针对ai,7900xtx和5070ti怎么选?
这不是一篇云评测。全部数据来自同一台 Ubuntu + ROCm 7.2.4 + 7900 XTX 24GB 主机的真实踩坑和实测。 如果你正在纠结”4000 块买不买 A 卡跑 AI”、”怎么搭环境”、”能跑什么模型”——这篇全给你讲清楚。
零、为什么会有这篇文章

过去一周,我在同一台 7900 XTX 主机上跑完了三件事:
- LLM 推理:llama.cpp + ROCm 跑 Qwen3.6-27B,测了四组参数矩阵,找到甜点配置
- ComfyUI 生图:Flux1.dev-fp8 vs Flux2 Klein 4B 横评,一个完整的 1024 文生图烟测
- LTX 视频生成:压力测试从 5 秒跑到 13 秒,触发了 swap thrashing,找到了最大稳定时长
这三条路线不是孤立的。它们共用同一张 24GB 显存、同一个 ROCm 环境、同一台 31GB 内存的机器。做这些测试的目标只有一个:2026 年,7900 XTX 能撑起一个本地 AI 内容生产环境吗?
答案是:能,而且性价比极高。 但每一条路线都有坑,我帮你全踩了一遍。
第一章:选购篇——二手 4000 还是全新 6000?

1.1 为什么是 7900 XTX?
跑本地 AI,显存是第一瓶颈。Qwen3.6-27B Q4_K_M 量化后约 16GB,加上上下文约 18.75GB。Flux2 Klein 4B 峰值约 16.9GB。24GB 显存才算真正够用。
目前消费级 24GB 显存的卡,屈指可数:
| 显卡 | 显存 | 二手价格(2026年) | 全新价格 |
|---|---|---|---|
| RX 7900 XTX | 24GB | ~4000 | ~6000 |
| RTX 4090 | 24GB | ~15000 | 已停产 |
| RTX 3090 | 24GB | ~6000 | 已停产 |
| RX 7900 XT | 20GB | ~3200 | ~4200 |
同显存容量,7900 XTX 二手只要 4090 的四分之一。
1.2 二手 4000 元值不值?
值。毫无悬念。
7900 XTX 不是矿卡重灾区(主流矿卡是 30 系),发热量大但正常使用的卡成色普遍不错。只要注意:
- 优先买公版或大牌非公(蓝宝石 Nitro+、华硕 TUF)
- 要求卖家提供 GPUBURN 烤机 10 分钟视频
- 问清购买渠道和使用时长
- 闲鱼防骗:视频验货、走平台
1.3 全新 6000 元值不值?
值,但要确认你的场景。
值得全新的情况:
- 长期主力机器,需要质保(一般 3 年)
- 工作室/创作工作室,稳定性优先
- 预算有弹性
1.4 横向对比总表
| 显卡 | 显存 | LLM 推理 | ComfyUI 生图 | 视频生成 | 性价比 |
|---|---|---|---|---|---|
| 7900 XTX 二手 | 24GB | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 🏆 |
| 7900 XTX 全新 | 24GB | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ✅ |
| RTX 3090 二手 | 24GB | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⚠️ 矿卡风险 |
| RTX 4090 | 24GB | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 💰 贵3倍 |
1.5 一句话选购建议
二手 4000 元是目前 24GB 显存段性价比最高的选择,没有之一。
第二章:环境搭建篇——Ubuntu + ROCm 7.2 从零开始
2.1 硬件配置(本文所有测试均基于此)
| 组件 | 型号 |
|---|---|
| CPU | AMD Ryzen 7 3700X |
| 内存 | 31GB(~32GB,实测可用不足整 32) |
| GPU | RX 7900 XTX 24GB(gfx1100) |
| ROCm | 7.2.4 |
| llama.cpp | b1-55ac090(ROCm 后端) |
| ComfyUI | 0.23.0 |
| PyTorch | 2.11.0+rocm7.2 |
2.2 安装 ROCm
# 安装 ROCm 7.2.4
# 注意:必须把用户加入 render 和 video 组!
sudo usermod -aG render $USER
sudo usermod -aG video $USER
# 然后重新登录(logout → login),不是重启
# 验证
rocminfo
# 输出:Name: gfx1100 / Marketing Name: Radeon RX 7900 XTX
rocm-smi
# ROCm version: 7.2.4⚠️ 最高频卡点:装完 ROCm 忘记加用户组,所有工具报权限错误。论坛里一半的求助帖是这个问题。
2.3 安装 llma.cpp(ROCm 后端)
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -DGGML_HIP=ON -DCMAKE_BUILD_TYPE=Release ..
make -j$(nproc)关键二进制:
build-rocm/bin/llama-cli(命令行推理)build-rocm/bin/llama-server(API 服务)build-rocm/bin/llama-bench(性能测试)
2.4 安装 ComfyUI
git clone https://github.com/comfyanonymous/ComfyUI
cd ComfyUI
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt推荐启动参数(实测稳定):
python main.py \
--listen 0.0.0.0 \
--port 8188 \
--disable-async-offload \
--force-upcast-attention \
--preview-method none⚠️ 不要加 –lowvram,否则 CLIP 会降级到 CPU,速度雪崩。 ⚠️ 显存溢出可能导致 Ubuntu 桌面崩溃(GDM 被杀),建议在 SSH 或 tty 模式下跑。
2.5 模型下载
HuggingFace 直连常常超时,推荐使用镜像站:
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download froggeric/Qwen3.6-27B-MTP-GGUF --local-dir /home/xin/models/镜像站速度实测稳定在 43-44 MB/s。
第三章:LLM 推理篇——Qwen3.6-27B + llama.cpp + ROCm 实战

3.1 模型选择
最终选择的模型:
| 属性 | 值 |
|---|---|
| 模型 | Qwen3.6-27B-Q4_K_M-mtp.gguf |
| 大小 | ~16GB |
| 来源 | froggeric/Qwen3.6-27B-MTP-GGUF |
| SHA256 | c0754e3014b4db6668425b33d7b64e92... |
选择 Q4_K_M 的原因:24GB 显存下 Q4_K_M 完全进显存(~18.75GB),还剩约 5.8GB。更高精度会超显存,更低精度影响质量。
3.2 四组参数矩阵测试
测试了四组配置,覆盖短对话和长文档场景:
| 配置 | 短对话速度 | 长 prompt 生成 | 显存占用 | 长 prompt 是否通过 |
|---|---|---|---|---|
| 32K / draft=2 | 43.91 t/s | — | 18.1 GB | ❌ 报错 |
| 64K / draft=2 🏆 | 44.00 t/s | 44.36 t/s | 18.75 GB | ✅ |
| 64K / draft=3 | 38.53 t/s | 54.49 t/s | 18.9 GB | ✅ |
| 64K / draft=3 + batch | 38.32 t/s | 54.08 t/s | 18.9 GB | ✅ |
核心发现:
1. 32K 不够用。 一篇 38037 token 的长文档直接报错。日常多轮对话、Agent 调用很容易超。建议直接上 64K。
2. 64K + draft=2 是最佳默认配置。 短对话保持 44 t/s,长文档也能正常处理,显存还剩 ~5.8GB。
3. draft=3 适合特定场景。 长文档生成飙到 54.5 t/s,但短对话降到 38.5 t/s。适合长文档分析、结构化输出、Agent 工具调用。
4. 调 batch size 没用。 -b 2048 -ub 512 在当前配置下没有收益。
3.3 基准测试(不开 MTP)
llama-bench -m Qwen3.6-27B-Q4_K_M-mtp.gguf -ngl 99 -p 512 -n 128 -ctk q4_0 -ctv q4_0 -fa on -r 3结果:
- Prefill: 936.90 ± 37.33 t/s(极快)
- Decode: 28.58 ± 0.04 t/s(偏慢)
开启 MTP(draft=2)后 decode 提升到约 38-44 t/s,提速约 36-54%。
3.4 推荐启动配置(API 服务)
llama-server \
-m /home/xin/models/Qwen3.6-27B-Q4_K_M-mtp.gguf \
--host 0.0.0.0 \
--port 8080 \
-ngl 99 \
-c 65536 \
-np 1 \
-ctk q4_0 \
-ctv q4_0 \
-fa on \
--spec-type draft-mtp \
--spec-draft-n-max 2 \
--reasoning off \
-a qwen36-27b-mtp启动后通过 http://192.168.0.110:8080/v1 提供 OpenAI 兼容 API,Chatbox、NextChat、LobeChat 均可连接。
⚠️ --reasoning off 一定要加,否则 Qwen3.6 在某些 Agent 请求中会进入长时间 thinking 模式,卡住无响应。3.5 显存状态
64K / draft=2 运行时:
TOTAL_VRAM: 24560 MB
USED_VRAM: 18748 MB (~76%)
FREE_VRAM: 5812 MB (~24%)模型 + 上下文占约 76% 显存。跑单个模型从容,但不要想同时挂两个大模型。
3.6 7900XTX LLM 推理能力总结
| 维度 | 评价 |
|---|---|
| ✅ 速度 | 短对话 44 t/s,长文档 54 t/s,体感流畅 |
| ✅ 显存 | 24GB 跑 27B Q4_K_M 还剩 5.8GB,从容 |
| ⚠️ 生态 | ROCm + llama.cpp 组合可用,配置比 CUDA 麻烦 |
| ❌ 上限 | 70B 模型需要分层卸载到 CPU,速度会降 |
第四章:生图篇——ComfyUI + FLUX2 Klein 4B 实战

4.1 为什么推荐 FLUX2 Klein 4B?
在同一台机器上做了 FLUX1.dev-fp8 和 FLUX2 Klein 4B 的 1024×1024 文生图横评,结论非常清晰:
| 方案 | 热启动出图速度 | 峰值显存 | 画面表现 |
|---|---|---|---|
| FLUX1.dev-fp8 | ~67s | ~21.0GB | 半插画风,细节偏玩具 |
| FLUX2 Klein 4B 🏆 | ~33s | ~16.9GB | 摄影质感,机械/场景更完整 |
| FLUX2 Klein 9B kv-fp8 | ~34s | ~20.2GB | 细节更丰富,但速度慢一倍 |
FLUX2 Klein 4B 比 FLUX1.dev-fp8 速度快一倍,显存还少 4GB。 在 7900 XTX 上毫无疑问是最值得作为主力生图方案的选择。
4.2 模型文件
Flux2 Klein 4B 使用拆分模型(不是单 checkpoint):
| 文件 | 大小 | 路径 |
|---|---|---|
| flux-2-klein-4b.safetensors(diffusion model) | 7.3GB | models/diffusion_models/ |
| qwen_3_4b.safetensors(text encoder) | 7.5GB | models/text_encoders/ |
| flux2-vae.safetensors(VAE) | 321MB | models/vae/ |
4.3 工作流(与 FLUX1 不同,不能照搬)
Flux2 Klein 4B 走拆分模型路线,不能用 CheckpointLoaderSimple:
UNETLoader(diffusion_model)
CLIPLoader(type="flux2")
VAELoader
→ CLIPTextEncode × 2(不要用 CLIPTextEncodeFlux!)
→ EmptyFlux2LatentImage
→ Flux2Scheduler(不要传 model 参数!)
→ KSamplerSelect → RandomNoise → BasicGuider
→ SamplerCustomAdvanced → VAEDecode → SaveImage两个关键踩坑:
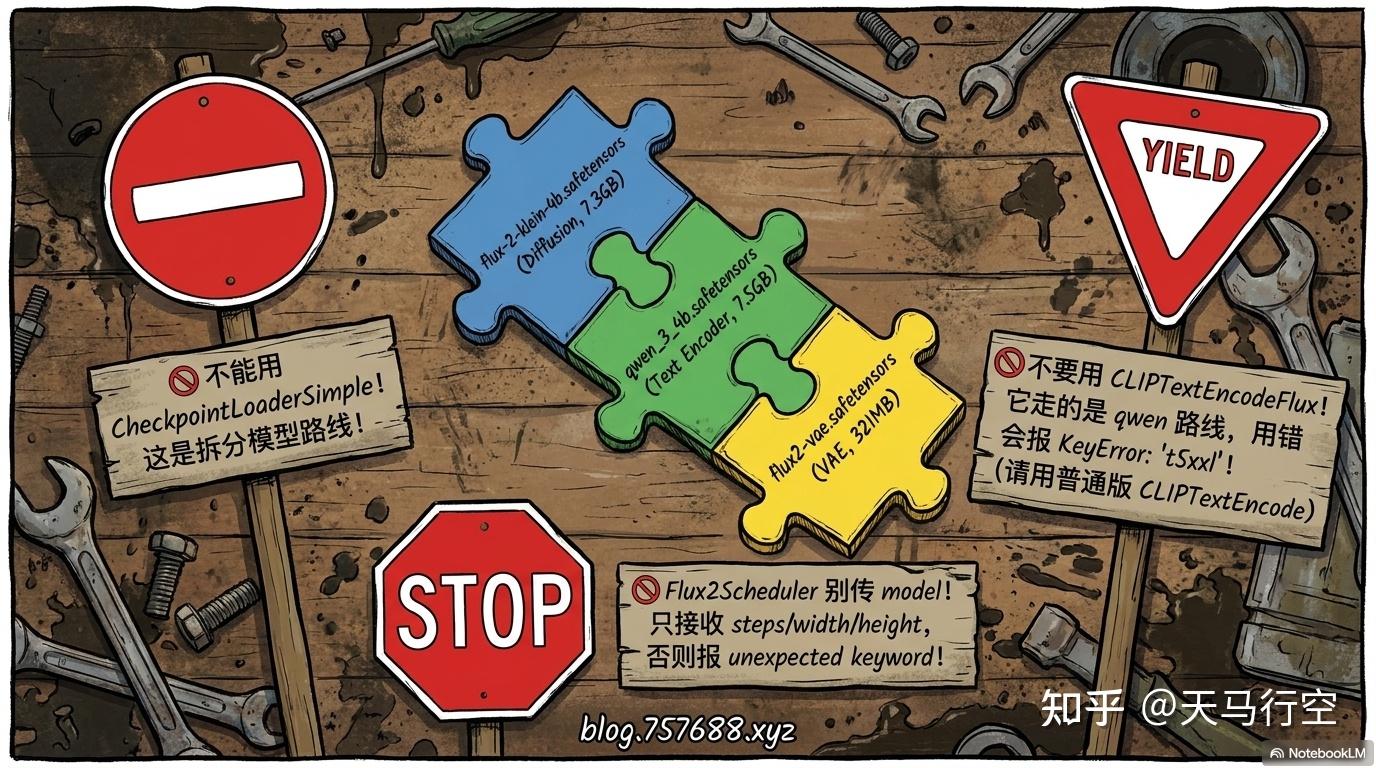
- 不要用
CLIPTextEncodeFlux。Flux2 Klein 4B 用的是 qwen_3_4b 文本编码器,不是 t5xxl 路线。用 CLIPTextEncodeFlux 会报KeyError: 't5xxl'。 - Flux2Scheduler 不要传 model。当前版本 Flux2Scheduler 只接收
steps/width/height,传 model 会报unexpected keyword argument 'model'。
4.4 速度详解
| 场景 | 出图时间 | 峰值显存 | 备注 |
|---|---|---|---|
| 冷启动(首次加载模型) | ~33s | 16.67GB | 重启 ComfyUI 后第一次 |
| 热启动(换 seed 继续跑) | ~33-34s | 16.9GB | 日常使用的保守口径 |
| 缓存命中(同 prompt 重复跑) | ~16-17s | 16.94GB | 依赖缓存,不宜宣传 |
| FLUX2 9B kv-fp8 热启动 | ~34s | 18.9-20.2GB | 细节更好,但速度慢 |
日常出图按 33-34 秒 计算,1024×1024 的 20 步 euler 采样。同 prompt 换 seed 跑几轮后可以进入缓存状态,但不应作为常规速度认知。
4.5 FLUX1.dev-fp8 对比参考
作为基线保留,但不推荐作为主力:
| 对比项 | FLUX1.dev-fp8 | FLUX2 Klein 4B |
|---|---|---|
| 冷启动 | ~95s (97.76s API) | ~33s |
| 热启动 | ~67s (66.84s API) | ~33s |
| 峰值显存 | ~21GB | ~16.9GB |
| 画面 | 半插画风,偏玩具感 | 摄影质感,更接近成片 |
| 工作流 | 单 checkpoint,简单 | 拆分模型,需注意节点选择 |
4.6 下一步横评建议
当前只测了红色机器人 prompt,建议补充三组提示词进一步验证:
人物/写真类:面部、手部、肤色稳定性 产品图类:边缘、材质、商业可用性 室内场景类:复杂光线、多物体关系
4.7 VRAM 占用汇总(所有生图工作流)
| 工作流 | 模型总大小 | 峰值显存 | 7900XTX 余量 |
|---|---|---|---|
| FLUX.1 dev fp8 1024 | 17GB | ~21GB | ~3GB ⚠️ |
| FLUX2 Klein 4B 1024 | 7.3G+7.5G+321M | ~16.9GB | ~7.1GB ✅ |
| FLUX2 Klein 9B kv-fp8 1024 | 9.2G+8.1G+321M | ~20.2GB | ~3.8GB ⚠️ |
第五章:视频生成篇——LTX-2.3 压力测试与内存调试

5.1 为什么选 LTX 不选 Wan?
社区共识(来自 http://lcz.me 抡锤者论坛多位用户):新手不要碰 Wan,LTX 更快、工作流更多、更容易上手。 Wan 速度极慢,7900 XTX 上体验不佳。
5.2 模型配置
| 文件 | 大小 | 备注 |
|---|---|---|
| ltx-2.3-22b-distilled-1.1-Q3_K_M.gguf | 9.9GB | U-Net |
| gemma-3-12b-it-Q4_K_M.gguf | 6.8GB | CLIP |
| ltx-2.3_text_projection_bf16.safetensors | 75MB | 文本投影 |
| LTX23_video_vae_bf16.safetensors | 1.4GB | VAE |
5.3 压力测试方法
编写了 stress_test.py,对 LTX-2.3 做逐级帧数递增测试(544×960,8 steps,Euler):
121f (5s) → 169f (7s) → 217f (9s) → 241f (10s) → 289f (12s) → 313f (13s)5.4 测试结果
默认模式下:
| 时长 | 帧数 | 结果 | 总耗时 | 备注 |
|---|---|---|---|---|
| 5s | 121f | ✅ | 47s | 正常速度,4.3s/it |
| 7s | 169f | ✅ | 45s | 正常速度,4.3s/it |
| 8s | 192f | ✅ | 160s | 开始内存碎片化 |
| 9s | 217f | ✅ | 91s | 速度开始下降 |
| 10s | 241f | ⚠️ | 91s | 明显变慢 |
| 9s 第二轮 | 217f | 🔴 | 677s | swap thrashing! |
| 10s 第二轮 | 241f | 🔴 | 800s | 严重 thrashing |
–lowvram 模式下:
| 时长 | 帧数 | 总耗时 | 备注 |
|---|---|---|---|
| 7s | 169f | 268s | 含模型加载 |
| 8s | 192f | 105s | 稳定 |
| 9s | 217f | 140s | 不会累积,但总体慢 |
5.5 根因分析
瓶颈不在显存,在系统内存。
显存: 16.6GB / 25.7GB(64%) ✅ 余量充足
内存: 31GB / 31GB(100%) ❌ 全部吃满LTX-2.3 的 VAE 解码阶段将 latent → pixel 转换时,视频帧数越多,临时内存需求越大。31GB 系统内存成为瓶颈:
第1轮: 内存 15GB → 生成完 20GB(+5GB 碎片)
第2轮: 内存 20GB → 生成完 25GB(+5GB 碎片)
第3轮: 内存 25GB → 生成完 31GB(OOM / swap)5.6 稳定可用范围
LTX-2.3 @ 544×960,7900XTX + 31GB 系统内存:
| 时长 | 帧数 | 评估 |
|---|---|---|
| ≤5s | ≤121f | 🟢 完美,45s 出片 |
| 7s | 169f | 🟢 可用,速度正常 |
| 8s | 192f | 🟡 临界,单次可,连续跑需注意 |
| 9s+ | 217f+ | 🔴 触发 swap,速度暴跌 |
5.7 解决方案(已验证)
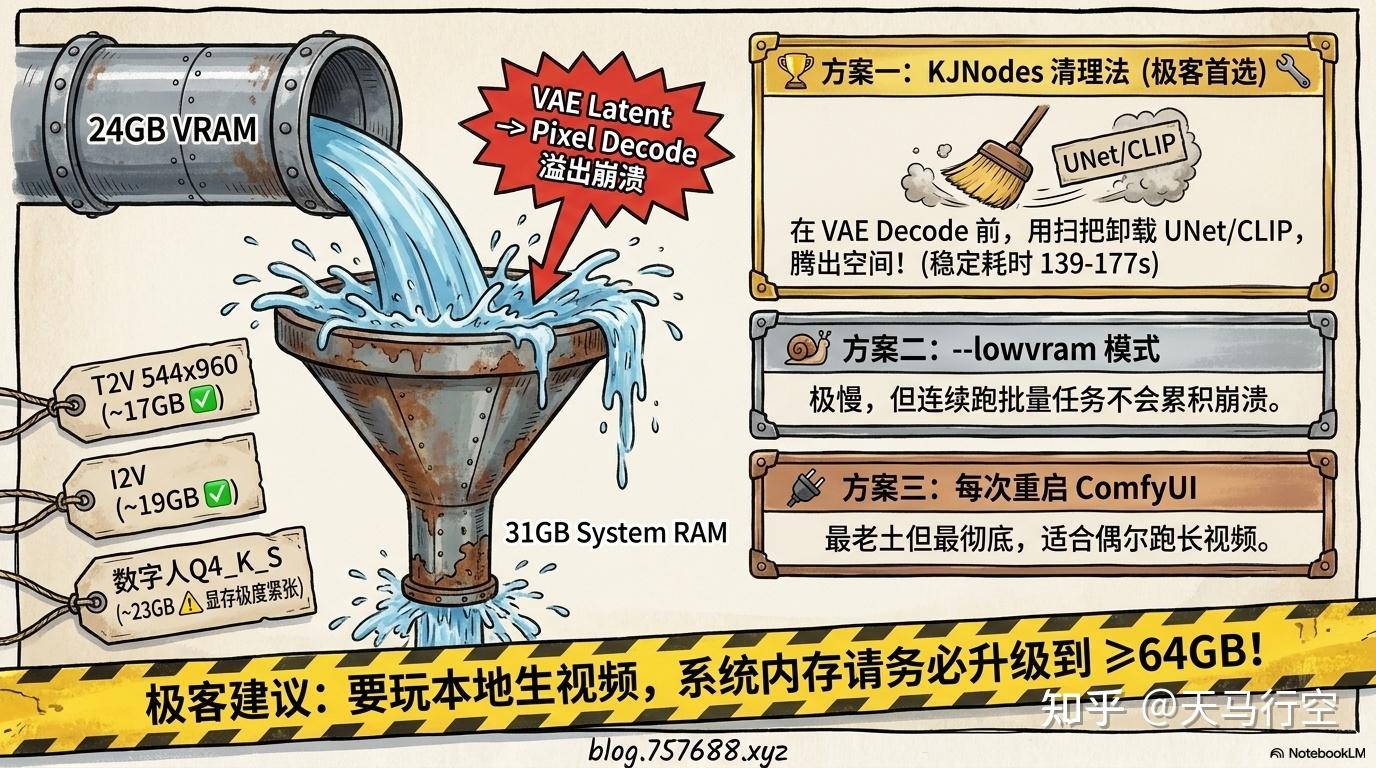
方案一(推荐):安装 KJNodes,在 VAE Decode 前插入清理节点
来自 http://lcz.me 论坛 @Xiaote 的实战方案:
LTXV分离音视频潜空间.video_lat
→ UnloadAllModels.value ← 先卸载前面的模型
→ VAE解码(分块).Latent
VAE模型
→ VAE解码(分块).vae关键:不是每轮生成后清,而是在 VAE Decode 前先卸掉 UNet/CLIP,把显存/内存让给 VAE 解码阶段。
安装方法:
- 下载
comfyui-easy-use(提供清理显存节点) - 下载
comfyui-unload-model(提供 UnloadAllModels) - 确保 KJNodes 是最新版(
ltxv_nodes.py第 653 行有已知 bug)
方案二:–lowvram 模式 稳定但慢,适合连续批量任务,不适合追求速度的单次任务。
方案三:每次生成后重启 ComfyUI 最彻底,但最慢。适合偶尔跑长视频。
5.8 各方案对比
| 方案 | 速度 | 防累积 | 适用场景 |
|---|---|---|---|
| 默认模式 | 🏆 最快 | ❌ 会累积 | 单次短视频 |
| –lowvram | 🐌 最慢 | ✅ 稳定 | 连续批量任务 |
| VRAM 清理节点 🏆 | 🟡 139-177s | ✅ 稳定 | 推荐,装 KJNodes 即可 |
| 每次重启 ComfyUI | ❌ 慢 | 🏆 最彻底 | 偶尔跑长视频 |
5.9 LTX 其余工作流的显存占用
| 工作流 | 峰值显存 | 7900XTX 余量 | 备注 |
|---|---|---|---|
| LTX T2V Q3_K_M 544×960 | ~17GB | ~7GB ✅ | 推荐新手先测 |
| LTX I2V Q3_K_M(+LoRA) | ~19GB | ~5GB ✅ | 需要相机控制 LoRA |
| LTX 数字人 Q4_K_S | ~23GB | ~1GB ⚠️ | 非常紧,建议先用 Q3_K_M 测试 |
5.10 提速建议
- 降低分辨率:960×544 比 896×1280 快数倍,后期放大效果一样好
- CLIP 放 CPU:如果显存紧张(如数字人),CLIP 放 device=cpu 可省 ~6.8GB
- 关闭桌面环境:SSH/tty 模式跑,避免显存溢出导致桌面崩溃
- 系统内存 ≥64GB:当前 31GB 是短板,升级到 64GB 后表现会大幅改善
第六章:7900XTX 本地 AI 能力总表

6.1 工作流全量 VRAM 参考
| 工作流 | 峰值显存 | 系统内存需求 | 速度基准 | 总体评估 |
|---|---|---|---|---|
| LLM 推理(Qwen3.6-27B, 64K) | 18.75GB | 32GB+ | 44 t/s | 🟢 完全可用 |
| FLUX2 Klein 4B 1024 文生图 | 16.9GB | 16GB+ | 33s/张 | 🟢 完全可用 |
| FLUX1.dev-fp8 1024 文生图 | 21GB | 16GB+ | 67s/张 | 🟡 偏慢 |
| FLUX Klein 9B 1024 文生图 | 20.2GB | 16GB+ | 34s/张 | 🟡 余量偏紧 |
| LTX T2V 544×960, ≤7s | ~17GB | 32GB+ | 45s | 🟢 完全可用 |
| LTX I2V 544×960, ≤7s | ~19GB | 32GB+ | ~2min | 🟡 需清理节点 |
| LTX 数字人 Q4_K_S | ~23GB | 64GB+ | ~20-40min | 🔴 非常紧张 |
6.2 性能总结
| 维度 | 评价 |
|---|---|
| ✅ 价格 | 二手 4000,全新 6000,24GB 显存性价比无敌 |
| ✅ LLM 推理 | Qwen3.6-27B 完全进显存,44 t/s 流畅可用 |
| ✅ 本地生图 | FLUX2 Klein 4B 33s 出图,显存余量充足 |
| ✅ 视频生成 | LTX 2.3 7s 短视频稳定可用 |
| ⚠️ 生态 | ROCm 已成熟,但配置比 CUDA 麻烦,文档更少 |
| ⚠️ 速度 | 比同级 N 卡慢 20-30%,但显存一样大 |
| ❌ 上限 | 70B 大模型需要 CPU offload,ICLoRA 等高级生图不支持 |
6.3 系统瓶颈分析
这个测试过程中最大的意外是:最大的瓶颈不是显存(24GB),而是系统内存(31GB)。
- LLM 推理:64K 上下文用了 18.75GB 显存,系统内存无压力 ✅
- ComfyUI 生图:峰值 16.9GB,系统内存无压力 ✅
- LTX 视频生成:VAE 解码阶段系统内存爆满,31GB 成为瓶颈 ❌
如果你要玩生视频,建议系统内存 ≥64GB。
第七章:踩坑清单(帮你省时间)
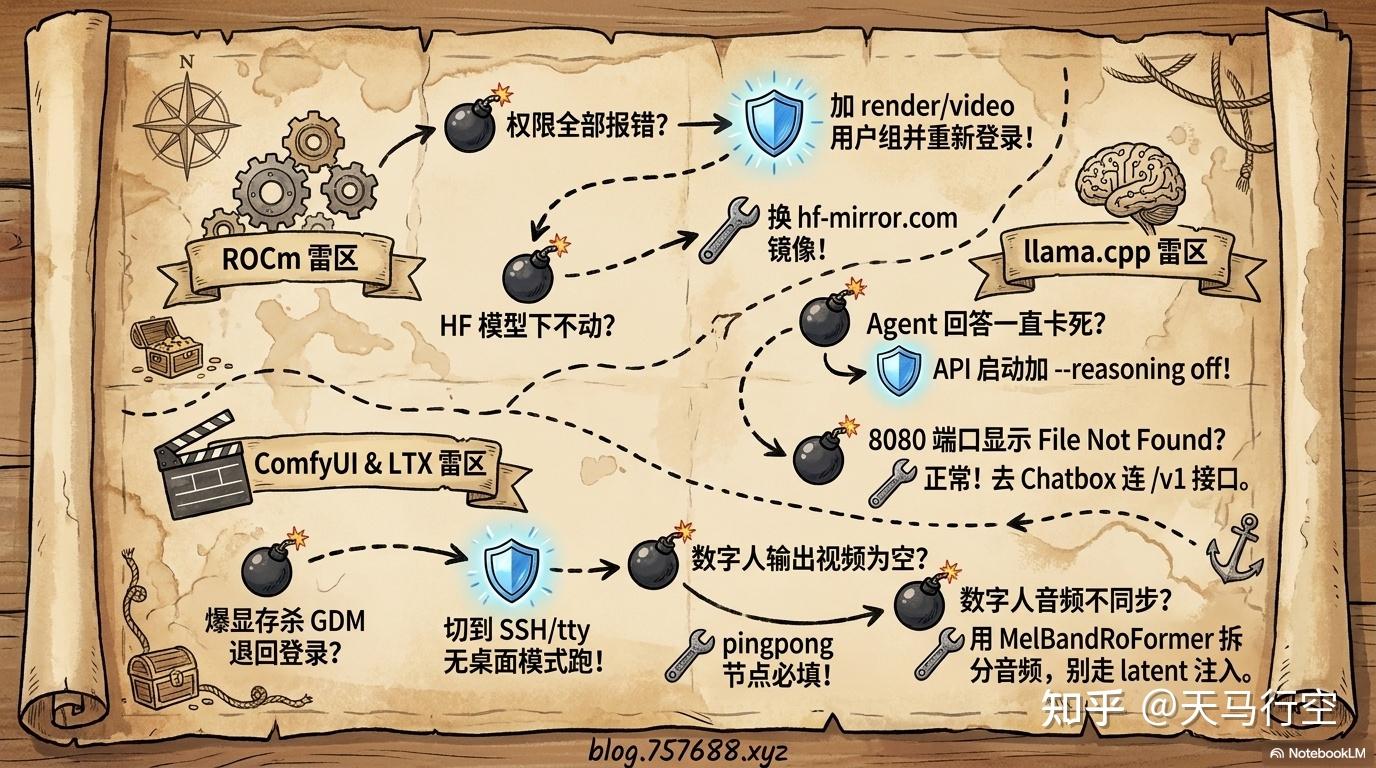
ROCm 相关
| 问题 | 现象 | 解决 |
|---|---|---|
| 权限错误 | rocminfo/llama-server 全部报错 | 加 render/video 组 + 重新登录 |
| 编译无 ROCm 后端 | llama.cpp 不调用 GPU | cmake 加 -DGGML_HIP=ON |
| HuggingFace 超时 | 模型下不了 | 用 http://hf-mirror.com 镜像站 |
| ROCm 版本不兼容 | gfx1100 识别异常 | 用 ROCm 7.2+(RDNA3 完整支持) |
llma.cpp 相关
| 问题 | 现象 | 解决 |
|---|---|---|
| 模型卡住无响应 | 发送请求后长时间没输出 | 加 --reasoning off |
| 32K 上下文不够用 | 长文档报错 | 直接用 -c 65536 |
| 浏览器显示 File Not Found | 打开 http://host:8080 没内容 | 正常!用 Chatbox 连 /v1 接口 |
ComfyUI 相关
| 问题 | 现象 | 解决 |
|---|---|---|
| CLIP 降级到 CPU | 出图极慢 | 不要加 --lowvram |
| CLIPTextEncodeFlux 报错 | KeyError: 't5xxl' | 用 CLIPTextEncode(普通版) |
| Flux2Scheduler 报错 | unexpected keyword argument 'model' | 只传 steps/width/height |
| 桌面崩溃回到登录页 | 显存溢出杀 GDM | SSH/tty 模式跑 |
| 批量跑几次后卡死 | 系统内存碎片化累积 | 每轮间清理节点或重启 |
LTX 视频相关
| 问题 | 现象 | 解决 |
|---|---|---|
| 长视频(9s+)卡死 | CPU 100% IO wait,疯狂 swap | 控制在 7-8s 以内 |
| 连续跑越来越慢 | 内存碎片化累积 | 装 KJNodes,VAE Decode 前清理 |
| 数字人 VAE 解码 35 分钟 | 分块 VAE 解码极慢 | 降低分辨率到 960×544 |
| VHS_VideoCombine 静默失败 | 数字人输出为空 | pingpong 是必填参数 |
| 音频不与画面同步 | 数字人对口型失败 | 用 MelBandRoFormer 拆分音频,不走 latent 注入 |
第八章:谁该买 7900 XTX?最终建议
✅ 适合买的人
- 预算有限,想要 24GB 大显存跑本地 AI
- 能接受 Linux 系统(其实 Ubuntu 没那么可怕)
- 主要做推理(LLM 对话、生图、短视频生成),不做大规模训练
- 对数据隐私有要求,不想把数据送上云端
- 愿意花半天时间搭环境(一劳永逸)
❌ 不适合的人
- 只想 Windows 下开箱即用 → 买 N 卡
- 需要跑 PyTorch 训练/微调 → ROCm 训练生态不如 CUDA
- 零耐心折腾驱动 → 直接用云端 API,省心省力
- 需要同时跑两个大模型 → 24GB 显存不够分,考虑双卡
一句话总结

7900 XTX 二手 4000 元,跑 LLM 推理 44 t/s 流畅、ComfyUI 生图 33s 出片、LTX 视频 7s 稳定可用——这是 2026 年 24GB 显存段性价比最高的本地 AI 方案,没有之一。
你不是在为生态买单,你是在为显存容量买单。而省下的那一万块,足够再买两张 7900 XTX。