「很多人都有误解,内存真的很难造」这一说法,其技术难度究竟体现在哪些方面?
问题原话是美光CEO桑杰·梅罗特拉(Sanjay Mehrotra)说的
“人们常常误解内存,不知道制造内存有多难。”
这话听起来像是营销话术。但如果你翻翻过去三十年半导体产业的”阵亡名单”,会发现一个诡异的事实:曾经想做DRAM的公司,死掉的数量远远多于活下来的。德国的奇梦达(Qimonda),2009年破产;日本的尔必达(Elpida),2012年破产;台湾的南亚科技蜷缩在利基市场,华邦电子更是早已转做NOR Flash。连Intel都曾在DRAM领域折戟沉沙,1985年黯然退出。
如今全球DRAM市场只剩四家还能打:三星、SK海力士、美光,以及2025年才挤上牌桌的中国长鑫存储。前三家占掉全球90%以上的份额。同一时期的NAND闪存市场,玩家有六七个,竞争格局松散得多。
为什么DRAM这个赛道淘汰率这么高?根本原因在于,DRAM的制造难度和普通芯片确实不是一个级别的。
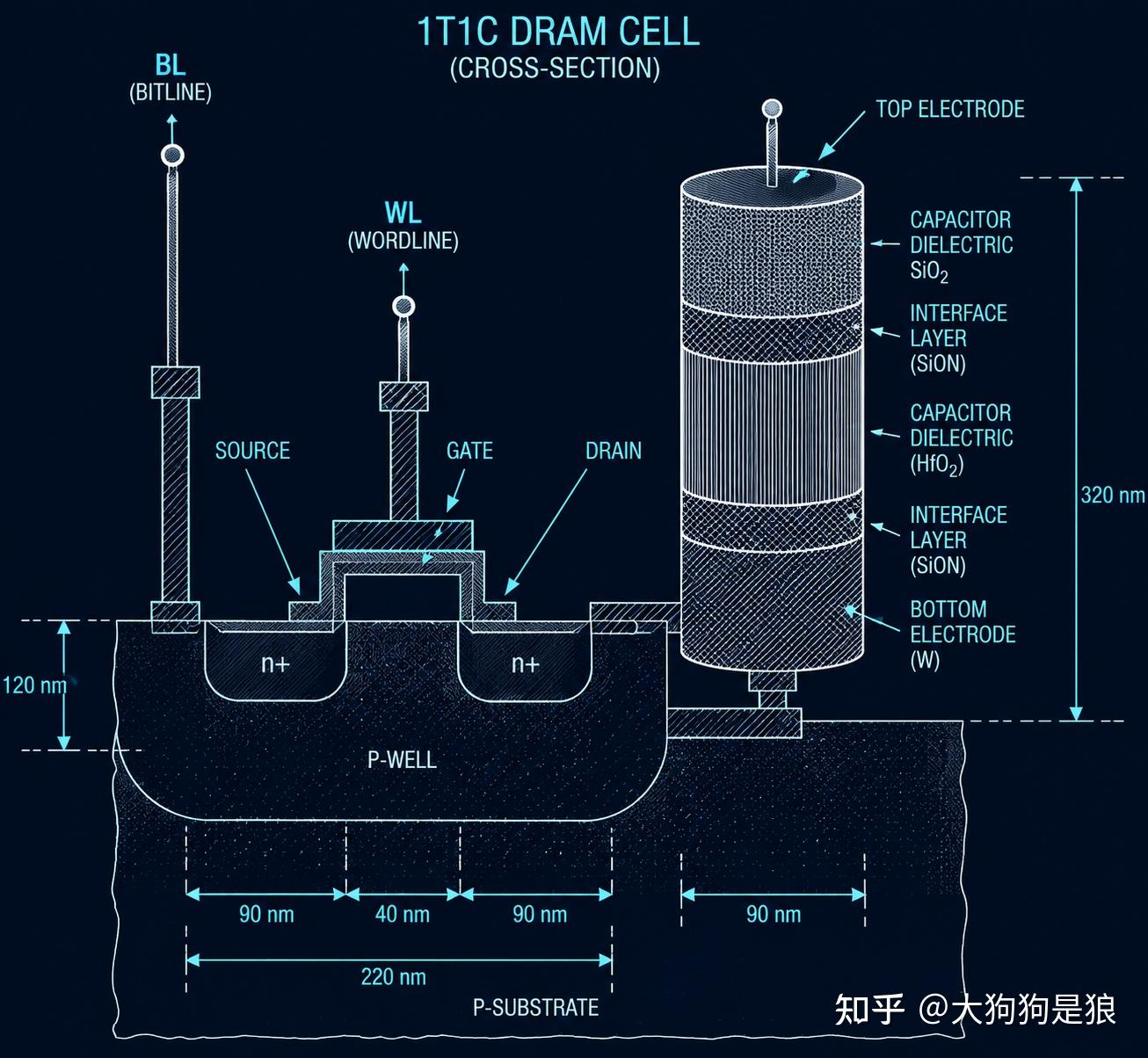
1T1C,一个精妙的结构
要理解DRAM为什么难造,得从它最基本的存储单元说起。
DRAM的每一个比特(bit)由一个晶体管(Transistor)和一个电容(Capacitor)组成,行话叫”1T1C”结构。晶体管充当开关,控制数据的读写;电容负责存储电荷,有电荷代表”1”,无电荷代表”0”。听起来简单得像初中物理课本上的电路图。
但瓶颈在于尺寸。
美光的技术博客做过一个形象的类比:把一颗DRAM芯片放大到足球场那么大,伸手拔起一根草,切成两半,再切成两半,再切成两半。这最后那一丁点,就是一个存储单元,而一颗普通芯片上塞着80亿个这样的单元。
问题在于,电容的物理特性决定了它不能无限缩小。电容的职责是存储足够多的电荷,让后续电路能准确区分”0”和”1”。行业标准要求每个单元维持约25飞法(fF)的电容值。这个数字听起来微不足道,但当你把存储单元的面积压缩到十几纳米见方时,要在那么小的地盘上塞进一个能稳定存住25fF电荷的电容,工程难度相当于”在米粒上雕刻一座精密迷宫”。
更致命的是漏电问题。存储单元里的晶体管越小,关断时漏过的电流就越大,电容里的电荷会慢慢流失。传统DRAM的刷新间隔大约64毫秒,也就是说每秒要给所有单元”充电”15次以上。如果晶体管漏电严重,刷新频率还得提高,功耗直接飙升。
这就是DRAM微缩的根本矛盾:你想把单元做小来提升密度,但单元越小,电容越小,信号越弱,漏电越严重,需要更频繁的刷新,反过来又增加了功耗和带宽压力。每一代制程进步,都是在跟这组矛盾做博弈。
电容的深沟槽是深宽比超过100的”纳米级深渊”
既然平面方向上没有更多空间给电容,工程师们开始往地下发展。
现代DRAM的电容结构采用深沟槽(Deep Trench)或堆叠柱状(Stacked Cylinder)设计,在存储单元下方挖出极深极窄的孔洞,在孔壁上沉积高介电常数的薄膜材料,来维持足够的电容值。当前的电容深宽比(Aspect Ratio,深度与宽度之比)已经超过100:1。
而这样的沟槽,在一颗芯片上需要同时挖出数十亿个,每一条的尺寸偏差都要控制在纳米级别。
刻蚀这样高深宽比的沟槽本身就是一项极限工艺。Lam Research(泛林半导体)的刻蚀设备在这个领域占比极高,是DRAM深沟槽刻蚀的核心供应商,深硅刻蚀的技术壁垒极高。在深宽比超过80:1之后,刻蚀等离子体很难到达沟槽底部,底部容易出现bowing(弓形变形)、CD(临界尺寸)不均匀、残膜等缺陷,每多挖深一点,良率就往下掉一截。
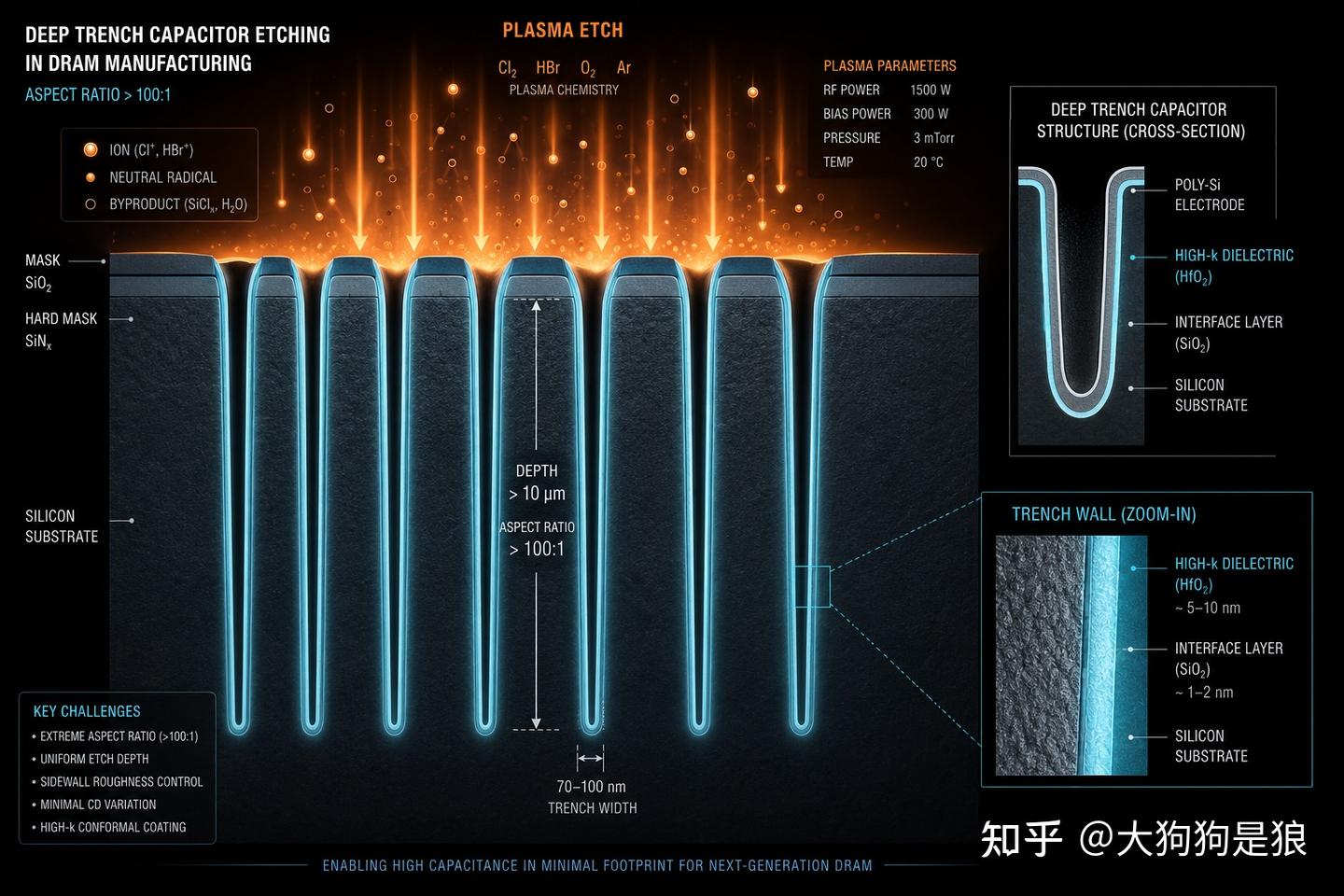
一位FAB刻蚀工程师在行业论坛里打过这样一个比方:”DRAM这玩意属于’螺丝壳里做道场’,各种CD尺寸、overlay挑战,litho压力巨大,当然etch压力也不小,口子的CD尺寸小了,稍微深一点就变成了巨大的深宽比。”
光刻也在不断追先进工艺
DRAM的光刻精度要求直逼逻辑芯片(CPU/GPU),远高于NAND闪存。原因在于DRAM单元排列极其密集,线宽节距(pitch)已经推进到十几个纳米级别。
先说清楚DRAM的节点命名规则,不然后面一堆术语看着跟天书似的。DRAM行业不用逻辑芯片的”5nm、3nm”那套说法,而是用1x、1y、1z、1α、1β、1γ来标记代际,每一代对应的是单元阵列的半间距(half-pitch)。1x约16到19纳米,1y约14到16纳米,1z约12到14纳米,1α约12到14纳米,1β约10到12纳米,1c约10纳米以下。三星最新的10a节点则做到了9.5到9.7纳米,是全球首个个位数纳米级的DRAM制程。这些数字跟逻辑芯片的命名不能直接换算,因为DRAM的”nm”指的是物理间距,不是等效栅极长度。
美光在介绍其1α(1-alpha)节点时打过比方:光刻机使用的深紫外光(DUV)波长193纳米,而要刻出的特征尺寸只有十几纳米。这相当于”用4英寸的油漆刷写10磅的文字”。物理学上的瑞利准则(Rayleigh Criterion)规定,光刻能分辨的最小特征尺寸受限于光源波长的一半,193nm的光理论上极限分辨也就不到100nm,跟十几nm的目标差了一个数量级。
怎么绕过去?主要有三招:
第一是浸没式光刻。在透镜和晶圆之间注入超纯水,利用水的折射率把等效波长压到134nm以下。看起来不起眼,但这项技术是ASML和台积电前CTO林本坚在2002-2003年力推的革命性方案,至今仍是DUV光刻的核心。
第二是计算光刻。利用海量算力从晶圆上想要得到的图案反推掩膜上应该画什么图案,相当于”骗”光线刻出比波长更细的线条。这需要超级计算机级别的算力,也是为什么英伟达的cuLitho平台在光刻领域越来越重要的原因。
第三是多重曝光(Multi-Patterning)。把一层图案拆成两到四次曝光来完成,每次刻一部分。代价是工序翻倍、掩膜成本翻倍、Overlay(层间对准)误差累积。每多一次曝光,对准精度就多一次挑战。
三星从1c节点开始在DRAM中引入EUV(极紫外光刻,13.5nm波长),SK海力士也在跟进。但EUV设备本身每台售价超过3亿美元,且EUV在DRAM中的应用比逻辑芯片更晚,工艺成熟度还在爬坡。美光的选择更保守,一直用DUV多重大到了1β节点,计划在1γ节点才全面引入EUV。
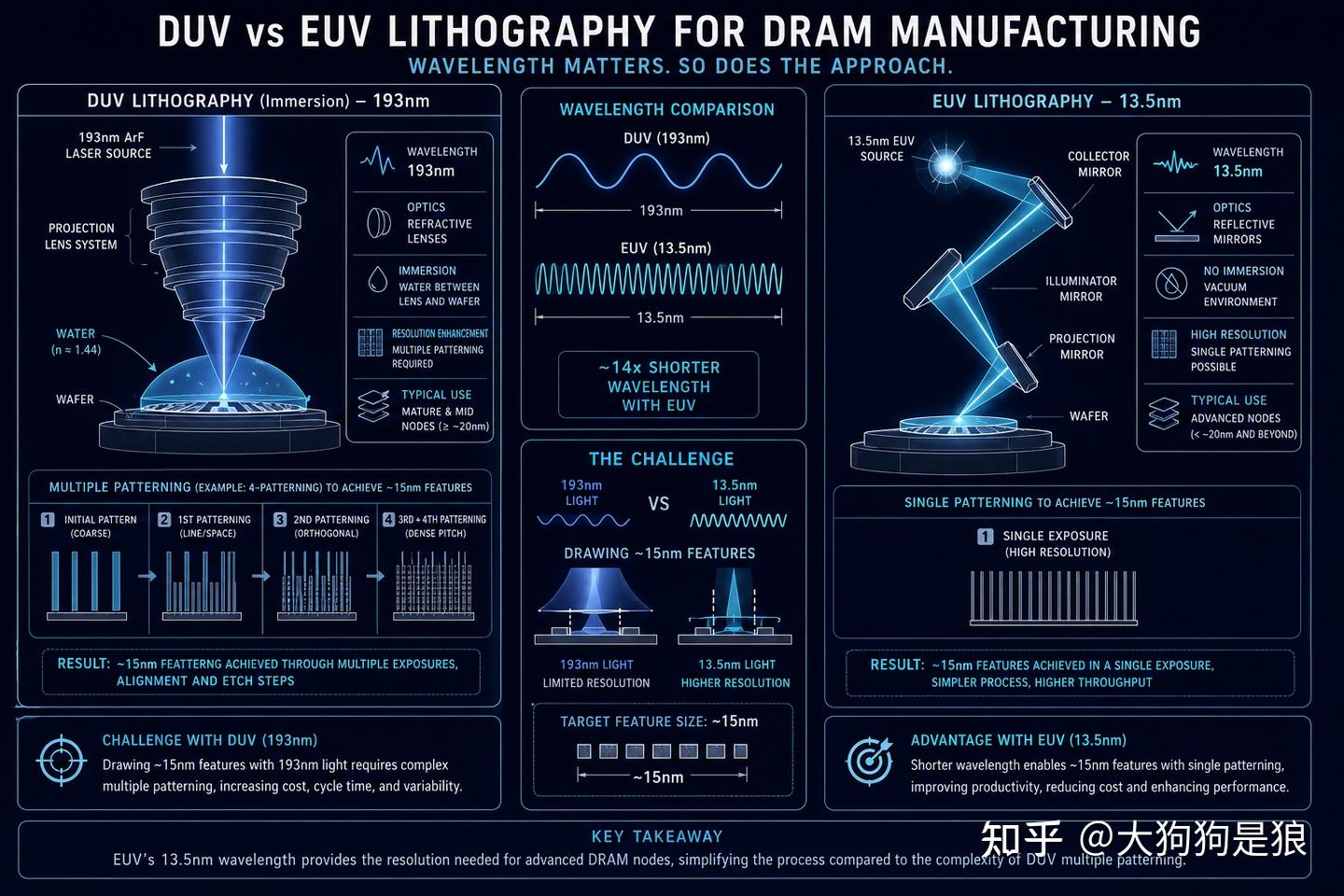
有意思的是,中国的长鑫存储目前完全没有EUV设备,硬是用DUV做出了DDR5产品。TechInsights在2025年初拆解发现长鑫的DDR5芯片时用了”surprising”这个词,因为用DUV做到17nm节点的DRAM,工艺调校的难度比有EUV高了一个台阶。
1000+道工序,每一步都不可逆
一颗DRAM芯片从晶圆到成品需要经过1000多道制造、检测和量测步骤。
美光的技术博客描述了这种极端复杂性:晶圆在工厂内被传送带和机械臂搬运的总距离达到数百公里,每一步都必须丝毫不差。更残酷的是,半导体制造不像汽车装配线,发现上一道工序的缺陷可以返工。芯片制造是单向的,任何缺陷一旦被后续的层覆盖,就永远无法修复。
这意味着良率管理是一种”预防而非治疗”的极端工程。美光的晶圆厂每天从检查系统输入超过100万张图像,利用深度学习技术在问题发生之前发现苗头。整个制造执行系统的数据量达到10PB级别。
但这还只是前道工艺(Front-End)。DRAM的后道封装同样不容小觑,尤其是在HBM(高带宽内存)时代。
HBM:把DRAM的难度再叠一层
HBM(High Bandwidth Memory)的本质是把多层DRAM裸片像千层饼一样垂直堆叠起来,中间用TSV(硅通孔,Through-Silicon Via)和微凸点(Micro Bump)做垂直电气互连,再整体封装到GPU旁边。
听起来只是”把已有的DRAM叠起来”,但实际制造难度堪称恐怖。
首先,每层DRAM裸片必须被减薄到20微米以下(大约人类头发直径的五分之一),才能满足封装高度约束:HBM3E的12层封装受制于约775微米的JEDEC总高限制,而HBM4计划用混合键合在类似高度内塞进16层。晶圆减薄到这个程度后极其脆弱,翘曲(warpage)问题严重,机械应力稍大就碎。
其次,TSV本身就是在晶圆上打穿通孔并填充铜导体,孔径只有几微米到十几微米,偏差超过0.1微米就可能导致整个芯片报废。一颗HBM芯片内部有数千个TSV和微凸点,每一个都必须完美无缺。
三星HBM4的良率据传低于60%。原因之一是三星在HBM4上做了一项大胆创新:逻辑基片(Logic Base Die)改用4nm先进逻辑工艺制造,而上面的DRAM层仍用10nm级DRAM工艺。这种”异质集成”把两种完全不同的工艺体系整合在同一模块里,是目前半导体制造中最顶级的难题之一。这种架构相当于用钢筋混凝土打地基(4nm逻辑工艺),上面再盖一座精密玻璃幕墙写字楼(10nm级DRAM工艺),两种工艺体系硬焊在同一模块里。
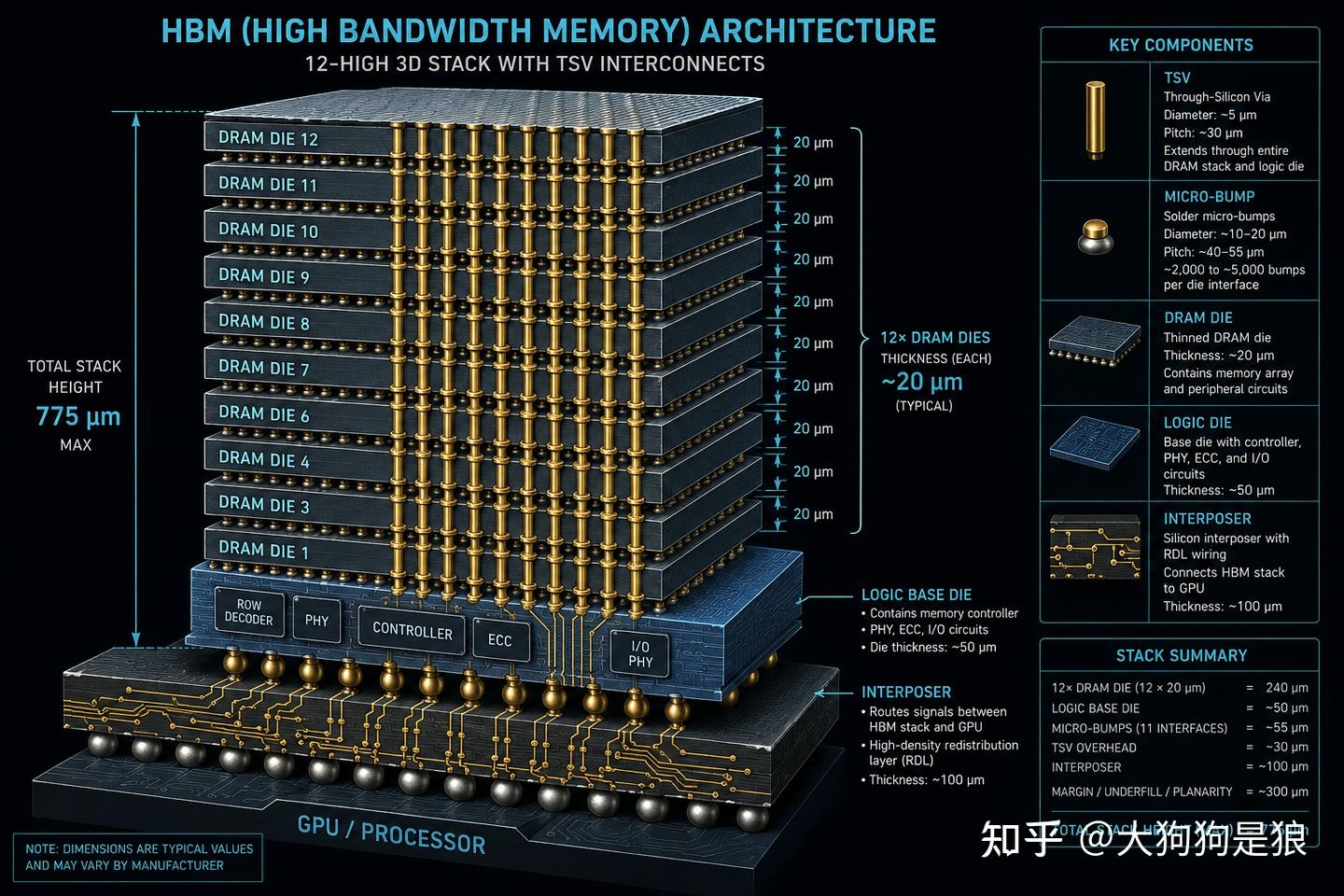
HBM制造中的缺陷检测同样到了极限。凸点间距从HBM3E的20-30微米缩小到HBM4的约10微米,缺陷数量随着互连线密度指数级增长。Bruker、Onto Innovation等检测设备厂商正在把X射线、声学、共焦激光等多种手段推向物理极限,但10微米以下的缺陷检出仍然极具挑战。
目前HBM在AI芯片总成本中的占比,已经从2024年第一季度的52%涨到了2025年第四季度的63%。Epoch AI的数据显示,你花100块钱买一块AI加速卡,其中63块钱是内存的成本。GPU反而是便宜的。
DRAM vs NAND:造瑞士表和盖楼的差距
很多人把DRAM和NAND混为一谈,觉得都是”存数据的芯片”。但它们的技术路线天差地别。
NAND闪存的存储单元是单一浮栅晶体管,结构简单。主流技术路线是像盖楼一样不断往上堆叠,从128层堆到232层再到300层,线宽微缩的压力远小于DRAM。而且NAND有一个天然优势:可以容忍一定比例的坏块,通过冗余设计和纠错算法(ECC)屏蔽缺陷,良率爬升相对容易。
DRAM则几乎不能容忍缺陷。一颗80亿单元的芯片,任何一个单元出问题都可能导致整行整列的数据异常。这还不算,DRAM的生产线和NAND的生产线根本不能互相复用。NAND产线的设备是为了”盖楼”准备的,粗放但能处理极深的通孔;DRAM产线的设备是为”雕刻”准备的,精密到原子级别。

Sohu上一篇分析文章有个精准的类比:指望一家NAND工厂转产DRAM,”无异于让建筑工地去生产瑞士手表”。全行业从未出现过NAND厂商反向进入DRAM并大规模量产的先例。
反过来却可以。三星、SK海力士、美光三巨头都是先在DRAM站稳脚跟,建立了极深的技术护城河和现金流之后,再去做NAND。属于”从难到易”的降维打击。
这也解释了为什么DRAM市场的利润率远高于NAND。长鑫存储2026年Q1的净利润率接近49%,部分季度盈利能力直接追近国际一线厂商。而NAND市场即便是龙头长江存储,受制于更多竞争者和更频繁的价格战,毛利率水平始终难以追上DRAM。
3D DRAM是三十年来最大的技术拐点
平面DRAM微缩的路已经快走到头了。业界共识是,10nm节点以下,纯粹靠缩小单元面积已经无法维持性能和良率的平衡。出路只有一条:像NAND一样,走向3D堆叠。
三星是最激进的一家。2026年4月,韩媒The Elec报道三星已成功生产出采用4F²单元结构和VCT(垂直通道晶体管,Vertical Channel Transistor)技术的10a工艺(实际线宽约9.5-9.7nm)DRAM晶圆,并在测试中确认了功能正常的芯片。4F²架构将传统DRAM的6F²单元面积缩减为2F×2F正方形,理论上可以提升30%到50%的单位面积容量。
这是业界首次在DRAM生产中引入垂直晶体管结构,相当于把原来平铺在地面上的电路”竖”起来。三星计划2028年量产这一技术。
SK海力士选择了另一条路线:4F² VG(Vertical Gate)技术,同样将晶体管垂直排列,但具体工艺路径不同于三星的VCT。
还有一条更激进的技术路线来自欧洲微电子研究中心(imec)。他们提出的IGZO 2T0C结构,干脆去掉了电容,用两个基于铟镓锌氧化物(IGZO)的薄膜晶体管替代传统的1T1C结构。IGZO材料的宽禁带特性使晶体管关断电流极低,保持时间可达400秒以上,比传统DRAM的毫秒级高出近百万倍。
imec在Nature Reviews Electrical Engineering上发表了详细论文,展示了保持时间超过4.5小时的2T0C DRAM单元。日本铠侠也在IEDM 2025上展示了OCTRAM技术,采用八层水平氧化物半导体晶体管堆叠。中科院微电子所、北京大学、Macronix等机构也在跟进研究。
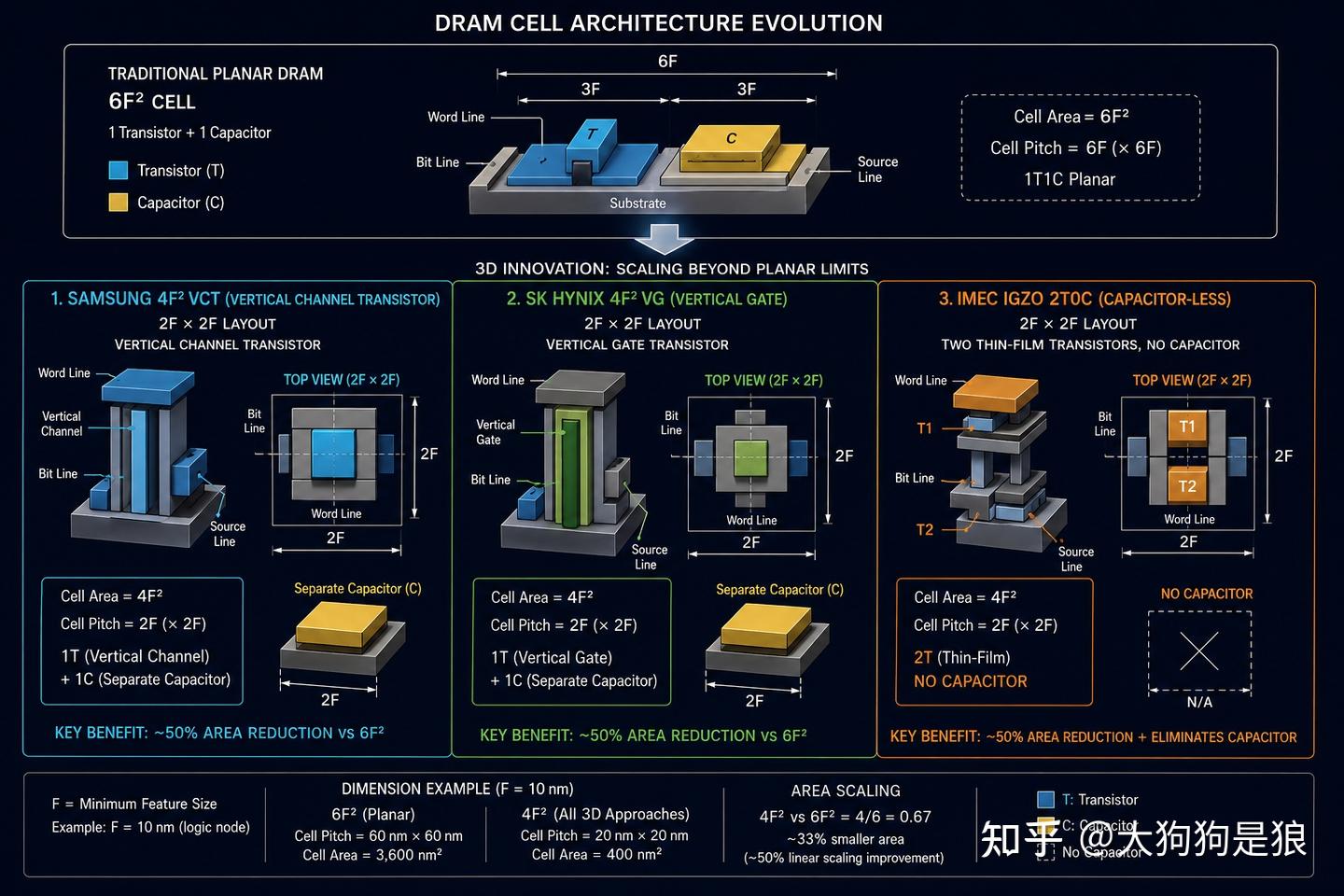
不过,3D DRAM并不是简单地把2D结构竖起来就完事。在硅和硅锗交替堆叠数十到数百层的结构中,两种材料之间晶格常数的微小差异(晶格失配)会积累内部应力,导致晶圆翘曲、位错和界面缺陷。3D DRAM需要蚀刻、沉积、材料和工艺工程多个环节的协同配合,其集成难度不亚于3D NAND最早期开拓时的挑战。
Yole Intelligence在2024年的报告中将IGZO-DRAM列入了长期技术路线图。机构预测,到2030年全球3D DRAM市场规模有望达到1000亿美元,2034到2035年间3D和2D DRAM的产能将出现交叉。
长鑫存储用DUV硬刚,成为全球第四
谈内存制造的难度,绕不开中国长鑫存储(CXMT)这个案例。
长鑫2016年在合肥成立时,全球DRAM市场已经被三家瓜分干净,三巨头合计份额超过95%。没有EUV,没有最先进的刻蚀设备,甚至连DUV光刻机的获取都受到出口管制限制。TechInsights在2025年3月的报告中用了”First China-made DDR5 Memory Released”的标题,语气里透着惊讶。
长鑫的技术路径是DUV多重曝光。在17nm节点的DDR5上,良率从最初量产时的约50%爬升到2025年底的80%,再到2026年Q1突破85%到90%。速率从DDR4-3200一路推到DDR5-8000Mbps,颗粒容量做到24Gb。用DUV做到这个水平,工艺调校的精细程度远超有EUV的情况。
招股书数据显示,长鑫2025年研发投入95.93亿元,研发投入比例显著高于三星(11.31%)、SK海力士(6.66%)和美光(10.16%)。这种超额投入某种程度上就是在用钱换技术差距。
2026年Q1,长鑫营收508亿元(同比增长719%),净利润330亿元。全球DRAM份额冲到约8%,正式成为”3+1”格局中的那个”1”。5月27日,科创板IPO过会,拟募资295亿元。
但坦率说,长鑫跟三巨头的差距仍然明显。三巨头已经推进到1c节点(约12-13nm),而长鑫的主力还在17nm。三星刚刚成功流片10a(9.5nm),正向着3D DRAM的全新时代冲刺。HBM领域,SK海力士独占全球超过一半的份额(Counterpoint Research 2026年Q1数据约58%),长鑫的HBM3还处在验证阶段。制程代差目前大约落后两代(3到5年),且设备获取的不确定性始终存在。
存进去容易,读出来才是地狱
说了这么多结构设计和工艺难题,还有一层几乎没人提的难度:读出放大器(Sense Amplifier)。
电容里存的电荷信号极其微弱,读出时只有几十毫伏的摆幅。要在纳秒级的时间窗口内,从一堆噪声里准确判断这到底是”0”还是”1”,读出放大器的设计直接决定了DRAM的时序参数(tRCD、tRP、tRAS、tRFC)。这些参数才是你买内存条时看到的CL延迟背后的物理含义。DDR5-8000的频率再高,如果时序参数跟不上,实际延迟可能还不如一颗调校好的DDR5-6400。
更棘手的是Row Hammer问题。2014年,卡内基梅隆大学的研究团队首次公开演示:只要反复高频访问DRAM中某一行的数据,相邻行的电荷就会被电磁耦合干扰翻转,导致数据损坏。这从一个学术发现迅速变成了安全漏洞,攻击者可以利用它绕过沙箱隔离、提权甚至接管系统。DDR4时代这是灾难性的,DDR5通过内部目标行刷新(Target Row Refresh)缓解了症状,但并未从物理层面根治。HBM同样受影响,只不过HBM堆叠后散热条件更差,Row Hammer触发的阈值可能更低。
实验室做几颗容易,量产是另一回事
实验室做出几颗能用的DRAM芯片并不稀奇。YouTube上甚至有人拍视频在自家花园棚屋里”手搓”RAM,播放量过百万。但当你要在300mm晶圆上同时制造数万亿个存储单元,每一个都要稳定可靠地工作好几年,每个偏差超过纳米级的工艺步骤都可能导致整片晶圆报废时,这就从技术问题变成了资本、供应链、人才的系统性壁垒。一座先进DRAM晶圆厂的造价已经超过200亿美元,美光单在内华达的一个项目就计划投入1000亿美元以上。这个数字够造三艘福特级航母。长鑫存储招股书披露的累计资本开支也已超过1500亿元人民币。换句话说,DRAM这个赛道连”上桌”的门票都是千亿元级别的。
DRAM产业在过去三十年里淘汰了一轮又一轮玩家,每次制程迭代都是鬼门关。奇梦达没跨过50nm,尔必达没跨过30nm。
三星的10a VCT晶圆已经出片,但垂直沟道晶体管在高频操作下的阈值电压漂移和散热问题,目前公开文献里几乎找不到讨论。未必是没遇到,更可能是遇到了但不敢说。SK海力士的4F² VG路线图铺到了2028年,imec的无电容IGZO DRAM还在从400秒的保持时间往数小时级别推进。中国这边,长鑫用DUV硬把DDR5推到了8000Mbps,正在规划15nm节点和HBM3的试产。
DRAM的下一个瓶颈未必是电容,可能是热管理。
参考来源:
- 美光CEO访谈:人们总是低估制造存储的难度
- 美光1α DRAM制程技术详解:走进1-Alpha DRAM
- DRAM vs NAND制造难度对比:DRAM难在哪里?NAND卷在何处?
- DRAM成为AI时代硬通货分析:比黄金还猛
- imec IGZO 2T0C DRAM技术:Disrupting the DRAM roadmap
- HBM制造难度分析:HBM,太难了
- 三星4F² VCT DRAM突破报道:4F架构全球首产!三星突破DRAM物理极限
- DRAM产业九大进入壁垒:DRAM产业的九大进入壁垒
- 长鑫存储IPO过会及技术进展:长鑫科技科创板过会
- SK海力士1c DRAM良率进展:SK海力士发力1c DRAM
- DRAM技术演进与市场分析:DRAM,巨变前夜
- DRAM,开启30年新赌局:DRAM,开启30年新赌局
- AI芯片内存成本占比分析:AI芯片63%的成本是内存
- 存储芯片生产全流程:存储芯片生产