AMD 锐龙 AIMax+Pro495 处理器现身,其高配将开启哪些应用场景?
Gorgon Halo相比前代Strix Halo,CPU微架构没变、GPU CU数量没变、NPU架构没变。频率涨了200MHz,约2%。如果只看这些数字,你会觉得AMD在戏耍消费者。
但有一个参数变了,而且变幅不小:统一内存从128GB扩到192GB,其中160GB可以分配给显存(AMD官方博客,2026.5.20)。
这个数字直接决定了你能往芯片里塞多大的模型。

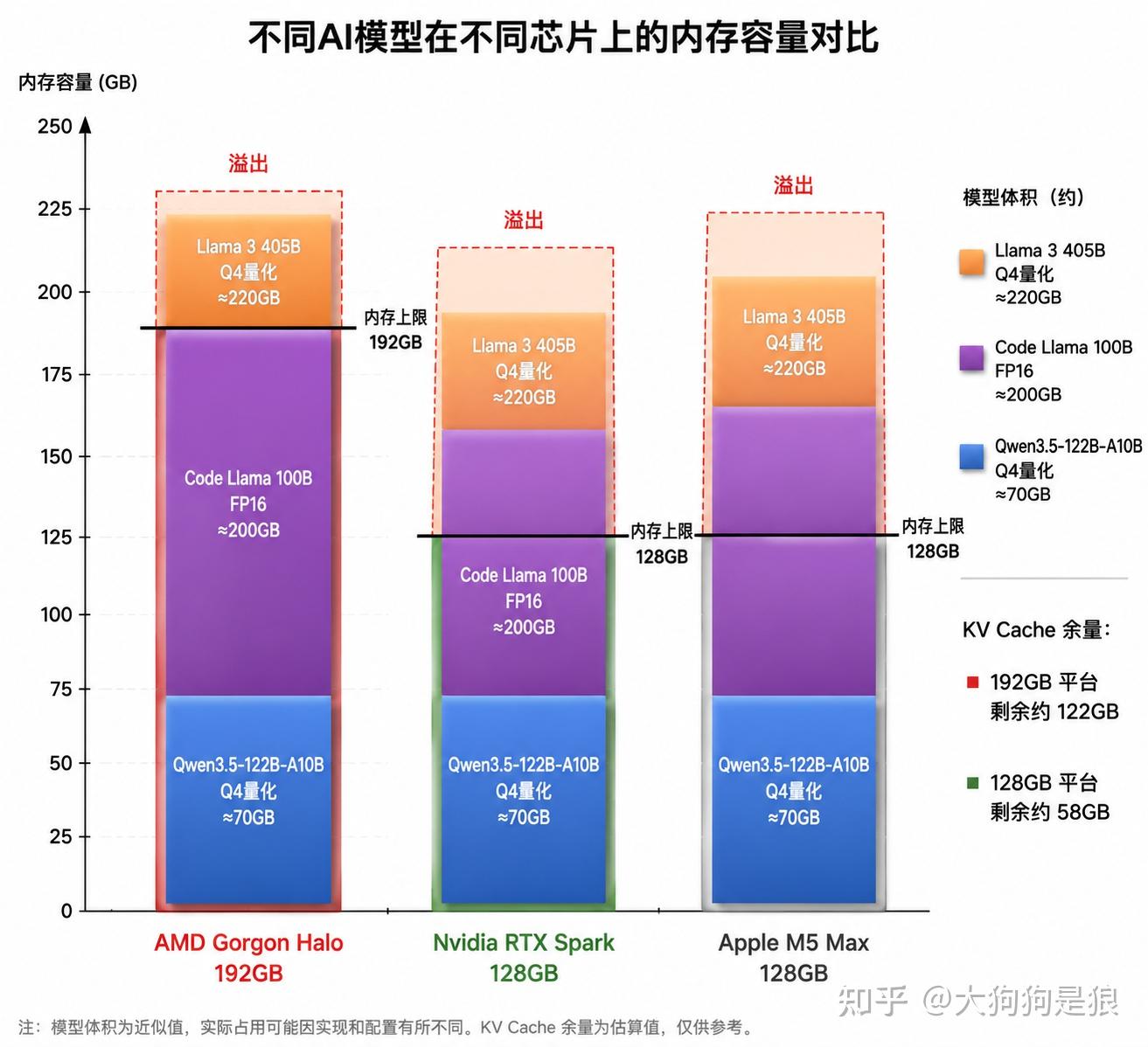
192GB能装什么
先搞清楚一件事:消费级设备跑大语言模型,瓶颈往往是内存大小。模型权重必须完整加载到内存里才能推理,装不下就是装不下,再快的计算单元也白搭。
当前开源模型的量化版本体积大致是这样的:Qwen3.5-122B-A10B是个MoE模型,122B总参数但只激活10B,Q4量化后约60-70GB(ModelScope模型页)。Llama 3 405B的Q4量化版本大约200-230GB。Meta的Code Llama 100B FP16需要约200GB。
128GB统一内存(前代Strix Halo的天花板)能跑Qwen3.5-122B-A10B的Q4量化版,但跑Llama 3 405B的任何量化版本都很勉强。192GB把上限推高了一档:Q4量化的405B仍有希望装进去(200-230GB的Q3量化版约170-190GB),122B级别的模型则可以从Q4升到Q5甚至Q6量化,精度更高。
更实际的影响的是KV Cache。长上下文推理时,KV Cache的内存占用会随序列长度线性增长。128GB的机器跑一个70B模型,权重占35GB,留给KV Cache和系统开销的有90GB左右。192GB的机器则多出64GB给KV Cache,意味着同样的模型能处理长得多的上下文窗口。
已经有用户在AMD AI MAX+ 395(128GB版)上实测跑Qwen3.5-122B-A10B的Q4量化版,模型本身占约80GB显存,剩余空间足以支撑较长的对话上下文(CSDN实测报告)。Gorgon Halo的192GB版把这个余量再拉高50%。
为什么AMD不换架构
你可能会问:既然Gorgon Halo号称400系列升级,为什么CPU/GPU/NPU的核心设计一律不动?
答案是功耗预算。Gorgon Halo的cTDP范围是45-120W(AMD官方规格页)。120W听起来不少,但要同时喂饱16个CPU核心、40个GPU CU和NPU,每一瓦都得精打细算。Zen 5的N4X工艺在5.2GHz下每核心功耗约6-7W,16核就是100W左右,留给GPU和NPU的空间只有20W上下。如果上Zen 6或者扩大GPU规模,立刻撞功耗墙。
台积电4nm在2026年已经不是最先进的工艺节点了(Apple M5已经在用第三代3nm),但N4X是台积电4nm家族里专门给高频HPC场景优化的变种,漏电流比N4P高一些但频率上限更好。这就是Gorgon Halo的boost频率能做到5.2GHz而Strix Point系列(N4P工艺)只能做到5.1GHz的原因(Tom’s Hardware Zen 5架构解析)。
所以Gorgon Halo的策略很清楚:核心设计不动,靠提高内存容量来拓宽应用边界。这是工程取舍。
SoC内部怎么连的
Gorgon Halo的封装里有三颗die:两颗Zen 5 CCD和一颗GCD(Graphics Compute Die)(IT之家封装解析)。每颗CCD包含8个Zen 5核心和32MB L3缓存,两颗合计16核64MB L3。GCD上集成了40个RDNA 3.5计算单元和XDNA 2 NPU,另外还有一块32MB的MALL Cache专门给核显用。
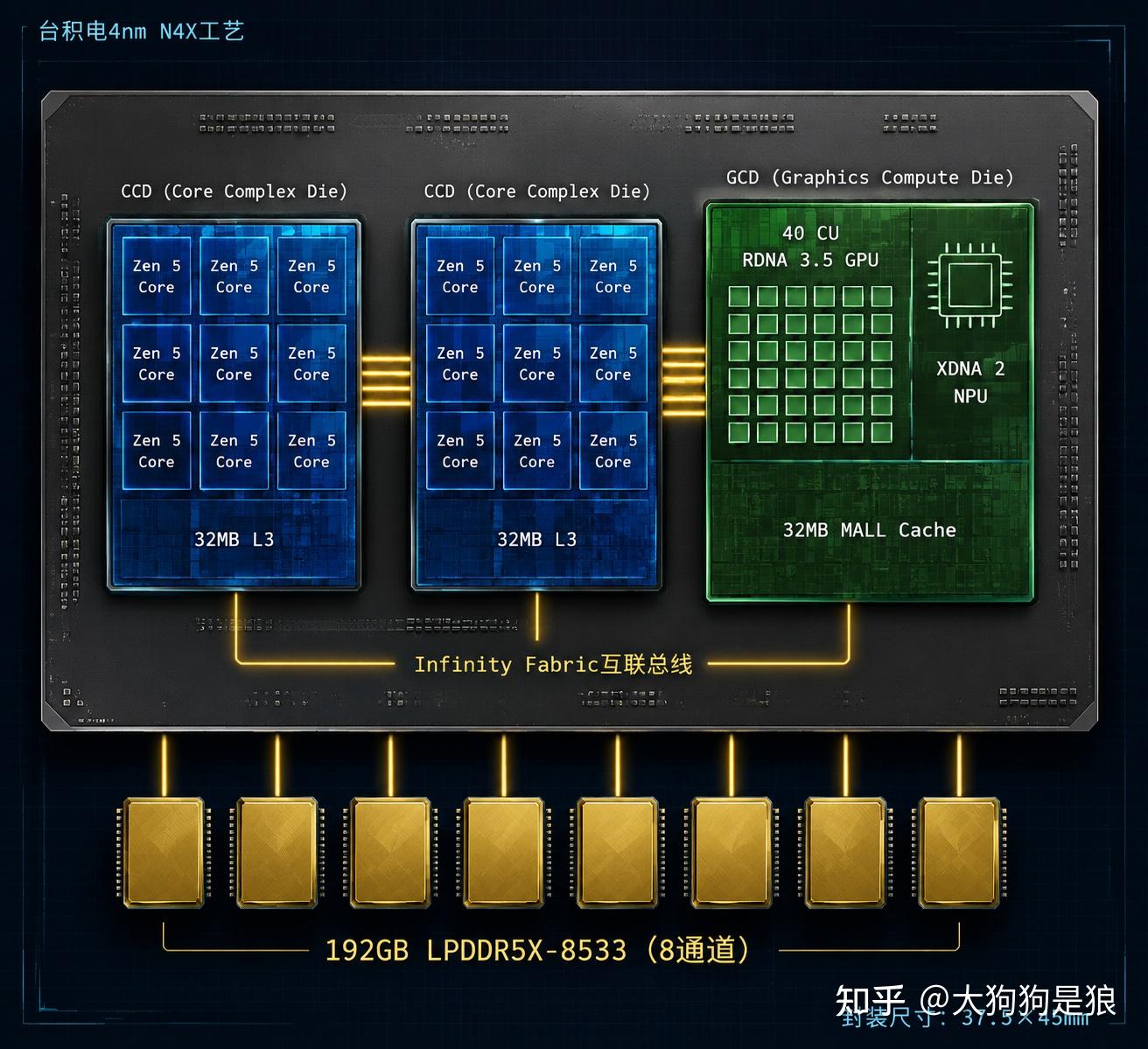
三颗die之间通过Infinity Fabric总线互联。这里有个容易忽略的设计细节:CCD和GCD之间的Infinity Fabric带宽直接影响CPU和GPU之间的数据传递速度。在统一内存架构下,CPU预处理完的数据要通过这条总线送给GPU做矩阵运算,总线的带宽和延迟决定了这个传递过程的效率。AMD没有公开Gorgon Halo的Infinity Fabric具体带宽数字,但参考Strix Halo的实测,这个带宽对于LLM推理场景是够用的,因为瓶颈通常在内存带宽而非die间互联。
Zen 5本身相比Zen 4的改进在这里值得简单提一下。前端取指带宽翻倍到每周期64字节,分支预测器实现了两拍前瞻(每个时钟周期预测两条分支),ALU从4个加到6个,浮点管线从3条加到4条。这些改动让Zen 5的IPC(每周期指令数)比Zen 4提升了大约10-16%(Wikipedia: Zen 5)。
不过Gorgon Halo上的Zen 5有一个和桌面版不同的地方:AVX-512数据通路被裁剪到256位宽。桌面版Granite Ridge是原生512位的。裁剪的原因还是功耗,120W的TDP容不下16个核心全开512位浮点管线。对AI推理影响不大,因为LLM推理走的是GPU的矩阵计算路径,不太依赖CPU的AVX-512。
统一内存到底解决了什么
传统PC里,CPU用DDR内存,GPU用独立显存,两边各管各的。GPU要处理系统内存里的数据,得先通过PCIe总线把数据拷贝到显存。PCIe 5.0 x16的带宽是64GB/s,这个速度对于大模型推理来说太慢了。更要命的是,拷贝本身有延迟,而且CPU和GPU不能同时以零拷贝方式访问同一份数据。
统一内存把这个问题从物理层面消除了。CPU和GPU共享同一块LPDDR5X内存,数据放在那里,两边都能直接访问,不需要拷贝。对于LLM推理这种需要在预处理(CPU)和矩阵运算(GPU/NPU)之间频繁切换数据的工作负载,统一内存不只是方便,它直接决定了你能跑多大的模型。
这也是为什么苹果M系芯片在本地AI领域突然变得重要。Apple从M1开始就用了统一内存架构,到M5 Max已经做到128GB统一内存和614GB/s带宽(Apple Newsroom M5发布)。很多开发者发现Mac mini跑本地LLM的体验意外地好,不是因为GPU多强,而是因为统一内存消除了数据搬运的瓶颈。Mac mini M4因为AI开发者抢购导致缺货,苹果CEO库克在财报会上专门提到了这个现象(什么值得买报道)。
三巨头正面PK
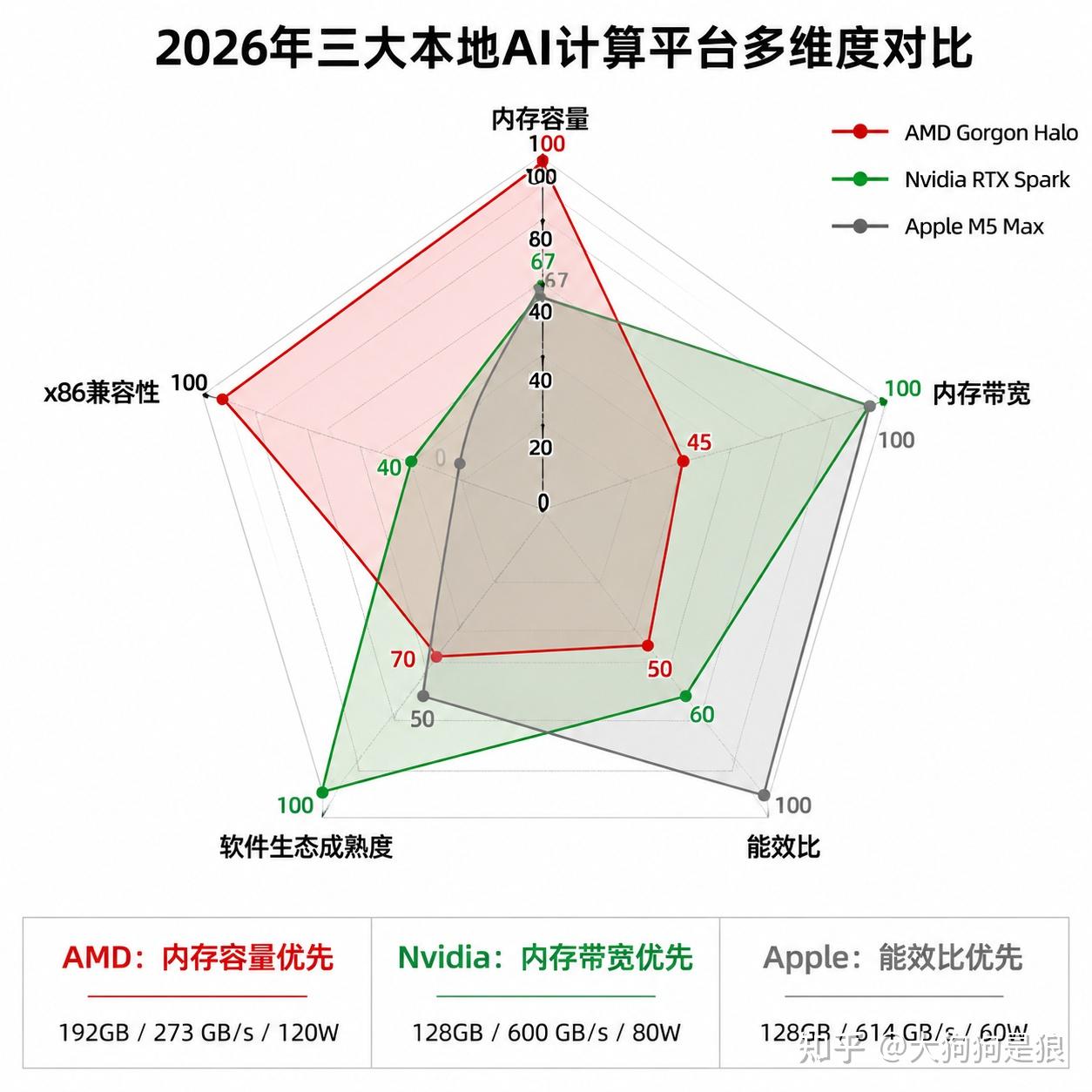
2026年上半年,面向本地AI推理的个人计算平台形成了三条技术路线。它们的规格差异直接反映了设计哲学的分歧。
AMD Gorgon Halo走的是”内存容量优先”路线。192GB LPDDR5X-8533,带宽273 GB/s,16核Zen 5 CPU加40CU RDNA 3.5 GPU加55 TOPS NPU,cTDP 45-120W(AMD官方规格表)。内存容量最大,但带宽最小。能装下最大的模型,但生成token的速度受带宽限制。x86架构意味着现有软件栈几乎不需要修改。
Nvidia RTX Spark走的是”内存带宽优先”路线。128GB LPDDR5X统一内存,带宽600 GB/s,20核Grace CPU(ARM Cortex-X925和A725各10核,联发科协同设计)加6144 CUDA核心Blackwell GPU加第5代Tensor Core,功耗45-80W(Wikipedia: Nvidia RTX Spark)。带宽是Gorgon Halo的2.2倍,但内存容量只有它的三分之二。CUDA生态是最大护城河,几乎所有AI框架都优先优化CUDA后端。ARM架构运行Windows 11需要依赖微软的Prism模拟器来跑x86应用,兼容性是个实际问题。
Apple M5 Max走的是”能效比优先”路线。128GB统一内存,带宽最高614GB/s,18核CPU加最高40核GPU(每核内嵌Neural Accelerator),功耗在笔记本中约30-60W(Apple支持 M5 Pro/Max技术规格)。同样的内存容量和带宽接近RTX Spark,但功耗低得多。GPU里集成的Neural Accelerator是每个核心内嵌的AI加速单元,集成度比Nvidia的Tensor Core还高。但macOS生态封闭,只有Apple自己的MLX框架,相比CUDA社区规模有限。
还有一个不能忽略的背景:Qualcomm Snapdragon X Elite已经在Copilot+ PC里跑了一年多,NPU达到45 TOPS,是ARM on Windows的先行者。RTX Spark进入这个市场时,Snapdragon已经是现有玩家,Nvidia要面对的不只是AMD和Apple,还有高通在ARM Windows生态中的先发优势。Intel这边,Lunar Lake和Arrow Lake的NPU也达到了48 TOPS级别,虽然内存容量远不如Gorgon Halo(最高64GB DDR5),但在主流价位段有价格优势。
成品产品:谁在卖什么、卖多少钱
AMD阵营目前只有一款成品设备在售:Ryzen AI Halo开发者平台,3999美元,128GB LPDDR5X-8000(Strix Halo版),2TB PCIe Gen4存储,5.9×5.9英寸机身,120W功耗,提供Linux和Windows 11 Pro两个SKU,Micro Center独家(AMD官方产品页)。Q3将升级到Gorgon Halo 192GB版本,价格未公布。HP和联想已确认将推出基于Gorgon Halo的移动工作站和迷你主机(AMD官方博客)。
Nvidia阵营有两类产品。DGX Spark面向AI开发者,3999美元(4TB版),128GB统一内存,1 PFLOP FP4 AI算力,搭载ConnectX-7 200Gbps高速网卡支持多机集群,运行DGX OS(基于Linux),2025年底已上市(Nvidia DGX Spark产品页)。RTX Spark消费级设备预计2499-3999美元区间,搭载RTX Spark SoC运行Windows 11,2026年秋季上市,首批厂商包括华硕ProArt P16/P14、联想Yoga Pro 9n、微软Surface Laptop Ultra等(Wikipedia引用)。微软还推出了Surface RTX Spark Dev Box,128GB统一内存,100W功耗(Microsoft Build 2026公告)。
Apple阵营的Mac mini M4(599美元起,最高64GB统一内存)因AI开发者抢购缺货。MacBook Pro M5 Pro/Max已上市,最高128GB统一内存。Mac mini M5/M5 Pro版本截至2026年6月WWDC结束仍未发布,供应链问题导致延迟(什么值得买报道)。
一个有意思的价格对比:AMD Ryzen AI Halo和Nvidia DGX Spark的4TB版都是3999美元,但软件栈完全不同。DGX Spark有CUDA的完整支持,Ryzen AI Halo依赖ROCm。AMD声称Ryzen AI Halo配置速度比DGX Spark更快,”从开机到生成Token只需几分钟”(AMD官方页面),不过这个说法没有第三方验证。

散热、噪音和不可升级性
这些是规格表上看不到的东西,但对实际使用影响很大。
120W的迷你主机,散热空间极其有限。AMD Ryzen AI Halo的机身只有5.9×5.9英寸,在这个体积内压住120W的TDP,风扇噪音在满载时不会低。目前还没有独立评测机构对Ryzen AI Halo的散热表现做过详细测试,但参考同体积的NUC类产品在满载时风扇噪音通常在35-45dBA的范围,放在桌面上会比较明显。
更关键的是降频行为。迷你主机在持续负载下通常会因为温度积累而降频,实际性能可能低于标称TDP对应的理论值。LLM推理往往是持续几分钟甚至几小时的负载,散热降频的影响不可忽视。
还有一个容易被忽略的问题:LPDDR5X内存是焊死的,不可升级。你买128GB就是128GB,买192GB就是192GB。如果半年后出了一个200B模型需要200GB内存才能跑,你只能整机换掉。这个”一次性决策”的风险对于目标用户(AI开发者)来说值得认真考虑。
带宽瓶颈:一个被说烂的问题
所有关于Gorgon Halo的讨论都在强调192GB内存容量,但带宽也很重要。
Gorgon Halo的LPDDR5X-8533在8通道配置下提供273 GB/s带宽。作为对比,RTX Spark是600 GB/s,M5 Max是614 GB/s。带宽差距超过2倍。
LLM推理的token生成速度在多数情况下受内存带宽限制。每生成一个token,GPU需要从内存中读取一遍模型权重。一个Q4量化的70B模型约35GB,在273 GB/s带宽下,理论上限是每秒约7-8个token(35GB ÷ 273 GB/s)。实际因为GPU缓存复用和计算并行,速度会高于这个纯带宽估算,但带宽天花板是硬约束。同样的70B模型在RTX Spark上(600 GB/s),理论上限约17 tokens/s,体感差距明显。
这就形成了一个尴尬的局面:Gorgon Halo能装下最大的模型,但生成速度最慢。RTX Spark装不下最大的模型,但生成速度最快。Apple M5 Max在容量和速度之间取了个中间值,同时功耗最低。
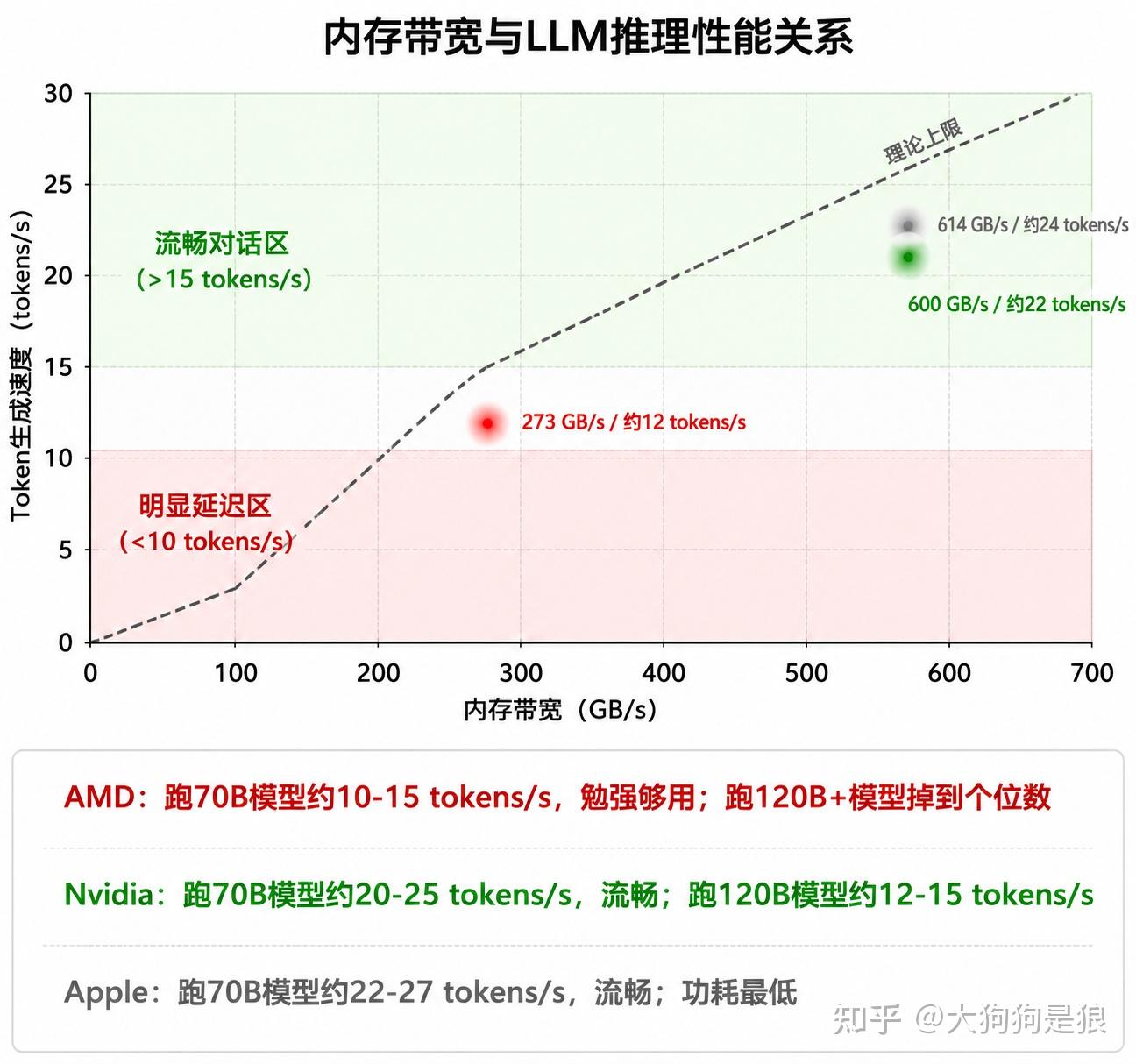
对于交互式对话场景(用户等待响应),273 GB/s的带宽跑70B模型大概能到10-15 tokens/s,勉强够用。但跑120B以上的模型,速度会掉到个位数,用户等待时间明显变长。
AMD这个芯片实际能用来干什么
说了这么多技术参数,落到具体场景:
本地大模型推理和原型开发是最核心的用途。192GB内存允许开发者在桌面上跑Q4量化的200-300B参数模型,不需要云端GPU时间。AMD ROCm已经支持PyTorch、vLLM、llama.cpp、Ollama、ComfyUI等主流框架(AMD官方页面)。但要注意,ROCm的算子覆盖率和调试工具成熟度跟CUDA仍有差距,实际开发中可能遇到某些模型不支持或者性能不达预期的情况。
多Agent并行工作流是AMD反复强调的概念(AMD官方博客)。192GB内存可以同时加载多个不同规模的模型,比如一个70B通用推理模型加一个7B分类模型加一个embedding模型,每个模型驻留在独立内存空间中。这个场景目前还比较前沿,具体的内存分区策略和任务调度开销取决于框架支持程度。
数据隐私场景是刚需。医疗、法律、金融等行业的数据不能出内网,本地推理是唯一选择。Gorgon Halo的x86兼容性在这里是实际优势,现有企业软件栈几乎不需要修改。
LoRA/QLoRA微调也能做,192GB内存对70B级别的模型参数高效微调够用。但40个RDNA 3.5 CU的FP16算力远不及独立GPU,微调速度会显著慢于云端方案。适合小规模实验性微调,不适合生产级训练。
制程和功耗的物理约束
三款芯片的制程选择反映了各自的设计取舍。Gorgon Halo用台积电4nm N4X,RTX Spark的Grace CPU大概率是台积电5nm或4nm级别(联发科设计),Blackwell GPU沿用Nvidia数据中心级工艺,Apple M5用台积电第三代3nm N3E。
功耗方面,Gorgon Halo的cTDP 45-120W,RTX Spark 45-100W,M5 Max在笔记本中约30-60W。Apple的能效优势在移动场景下是决定性的。在桌面场景下,120W的散热约束让AMD和Nvidia的实际持续性能都可能低于标称值。
192GB LPDDR5X-8533内存方案的成本和良率是个实际问题。192GB需要在封装基板上放置更多内存颗粒,信号完整性在8533MHz的频率下是个工程挑战。如果成本过高导致终端产品定价大幅超出4000美元这个心理关口,Gorgon Halo的性价比优势就会被削弱。这个问题要到Q3产品正式上市时才有答案。
参考来源:
- AMD Ryzen AI Max+ PRO 495官方规格页
- AMD官方博客:Ryzen AI Halo与Ryzen AI Max PRO 400系列
- AMD Ryzen AI Halo开发者平台
- Wikipedia: Nvidia RTX Spark
- Wikipedia: Zen 5
- Apple Newsroom: M5发布
- Apple支持: M5 Pro/Max技术规格
- Nvidia DGX Spark产品页
- Tom’s Hardware: Zen 5架构深度解析
- IT之家: Strix Halo封装解析
- ModelScope: Qwen3.5-122B-A10B模型页
- CSDN: AMD AI MAX+395跑Qwen3.5-122B实测
- 腾讯云开发者社区: RTX Spark技术分析