
国产计算卡海光K100-AI战力如何?单卡部署Qwen3.6-27B/Gemma4-26B-A4B实战表现
众所周知,随着全球AI产业的升级和中美政治关系的动荡,英伟达的计算卡不仅一卡难求,价格高昂,消费者不得不忍受其金子一般的显存价格,并且由于禁售令,斥重金购买了旗舰卡后还不享受保修。
来看看英伟达显卡的价格吧家人们
| 型号 | 核心算力(FP16) | 显存容量 | 官方售价 | 到手价 |
|---|---|---|---|---|
| RTX5090 | 419 TFLOPS | 32G GDDR7 | 16499 | 30000+ |
| RTXPRO6000 | 500 TFLOPS | 96G GDDR7 | 78000 | 100000+ |
| H100 | 1,979 TFLOPS | 80G HBM3 | 未公开 | 130000+ |
| H200 | 1,979 TFLOPS | 141G HBM3e | 未公开 | 300000+ |
这个价格对于个人玩家而言简直是天价,而且还未必能买得到!
天下苦Nvidia久矣!
想跑大模型,但是买不起N卡,就算买得起,还可能买不到。
那怎么办?
不如支持国产?
那来看看国产卡吧(仅举例部分型号,价格未必准确)
| 型号 | 核心算力 | 显存容量 | 官方售价 | 到手价 |
|---|---|---|---|---|
| (华为)昇腾920 Pro | 400 TFLOPS | 128GB HBM3 | 200000 | 200000+ |
| (华为)昇腾950PR | 390 TFLOPS | 112GB HBM3 | 70000 | 70000+ |
| (海光)Z100 | 24.5 TFLOPS | 32G HBM2 | 没查到 | 2000 |
| (海光)K100-AI | 196 TFLOPS | 64G HBM2 | 20000 | 15000 |
| (寒武纪)思元590 | 256 TFLOPS | 96G HBM2e | 70000 | 没查到 |
看来看去,华为和寒武纪对个人玩家而言还是太昂贵了,相对适合个人玩家的是海光。
而我手里正好有一张海光K100-ai DCU,它的表现如何?
当然,这里先叠个甲:我不是要说海光 K100-AI 能直接平替 5090,更不是要吹它吊打 H100、H200。参数表看着热闹,但真正拿来跑大模型的时候,决定体验的从来不只是 TFLOPS,还有显存容量、驱动生态、框架兼容性、量化支持、推理后端、内存带宽,以及最重要的一点——你到底能不能把它买回来、装起来、跑起来。
海光 DCU 本身属于面向 AI 和通用计算场景的 GPGPU 架构加速卡,公开资料中也将 DCU 描述为高性能 GPGPU 架构 AI 加速卡;同时,OpenCloudOS 的部署文档里已经能看到对海光 K100_AI、BW1000 等设备,以及 DCU 驱动、DTK 软件栈的支持说明。也就是说,它不是那种“只能在 PPT 里跑分”的东西,而是确实有一套面向实际部署的软件环境。
但问题也正好出在这里:能跑,不等于好跑;能装驱动,不等于生态完善;能点亮,不等于大模型推理体验就一定丝滑。尤其是对个人玩家来说,大家关心的根本不是企业采购白皮书里的“国产算力生态建设”,而是几个非常朴素的问题:
第一,单卡 64GB 显存到底能不能装下 26B、27B 级别的大模型?
第二,Qwen3.6-27B、Gemma4-26B-A4B 这种模型在 K100-AI 上能不能正常推理?
第三,速度到底是“能用”,还是“只能勉强跑”?
第四,折腾驱动、环境、依赖、推理框架的过程到底有多痛苦?
所以这篇文章不打算写成参数复读机,也不想写成“国产一定行”的情绪稿。我的思路很简单:既然大家都说国产 AI 计算卡越来越成熟,那就把它插进机器里,装系统、装驱动、配环境、拉模型,直接用真实模型跑一遍。
跑得动就是跑得动,跑不动就是跑不动;哪里顺滑就夸哪里,哪里卡壳也直接说。毕竟对于个人玩家来说,最有价值的不是一句“生态完善”,而是你照着这篇文章操作之后,能不能少踩几个坑。
废话不多说,直接上实战。
环境准备
系统:Ubuntu22.04
DTK驱动:dtk-26.04驱动
DTK:DTK-26.04
Docker:拉取最新版即可 文档
下载DTK驱动:
wget https://download.sourcefind.cn:65024/file/6/dtk-26.04驱动/rock-6.3.30-V1.4.1a.run删除旧驱动(如有):
apt-get remove rock安装驱动:
chmod 755 rock*.run && ./rock*.run && reboot验证DCU驱动安装是否成功:
lsmod | grep dculsmod | grep hydcu拉取最新版Docker
docker pull vllm/vllm-openai:latest海光K100-ai官方路线
海光提供了开箱即用的vLLM镜像,所以使用vLLM可以享受到接近无痛的部署体验。
镜像:vllm018-ubuntu22.04-dtk26.04-gemma4-0413-k100ai
下载镜像:
docker pull harbor.sourcefind.cn:5443/dcu/admin/base/custom:vllm018-ubuntu22.04-dtk26.04-gemma4-0413-k100ai创建容器:
# /opt/hyhal 用来放模型文件,这里以 Qwen3.6-27B 为例
# 容器名可以按自己习惯修改,这里使用 vLLM
docker run -it \
--network=host \
--ipc=host \
--shm-size=16G \
--device=/dev/kfd \
--device=/dev/mkfd \
--device=/dev/dri \
-v /opt/hyhal:/opt/hyhal \
--group-add video \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--name vLLM \
harbor.sourcefind.cn:5443/dcu/admin/base/custom:vllm018-ubuntu22.04-dtk26.04-gemma4-0413-k100ai \
/bin/bash启动并进入容器:
docker start vLLM #启动容器
docker exec -it vLLM bash #进入容器启动vLLM:
export VLLM_USE_V1=0
nohup vllm serve /opt/hyhal/Qwen3.6-27B \
--port 8080 \
--api-key "sk-vllm-test-q8" \
--served-model-name "qwen3.6-27b-local" \
--max-model-len 8192 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--dtype float16 \
--trust-remote-code > vllm_server.log 2>&1 &盯一下日志:
tail -f vllm_server.log成功证明:
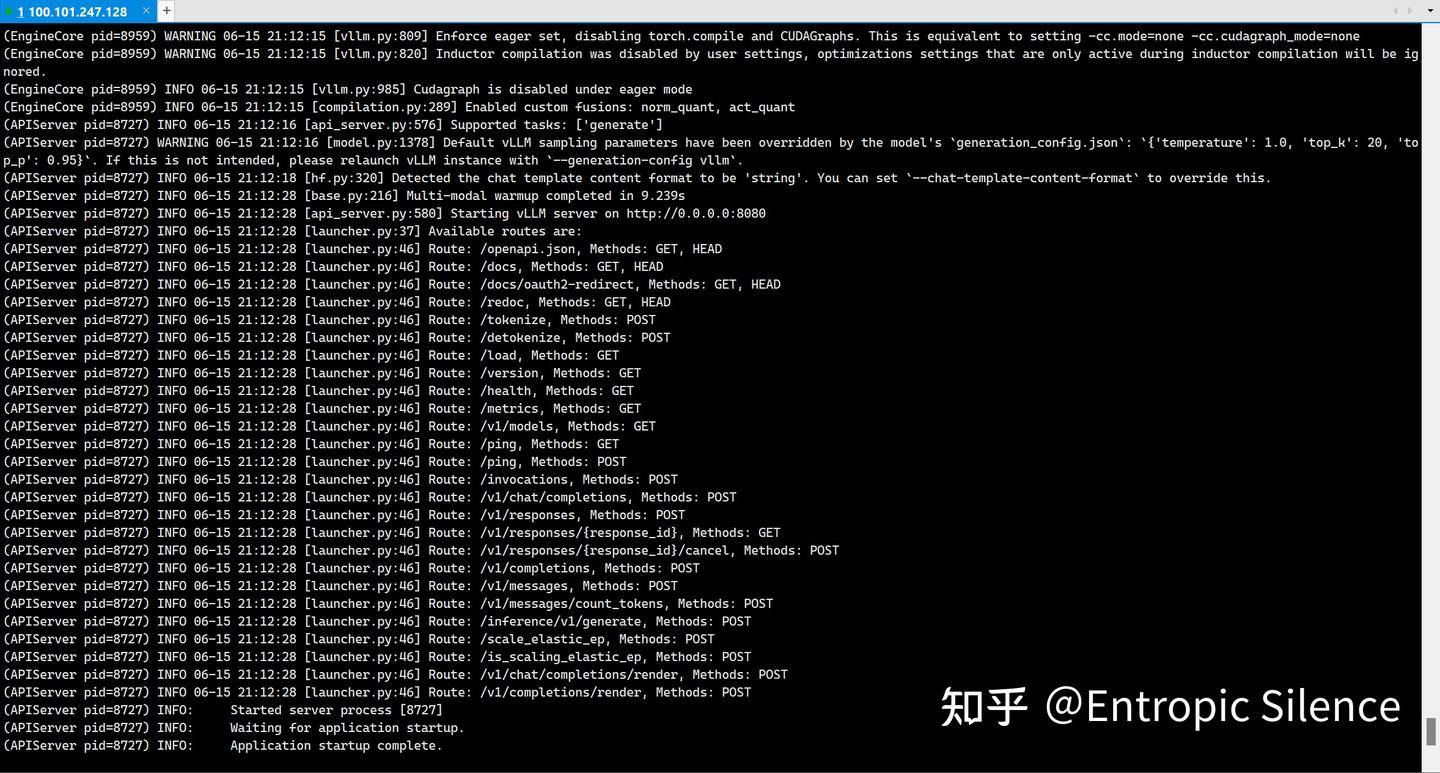
测试:
curl http://localhost:8080/v1/chat/completions \
> -H "Content-Type: application/json" \
> -H "Authorization: Bearer sk-vllm-test-q8" \
> -d '{
> "model": "qwen3.6-27b-local",
> "messages": [
> {"role": "user", "content": "你好,请确认你的模型名称,并用生动的语言向我解释一下什么是“奥卡姆剃刀原理”。"}
> ],
> "temperature": 0.7,
> "max_tokens": 512
> }'
测试结果:
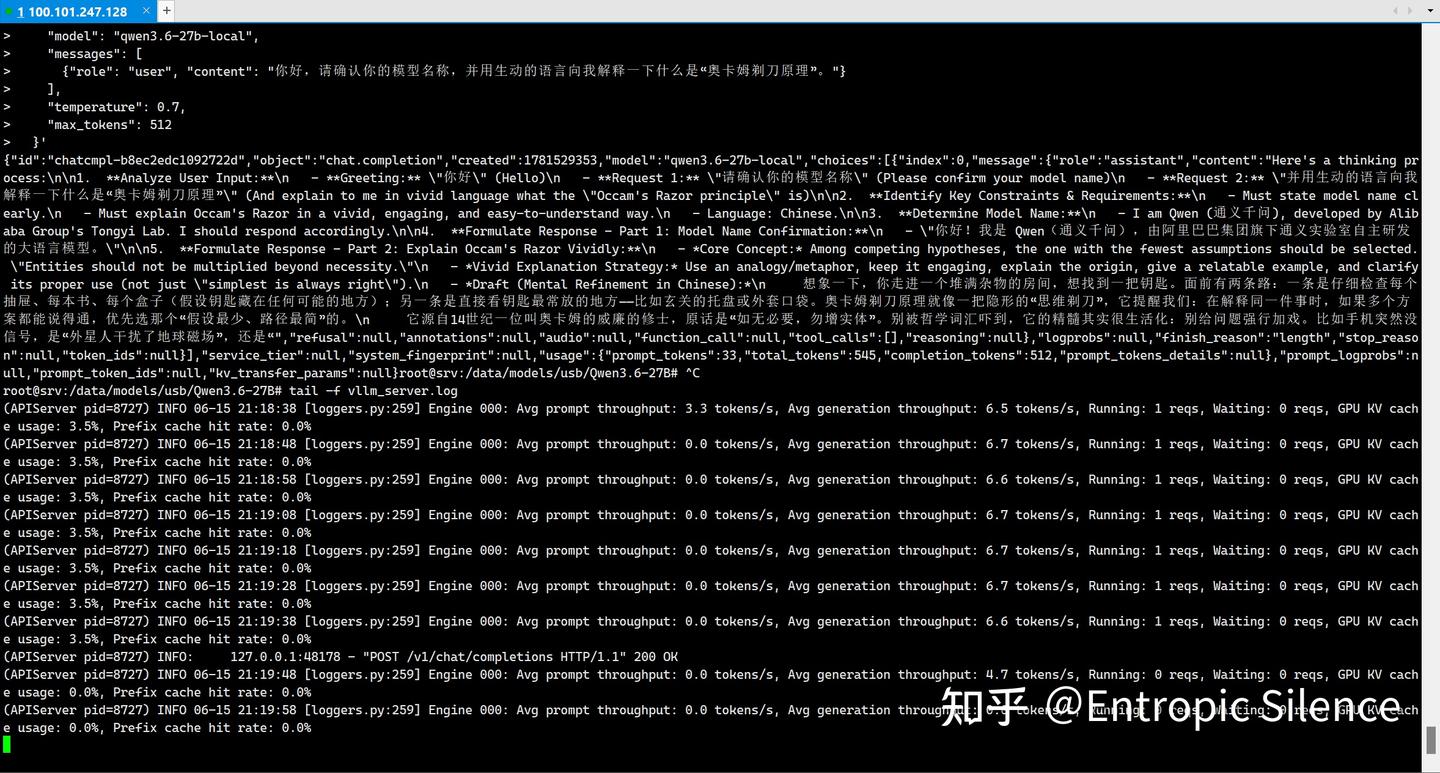
Avg prompt throughput: 3.3 tokens/s (提示词处理速度)
Avg generation throughput: 6.7 tokens/s (文本生成速度)
vLLM是面向企业级,高吞吐,多用户的引擎,对于单卡部署的个人玩家而言并不太友好。
有经验的同志应该已经注意到了:为什么要跑FP16全精度的Qwen3.6-27B?vLLM明明支持AWQ量化或者其它量化精度,为什么不用?
很遗憾,海光K100-ai只原生支持FP32、TF32、BF16、FP16、INT8,并且缺少Conch 算子:它只支持 Group Size = 128 的模型。Exllama 算子:无法处理uint4的特殊封包格式。
一共64G显存,除掉vLLM开销,能用的只有60G左右,再算上KVCache,能运行的模型大小就限制在了27B以下。
而近期最火的模型:
| Dense | Qwen3.6-27B | Gemma4-31B |
|---|---|---|
| Moe | Qwen3.6-35B-A3B | Gemma4-26B-A4B |
能运行的就只剩下Qwen3.6-27B和Gemma4-26B-A4B。
而经测试海光K100-ai并不擅长Dense模型(6.7t/s真的能用吗?)
所以可选项就只剩下Gemma4-26B-A4B了。
实在鸡肋了点。
所以,在社区的佬友们的努力下,探索出了新的方案:
光合社区路线
佬友们都知道,最适合个人玩家的引擎是llama.cpp。
可是海光官方并没有提供llama.cpp的支持,所以社区大佬给出了解决方案:Z100L四卡运行`llama.cpp + HIP + GGUF`运行gemma-4-31B-it教程
这篇文章是基于多卡Z100L的教程,核心思路在于在 Z100L/海光 DTK 这种非标准 ROCm 环境上,不硬伪装、不硬推复杂框架,而是基于上游 llama.cpp + HIP + GGUF 做最小适配,选择稳定的多卡 layer split 和长上下文参数,把 4 卡机器收敛成一个可用的本地推理服务。
这篇文章虽然没有直接给出单卡K100-ai的解决方案,但是提供了宝贵的思路,于是我们可以自行在K100-ai上编译llama.cpp。
编译过程较为繁琐,这里不过多赘述,因为社区已经有大佬编译好了,下载即用。
如果有需要,我会再发一篇编译教程。
大佬的帖子:K100_AI 编译的 llama.cpp 支持 Qwen3.6 MoE 模型
下面是教程
依然进入前文创建的容器:
docker start vLLM #启动容器
docker exec -it vLLM bash #进入容器下载编译好的 llama.cpp:
wget http://60.190.128.9/llama.cpp.tar.gz解压:
cd /workspace
tar -zxvf llama.cpp.tar.gz
cd llama.cpp注入环境变量:
export LD_LIBRARY_PATH=$(pwd)/build/bin:$(pwd)/build/src:$(pwd)/build/common:$(pwd)/build/ggml/src:/opt/dtk/lib:/opt/dtk/lib64:/opt/dtk/hip/lib:/opt/dtk/hsa/lib:/opt/dtk/hipblas/lib:/opt/dtk/rocblas/lib:$LD_LIBRARY_PATH如果不想每次都注入一次,可以:
echo 'export LD_LIBRARY_PATH=/opt/hyhal/llama.cpp/build/bin:/opt/hyhal/llama.cpp/build/src:/opt/hyhal/llama.cpp/build/common:/opt/hyhal/llama.cpp/build/ggml/src:/opt/dtk/lib:/opt/dtk/lib64:/opt/dtk/hip/lib:/opt/dtk/hsa/lib:/opt/dtk/hipblas/lib:/opt/dtk/rocblas/lib:$LD_LIBRARY_PATH' >> ~/.bashrc启动服务:
#-m /data/models/usb/替换成你想跑的模型 \
nohup /data/models/usb/llama.cpp/build/bin/llama-server \
-m /data/models/usb/Qwen3.6-27B-Q8_K_P.gguf \
-ngl 999 \
-c 32768 \ #32K上下文
-np 4 \ #4并发
--cache-type-k q8_0 \
--cache-type-v q8_0 \
-fa on \
--host 0.0.0.0 \
--port 8080 \
--api-key "sk-qwen36-27b-q8" > /data/models/usb/server.log 2>&1 & #随意更换"sk-"开头的APIKey查看日志:
tail -f server.log成功标志:
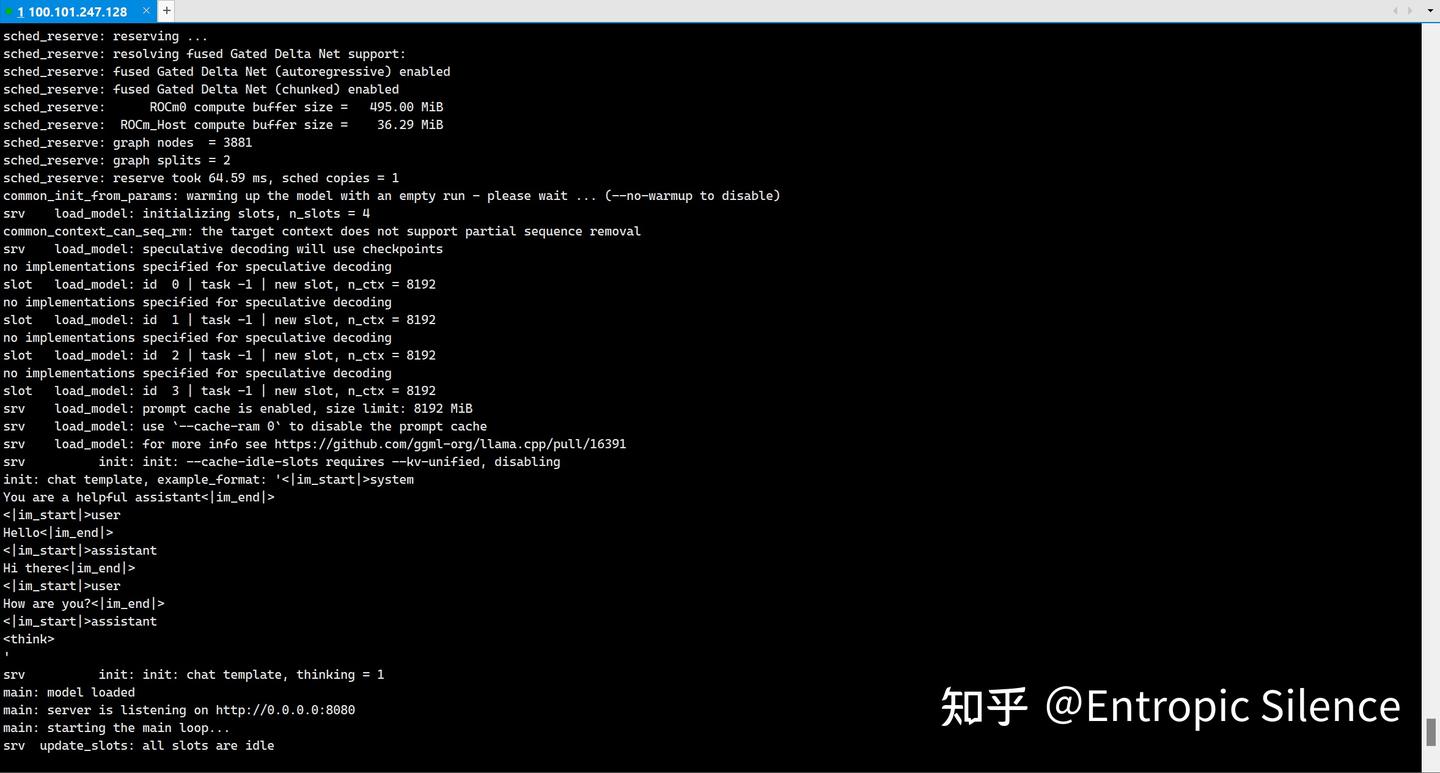
写个测试脚本:
cat << 'EOF' > speed_test.py
import requests
import time
import json
import sys
API_URL = "http://127.0.0.1:8080/v1/chat/completions"
API_KEY = "sk-qwen36-27b-q8"
PROMPT = "Please explain the principle of quantum entanglement in Chinese. Write at least 500 words."
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}",
}
data = {
"model": "qwen-local",
"messages": [
{"role": "user", "content": PROMPT}
],
"stream": True,
"temperature": 0.7,
"max_tokens": 1024,
"stream_options": {
"include_usage": True
}
}
def extract_text_from_chunk(chunk):
"""
兼容多种 OpenAI / llama.cpp / Qwen reasoning 流式格式。
"""
texts = []
choices = chunk.get("choices", [])
if not choices:
return ""
choice = choices[0]
delta = choice.get("delta") or {}
message = choice.get("message") or {}
candidates = [
delta.get("content"),
delta.get("reasoning_content"),
delta.get("reasoning"),
choice.get("content"),
choice.get("text"),
message.get("content"),
]
for item in candidates:
if isinstance(item, str) and item:
texts.append(item)
return "".join(texts)
print(f"Sending request to {API_URL}...")
print("-" * 50)
start_time = time.perf_counter()
first_token_time = None
end_time = None
chunk_count = 0
char_count = 0
completion_tokens = None
prompt_tokens = None
raw_debug_lines = []
try:
with requests.post(
API_URL,
headers=headers,
json=data,
stream=True,
timeout=(10, None),
) as response:
print(f"HTTP Status: {response.status_code}")
print(f"Content-Type: {response.headers.get('content-type', '')}")
print("-" * 50)
response.raise_for_status()
for raw_line in response.iter_lines(decode_unicode=True):
if not raw_line:
continue
line = raw_line.strip()
if line.startswith(("event:", "id:", "retry:", ":")):
continue
# OpenAI/SSE: data: {...}
if line.startswith("data:"):
payload = line[len("data:"):].strip()
else:
payload = line
if payload == "[DONE]":
break
try:
chunk = json.loads(payload)
except json.JSONDecodeError:
if len(raw_debug_lines) < 5:
raw_debug_lines.append(line)
continue
usage = chunk.get("usage")
if usage:
prompt_tokens = usage.get("prompt_tokens", prompt_tokens)
completion_tokens = usage.get("completion_tokens", completion_tokens)
text = extract_text_from_chunk(chunk)
if text:
now = time.perf_counter()
if first_token_time is None:
first_token_time = now
print(f"\n[TTFT First Token: {first_token_time - start_time:.2f} s]\n")
sys.stdout.write(text)
sys.stdout.flush()
chunk_count += 1
char_count += len(text)
else:
if len(raw_debug_lines) < 5:
raw_debug_lines.append(payload)
end_time = time.perf_counter()
print("\n\n" + "-" * 50)
print("Performance Report:")
total_time = end_time - start_time
print(f" Total Time : {total_time:.2f} s")
if first_token_time is not None:
ttft = first_token_time - start_time
generation_time = end_time - first_token_time
print(f" TTFT First Token : {ttft:.2f} s")
print(f" Generation Time : {generation_time:.2f} s")
print(f" Output Chunks : {chunk_count}")
print(f" Output Characters : {char_count}")
if completion_tokens:
print(f" Completion Tokens : {completion_tokens}")
print(f" Token Speed : {completion_tokens / generation_time:.2f} tokens/s")
else:
print(f" Char Speed : {char_count / generation_time:.2f} chars/s")
print(" Token Speed : unavailable from client; check llama.cpp server log")
else:
print(" No text field was parsed from stream.")
print(" Server may be returning an unexpected schema.")
if raw_debug_lines:
print("\nFirst raw chunks:")
for i, item in enumerate(raw_debug_lines, 1):
print(f" [{i}] {item[:1000]}")
except Exception as e:
print(f"\nRequest failed: {repr(e)}")
EOF运行测试脚本:
python3 speed_test.py测试结果:
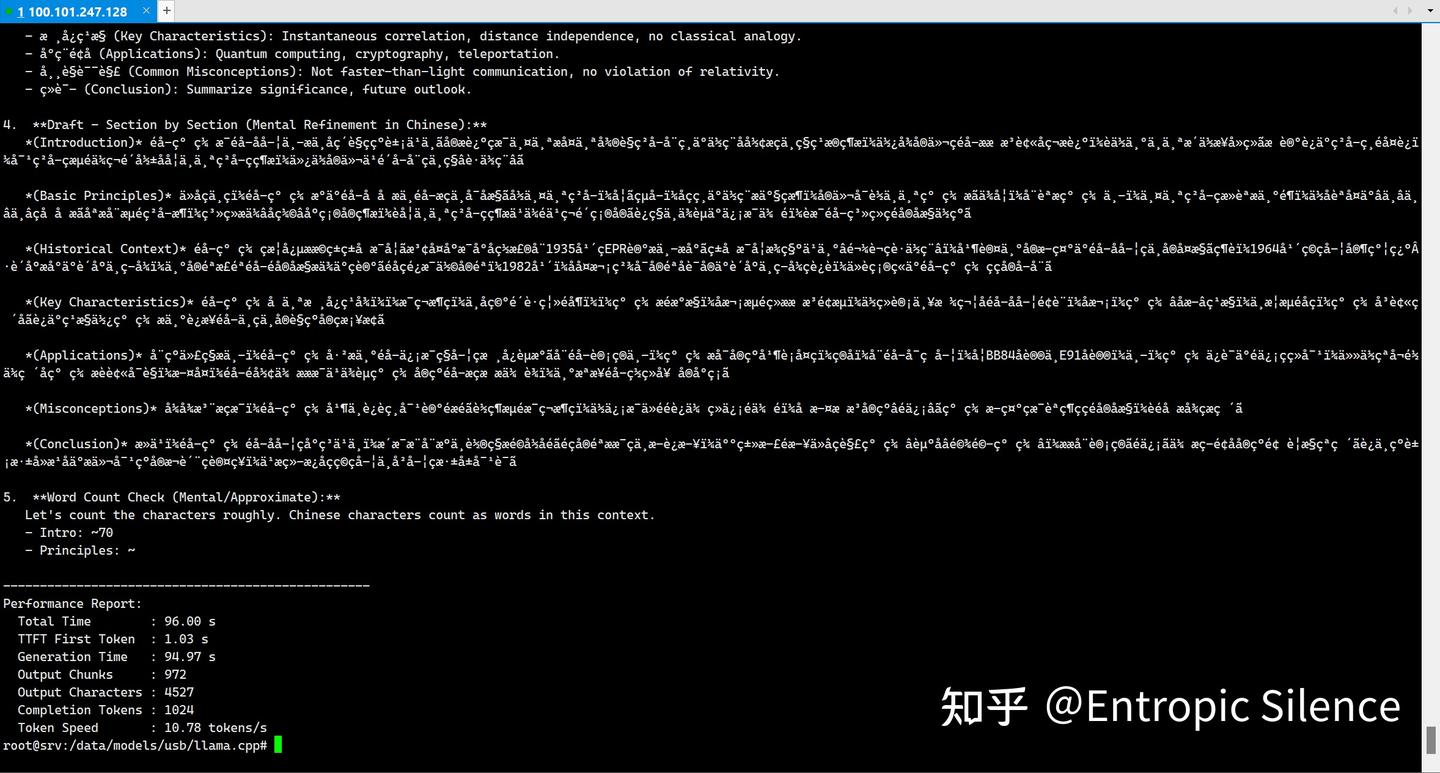
换成llama.cpp后速度达到10t/s以上,有了不小的提升。
不过我们使用llama.cpp可不是仅仅只是为了跑Qwen3.6-27B-Q8_K_P,Moe才是K100-ai的主场。
换成Gemma4-26B-A4B-Q8_K_P试试:
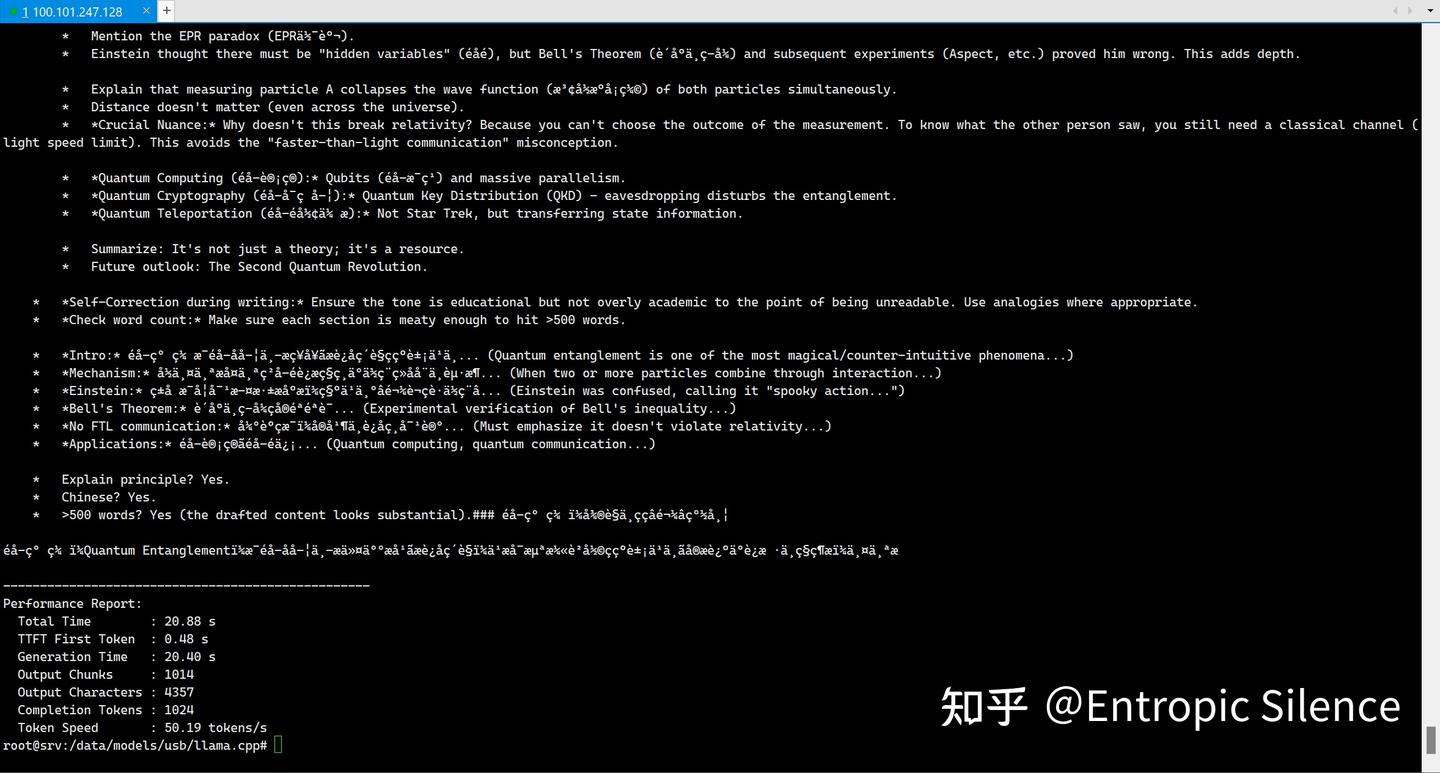
速度达到50t/s,完全达到可用水平。
除此之外,还有MTP,Dflash等功能值得继续探索,这个速度还远远不是极限。
结论
到这里,这次海光 K100-AI 单卡部署 Qwen3.6-27B / Gemma 4 26B A4B 的实战基本就告一段落了。
结论是很明显的:K100-ai的兼容性,软件生态都尚不成熟,依赖官方的优化和技术支持,但是也有极大的探索空间,目前它在我手上的发挥还远远不到它的极限。
vLLM 路线证明了一件事:K100-AI 的确可以较为稳定地跑起 27B 级别的大模型。只是对于个人玩家来说,FP16 路线显存压力大、速度一般,整体而言只能算是"能用"。如果只是到这里,那这张卡的评价确实会比较尴尬:64GB 显存看起来很香,但真用起来又总觉得差点意思。
真正有趣且适合个人玩家的是 llama.cpp + GGUF 这条社区路线。
换成 llama.cpp 后,Qwen3.6-27B-Q8_K_P 的速度明显提升,而 Gemma 4 26B A4B-Q8_K_P 更是跑到了 50 tokens/s 级别。这个结果至少说明,在合适的模型、合适的量化格式、合适的推理后端下,K100-AI 并不是只能“亮机截图”的国产计算卡,而是确实能进入个人玩家可用的本地大模型推理区间。
就实际使用体验而言,海光K100-ai接近于一张64G显存的RTX3090,尽管很多模型需要折腾环境和依赖,离“无痛好用”还有距离,但至少已经是"能投入使用"的级别了。
最后,希望海光继续精进优化,扩大生态优势,给国内玩家带来一些量大管饱的高性能卡。
海光K100-ai爷爷击落邪恶Nvidia显卡.jpg