现在怎么没有人提用AMD MAX395去跑本地大模型了?
现在性价比最高的大模型工作站应该是采用AMD AI Max处理器的核显本。
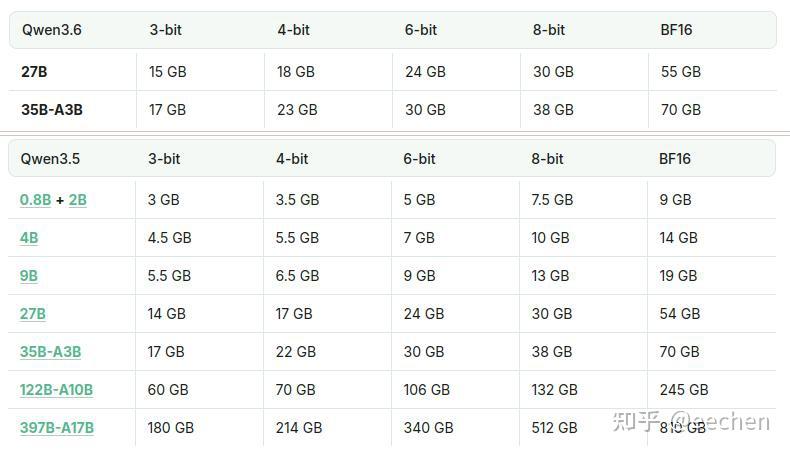
比如你要跑4位量化的Qwen3.6-35B-A3B这个MoE模型,你至少需要一张24GB显存的显卡(比如7900XTX、4090、5090Dv2、5090移动版),但你用一台64GB统一内存的395核显本,很轻松就能跑起来,而且速度并不慢,生成速度能达到60+ tok/s。受395核显本的内存带宽(256GB/s)限制,其实跑更大规模参数的模型意义并不大。
去年首发的AI Max+ 395,基本可以当作AMD笔记本最强处理器R9-9955HX和最强核显Radeon 8060S的合体,但价格昂贵,曲高和寡。
AMD为了救场(元器件去库存),今年年初加推了AI Max+ 392,12核24线程(相比395少了4个核心),但仍保留64MB超大L3缓存(堪称笔记本版X3D),仍集成了AMD最强核显Radeon 8060S,图形性能接近RTX5060移动版。
32GB内存版本,价格在8000元+,最大可以设置24GB显存。
64GB内存版本,价格在10000元+,最大可以设置48GB显存。
实际上AMD统一内存有成熟的GTT动态显存技术,所以完全没必要预留这么大的显存,没必要预留超过8GB的显存,通常预留2GB显存就好了。
这就意味着1万元的预算,就可以轻松运行14B模型(FP16精度,需要28GB+显存)甚至32B模型(INT8精度,需要32GB+显存)。
100W左右的功耗,122TOPS的AI算力,256GB/s的内存带宽(跟Mac M4 Pro和Nvidia DGX Spark一个级别,但价格便宜得多),虽然不快,但已经解决了能不能跑的问题。
可以说,既可以当一台甜品游戏本,也能当一台大模型移动工作站,性价比和性能都不输Mac mini(M4 Pro甚至M5 Pro的图形性能是斗不过AMD最强核显Radeon 8060S的,带宽也是半斤八两)。
A卡对Linux的支持相当不错,驱动集成在Linux内核树,系统可以做到开箱即用,对有游戏需求和大模型开发需求的Linux极客也是一个不错的选择。
给个参考,不是395处理器,而是低一个档次的365处理器,Linux上用AMD轻薄本365处理器880M核显本地跑Qwen3.6-35B-A3B-IQ4_NL这个热门的MoE模型,生成速度也能达到25 tokens/s,amdgpu_top显示APU功率为37W,不严谨地估算,功率增加1W,每秒多生成1个token。
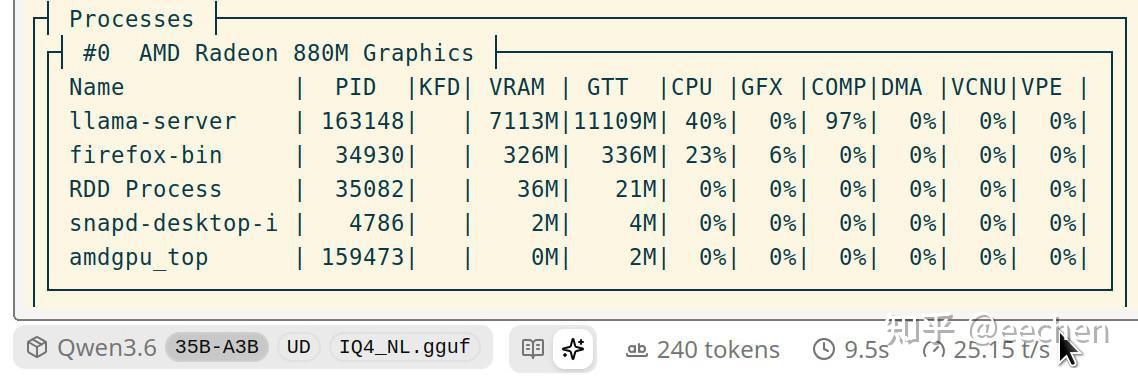
395核显比365核显大约强3倍,速度能达到60+ tokens/s(20+可用、40+流畅、60+飞快)。
395在我看来最甜的地方就是跑Q8量化的MoE模型Qwen3.6-35B-A3B(至少需要40GB显存或统一内存),速度仍有40+ tokens/s,而且还有充裕的空间来存放KV cache上下文。为什么是Q8量化呢?因为8-bit量化才是模型的完全体(16-bit量化是究极体)。
PS:
这个帖子下居然还有Intel粉丝吹Intel的3代Ultra,这玩意仍然是双通道128bit,把内存频率拉到9600MHz,内存带宽也只是154GB/s,而AMD AI Max 392、Mac M4 Pro、Nvidia DGX Spark的内存带宽都在256GB/s以上,明显不是一个级别的东西,Intel搞AI PC,我看来是没有一点诚意,牢英还当自己是以前的老大是吧。
再就是游戏性能,AI Max 392集成的是AMD最强核显Radeon 8060S,性能堪比RTX4060,再加上64MB超大L3缓存,不管是3A游戏还是电竞网游,帧数都是暴打3代Ultra。
I粉还是期待牢英下一代大核显Razor Lake AX和Serpent Lake去挑战AMD Halo核显吧。
从Nvidia发布DGX Spark迷你主机到最近发布的RTX Spark笔记本,再一次印证了AMD AI Max方案的前瞻性。