
本地跑AI大模型,显卡显存怎么选?一张表搞定,别再买错了
我身边有个朋友,花 3000 块买了一张 RTX 4060 Ti 16GB,兴冲冲想在家跑 32B 大模型。
结果?装好模型,点击加载,等了两分钟——报错:显存不足。
他以为是软件问题,重装了三次环境,折腾了一整个周末,最后才搞明白:16GB 显存,根本装不下 32B 的模型。
白花 3000 块,只能跑个 7B 的小模型。
这种坑,我见过太多人踩。
本地跑大模型,最关键的门槛只有一个字:显存。不是显卡多少核,不是算力多强,是显存够不够。
今天这篇,帮你把选显卡、选显存这件事彻底搞清楚。不讲理论,全是干货。
一、显存是什么?为什么它比显卡型号更重要?
很多人买显卡第一眼看的是型号:4090 > 4080 > 4070。
但对于本地跑大模型来说,这个排名没太大意义。你应该第一眼看的是:这张卡有多少 GB 显存。
显存(VRAM)就是显卡自带的内存。 你可以把它理解成显卡的”工作台”——模型要跑起来,必须先把所有数据摆上这张工作台。工作台太小,模型就放不下,直接报错崩溃。
本地跑大模型,显存主要被两件事瓜分:
① 模型权重:模型本身的数据量,这是最大头。一个 32B 参数的模型,哪怕经过压缩,也要吃掉 18-20GB 显存。
② KV Cache(上下文缓存):模型在对话过程中,需要把你说过的每一句话都暂存在显存里,方便前后参考。你的对话越长,这部分占的显存越多。如果你想让模型读完一篇 5000 字的长文再回答你,这部分开销相当可观。
记住这个核心结论:显存不够,模型直接跑不起来。这是硬门槛,不是软限制。
二、核心公式:你需要多少显存?

一句话概括显存的计算逻辑:
所需显存 ≈ 模型参数量 × 量化精度对应的字节数 + KV Cache 预留 + 系统开销(约 2GB)
这里面有个关键词你需要先搞懂:量化精度。
模型原始精度是 FP16(每个参数 2 个字节),但 FP16 非常吃显存。为了能在消费级显卡上跑起来,大家普遍会用量化技术把模型压缩:
- Q8(8位量化):精度最高,显存约是原版的一半
- Q4(4位量化):精度略有损失,但体感很小,显存约是原版的 1/4,这是目前最推荐的方案
- Q2(2位量化):显存占用极小,但模型会明显”变蠢”,不推荐正式使用
下面这张表,是你选卡前最应该看的一张表:
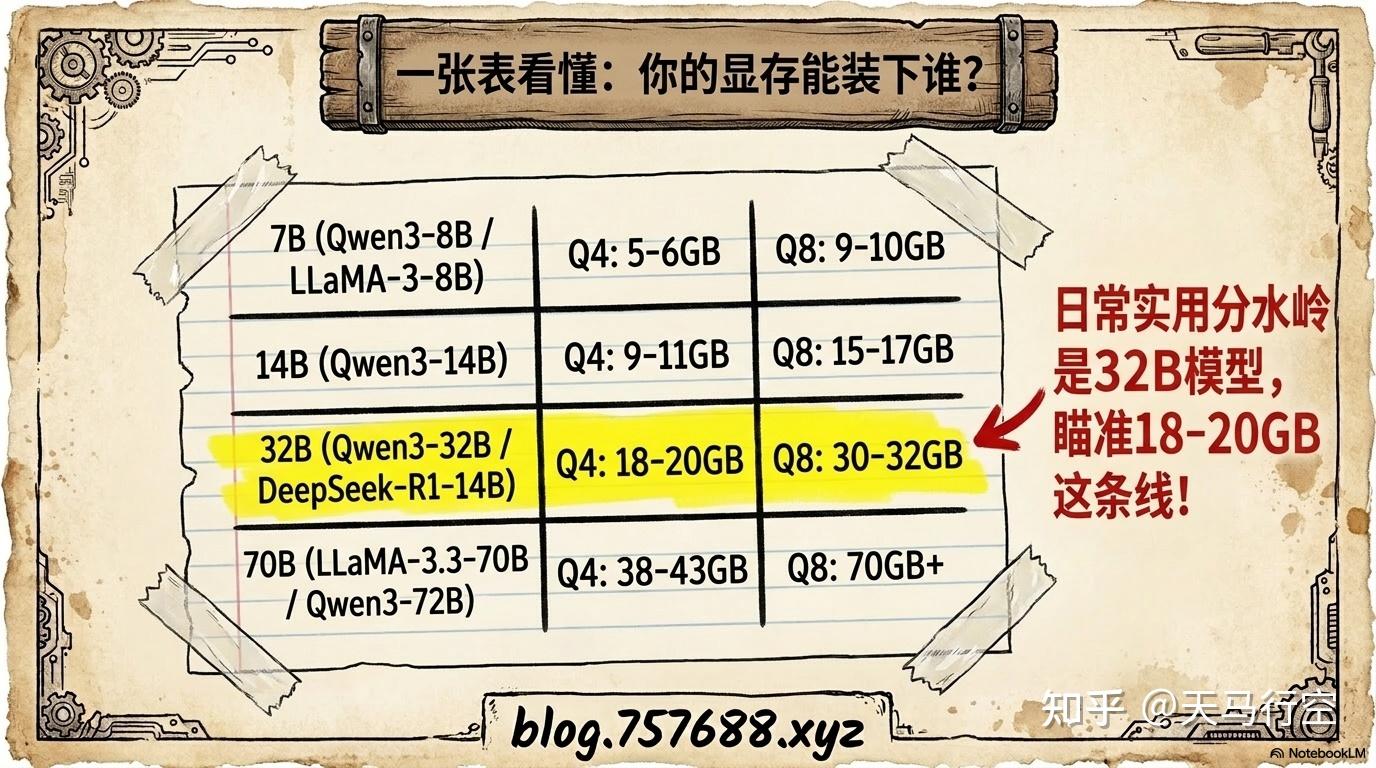
| 模型规模 | 典型代表 | Q4量化显存需求 | Q8量化显存需求 |
|---|---|---|---|
| 7B | Qwen3-8B、LLaMA-3-8B | 约 5-6GB | 约 9-10GB |
| 14B | Qwen3-14B | 约 9-11GB | 约 15-17GB |
| 32B | Qwen3-32B、DeepSeek-R1-14B | 约 18-20GB | 约 30-32GB |
| 70B | LLaMA-3.3-70B、Qwen3-72B | 约 38-43GB | 约 70GB+ |
一个快速判断法:
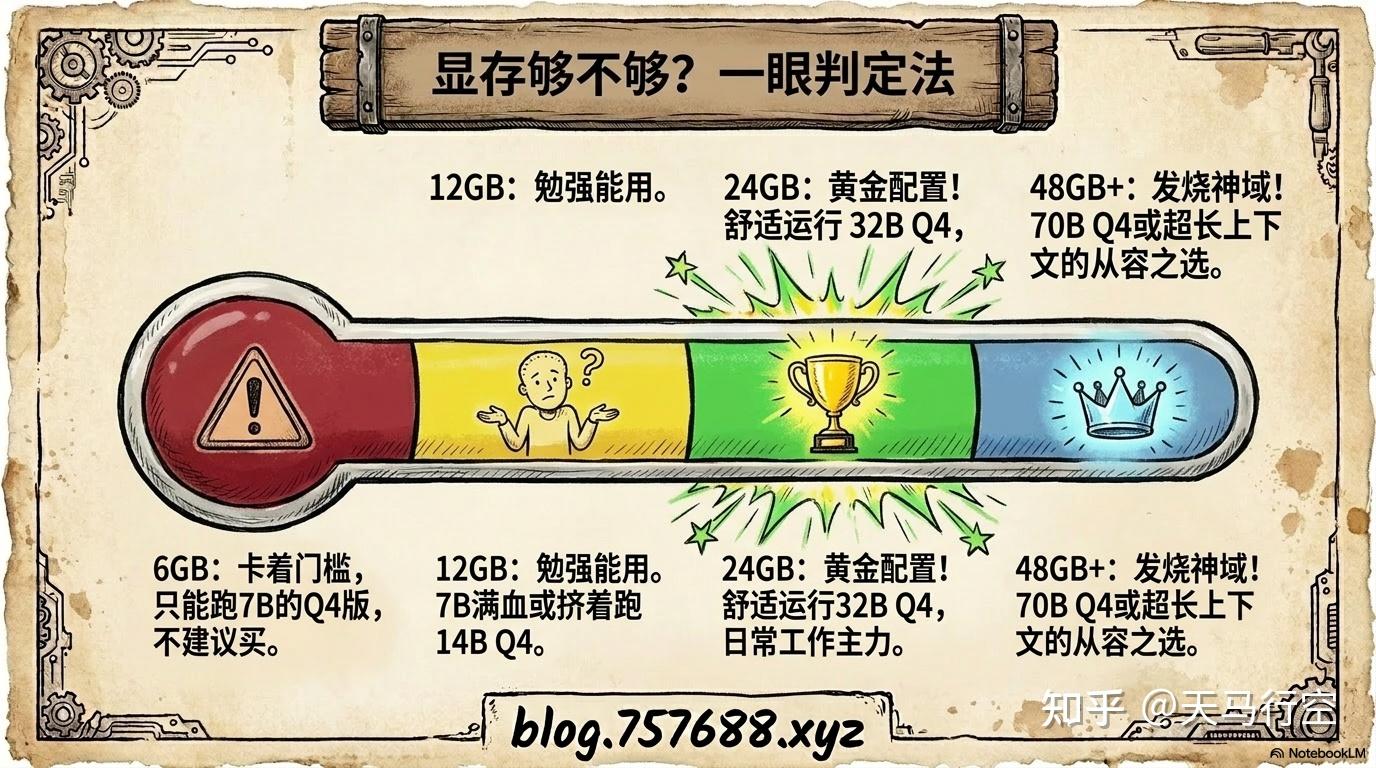
- 6GB 显存 → 只能跑 7B 模型 Q4 版,刚好卡着门槛,不建议
- 12GB 显存 → 7B 满血 Q8,或挤着跑 14B Q4,勉强能用
- 24GB 显存 → 舒适运行 32B Q4,日常使用的黄金配置
- 48GB 以上 → 可以跑 70B Q4,或在长上下文场景下更从容
三、量化精度避坑:Q2 真的会让模型”变蠢”
很多新手为了省显存,会选择 Q2 量化版本。这个选择大概率让你后悔。
我之前用单张 3060(12GB)跑 35B 模型的 Q2 版,实际体验是这样的:
让它分析一段 Rust 代码,它能找到错误位置,但在解释生命周期细节时,开始自创语法——用一本正经的口吻说着根本不存在的规则。
这种”智商缺失”在实际使用中非常致命,尤其是你需要它来帮你写代码、做逻辑分析的时候。
后来换成 Q4 版本,同样的问题,它不仅指出了错误,还主动提示我加上异常处理和日志埋点。完全是两个物种。
结论:Q4_K_M 是目前本地部署的黄金选择。 精度损失微乎其微,但对显存的要求比 FP16 少了 75%。如果你显存实在紧张,宁可选更小参数的 Q4 模型,也不要选同等参数的 Q2。
四、2026 年主流显卡横评:哪张卡最值?
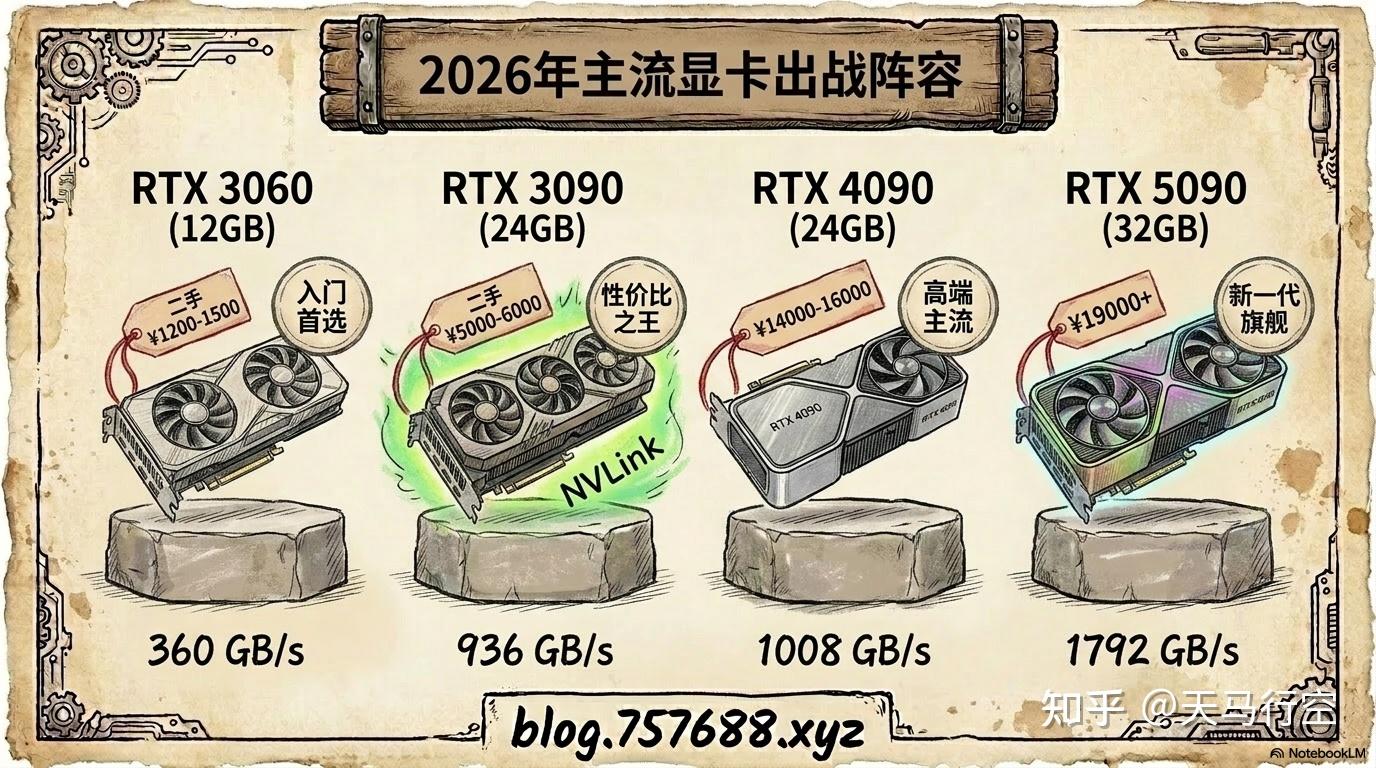
我把目前市面上的主要选择整理成一张表,对照着看:
| 显卡 | 显存 | 显存带宽 | 能跑的模型 | 参考价格 |
|---|---|---|---|---|
| RTX 3060 | 12GB | 360 GB/s | 7B满血、14B Q4勉强 | 二手约 1200-1500元 |
| RTX 3090 | 24GB | 936 GB/s | 32B Q4流畅 | 二手约 5000-6000元 |
| RTX 4090 | 24GB | 1008 GB/s | 32B Q4流畅 | 约 14000-16000元 |
| RTX 5090 | 32GB | 1792 GB/s | 32B Q4从容、70B Q4吃紧 | 约 19000元+ |
| Mac M系列 | 统一内存 | 800GB/s+ | 取决于内存配置 | 视配置而定 |
几个关键结论:
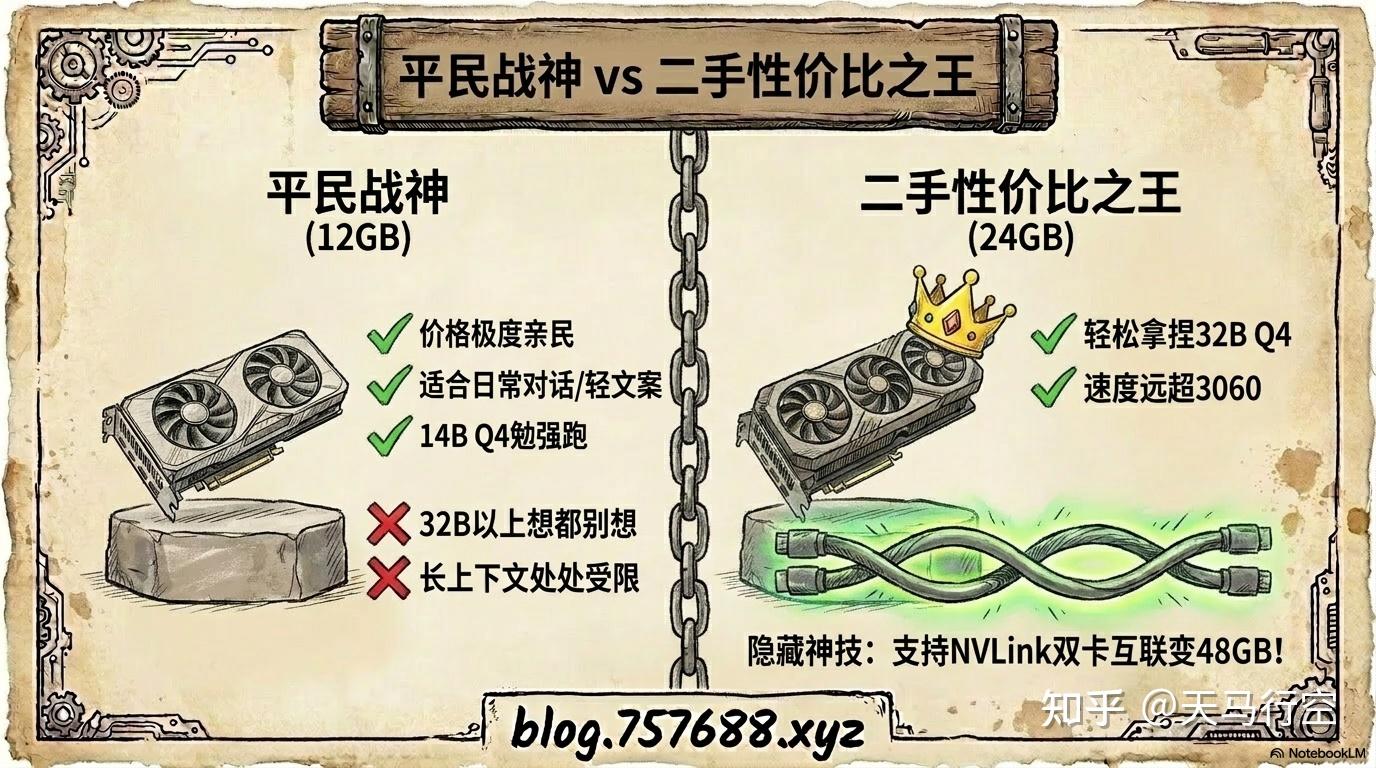
① RTX 3060 12GB:入门首选,但要接受局限性
12GB 显存刚好能跑 14B Q4,速度还可以接受。如果你主要用来做日常对话、写写文案,这个配置够用。价格便宜,闲鱼千多块能拿下。
但如果你想跑 32B 以上的模型,或者需要长上下文,12GB 会让你感到处处受限。
② RTX 3090 24GB:性价比之王
二手 3090 是目前最划算的 24GB 选择。能流畅跑 32B Q4,速度比 3060 快很多。而且 3090 支持 NVLink 双卡互联,两张 3090 可以合并成 48GB 显存池——这是 4090 没有的能力。

③ RTX 4090 24GB:高端主流选择
同样是 24GB,4090 比 3090 快约 30-40%,但价格贵了 2-3 倍。如果你的主要场景是推理速度(比如本地部署 API 给自己的工具调用),4090 的算力优势很明显。
④ RTX 5090 32GB:新一代旗舰,多出来的 8GB 很关键
从 24GB 到 32GB,对于 32B 以上的模型来说是质变。5090 还支持新架构的 FP4 量化,推理速度比 4090 快约 30-50%。预算充足首选,但价格感人。
五、双卡拼显存:低预算实现 24GB 的捷径
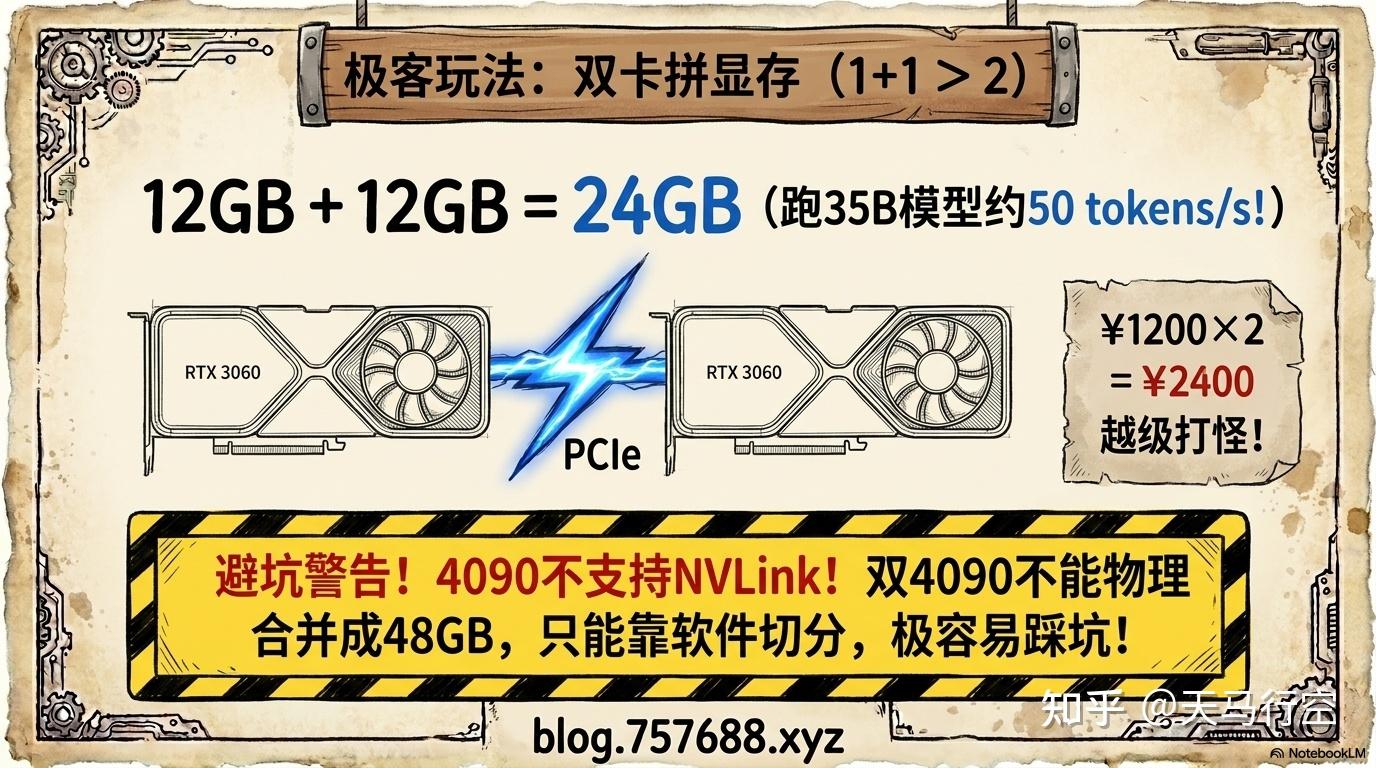
这是很多人忽略的玩法:买两张便宜的显卡,显存叠加,超越单张高端卡。
我之前的实测是这样的:用两张 3060(12GB×2=24GB),运行 Qwen3.6-35B 的 Q4 版本,实测生成速度约 50 tokens/s。
这意味着什么?一张二手 3060 约 1200 元,两张合计 2400 元,就能跑起单张 3090 才能搞定的 35B 模型,而且速度还不错。
不过有几个注意事项:
- 需要一块支持双 PCIe 插槽的主板(B550 以上)
- 电源功率建议 650W 以上
- 两张卡通过 llama.cpp 的
--tensor-split参数协同工作,走 PCIe 通信,速度会比单卡稍慢 - 4090 不支持 NVLink,双 4090 的显存不能合并成 48GB 池,只能靠软件切分——这是很多人不知道的大坑
六、Mac 统一内存:绕开显卡的另一条路
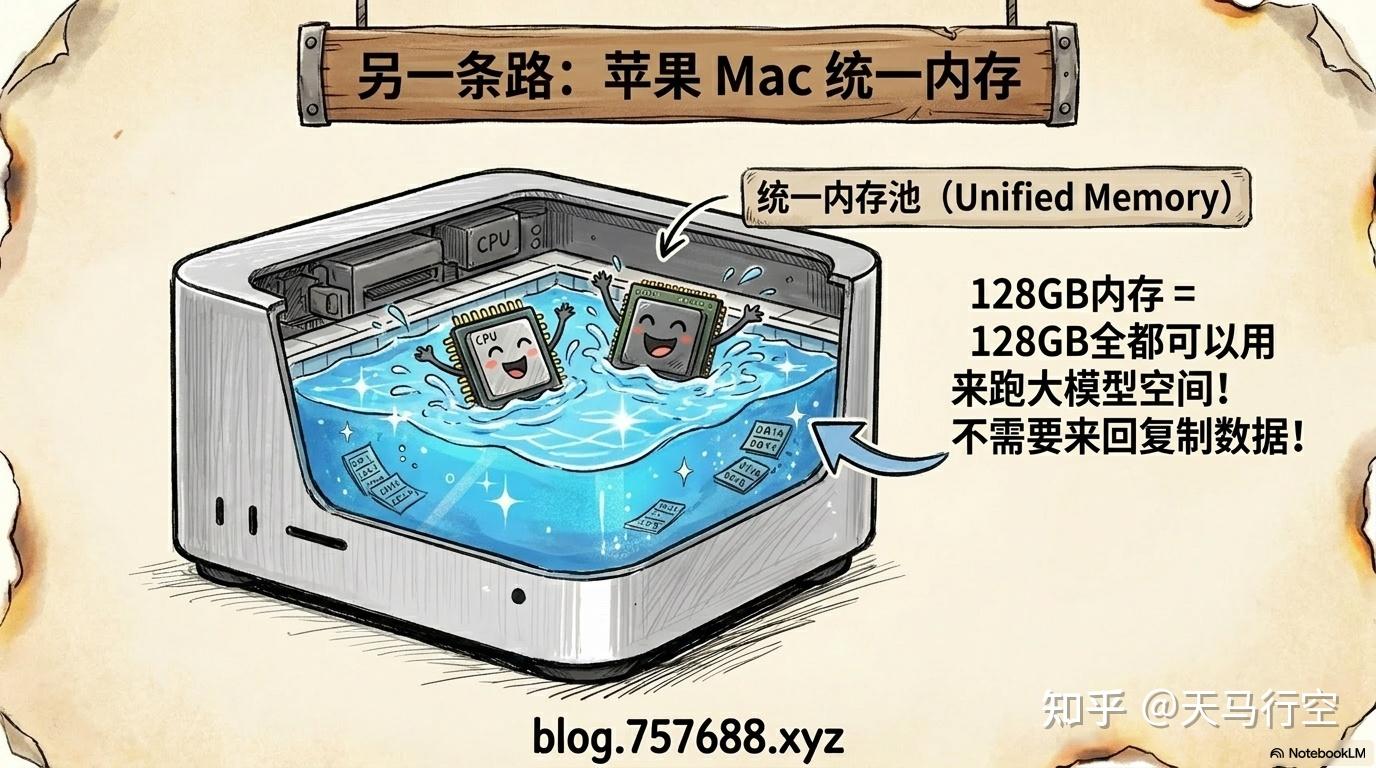
如果你不想玩显卡,苹果的 Mac(M系列芯片)是另一条路线,而且有独特优势。
Mac 的核心优势是统一内存架构:CPU 和 GPU 共享同一块内存,不需要在系统内存和显存之间来回复制数据。这意味着 128GB 的内存,就是 128GB 可以用于跑大模型的空间。
我做过实测对比,在同等 4 万元预算下(Mac Studio M2 Ultra 192GB vs 双 4090 Linux 机器):
跑 35B MoE 模型(Qwen3.6-35B Q4):
- Mac Studio:55-75 tokens/s
- 双 4090:80-105 tokens/s
- 结论:双 4090 快约 40%,但 Mac 已经是”极快”水平,日常使用感知差别不大
跑 70B 大模型(Llama-3.3-70B Q4):
- Mac Studio:10-16 tokens/s
- 双 4090:30-45 tokens/s
- 结论:双 4090 快 2-3 倍,70B 模型是 4090 的主场
长上下文场景(70B + 128K 超长对话):
- Mac Studio:✅ 从容运行(192GB 内存余量充足)
- 双 4090:❌ 显存不够,直接 OOM 崩溃
- 结论:这个场景 Mac 完胜,这是 NVIDIA 消费级显卡根本达不到的能力
Mac 的适合人群:
- 需要跑超大模型(70B+)或超长上下文(128K+)
- 在意安静和功耗(Mac 满载 250W vs 双 4090 约 1000W)
- 不想折腾 Linux 驱动和 CUDA 版本地狱
- 已经是苹果生态用户
Mac 的局限:
- 推理速度(tokens/s)明显低于同价位 NVIDIA 配置
- CUDA 生态不兼容:ComfyUI 生图、vLLM 部署、LoRA 微调等工具支持不完整
- 内存焊死,买多少就是多少,不能升级
七、选购决策树:按你的情况对号入座
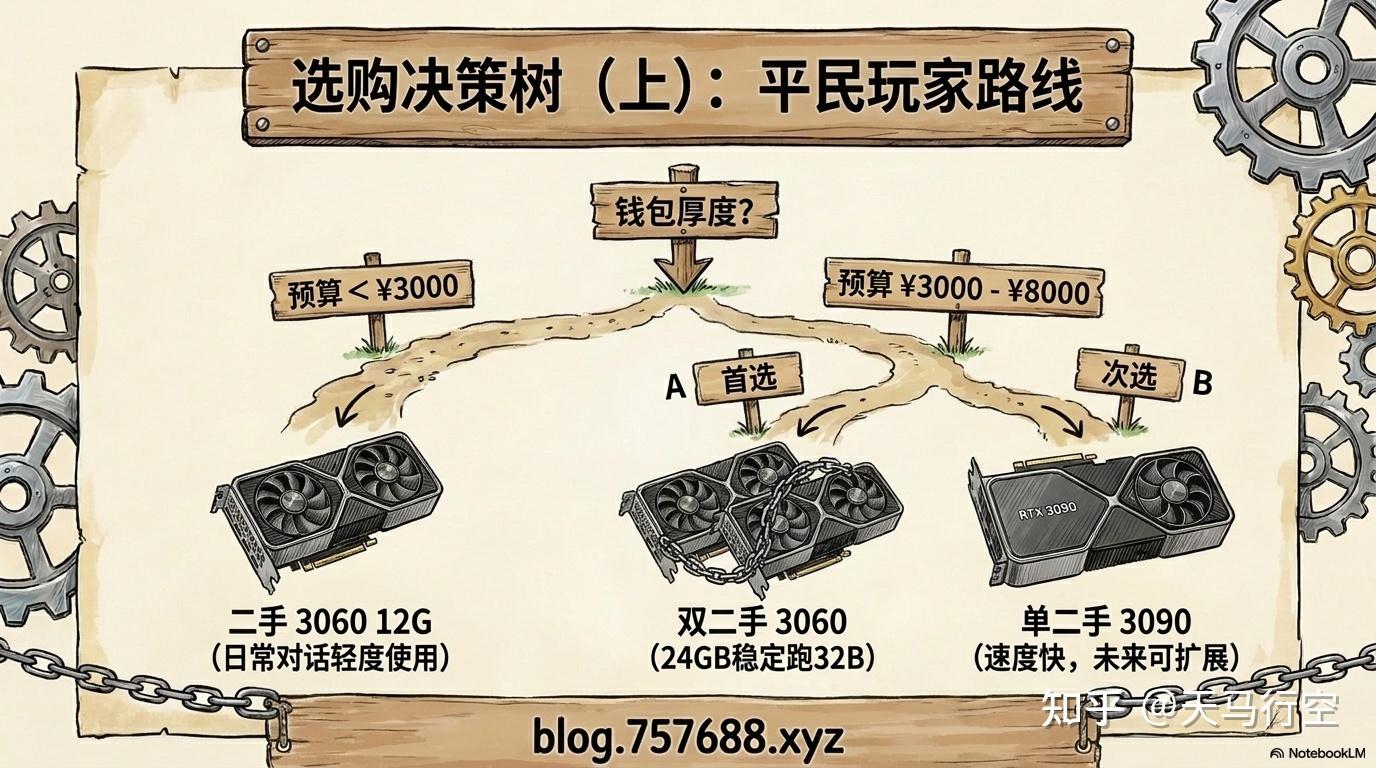
读到这里,总结成一个决策树,按你的实际情况选择:
① 我的预算不超过 3000 元 → 闲鱼二手 RTX 3060 12GB(约 1200 元) → 能跑 7B 满血 Q8、14B Q4 → 日常对话、轻量写作够用,别指望跑大模型
② 我的预算在 3000-8000 元 → 首选:二手双 RTX 3060(合计约 2400-3000 元),24GB 显存,跑 32B Q4 稳定 → 次选:二手 RTX 3090 单卡(约 5000-6000 元),24GB,速度更快,后续可双卡 NVLink 扩展
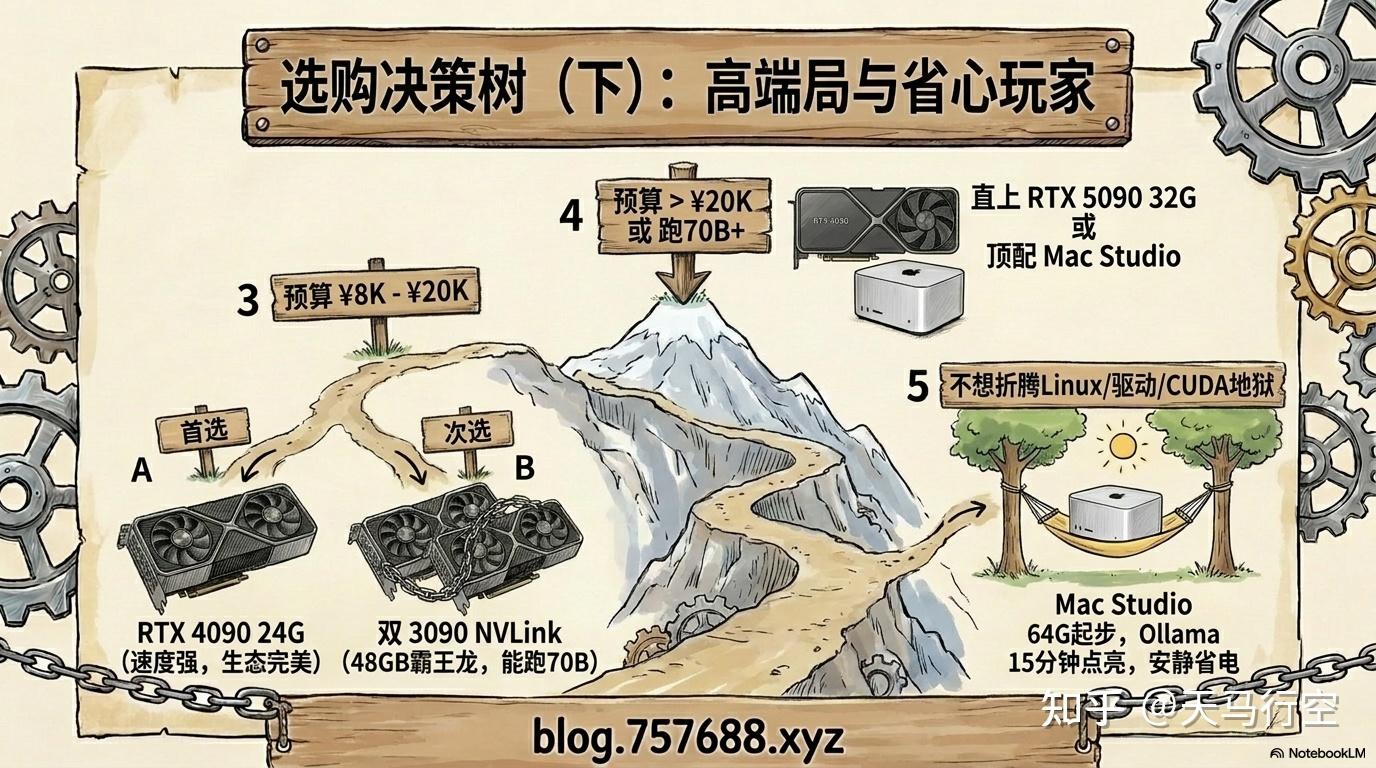
③ 我的预算在 8000-20000 元 → 首选:RTX 4090(约 14000-16000 元),24GB 显存,速度强,CUDA 生态完整 → 次选:双 3090 NVLink(约 12000 元),48GB 合并显存,可跑 70B Q4,性价比更高
④ 我的预算超过 20000 元,或者我需要跑 70B+ 超大模型 → 选 RTX 5090(约 19000 元+),32GB 显存,速度最强 → 或选高内存 Mac Studio(M3 Ultra 或 M4 Max/Ultra,128GB 内存),超长上下文、超大模型的唯一消费级选择
⑤ 我不想折腾 Windows 和显卡驱动 → 直接上 Mac Studio,选 64GB 起步,128GB 更从容 → 使用 Ollama + OpenWebUI,15 分钟跑起来,安静省电
最后说一句话

选显存,本质上是给自己的使用场景做规划。
如果你只是想试试本地 AI 好不好玩,7B 模型就够了,3060 二手卡起步,花小钱先体验。
如果你真的想把本地 AI 用到生产力工作里——写代码、分析文档、长文对话——至少要 24GB 显存,Q4 量化的 32B 模型,这才是真正”好用”而不是”能用”的门槛。
能上大显存,就别抠。别为了省几千块,把自己锁进两年的显存焦虑里。
你现在的配置是什么?打算跑哪些模型?
评论区告诉我,我帮你分析值不值得升级,不忽悠。
回复关键词”显存”,我整理了一份显存需求速查表和量化格式选择指南,直接拿走就能用。
作者:旅行者 | 玩客笔记 — 不站队,不吹票,只说真话。
#本地AI #显卡选购 #大模型 #显存 #AI硬件 #玩客笔记