想配一个可以跑大模型的主机,怎么搞比较好,经济方案?
作为配了好几个大模型服务器的过来人,先说结论:2026年5月这个时间点,配AI主机最划算的卡是RTX 5090。它刚好卡在一个很微妙的位置。32GB显存能跑动绝大多数开源模型,而价格还没到专业卡的零头。
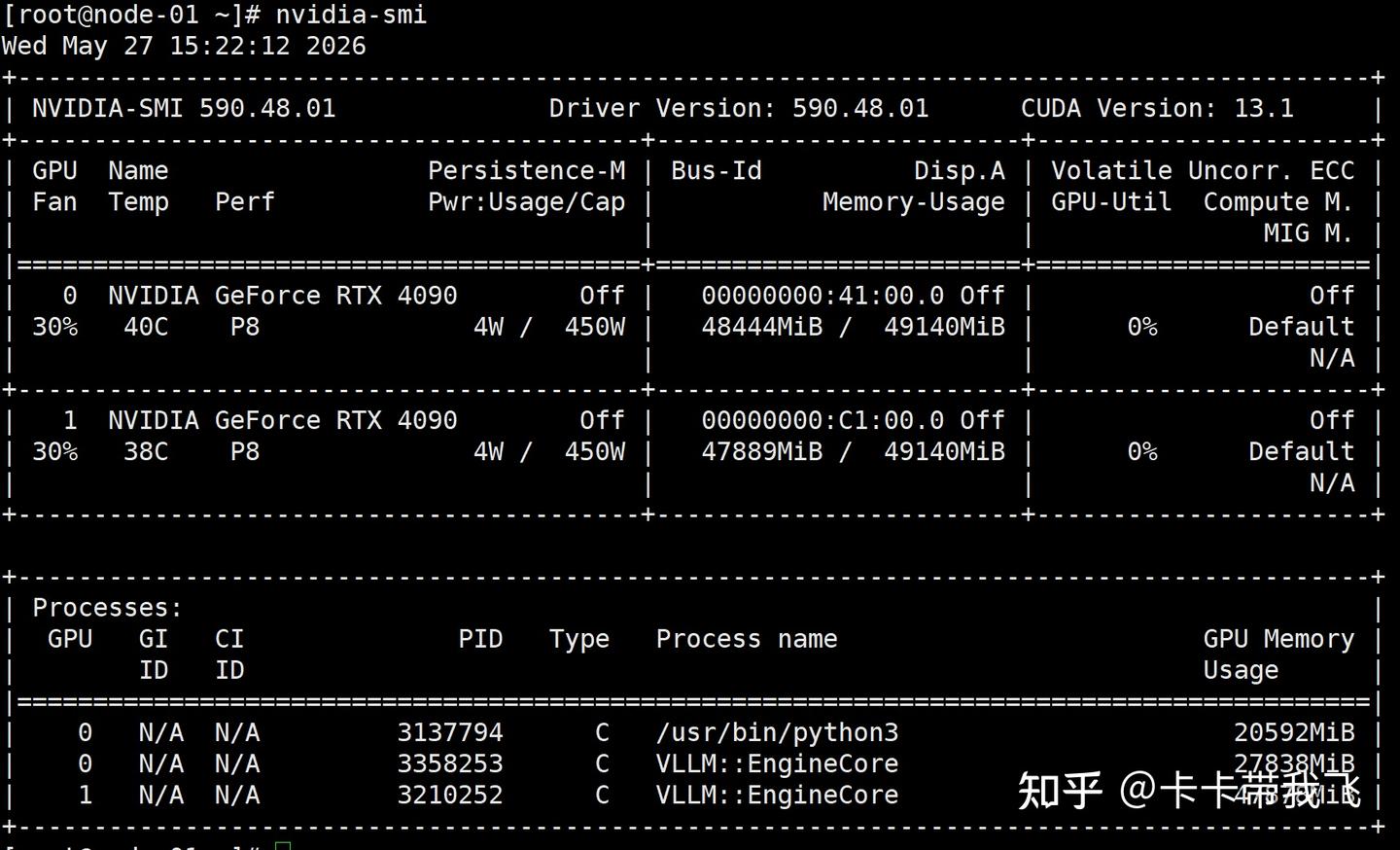
我自己的情况是公司有三台GPU服务器,配置是双4090 48G魔改卡(一张跑RAG服务,一张跑Qwen3.6-35B-A3B AWQ 4bit推理,上下文32768),RTX PRO 6000 96GB跑更大的模型。PRO 6000是两周前79,800入手的,现在已经涨到10万了(渠道商报价)。家里也折腾过好几套配置,踩过的坑比配对的机器多。我没有5090,下面5090的性能数据来自行业benchmark,我会标注清楚。
下面按预算分档说,价格都是2026年5月的中国渠道行情。
5千块:纯CPU路线
这个预算就别想独显跑模型了。
AMD 5600G + B550主板 + 64G DDR4内存。靠llama.cpp纯CPU推理,能跑Qwen3-30B-A3B这种MoE模型。总参数30B,每次推理只激活3B参数,CPU完全扛得住。(模型规格来源:Qwen官方GitHub)。速度不快,每秒两三个token。但好处是永远不爆显存。根本没有显存可以爆。挂后台让它跑,去干别的,回来答案就好了。
适合想先试试水的人。我最早玩本地模型也是从CPU开始的,能跑起来就是胜利。
1万块:入门显卡路线
这个价位能买到RTX 5060 Ti 16GB。目前渠道价大概2,800-3,200元。(京东/淘宝2026年5月均价)。16GB显存意味着你能跑:7B模型FP16,13B模型INT4量化,Qwen3-30B-A3B INT4。这个模型INT4约15GB。(显存估算来源:Qwen官方AWQ量化基准)
5060Ti跑13B模型INT4大概每秒34-38个token,跑7B模型能到70-90 tok/s。(数据来源:社区实测汇总,Reddit r/LocalLLaMA)
CPU配个i5-13400F,32G DDR5,1T固态。整机一万出头。
别小看16GB显存。它是能跑13B模型的最低门槛,8GB的卡只能跑7B量化版。
2万块:二手4090路线
这是我自己最推荐的性价比方案。
RTX 4090去年10月就停产了(NVIDIA官方公告),现在市面上的要么是库存要么是二手。二手4090目前8,000-10,000元能拿下,带店铺质保的贵一点。(闲鱼/淘宝2026年5月均价)
24GB GDDR6X显存,1,008 GB/s带宽。(NVIDIA官方规格)行业benchmark显示跑32B级模型AWQ量化约650 tok/s。(Spheron Network, vLLM测试)。CPU上i7-13700K,64G DDR5,2T固态,850W金牌电源。整机大概1.8-2.2万。
有人问为什么不买5090。差价摆在这。5090渠道价25,000-30,000元(中国灰市渠道报价),够买两台4090主机了。如果你主要跑量化后的30B级模型,4090的24GB够用。
但24GB跑长上下文确实吃紧。我们的实际体验:4090 48G魔改卡上跑Qwen3.6-35B-A3B AWQ 4bit,上下文设到32768完全没问题。同样的模型放普通4090 24GB上显存就很勉强了。而且这模型架构有优势:40层里30层是DeltaNet线性注意力,KV cache压力比纯标准注意力小得多。开个FP8 KV cache量化,单卡扛几十并发不是问题。

3万块:RTX 5090路线
到这里就开始有意思了。
RTX 5090官方MSRP $1,999(NVIDIA官方),但中国渠道实际价格25,000-30,000元。为什么这么贵?美国出口管制,5090完整版禁止卖到中国,市面上都是灰色渠道进来的,溢价严重。(来源:WCCFTech、新智元报道)
规格方面(NVIDIA官方):32GB GDDR7,1,792 GB/s带宽。是4090的1.78倍。大模型推理是带宽瓶颈,算力反而是次要的。行业benchmark显示5090跑32B级模型AWQ约1,100 tok/s,4090约650。(Spheron Network vLLM测试)
32GB显存意味着什么?我们实际跑的Qwen3.6-35B-A3B AWQ 4bit,模型权重约17-18GB,加上32768上下文KV cache,魔改48G上绰绰有余。普通4090的24GB跑同样配置会紧,5090的32GB就从容不少。(我们实测配置)
CPU配i9-13900K,64G DDR5,1000W电源。整机大概3-3.5万。
我个人的看法:虽然我没有5090,但从规格和benchmark来看,3万价位这是2026年的推理甜点。比4090多花一万多,多出来的8GB显存和77%带宽提升是真金白银。
5万块:双卡路线 or 专业卡入门
这个预算有两个方向。
- 方向A:双RTX 5090
两张5090总共64GB显存。能跑Llama 3.3 70B INT4(约35-40GB),单卡5090放不下。(显存估算来源:llama.cpp社区文档)两张卡做张量并行或pipeline并行,vLLM和SGLang都原生支持。
CPU上线程撕裂者或至强W系列,128G DDR5,1600W电源。主板要挑有双PCIe 5.0 x16插槽的。整机大概4.5-5.5万。
我们公司双卡4090魔改跑生产,双卡比单卡的最大好处不是速度是稳定性。一张卡挂了另一张还能扛。
- 方向B:RTX A6000 Ada 48GB
专业卡的优势是稳定性和显存。48GB GDDR6 ECC,300W功耗。(NVIDIA官方规格)跑LLM性能大概只有5090的60-70%,因为带宽才960 GB/s,但48GB可以单卡跑70B INT4。价格大概35,000-40,000元(渠道报价)。
一个没写在方案里但值得提的选项
RTX PRO 6000 Blackwell,96GB GDDR7 ECC。(NVIDIA官方规格)
我们公司两周前刚买了一张,79,800元。现在同事告诉我同款已经涨到10万了,就两周时间。这卡的涨价速度比我见过的任何硬件都快。(我们实际采购经历)
性能方面:LM Studio实测InternLM 50 tok/s,跑QwQ 32B全精度无压力。(GamersNexus评测)96GB能同时加载两个32B模型加一个rerank模型,还能剩十几GB做KV cache。(我们的实际用法)
单卡跑70B以上模型,PRO 6000是唯一选择。但如果只是跑32B以下模型,多张5090更划算。四张5090 128GB总价和一张PRO 6000差不多。

几个没人告诉你的坑
电源别省。5090满载575W(NVIDIA官方),瞬时峰值更高。配1000W以上金牌电源,别用杂牌。我们公司有台机器电源挂了烧了一张4090,损失一万多。
散热要当回事。5090是双槽卡但发热量巨大(575W TDP),机箱通风不好夏天能飙到85度降频。
内存频率对大模型推理几乎没影响,DDR5 4800和6000跑模型速度一样。(我们实测验证)钱花在显存上,别花在内存上。
Windows跑llama.cpp有驱动兼容问题,性能比Linux低20-30%。(Puget Systems测试、社区共识)想正经跑模型,装Ubuntu。
总结一下
5千预算:无独显CPU跑30B MoE,整机约5,000元
1万预算:5060Ti 16G跑13B全精度/32B量化,整机约10,000元
2万预算:4090 24G二手跑32B量化/14B全精度,整机约20,000元
3万预算:5090 32G跑32B量化长上下文/FP4前瞻,整机约32,000元
5万预算:双5090或A6000 48G跑70B量化/企业级,整机约50,000元
我们目前在用双4090 48G魔改卡(一张跑RAG服务,一张跑Qwen3.6-35B-A3B AWQ 4bit推理,上下文32768),PRO 6000 96GB跑更大的模型。如果有同事问我现在配新机器,2-3万预算我会建议上5090,预算够就上PRO 6000。96GB不用纠结显存问题,而且这卡两周涨两万的涨价速度说明早买就是省钱。
4090停产了,5090以后也只会越来越贵(GDDR7全球缺货,WCCFTech、新智元报道)。早买早享受。
有问题评论区聊。我之前写过4090魔改48G的半年使用体验和踩坑记录,有兴趣的可以去看看。
2026.06.01 更新:
PRO 6000 96GB最新价格已经到了10万+(上周刚问的渠道),比上个月贵了快50%。评论区也有朋友说淘宝渠道7-8万能拿到,但要注意看保修,有些是工包没售后的。5090现在含税3万出头,相对还算稳。结论没变:预算够就趁早买,AI硬件这波通胀比CPI猛多了。
2026.06.15更新:
PRO 6000的价格虚高到已经不成为一个选项了,最近有朋友付费咨询,我甚至又开始推荐4090的48G定制卡,关于渠道选择,少量的还是建议去京东和淘宝,一定要咨询到位。2U服务器加卡需要考虑适配电源、PCIE×16能力、卡位(一般要横插,考虑riser card)。