深度学习用什么卡比较给力?
翻了一下这个问题的已有回答,大部分是2023到2024年初写的。这两年显卡市场翻天覆地:4090停产,5090出了但中国禁售完整版,GDDR7全球缺货推高全系价格。
所以我写一版2026年5月的。不讲怎么配整机(那个我另写了一篇),这篇纯聊显卡本身。
我自己的情况:公司跑生产,用过4090 24G,4090魔改48G,RTX PRO 6000 96G。目前主力推理卡是4090魔改48G跑Qwen3.6-35B-A3B AWQ 4bit。我没有5090,所以5090的数据标注了来源。
▎ ⭐ 一个大原则:显存 > 带宽 > 算力
很多人选卡第一眼看TFLOPS。跑深度学习的话,这个顺序是错的。
大模型推理真正的瓶颈是显存容量和带宽。算力反而是最不重要的那个。举个具体例子:5090的FP16算力只比4090高27%,但带宽高了78%,显存多了33%。实际跑32B级模型AWQ量化,5090约1,100 tok/s,4090约650 tok/s。提升69%。(Spheron Network vLLM benchmark)
69% vs 27%,差距来自显存和带宽。4090的24GB跑32B模型KV cache塞不下,系统频繁做显存换页。5090的32GB刚好跨过这个坎。
所以判断一张卡能不能"给力",先看显存放不放得下你的模型+上下文,再看带宽够不够喂饱计算单元,最后才看算力。
▎ ⭐ RTX 5090:推理甜点,但不是神卡
先给数据(NVIDIA官方规格):32GB GDDR7,1,792 GB/s带宽,21,760 CUDA核心,575W TDP。MSRP $1,999,但那是美国价。中国市场完整版走灰色渠道,实际25,000-30,000元。
这卡的定位很微妙。32GB显存,比4090多8GB,比PRO 6000少64GB。刚好卡在"能跑30B级模型"的及格线上。1,792 GB/s带宽是目前消费卡里最高的,4090的1.78倍。
Spheron的benchmark显示,32B模型AWQ量化在5090上约1,100 tok/s,比4090的650快69%。但这不是因为5090算力多强,是4090的24GB塞不下KV cache在拖后腿。模型换成7B级别,差距缩小到37%(3,500 vs 2,550 tok/s)。
5090还有两个未来牌:FP4精度支持(Blackwell架构独有,理论上32GB等效64GB),以及更大的显存放在长上下文场景下优势更大。32K context在4090上很勉强,在5090上就从容了。
但5090不是没有槽点。575W TDP是消费卡里最高的,散热压力大。没有ECC内存。中国买不到正规渠道的完整版:NVIDIA在中国只合法卖5090D V2(24GB/384-bit,带宽砍了25%),实际性能未必比4090好多少,价格还要24,000-34,000元。(快科技/17173报道)
▎ 💡 PRO 6000 Blackwell 96GB:一张卡解决显存焦虑
这卡的核心卖点就一个:96GB GDDR7 ECC。(NVIDIA官方规格)
纯算力它不比5090强多少。GamersNexus评测显示模型能塞进32GB时只快0-25%。但模型一旦超过32GB,差距瞬间拉开:
Gemma 3 27B:PRO 6000 29 tok/s vs 5090 5 tok/s
Llama 3.3 70B Q4:PRO 6000 ~8 tok/s vs 5090 ~0.8 tok/s
(GamersNexus LM Studio实测,2025年评测)
5090跑70B Q4几乎不可用。显存爆了之后靠CPU offload,速度降到每秒不到一个token。PRO 6000虽然也只有8 tok/s,但至少能用。
PRO 6000的真正价值不在单模型速度,在能同时跑多个。96GB可以同时加载两个32B模型加一个rerank模型,再加几十GB做KV cache。这对生产环境多模型服务是刚需。
槽点是价格和散热。600W TDP(比5090还高25W),GamersNexus测核心82°C。更麻烦的是涨价:我们公司两周前79,800买的,现在渠道已经报10万了,就两周时间。(我们实际采购)
▎ ⚠️ 消费卡 vs 专业卡:场景决定选择
很多人纠结4090/5090还是A6000/A100。这是两个完全不同的赛道。
消费卡(4090/5090)的优势在性价比。推理性能基本追平专业卡(5090 vs H100在7B模型上只差11%,Spheron测试),价格便宜得多(5090 3万 vs H100 20万+)。缺点:没有ECC,没有NVLink,中国买完整版要靠灰市。
专业卡(A6000/A100/PRO 6000)的优势在可靠性。ECC内存防止静默数据错误,训练场景刚需。NVLink多卡互联,大规模训练必需的。缺点:贵,推理性价比不如消费卡。
RunPod的cost benchmark:每100美元月费能买到的token数,5090是24.8 tok/s,H100 PCIe是12.0 tok/s。5090单位成本的推理吞吐是H100的两倍。
一句话:做推理买消费卡,做训练买专业卡,又要推理又要训练买H100。
▎ ⚠️ 4090:停产了,但二手市场还在
4090 2024年10月就停产了(NVIDIA公告),现在市面上全是库存和二手。24GB GDDR6X,1,008 GB/s带宽。32B AWQ量化约650 tok/s。(Spheron)
二手价8,000-10,000元(闲鱼/淘宝均价),性价比仍然很高。但24GB显存在2026年已经是及格线边缘了。我们自己的经验:Qwen3.6-35B-A3B AWQ 4bit在魔改48G上跑32768上下文很稳,24G原版就跑不了。
4090还有个出路:魔改48G。中国工厂把显存颗粒换成更大容量的,约22,500元。我们在用两
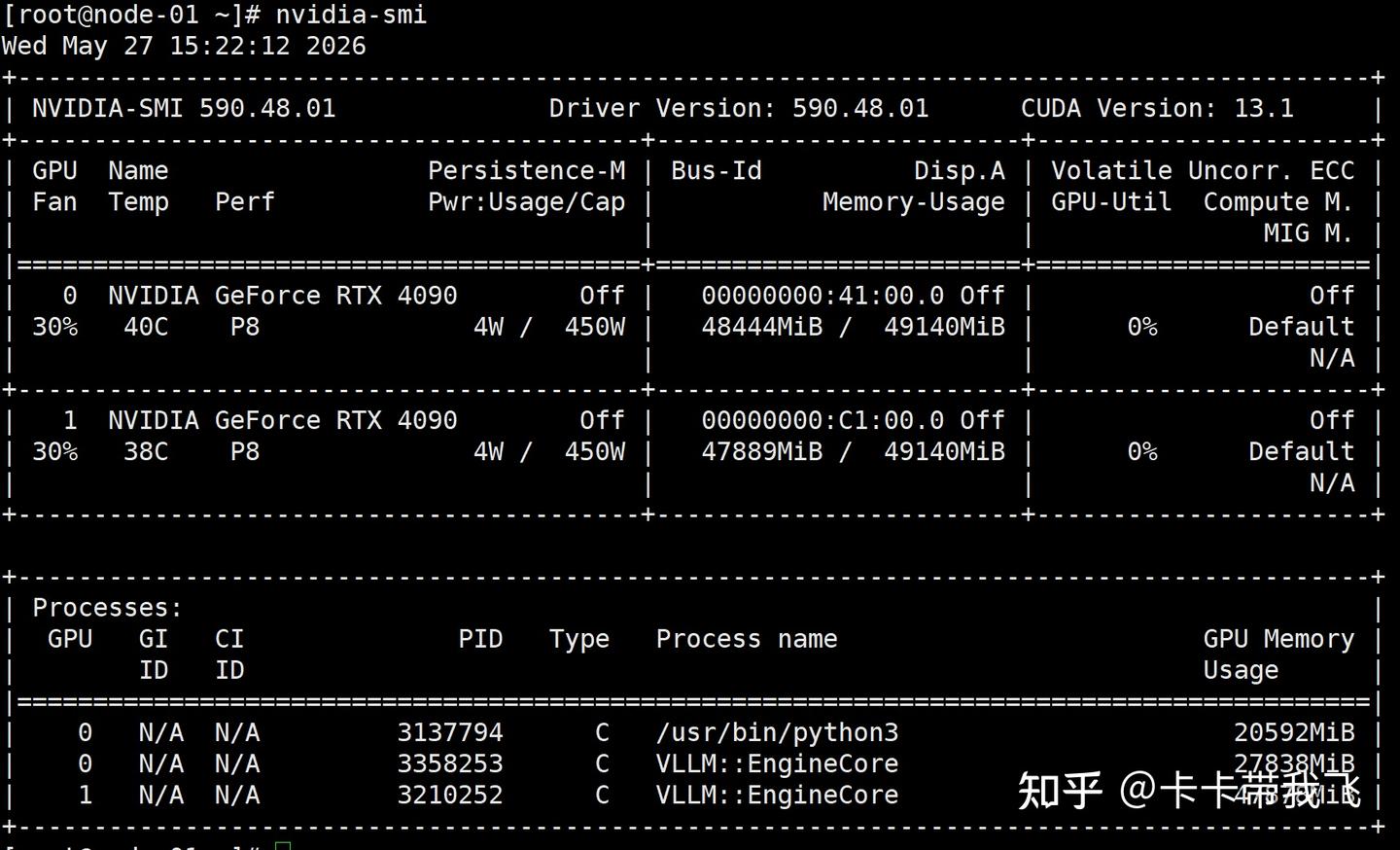
张,跑了半年多。48GB能跑70B INT4(约40GB),或同时加载两个32B模型。缺点是没保修,散热压力大。(我们实测 + InfoQ中文站报道)
▎ ⚠️ 中国买卡的特殊情况
这个必须单独说,因为直接影响你买不买得到、花多少钱。
出口管制。美国限制高性能GPU出口中国。RTX 5090完整版不能在中国合法销售,市面上都是灰色渠道。京东曾短暂上架35,999元后当天就下架了。(WCCFTech、TweakTown报道)
5090D陷阱。NVIDIA在中国合法卖的叫RTX 5090D V2。名字很像,但显存24GB、位宽384-bit(完整版是32GB/512-bit)。带宽砍了25%,实际性能未必比4090好。价格还要24,000-34,000元。(快科技报道)
全系涨价。GDDR7全球缺货,美国5090渠道价已从$1,999涨到$3,000-4,200。中国灰市只会更贵。PRO 6000同样被管制,两周涨两万的速度前所未见。
结论:买卡之前先确认三件事。完整版还是D版?有没有保修?渠道靠不靠谱?
▎ 💡 快速参考(2026年5月)
4090 24G:1,008 GB/s,~650 tok/s,二手8,000-10,000元 → 性价比之选,但24GB已勉强
5090 32G:1,792 GB/s,~1,100 tok/s,25,000-30,000元 → 推理甜点,中国买不到正规渠道
4090魔改48G:1,008 GB/s,~650 tok/s,~22,500元 → 赌博,赢了很香
PRO 6000 96G:1,792 GB/s,~1,200 tok/s,79,800-100,000+元 → 显存焦虑终结者
A100 80G:2,039 GB/s,~1,400 tok/s,二手55,000-65,000元 → 训练+推理全能
H100 80G:3,350 GB/s,~4,600 tok/s(7B),200,000-280,000元 → 企业训练集群
数据来源:NVIDIA官方 / Spheron / GamersNexus / RunPod / 我们实测
入门卡(3060 12G/5060Ti 16G)适合学生跑实验,但不在本文"给力"的讨论范围内。配整机方案我写在了另一篇回答里。
最后再说一遍那个原则:先搞清楚你主要跑什么模型,再决定买什么卡。跑7B模型的买5090是浪费,跑70B模型的买4090是折磨。显存放得下是第一优先级,其他都是次要的。
有什么问题评论区聊。我之前写过4090魔改48G的半年踩坑记录,有兴趣的可以去看。