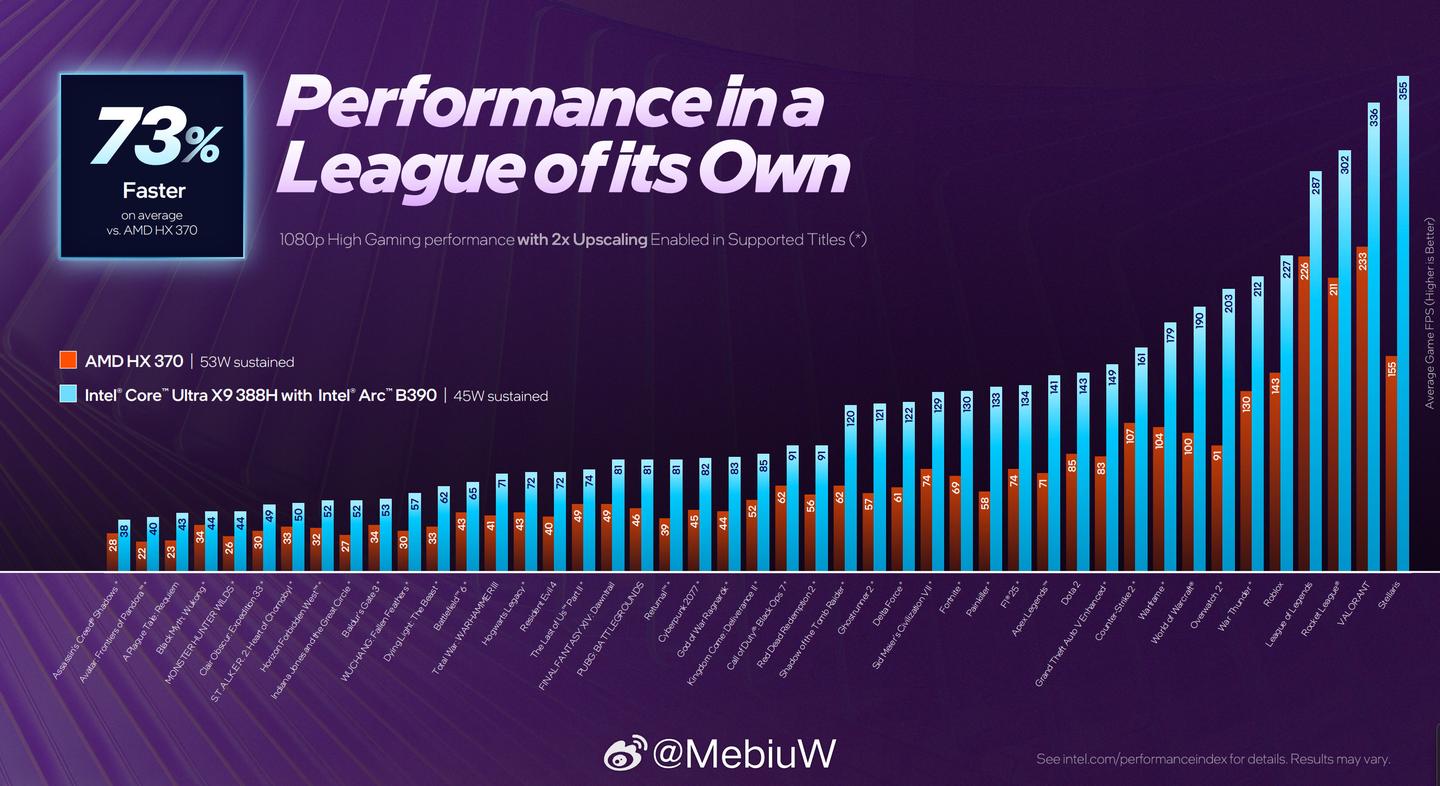
由于这里只是Intel核显的快速预览,具体的我就不多说了,以后再聊Xe 3. 记得关注我的公众号,weibo_mebiuw.
Xe3P时代:Nova Lake 核显展望
Panther Lake的GPU 大概会是Intel 这几年来进步最大一次,明年的Nova Lake H 在游戏性能部分我倒不是特别期待了,估计保持12Xe的规格下继续提升一些IPC和频率,性能按照传闻提升20%附近吧。 而我所期待的Nova Lake GPU部分则是Xe3P带来的AI特性变化。

Xe 3 架构最令人遗憾的地方就是矩阵加速XMX部分对比Xe 2的提升较小,没有紧跟时代做低精度浮点的推理支持,仍然只支持FP16、BF16的浮点精度。 虽然Xe 3 依然有很不错的INT4的拓展支持,但显然从Nvidia 砍INT4 INT8 的角度来看,FP8 FP4才应该是未来低精度推理的方向。

从Intel第一个明确的Xe3P架构GPU Crescent Island 来看,Xe3P 终于在数据格式上补全了,已经明确支持如今颇为重要的FP4/MPXP4在内的4bit 浮点推理,大概率也会同样支持FP8,可以期待Nova Lake的Xe3P 也会同样支持这个特性。 从DLSS4.5来看,Xe3P 对于FP4的支持,应该可以迎来XeSS上的再一次进化,现如今的Panther Lake 在跑XeSS MFG的时候明显出现了AI开销较大的问题,应用FP4粗略算可以让开销直接减半。
总结
综上所述,说一句Intel在核显上从不挤牙膏应该没问题吧? Intel 在有条件更新核显的时候都是绝不吝啬,要工艺给工艺,要架构刷架构,要特性给特性.... 比起AMD 习惯性祖传古董GPU架构甚至倒吸规模的,这个态度好太多。记得关注我的公众号“weibo_mebiuw”。