畅想下一代内存技术LPDDR6:杀死GDDR的开始!
4 通道 LPDDR6 的大核显产品不仅在内存带宽上显著压过 128bit 60 系显卡,其还有统一内存这一真正杀器。
新春快乐,马年大橘~ 记得关注我公众号 weibo_mebiuw.
今天我们聊聊我个人非常看好的一代内存技术 LPDDR6,因为 LPDDR6 的出现非常有希望引爆消费端的 AI 变革,让消费端(手机、个人 PC)的 AI 变得不再鸡肋,甚至能够进一步带来芯片形态的变革。
LPDDR6:革了祖宗之法的提升
作为第六代 LPDDR 技术,LPDDR6 这一次在内存带宽的增幅上取得了史诗级提升。为什么说是史诗级呢?因为不同于以往 LPDDR 的 Gen2Gen 增益仅仅只是将内存速率提升,LPDDR6 这次同时增加了内存速率和内存位宽。
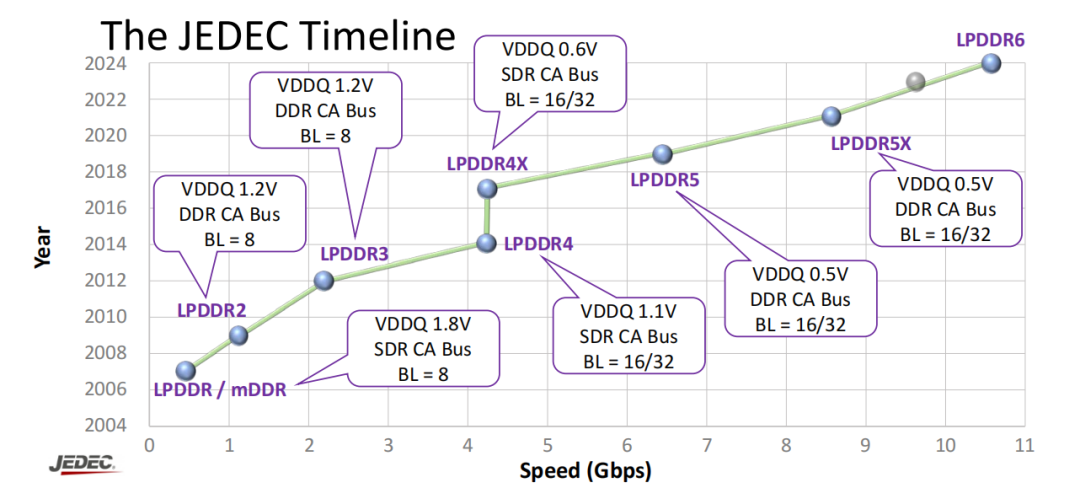
在过去,手机端/PC 端所主流配置的双通道 LPDDR 内存等效的内存位宽分别是等效 64bit 和 128bit,其对应的原始 LPDDR 通道宽度是 16bit。从 LPDDR/DDR1 到 LPDDR5/DDR5,这个位宽标准几十年如一日从未被打破。但是到了 LPDDR6 这一代这个规则被打破了,LPDDR6 的原始通道宽度从 16bit 提升到了 24bit,对应的手机端/PC 端所主流配置的双通道 LPDDR 位宽也就自然而然的成了 96bit 和 192bit。

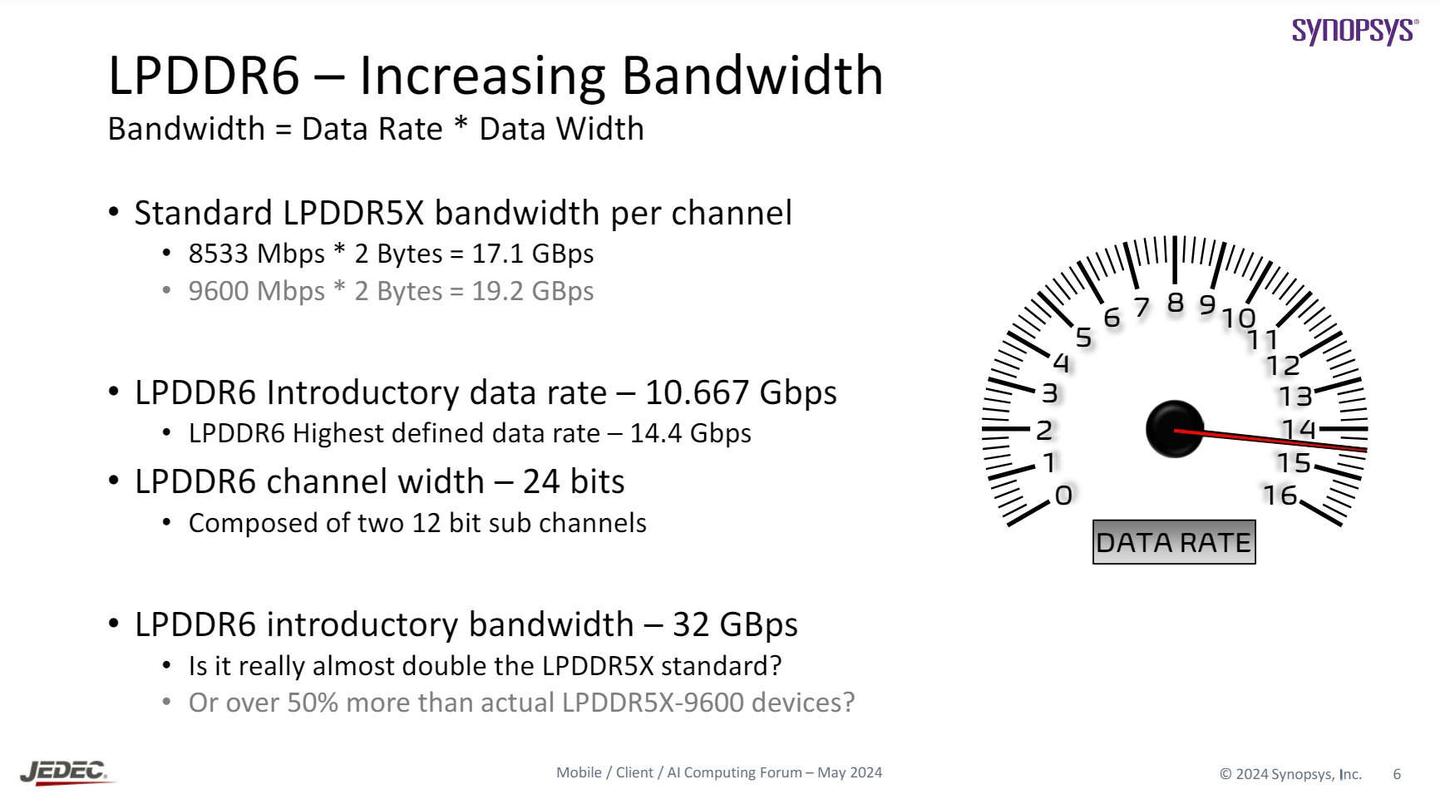
伴随着内存速率和位宽的双重提升,LPDDR6 初代的主流型号 LPDDR6 12.8Gbps 将会相比于当前主流的 LPDDR5X 9.6Gbps 提升多少呢?(备注:我只考虑主流出现的型号,10.7Gbps 的 LPDDR5X 和 14.4Gbps 的 LPDDR6 都不考虑) 既然我这么问了,那这显然不是单纯的位宽✖️速率的游戏。 LPDDR6 这代引入了容错机制,每 288bit 传输的数据中只有 256bit 的有效数据,因此 LPDDR6 在计算“位宽✖️速率”后还要考虑这个有效率的问题,这里不难算出来 256/288=0.889 。
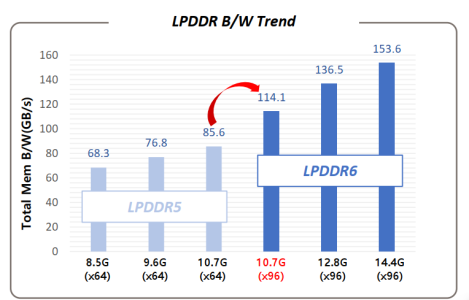
那么接下来我们就可以看到,手机端的双通道 LPDDR5X 9.6Gbps 的位宽是 64/8*9.6=76.8 , 而如果一旦升级到 12.8Gbps 的 LPDDR6 那就是 96/8*12.8*0.889=136.55 ,整体带宽接近 80%! 可见,这个速率的提升是远大于过去 LPDDR4X 4.3Gbps 到 LPDDR5 5.5Gbps 的,也大于之前同样的环境。
LPDDR6 :疯狂追赶与 GDDR7 的带宽差距
一般而言,内存带宽的提升无非就是代表着核显 GPU 和 AI 推理的上限又进一步提升,为什么值得我单独拿出来吹一波说可能引起消费电子产品的变革? 这里就不得不拿现在正在 AI 风口浪尖上的独显来说了。独显也是显卡也需要相应的存储系统,一般而言都采用 GDDR 显存。 GDDR、DDR、LPDDR 算是一个 DRAM 大家族里的不同成员,只是他们的分工有所不同而已。本来大家因为特性各自不同,井水不犯河水,但现在我得说 LPDDR6 真可以吃了不少 GDDR 的市场。
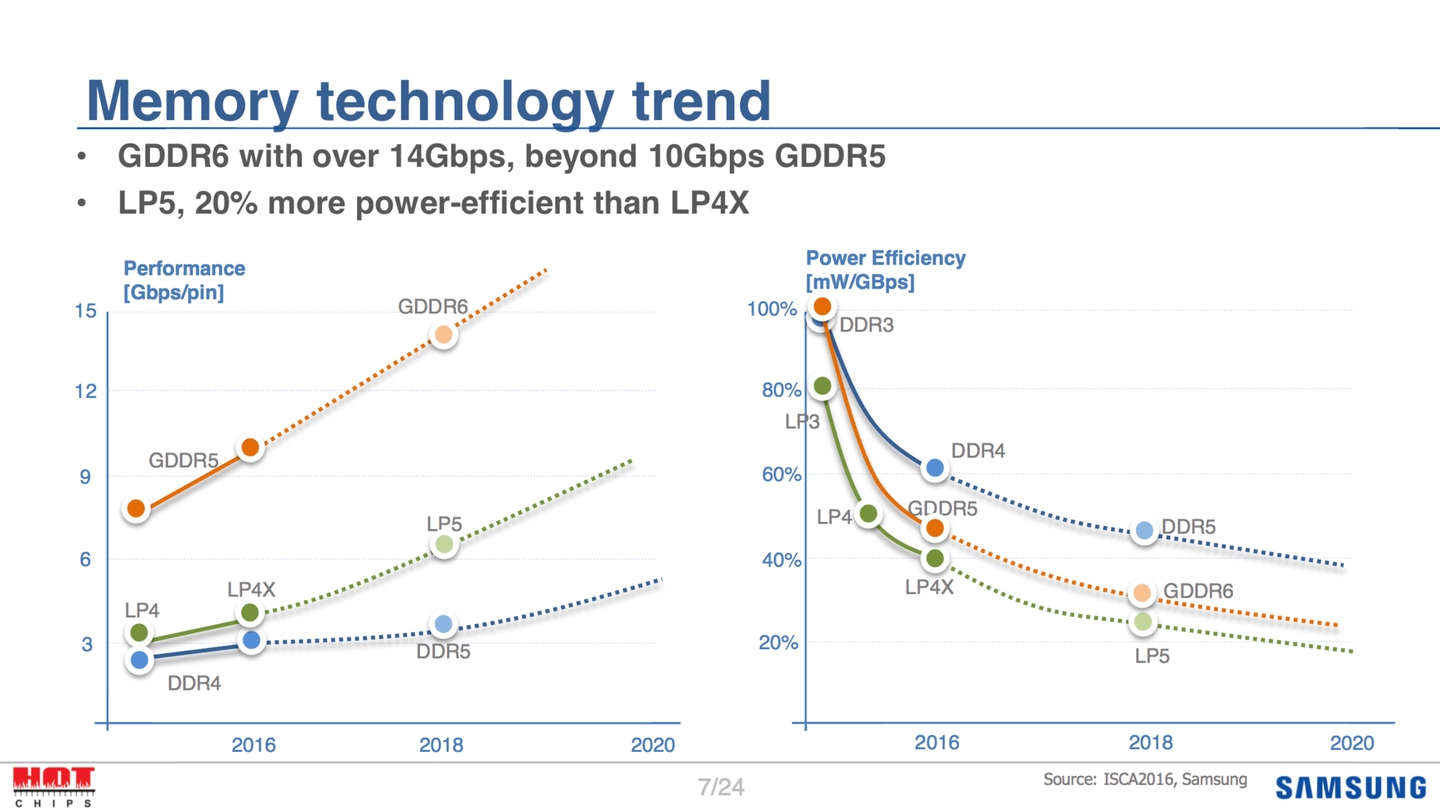
在过去搭载 GDDR 显存颗粒的独显,在总体带宽上是远胜 LPDDR 的方案的。 举个例子来说,LPDDR5 系列的典型速率范围是 5.5Gbps-10.6Gbps,而 LPDDR5 对应 GDDR6 14Gbps-20Gbps 到 GDDR7 初期的速率 24-30Gbps,基本上就是同样位宽下 GDDR 有 LPDDR 3 倍的带宽。 而 PC 端(不包含 Mac)这边一般考虑到成本因素后,大批量产品最多也就能搞类似 Strix Halo 那样的四通道 256bit 产品,折算到 GDDR 系列也就理论上最多能战 Nvidia 96bit 独显的产品。 就算是 Mac Studio 上成本爆炸的 M3 Ultra 16 通道内存(1024bit),最后也就凑合 4090 系列 384bit 位宽都勉强。
但到了 LPDDR6 时代情况就不一样了。由于在 DRAM 市场里,高端专业 AI 卡清一色 HBM,PC 手机不是 LPDDR 就是 DDR, GDDR 显存属于市场需求非常小的产品,自然而然发展速度就很慢。未来几年,GDDR7 将会和 LPDDR6 共存很久,而你仔细算就能发现,GDDR7 对比 LPDDR6 的带宽优势小了很多。

以今年主流的 RTX5060 移动端为例,搭载了 128bit 24Gbps 的 GDDR7 显存,显存位宽只有 384GB/s 而已。而 AMD 明年的 Medusa Halo 所使用的四通道 LPDDR6 内存带宽方案,保守估计是 96*4/8*12.8=614.4 GB/s,仅仅略低于 5070Ti 192bit 28Gbps 的 672GB/s 一些。
那么不知道你是否发现这个问题了,RTX 60 系列的显卡将长期保持在 128bit 位宽,那它的显存位宽将会被 LPDDR6 时代诸如 Medusa Halo 这样的四通道产品所长期压制? 128bit GDDR7 就算按照 36Gbps 这样的超高速率去算,也就区区 384*1.5=576 GB/s 而已,并且那个时候的 LPDDR6 也早就不是 12.8Gbps 了。 而你要记住 Nvidia 的显存位宽不可能随便提升,6060 甚至 7060 都不可能到 192bit。
所以这就带来了第一个吹捧 LPDDR6 的地方了,4 通道 LPDDR6 的大核显产品(Medusa Point、Nova Lake AX)的核显性能上限,比 128bit GDDR7 的 60 系列 要来的高。
LPDDR6 终极杀器:统一内存
4 通道 LPDDR6 的大核显产品除了能够在内存带宽上显著压过 128bit 60 系显卡以外,其还有一个真正的杀器就是统一内存。 在非大核显方案中,内存是内存显存是显存,二者没法直接叠加。 那么无论是从跑 AI 的方便程度上,还是从经济成本上都不划算。而如果二者共享显存之后呢? 事情是不是很妙? 60 系显卡 8GB 起步,未来几年顶多也就 12GB。但是如果共享显存了,32GB 只是开胃菜,64GB 是甜点,128GB+也是轻轻松松是不是?

那么,这里就很容易可以发现,四通道的 LPDDR6 方案无论是在内存带宽还是容量上,其优势都是远胜双通道 LPDDR6 内存+128bit 60 系显卡这样的经典组合方案的.... 所以今天我的终极观点就是,进入到 LPDDR6 时代后,128bit 的独显在笔记本端应该被淘汰了。在技术上,四通道 LPDDR6 的方案无论从哪个角度来看都比 128bit 独显方案要来得好。
AMD 这边的 Medusa Halo 不出意外就会这么搞,Intel 这边的 Nova Lake 会不会搞不确定。 但 Intel 自己搞不搞不是很重要,Nvidia 和 Intel 是确认联姻了,其合作的产品形态大概率也是会如此。 因为这篇文章里,我重复很多遍的 128bit 独显在 LPDDR6 下真不行。
结语:能否杀死更多 GDDR7 方案?
总结下今年的观点,进入到 LPDDR6 时代后,具备经济可行性的四通道 LPDDR6 方案技术上显著优于搭配 128bit 60 系独显的方案,只要 GPU 的核心不是太拉胯,不建议考虑独显方案。

而对于苹果而言,其本身还有 8 通道的 Max 方案和 16 通道的 Ultra 方案,可以在带宽轻松压制 256bit/512bit、媲美 384bit/768bit 的 GDDR7 方案的同时,在能耗比和显存容量上绝对碾压。

因此稍微夸张点说,如果不考虑 Intel 和 AMD 的大核显产品卖不出去的问题,LPDDR6 比起 GDDR7 更适合如今的 GPU。 LPDDR 虽然速率相对较低,但是耐不住其容量比 GDDR7 大很多的特性在 AI 时代就是给力,活脱脱一个青春版 HBM~ Intel 数据中心推理用的 Crescent Island 也是采用了 LPDDR 方案,目前是 LPDDR5X,未来大概也是变成 LPDDR6。 GDDR 系列相对缓慢的速率提升和难以解决的容量问题,将会让 GDDR 本来就小的市场越来越小。
下一篇专门聊聊大核显产品(Medusa Halo之类),记得关注我公众号 weibo_mebiuw.