Intel Nova Lake 复仇三利器,剑指AMD
Intel Nova Lake系列CPU将在2027年CES发布,你期待Intel的顺利复仇吗?
Intel 某种意义上也算时运不济,不是在主动延期的路上就是在被动延期的路上。随着消费级DRAM市场的进一步恶化,本应在今年年底发布的Nova Lake 系列CPU也只能被迫延期到了2027年CES,而今年我们只能“望PPT止渴”了。
关于Nova Lake 我已经聊了很多(惯例提醒可以到我的公众号“weibo_mebiuw”看到),而这篇文章我想聊聊Nova Lake的“复仇”。客观上,Intel 的Arrow Lake 是Intel之耻的集大成之作,100% 台积电工艺,倒退的频率、Bug 缠身的Lion Cove、游戏倒退、X3D对位缺失、AVX 512的持续缺失。 而到了Nova Lake上终于是“该有的都有了”。
那么这篇文章,我们就聊聊Nova Lake 都有了哪些能够复仇AMD的特性?
1. AVX 512 is Back !
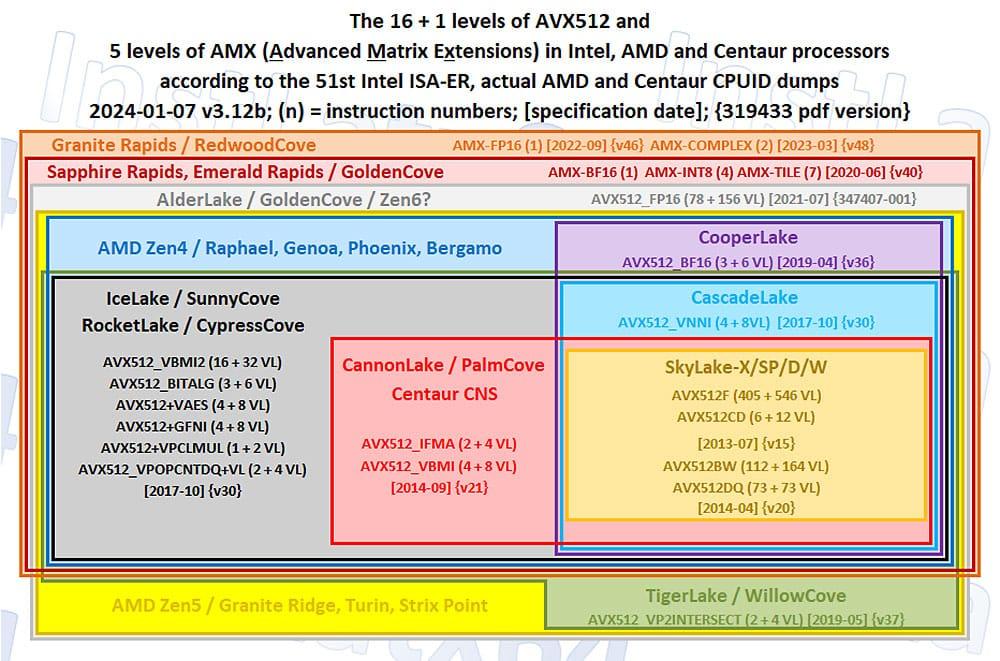
Intel是CPU 高性能计算的首要推动者,从AVX到AMX无一不都是Intel 在大力主推,甚至Intel能够在当初14nm这样一个老掉牙的节点上就实现全宽度的AVX512, 而AMD 直到Zen 5才刚刚做到。 Intel 也为了推行AVX512,背负了不少骂名。但好巧不巧,Intel正好在AVX512 即将成熟稳定的时候,在12代Alder Lake处理器上放弃了AVX512的支持,将自己耕耘好的优势拱手让给AMD,甚是可惜。

Alder Lake 放弃AVX512的原因非常简单粗暴,大小核设计里的E核心不支持AVX512,那么为了指令体系的一致性,Alder Lake只能整体放弃AVX512,屏蔽P核心的AVX512能力。 这里也给大家说下,虽然Intel的大小核体系是异构体系,但是指令集层面是同构的。

如果说Intel Alder Lake和Raptor Lake因为小核芯先天硬件不足屏蔽了AVX512 是情有可原的话,那么到了Arrow Lake这个二代目产品里,AVX512 依旧缺失就非常不应该了。 事实上,Skymont/Darkmont这一代的小核心,硬件上具有4个128bit的SIMD单元,其吞吐是满足AVX512 半吞吐要求水平的(也就是AMD Zen 4 或 Zen 5 APU)。在这样一个SIMD规模下,Intel 不考虑增加AVX512 就是得找骂了。 虽然这样的硬件下,支持AVX512还是AVX2,都不影响SIMD的理论吞吐,但AVX512 指令集有太多先进特性,最终结果就是即便同样宽度下,AVX512 也能暴打同宽度AVX2。
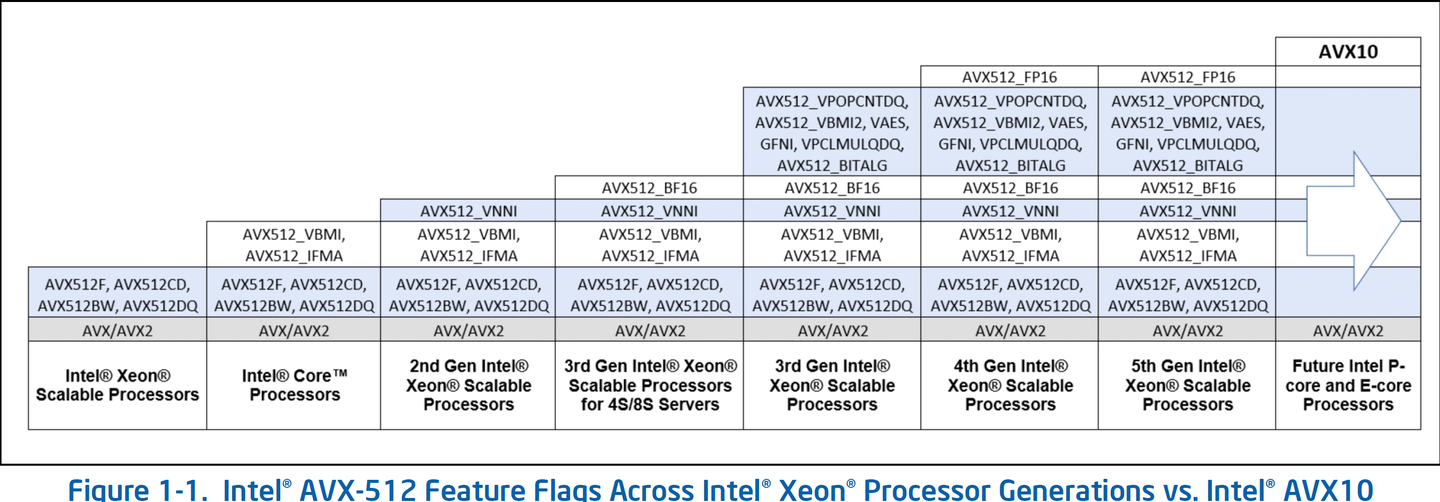
回到Nova Lake上,目前已经确认将会支持AVX512的迭代版AVX10.2指令集,那么无论Nova Lake是否能直接运行AVX512的代码,也都提供了一个很快可以支持最新AVX的机会。 AVX10.2和AVX512 同样宽度和压力,编译器flag一改,现有的优化成果直接套用。 支持AVX10.2的Nova Lake 不但可以弥补AVX这个瘸腿,或许也能让双bLLC Compute Tile版的Nova Lake 16P+32E 成为桌面AI工作站的神器。
2. 大缓存 is Back !
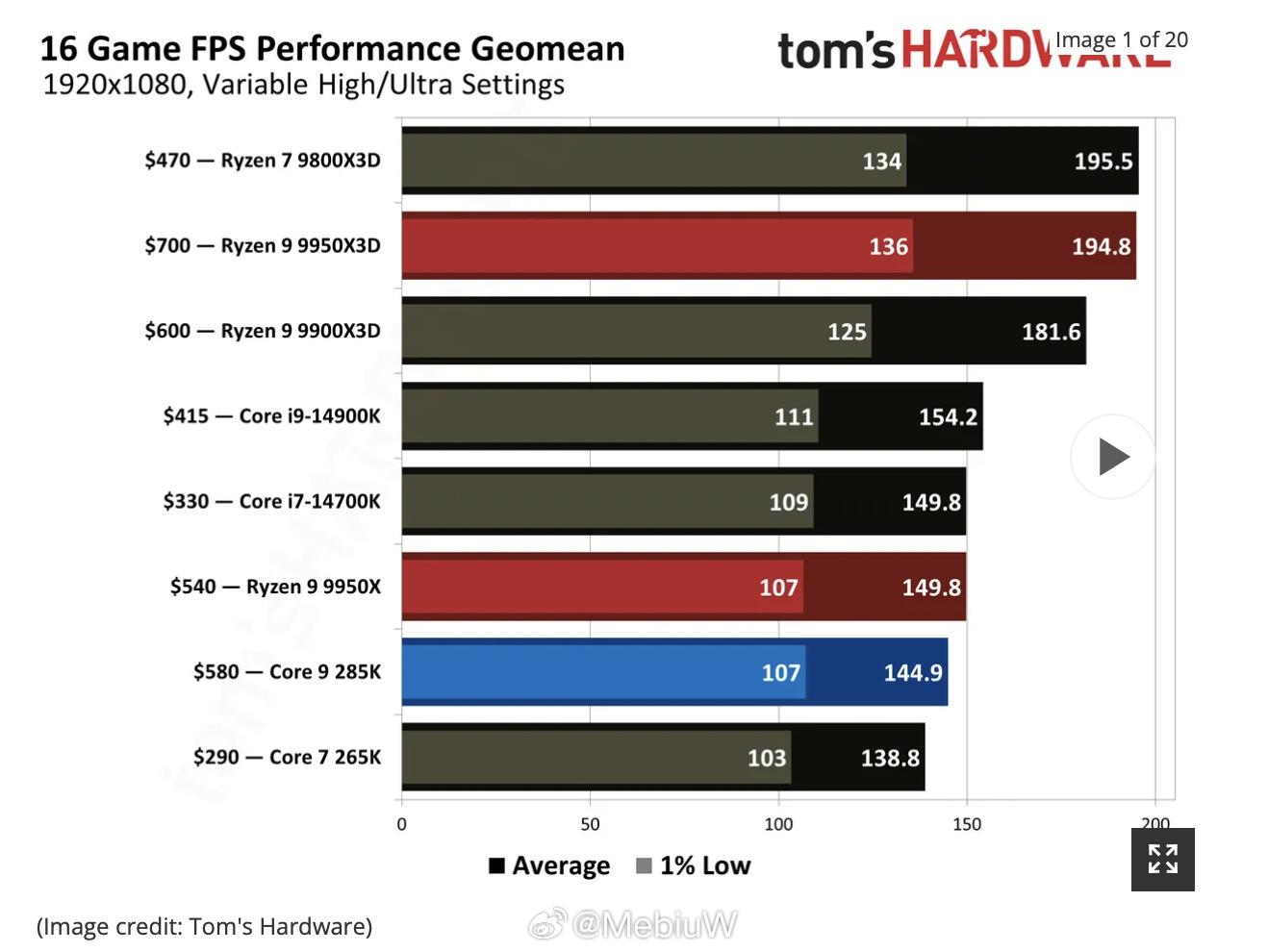
自酷睿开始,Intel CPU的游戏性能一直也是遥遥领先AMD,即便是严重翻车的Arrow Lake S 其在游戏性能方面也是基本打平AMD Zen 5。 AMD 在游戏上真正拿下Intel 的是AMD跳脱于常规处理器设计的、大缓存X3D设计。
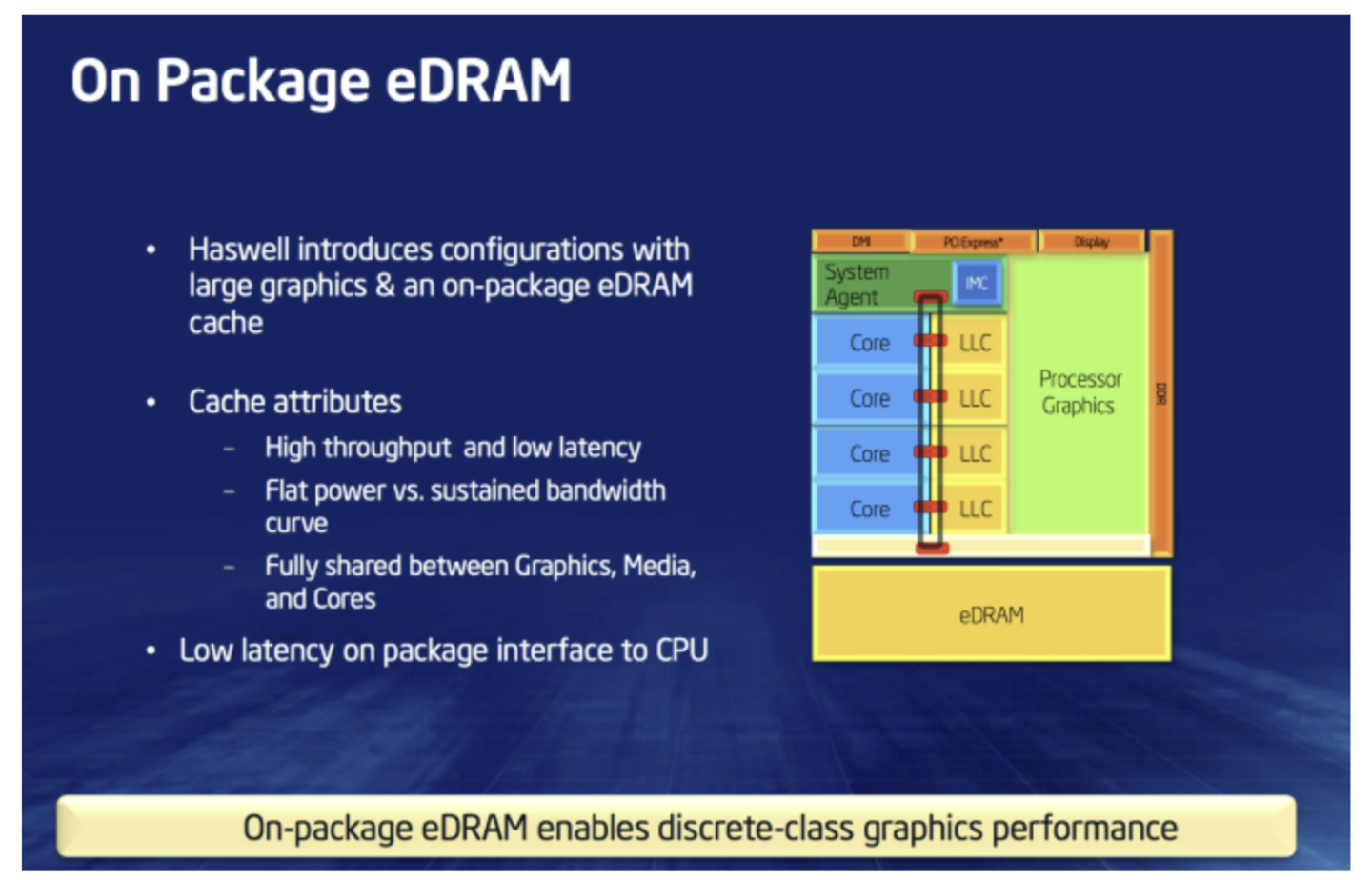
另一方面,我也一直在说AMD的这个X3D虽然在3D堆叠缓存上是独创,但是给处理器外挂大缓存增加游戏性能并不是AMD首创的,而是今天被X3D打冒烟的Intel。 Intel 早在Broadwell 时期的就推出过外挂EDRAM大缓存的桌面CPU,在游戏测试中即便用着比Haswell Refresh更低的频率,也在1080P上取得了接近20%的性能提升。所以建立在Intel本身知道大缓存功效且有自己技术方案的前提下,当Intel 发现AMD首代5800X3D 开始搞大缓存后,是不是应该在7800X3D时代跟上,至少是9800X3D? 然而,没有如果,Intel 到了Arrow Lake 依旧选择不上大缓存,然后又遭遇上了Lion Cove 的Bug。

不过事情到了Nova Lake 重要有转机,Intel 终于给Nova Lake加上了bLLC大缓存。 而且不同于AMD采用落后工艺造SRAM后堆叠的方案,Nova Lake的bLLC是实打实的原生L3,在集成度和性能上都显著优于外挂方案。 N2的SRAM和N6的SRAM,谁能把性能做起来不言而喻。

所以,只要Intel 和 AMD 两家正常进步,AMD不突然出现卫星科技或者Intel再次拉胯,那么Intel Nova Lake 在修正Lion Cove Bug + Gen2Gen 提升+ bLLC Buff的叠加下,游戏性能非常可观。目前我的预期是强过Zen 6X3D。
3. 多Compute Tile来了!

在过去我分析Intel和AMD的Chiplet策略的时候一直在说,Intel的Chiplet策略(特别是Xeon)上是物理上胶水,但是逻辑上不存在胶水。而AMD这里则是彻头彻尾的胶水。 直白一点,二者的差别在于 Intel的核心互联设计只有一级总线(Mesh or Ringbus),没法物理上灵活配置核心(Ringbus)或者代价极大上限低(Mesh)。 对比之下,AMD的Chiplet 在牺牲互联后,则是可以灵活复用芯片,灵活配置核心。 所以做为代价,Intel的消费端要堆核心,只能不断流片新Die。 虽然这样做性能更好,但其成本不利于竞争。

事情的转机出现在Lunar Lake和Panther Lake的这一代SoC总线上。 在经历了Meteor Lake/Arrow Lake的初步双Cluster尝试后,在Lunar Lake / Panther Lake 的SoC总线是可以挂载多个不同的CPU Cluster,并且正常调用和通信,就如同AMD 多个CCD挂载在一起那种。
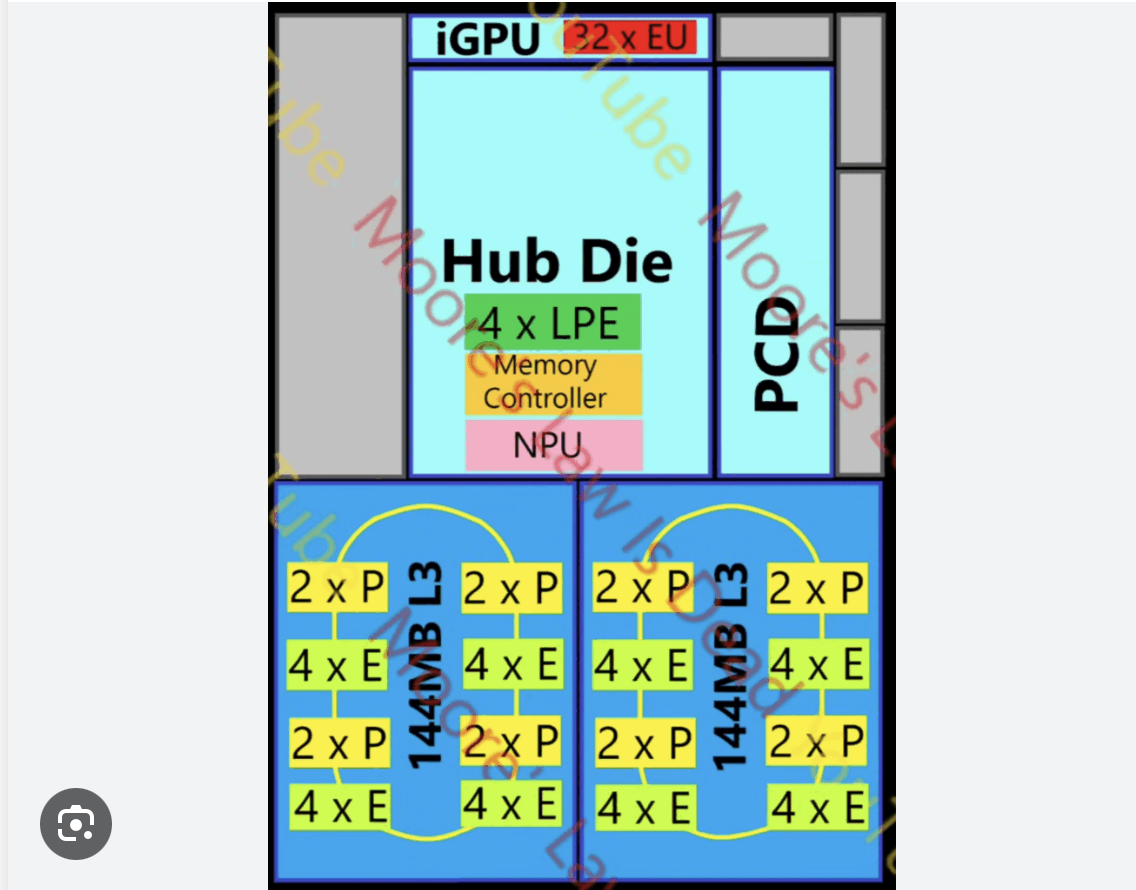
基于这个新的总线设计,虽然Lunar Lake和Panther Lake只是挂载了一个LPE的Cluster,但这个技术的出现有个很重要的信号就是Intel 未来也可以和AMD一样,直接叠加Compute Tile在一起。因此,我们终于在Nova Lake上看见了这样的设计,Nova Lake 可以挂载两个Compute Tile, 双倍多核跑分,师夷长技以制夷。 而且不止是Nova Lake,大家也要意识到Intel未来可能全面转向这个技术,拿出更多大量核心堆叠的东西。 PS,这里说下,服务器端的Clearwater Forest 虽然上了复杂的胶水,但本质依旧还是“物理胶水、逻辑不胶水”。
小结:该有的都有了
除了我上面特别提到的三个特性,Nova Lake 还有很多特性,可以翻翻我之前的文章或者关注下我之后的更新。 总体来说,除了P核心本身还是Cove屎山架构,Nova Lake 在CPU上基本上把目前X86 能给的好东西都给了。从纸面上我对Nova Lake的期待是非常高的,如果Nova Lake 依旧大败,那么唯一能期待的就是Unified Core了。
最后,可能有人会问到Nova Lake又把内存控制器放到SoC (Hub)侧了,是不是不太好? 我想说,一来AMD也是如此,这绝不是Arrow Lake翻车的根本原因。二来,既然要做真胶水,内存控制器就不可能放在CPU侧。
好了,最后求个公众号关注(weibo_mebiuw)。