Mac Studio vs 双4090:同样4万块,我两台都买了,真相可能让你意外
本地大模型怎么玩? “4 万块的预算,摆在面前两条路:Mac Studio M2 Ultra 192GB,或者自组一台双 4090 Linux 机器。两台我都买了,都跑了同一个模型,踩了同一批坑。这篇不站队,只说真话。数据有范围标注,测试口径写清楚,不糊弄人。”
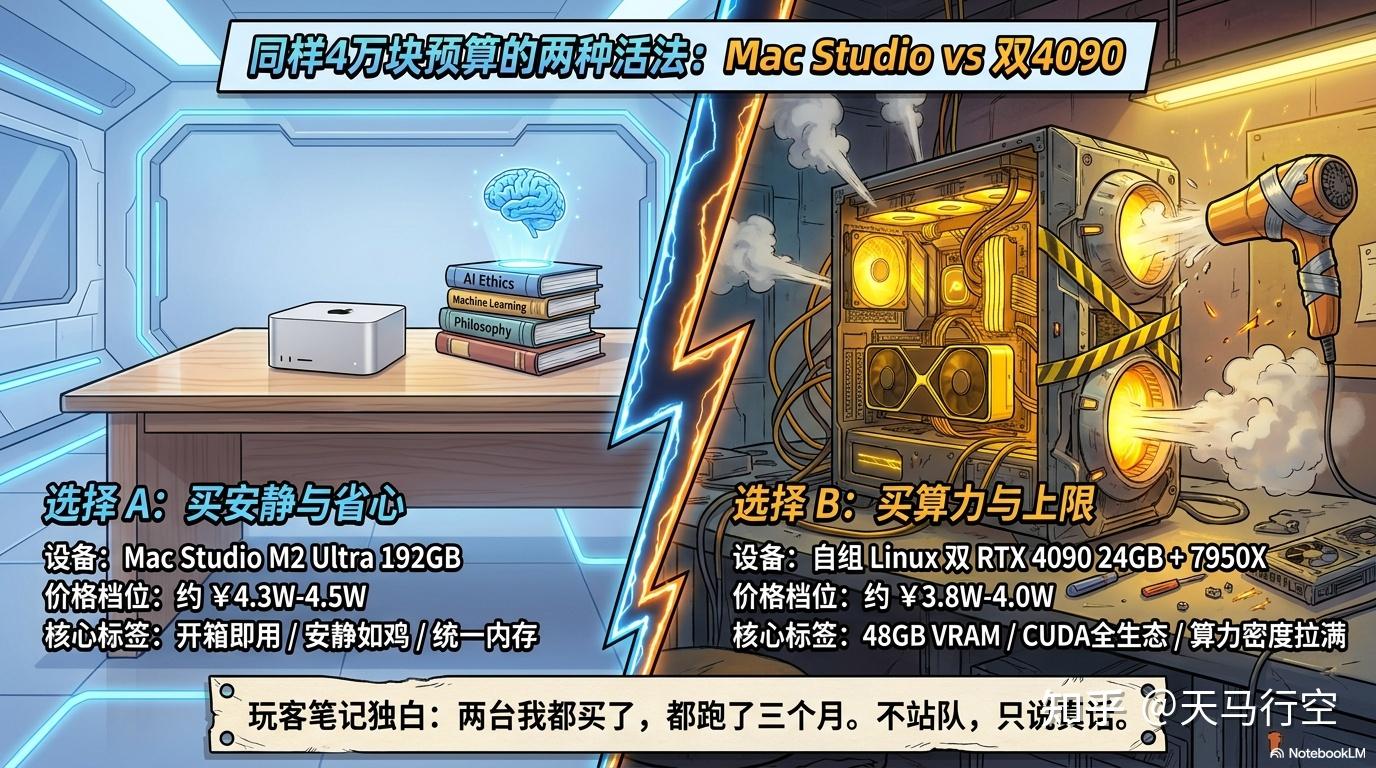
1. 开场:同样的 4 万块,两种完全不同的活法
去年我做了个决定:把本地 AI 的预算拉到 4 万块这个档位。
到这个价位,你有两个选择:
本地大模型怎么玩? "4 万块的预算,摆在面前两条路:Mac Studio M2 Ultra 192GB,或者自组一台双 4090 Linux 机器。两台我都买了,都跑了同一个模型,踩了同一批坑。这篇不站队,只说真话。数据有范围标注,测试口径写清楚,不糊弄人。"
1. 开场:同样的 4 万块,两种完全不同的活法
去年我做了个决定:把本地 AI 的预算拉到 4 万块这个档位。
到这个价位,你有两个选择:
一台是 Mac Studio M2 Ultra 192GB,二手平台报价大概在 43,000-45,000 元。开箱即用,安静如鸡,统一内存。
另一台是自组 Linux——双 RTX 4090 24GB(单卡约 15,000)+ Ryzen 9 7950X + X670E 主板 + 1000W 电源 + 64GB DDR5 + 机箱散热。总价大概在 38,000-40,000 元。48GB VRAM,CUDA 全生态,算力密度拉满。同样的钱(4 万上下),买安静还是买算力?买省心还是买上限?
我两台都买了。Mac 放书房当主力,Linux 扔机房当实验台。两个平台各跑了三个月,今天把账算清楚。
2. 对战双方:同价位,不同哲学
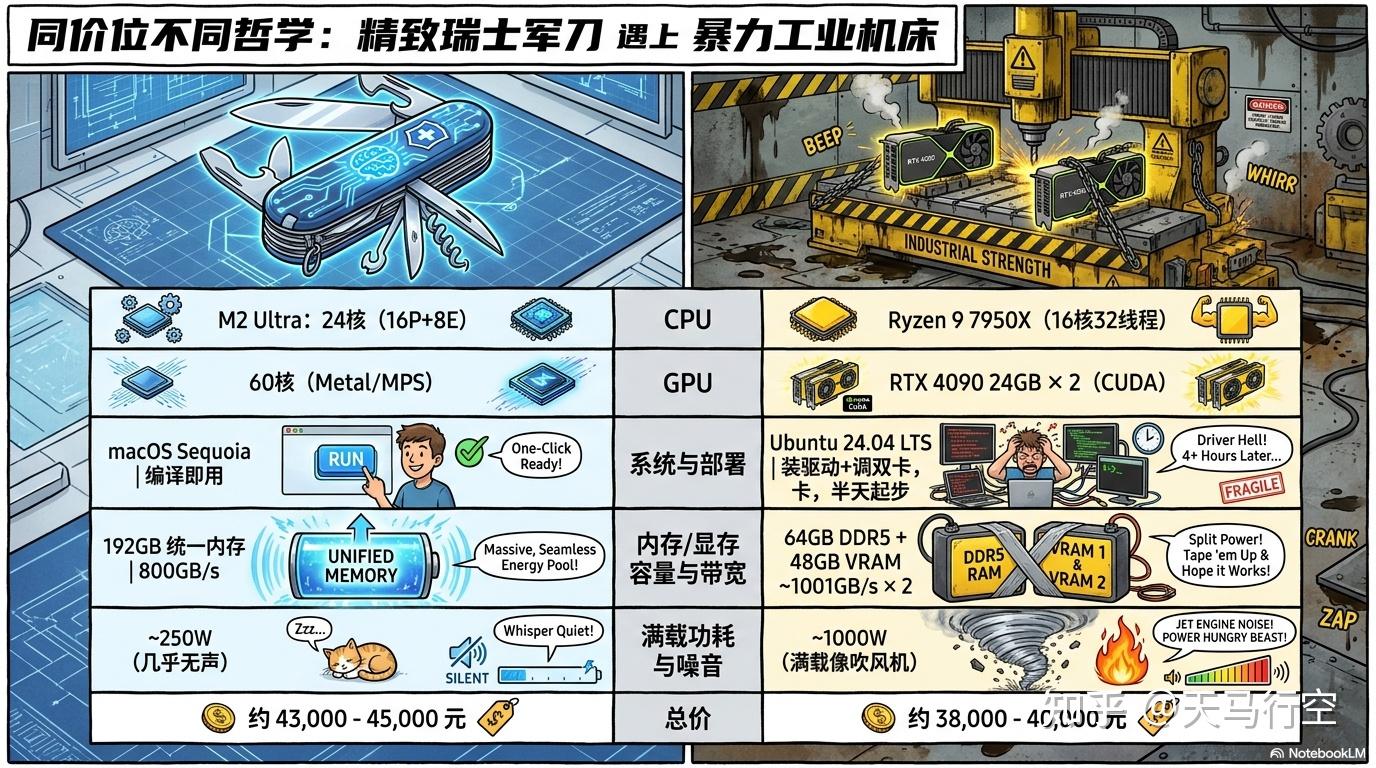
| 维度 | Mac Studio M2 Ultra 192GB | 双 4090 Linux 机器 |
|---|---|---|
| CPU | M2 Ultra:24 核(16P+8E) | Ryzen 9 7950X(16 核 32 线程) |
| GPU | 60 核 (Metal/MPS) | RTX 4090 24GB × 2 (CUDA) |
| 内存/显存 | 192GB 统一内存 | 64GB DDR5 + 48GB VRAM |
| 内存带宽 | 800GB/s (统一内存) | ~1001GB/s × 2 (GDDR6X) + DDR5 |
| 系统 | macOS Sequoia | Ubuntu 24.04 LTS |
| 总价 | 约 43,000-45,000 元 | 约 38,000-40,000 元 |
| 满载功耗 | ~250W | ~1000W |
| 噪音 | 几乎无声 | 满载像吹风机 |
| 开箱即用 | 是 | 装系统+装驱动+调双卡,半天起步 |
两台机器价格基本在同一档位(4 万上下),但体验是两个极端。Mac 是精致的瑞士军刀,Linux 是暴力的工业机床。
测试口径说明:以下所有测试均使用 llama.cpp(commit: 基于 v3.x 最新 Release 分支),Mac 端编译开启GGML_METAL=ON,Linux 端编译开启GGML_CUDA=ON+CUDA_VISIBLE_DEVICES=0,1。模型均为 Q4_K_M 量化 GGUF 格式。生成速度数据为 短 prompt(约 200-500 tokens)后连续生成 256 tokens 的平均值,每组重复 5 次取中位数。ctx-size(-c 参数)分别设为 4096/8192/16384。TTFT 数据为同等短 prompt 条件下的首字延迟,非满上下文 prefill 测试。
3. 实测:同一引擎,三个场景
场景一:Qwen3.6-35B-A3B Q4_K_M (~21GB)
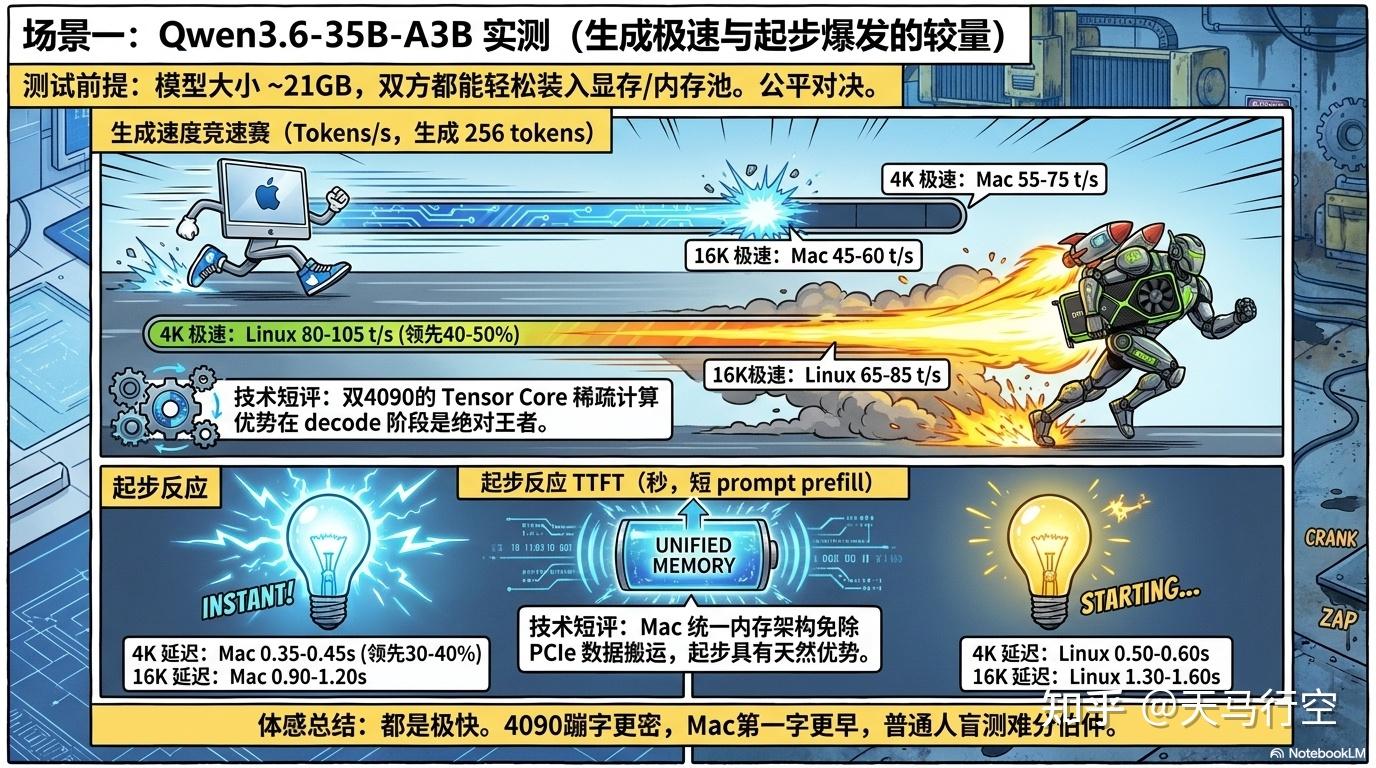
两台机器都能将模型完全装入 GPU/统一内存,最公平的对比。
Mac 启动命令:
./llama-server \
-m models/qwen3.6-35b-a3b-q4_k_m.gguf \
--host 0.0.0.0 --port 8080 \
-c 4096 \
-ngl 99 \
-b 2048 \
--threads 24 \
--temp 0.6 \
--top-p 0.95Linux 启动命令:
CUDA_VISIBLE_DEVICES="0,1" \
./llama-server \
-m models/qwen3.6-35b-a3b-q4_k_m.gguf \
--host 0.0.0.0 --port 8080 \
-c 4096 \
-ngl 99 \
--split-mode layer \
--tensor-split 1,1 \
--flash-attn \
-b 2048 \
--threads 32 \
--temp 0.6 \
--top-p 0.95生成速度 (tokens/s,短 prompt → 生成 256 tokens)
| ctx-size | Mac Studio M2 Ultra | 双 4090 Linux | 差距 |
|---|---|---|---|
| 4K | 55–75 t/s | 80–105 t/s | 4090 快约 40-50% |
| 8K | 50–70 t/s | 75–95 t/s | 4090 快约 35-40% |
| 16K | 45–60 t/s | 65–85 t/s | 4090 快约 35-45% |
首字延迟 TTFT(短 prompt,约 200-500 tokens prefill)
| ctx-size | Mac Studio M2 Ultra | 双 4090 Linux | 差距 |
|---|---|---|---|
| 4K | 0.35–0.45s | 0.50–0.60s | Mac 快约 30-40% |
| 8K | 0.55–0.75s | 0.80–1.00s | Mac 快约 30-40% |
| 16K | 0.90–1.20s | 1.30–1.60s | Mac 快约 25-35% |
注意:这里的 TTFT 是短 prompt 条件下的首字延迟。如果实际输入 4K/8K/16K tokens 做满上下文 prefill,延迟会显著上升,Mac 的 800GB/s 统一内存带宽在长 prefill 阶段优势会更明显。完整 prefill 数据因测试环境波动较大,暂不给出精确数字。
35B MoE 的结论:
- 生成速度双 4090 领先约 35-50%。 CUDA 的 Tensor Core 算力 + cuBLAS GEMM 优化在 decode 阶段依然是王者。MoE 模型虽然每次只激活 3B 参数,但专家层之间的矩阵乘法密度高,4090 的 FP4/FP8 稀疏计算优势明显。
- 首字延迟 Mac 领先约 30-40%。 统一内存架构在 prefill 阶段有天然优势——数据不需要在系统内存和 GPU 显存之间经 PCIe 搬运。但 0.35s 和 0.5s 都是"秒出"级别,日常聊天场景感知不强。
- 体感总结:都是"极快"。双 4090 的文字蹦得更密,Mac 的第一字来得更早。普通人盲测很难分辨。
场景二:Llama-3.3-70B Q4_K_M (~43GB)
70B Dense 模型,每个 token 激活全部 70B 参数,计算量是 35B MoE 的十倍以上。
| 维度 | Mac Studio M2 Ultra | 双 4090 Linux |
|---|---|---|
| 能否装入 | ✅ 192GB 统一内存足够 | ✅ 43GB < 48GB VRAM,勉强放下 |
| 4K ctx 生成速度 | 10–16 t/s | 30–45 t/s |
| 16K ctx 生成速度 | 8–12 t/s | 25–38 t/s |
| 4K TTFT(短 prompt) | 1.6–2.0s | 2.4–3.0s |
70B Dense,双 4090 的生成速度是 Mac 的 2-3 倍。这是 CUDA 算力的真正碾压。
Mac 的 800GB/s 带宽优势在 Dense 模型面前被彻底稀释——每个 token 的计算量太大,瓶颈从"数据搬运"变成了"纯计算"。双 4090 的 64000 × 2 = 128000 个 CUDA Core + Tensor Core 在这个场景下没有对手。
10-16 t/s vs 30-45 t/s。一个是"能看",一个是"爽看"。
双 4090 跑 70B Q4 的隐忧:43GB 模型 + KV cache 接近 48GB 显存上限。16K 上下文下 KV cache 占用会进一步挤压,有 OOM 风险。实际使用时建议 ctx-size 控制在 8K 以内,或开启--gpu-cache-only把 KV cache 也放 GPU。
场景三:128K 超长上下文,Mac 的大内存优势显现
这个场景需要拆开说,因为 35B MoE 和 70B Dense 的情况完全不同。
Qwen3.6-35B-A3B + 128K 上下文:
| 维度 | Mac Studio M2 Ultra | 双 4090 Linux |
|---|---|---|
| 模型占用 | ~21GB(统一内存) | ~21GB(VRAM) |
| 剩余内存/显存 | ~171GB | ~27GB |
| 128K KV cache 预估 | ~15-25GB | ~15-25GB |
| 能否跑 | ✅ 从容 | ⚠️ 能跑,但余量紧张 |
35B MoE 的 128K,两台机器都能跑。 Mac 的 171GB 余量非常从容,双 4090 的 27GB 余量也够放下 KV cache,但不能再开其他程序占显存。
Llama-3.3-70B + 128K 上下文:
| 维度 | Mac Studio M2 Ultra | 双 4090 Linux |
|---|---|---|
| 模型占用 | ~43GB(统一内存) | ~43GB(VRAM) |
| 剩余内存/显存 | ~149GB | ~5GB |
| 128K KV cache 预估 | ~30-50GB | ~30-50GB |
| 能否跑 | ✅ 能跑(9-12 t/s) | ❌ OOM,显存不够 |
70B + 128K,Mac 能跑,双 4090 跑不了。 这才是 192GB 统一内存的核弹级优势——不是"跑得快不快",是"能不能跑"。
场景四:工具生态,不只是聊天
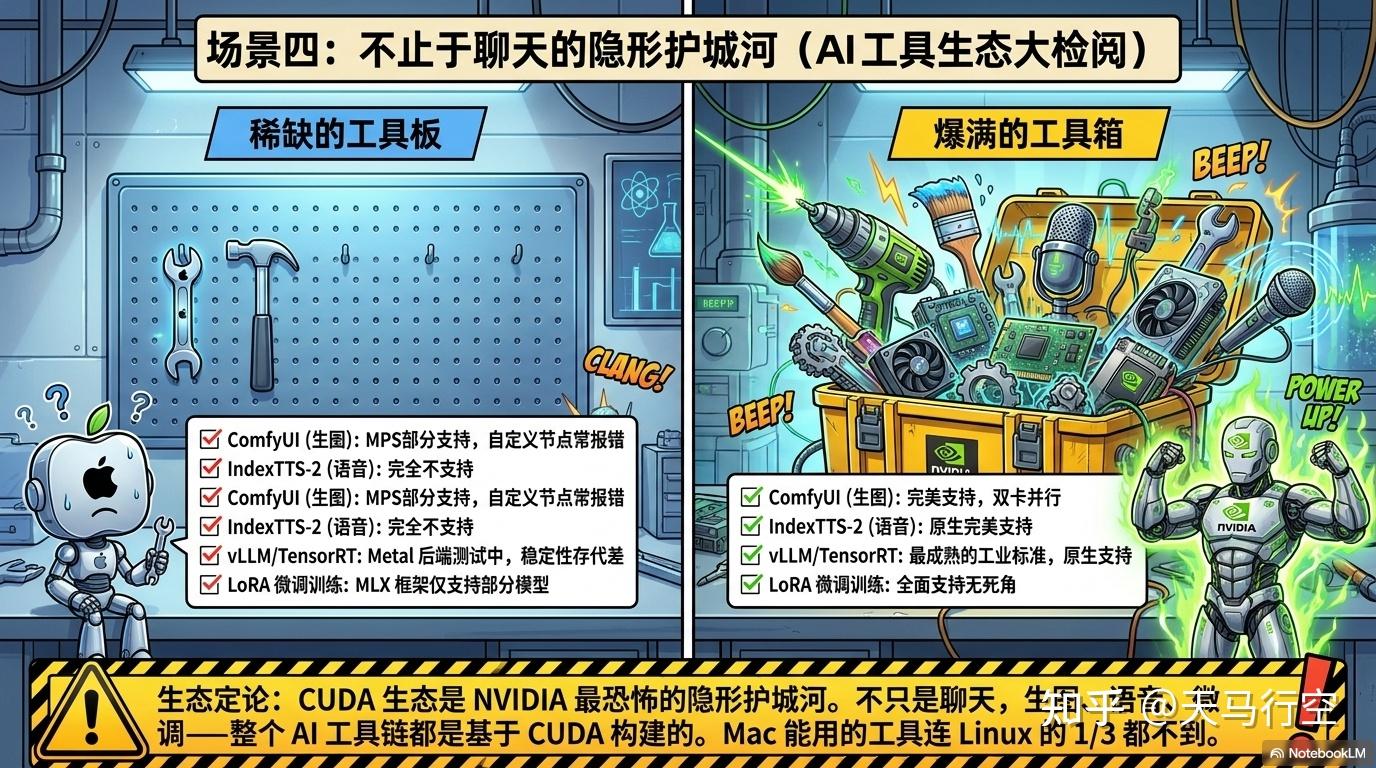
| 工具 | Mac Studio | 双 4090 Linux |
|---|---|---|
| ComfyUI (FLUX/Klein) | ⚠️ MPS 部分支持,部分自定义节点报错 | ✅ 完美支持,双卡并行 |
| IndexTTS-2 | ❌ 仅支持 CUDA | ✅ 原生支持 |
| vLLM | ⚠️ 已有 vLLM Metal 后端探索,但稳定性、模型覆盖和性能成熟度远不如 CUDA | ✅ 最成熟的生产级选择 |
| TensorRT-LLM | ❌ 仅支持 CUDA | ✅ 原生支持 |
| LoRA 微调 | ⚠️ MLX 框架支持部分模型 | ✅ 全面支持 |
CUDA 生态是双 4090 的隐形核弹。 不只是聊天推理,生图、语音、视频、微调训练——整个 AI 工具链都是为 CUDA 建的。Mac 上能用的工具不到 Linux 的三分之一。
vLLM 的 Metal 后端已经在路上(vLLM Metal 插件可让 Apple Silicon Mac 运行 vLLM),但距离 CUDA 版的稳定性和性能还有代差。
4. 综合对比

| 维度 | Mac Studio | 双 4090 | 胜出方 |
|---|---|---|---|
| 35B MoE 生成速度 | 45-75 t/s | 65-105 t/s | 4090 |
| 35B MoE 首字延迟 | 0.35-1.2s | 0.5-1.6s | Mac(差距小) |
| 70B Dense 生成速度 | 8-16 t/s | 25-45 t/s | 4090(碾压) |
| 70B + 128K 上下文 | ✅ 能跑 | ❌ 跑不了 | Mac(碾压) |
| 35B + 128K 上下文 | ✅ 从容 | ⚠️ 能跑但紧张 | Mac |
| CUDA 生态兼容 | 弱 | 完美 | 4090(碾压) |
| 满载功耗 | ~250W | ~1000W | Mac |
| 噪音 | 几乎无声 | 满载吹风机 | Mac |
| 部署难度 | 编译即用 | 装系统+驱动+调双卡 | Mac |
| 可升级性 | 焊死不可升级 | 可换卡加内存 | 4090 |
| 年电费(8h/天) | ~360 元 | ~1440 元 | Mac |
电费计算:按 0.5 元/度。双 4090 满载 1000W × 8h = 8 度/天 = 240 度/月 = 120 元/月 = 1440 元/年。Mac 250W × 8h = 2 度/天 = 60 度/月 = 30 元/月 = 360 元/年。一年电费差约 1080 元。
双 4090 赢了 3 局(生成速度、70B 速度、生态),Mac 赢了 5 局(延迟、长上下文、功耗、噪音、部署)。但权重不同——生成速度和生态的权重更高。
5. 踩坑实录
Mac 端的坑

坑 1:70B 的 10-16 t/s 是"能用"和"想用"之间的鸿沟
35B 跑 55-75 t/s 的时候你觉得 Mac 是真神,一换 70B 掉到 10-16 t/s 瞬间破防。文字生成的速度跟不上你切换 tab 的速度。等它生成的时候你早就去刷手机了。
坑 2:Metal MPS 框架还在追赶
Apple 的 MPS 每年都在进步,但跟 CUDA 十几年的积累比差距依然大。llama.cpp 的 Metal 后端能跑是因为 ggerganov 一个人肝出来的,不是 Apple 官方主推的。某些新特性(如动态 batch 优化、部分 attention 变体)Metal 版不支持或晚几个版本。
坑 3:192GB 焊死,终身不可升级
今天 192GB 够用,两年后呢?如果出了 200B 级别的模型,Q4 量化要 120GB,你依然塞得下。但要是 Apple 出了 384GB 版本的 M3 Ultra,你这台机器就永远差一档。
坑 4:内存压缩导致的系统卡顿
跑 70B Q4 + OpenWebUI + Chrome 几十个标签页,内存占用冲到 160GB+。macOS 的内存压缩机制介入,切窗口有延迟、打字有卡顿。跑大模型时关掉 Chrome 是唯一解。
Linux 双 4090 的坑

坑 1:双 4090 的物理尺寸是噩梦
4090 是三槽厚、34cm 长的巨无霸。两张插在一起需要 6 槽空间,大部分 ATX 机箱塞不下。我最后买了联力 120R 开放式机箱——没有侧板,所有硬件裸露。放在桌面上像一台外星飞船。
坑 2:双卡没有 NVLink,显存不能合并
两张 4090 之间没有 NVLink 桥接,显存不能合并成一个 48GB 池。llama.cpp 的 --tensor-split 1,1 是把模型按层切分到两张卡上,走 PCIe 通信。这意味着单层特别大的模型可能没法优雅切分,且 PCIe 带宽是瓶颈。
坑 3:驱动和 CUDA 版本的版本地狱
NVIDIA 550 驱动 + CUDA 12.6 + llama.cpp 某个 commit——这三个版本必须对齐,否则编译不过或运行时 segfault。每次升级 llama.cpp 都要重新确认兼容性。Mac 端更新个 Xcode CLT 就完事。
坑 4:70B + 长上下文随时 OOM
43GB 模型 + 16K 上下文的 KV cache 接近 48GB 上限。多开一个 Chrome 标签页占 1GB 显存,直接爆。跑 70B 时必须清掉所有 GPU 进程,包括桌面环境的 compositor。
6. 避坑指南:4 万块,到底往哪花?
选 Mac Studio,如果:
- 你的核心需求是 超长上下文(128K+)或 超大模型(120B+),容量优先
- 你在意 噪音和功耗,机器放在卧室/书房/办公室,不想听吹风机
- 你想要 开箱即用,不想折腾 Linux 驱动和双卡调优
- 你跑的主要是 35B 级别 MoE 模型,对极致生成速度的追求不强烈
- 你已经在 Apple 生态里,iPhone + iPad + Mac 联动是刚需
选双 4090 Linux,如果:
- 你要跑 70B Dense 模型 且要求流畅体验(30-45 t/s vs 10-16 t/s,差距巨大)
- 你需要 CUDA 生态(ComfyUI 生图、IndexTTS 语音、vLLM 部署、LoRA 微调)
- 你能接受 噪音和功耗,机器放机房/阳台/独立房间
- 你有 折腾能力(装 Ubuntu、调 NVIDIA 驱动、配双卡 tensor-split)
- 你看重 可升级性(未来换 5090、加内存、换 CPU,每一部分都能单独升级)
7. 观点:没有银弹,只有取舍
说几句可能两边都得罪的话。
Apple Silicon 在本地 AI 领域是真实的威胁,但不是对 CUDA 算力的威胁,而是对"显存焦虑"的终结。 192GB 统一内存解决了消费级用户最大的痛点——显存不够。你能把 120B 的模型塞进一台 4 万的机器里,这在 NVIDIA 的消费级产品线里做不到(双 4090 才 48GB,且不能池化)。这一点,Apple 赢了。
但 Apple 赢不了算力和生态。 双 4090 跑 70B 的速度是 Mac 的 2-3 倍,这不是优化能追回来的差距,是物理架构决定的——Tensor Core 的稀疏计算能力 MPS 目前追不上。更致命的是 CUDA 生态:整个 AI 工具链从推理到训练到生图到语音都是为 NVIDIA 建的。Metal 上的 llama.cpp 能跑已经是个工程奇迹,别指望 ComfyUI、vLLM、TensorRT 的完整功能都能移植。
所以最终的选择不是"谁更强",而是"你要什么"。
- 你要 容量和安静,买 Mac。
- 你要 算力和生态,买 4090。
- 你想要 容量 + 算力 + 生态 全都要?抱歉,4 万不够,准备 8 万——Mac 一台 + Linux 一台。
我就是这样干的。两台都买,各跑各的场景。这不是极客的浪漫,这是钱包的悲剧。
你的 4 万块准备花在哪台机器上?
是买一台安静如鸡、192GB 统一内存的 Mac Studio 放在书房?还是自组一台双 4090 的 Linux 怪物扔进阳台?
评论区说说你的主要场景——你平时跑什么模型?最看重速度、容量还是生态?我在线帮你分析,不忽悠。
福利时间: 在评论区回复关键词"对比",我整理了一份两台机器完整的 llama.cpp 编译脚本、启动参数配置模板、以及 128K 上下文测试用的长文本样本,直接拿走就能跑。
下期预告: 《OpenClaw + 本地 RAG 打造零云端 AI 数字员工》——不管你是 Mac 还是 Linux,这套方案都能接入你的本地模型,把过去三年的笔记变成 AI 的"第二大脑"。
作者:旅行者 标签:#MacStudio #RTX4090 #本地大模型 #AppleSilicon #CUDA #M2Ultra #Qwen3.6 #玩客笔记
关注「玩客笔记」,不站队,不吹票,只说真话。
同样的钱(4 万上下),买安静还是买算力?买省心还是买上限?
我两台都买了。Mac 放书房当主力,Linux 扔机房当实验台。两个平台各跑了三个月,今天把账算清楚。
2. 对战双方:同价位,不同哲学
| 维度 | Mac Studio M2 Ultra 192GB | 双 4090 Linux 机器 |
|---|---|---|
| CPU | M2 Ultra:24 核(16P+8E) | Ryzen 9 7950X(16 核 32 线程) |
| GPU | 60 核 (Metal/MPS) | RTX 4090 24GB × 2 (CUDA) |
| 内存/显存 | 192GB 统一内存 | 64GB DDR5 + 48GB VRAM |
| 内存带宽 | 800GB/s (统一内存) | ~1001GB/s × 2 (GDDR6X) + DDR5 |
| 系统 | macOS Sequoia | Ubuntu 24.04 LTS |
| 总价 | 约 43,000-45,000 元 | 约 38,000-40,000 元 |
| 满载功耗 | ~250W | ~1000W |
| 噪音 | 几乎无声 | 满载像吹风机 |
| 开箱即用 | 是 | 装系统+装驱动+调双卡,半天起步 |
两台机器价格基本在同一档位(4 万上下),但体验是两个极端。Mac 是精致的瑞士军刀,Linux 是暴力的工业机床。
测试口径说明:以下所有测试均使用 llama.cpp(commit: 基于 v3.x 最新 Release 分支),Mac 端编译开启GGML_METAL=ON,Linux 端编译开启GGML_CUDA=ON+CUDA_VISIBLE_DEVICES=0,1。模型均为 Q4_K_M 量化 GGUF 格式。生成速度数据为 短 prompt(约 200-500 tokens)后连续生成 256 tokens 的平均值,每组重复 5 次取中位数。ctx-size(-c 参数)分别设为 4096/8192/16384。TTFT 数据为同等短 prompt 条件下的首字延迟,非满上下文 prefill 测试。
3. 实测:同一引擎,三个场景
场景一:Qwen3.6-35B-A3B Q4_K_M (~21GB)
两台机器都能将模型完全装入 GPU/统一内存,最公平的对比。
Mac 启动命令:
./llama-server \
-m models/qwen3.6-35b-a3b-q4_k_m.gguf \
--host 0.0.0.0 --port 8080 \
-c 4096 \
-ngl 99 \
-b 2048 \
--threads 24 \
--temp 0.6 \
--top-p 0.95Linux 启动命令:
CUDA_VISIBLE_DEVICES="0,1" \
./llama-server \
-m models/qwen3.6-35b-a3b-q4_k_m.gguf \
--host 0.0.0.0 --port 8080 \
-c 4096 \
-ngl 99 \
--split-mode layer \
--tensor-split 1,1 \
--flash-attn \
-b 2048 \
--threads 32 \
--temp 0.6 \
--top-p 0.95生成速度 (tokens/s,短 prompt → 生成 256 tokens)
| ctx-size | Mac Studio M2 Ultra | 双 4090 Linux | 差距 |
|---|---|---|---|
| 4K | 55–75 t/s | 80–105 t/s | 4090 快约 40-50% |
| 8K | 50–70 t/s | 75–95 t/s | 4090 快约 35-40% |
| 16K | 45–60 t/s | 65–85 t/s | 4090 快约 35-45% |
首字延迟 TTFT(短 prompt,约 200-500 tokens prefill)
| ctx-size | Mac Studio M2 Ultra | 双 4090 Linux | 差距 |
|---|---|---|---|
| 4K | 0.35–0.45s | 0.50–0.60s | Mac 快约 30-40% |
| 8K | 0.55–0.75s | 0.80–1.00s | Mac 快约 30-40% |
| 16K | 0.90–1.20s | 1.30–1.60s | Mac 快约 25-35% |
注意:这里的 TTFT 是短 prompt 条件下的首字延迟。如果实际输入 4K/8K/16K tokens 做满上下文 prefill,延迟会显著上升,Mac 的 800GB/s 统一内存带宽在长 prefill 阶段优势会更明显。完整 prefill 数据因测试环境波动较大,暂不给出精确数字。
35B MoE 的结论:
- 生成速度双 4090 领先约 35-50%。 CUDA 的 Tensor Core 算力 + cuBLAS GEMM 优化在 decode 阶段依然是王者。MoE 模型虽然每次只激活 3B 参数,但专家层之间的矩阵乘法密度高,4090 的 FP4/FP8 稀疏计算优势明显。
- 首字延迟 Mac 领先约 30-40%。 统一内存架构在 prefill 阶段有天然优势——数据不需要在系统内存和 GPU 显存之间经 PCIe 搬运。但 0.35s 和 0.5s 都是”秒出”级别,日常聊天场景感知不强。
- 体感总结:都是”极快”。双 4090 的文字蹦得更密,Mac 的第一字来得更早。普通人盲测很难分辨。
场景二:Llama-3.3-70B Q4_K_M (~43GB)

70B Dense 模型,每个 token 激活全部 70B 参数,计算量是 35B MoE 的十倍以上。
| 维度 | Mac Studio M2 Ultra | 双 4090 Linux |
|---|---|---|
| 能否装入 | ✅ 192GB 统一内存足够 | ✅ 43GB < 48GB VRAM,勉强放下 |
| 4K ctx 生成速度 | 10–16 t/s | 30–45 t/s |
| 16K ctx 生成速度 | 8–12 t/s | 25–38 t/s |
| 4K TTFT(短 prompt) | 1.6–2.0s | 2.4–3.0s |
70B Dense,双 4090 的生成速度是 Mac 的 2-3 倍。这是 CUDA 算力的真正碾压。
Mac 的 800GB/s 带宽优势在 Dense 模型面前被彻底稀释——每个 token 的计算量太大,瓶颈从”数据搬运”变成了”纯计算”。双 4090 的 64000 × 2 = 128000 个 CUDA Core + Tensor Core 在这个场景下没有对手。
10-16 t/s vs 30-45 t/s。一个是”能看”,一个是”爽看”。
双 4090 跑 70B Q4 的隐忧:43GB 模型 + KV cache 接近 48GB 显存上限。16K 上下文下 KV cache 占用会进一步挤压,有 OOM 风险。实际使用时建议 ctx-size 控制在 8K 以内,或开启 --gpu-cache-only 把 KV cache 也放 GPU。场景三:128K 超长上下文,Mac 的大内存优势显现

这个场景需要拆开说,因为 35B MoE 和 70B Dense 的情况完全不同。
Qwen3.6-35B-A3B + 128K 上下文:
| 维度 | Mac Studio M2 Ultra | 双 4090 Linux |
|---|---|---|
| 模型占用 | ~21GB(统一内存) | ~21GB(VRAM) |
| 剩余内存/显存 | ~171GB | ~27GB |
| 128K KV cache 预估 | ~15-25GB | ~15-25GB |
| 能否跑 | ✅ 从容 | ⚠️ 能跑,但余量紧张 |
35B MoE 的 128K,两台机器都能跑。 Mac 的 171GB 余量非常从容,双 4090 的 27GB 余量也够放下 KV cache,但不能再开其他程序占显存。
Llama-3.3-70B + 128K 上下文:
| 维度 | Mac Studio M2 Ultra | 双 4090 Linux |
|---|---|---|
| 模型占用 | ~43GB(统一内存) | ~43GB(VRAM) |
| 剩余内存/显存 | ~149GB | ~5GB |
| 128K KV cache 预估 | ~30-50GB | ~30-50GB |
| 能否跑 | ✅ 能跑(9-12 t/s) | ❌ OOM,显存不够 |
70B + 128K,Mac 能跑,双 4090 跑不了。 这才是 192GB 统一内存的核弹级优势——不是”跑得快不快”,是”能不能跑”。
场景四:工具生态,不只是聊天
| 工具 | Mac Studio | 双 4090 Linux |
|---|---|---|
| ComfyUI (FLUX/Klein) | ⚠️ MPS 部分支持,部分自定义节点报错 | ✅ 完美支持,双卡并行 |
| IndexTTS-2 | ❌ 仅支持 CUDA | ✅ 原生支持 |
| vLLM | ⚠️ 已有 vLLM Metal 后端探索,但稳定性、模型覆盖和性能成熟度远不如 CUDA | ✅ 最成熟的生产级选择 |
| TensorRT-LLM | ❌ 仅支持 CUDA | ✅ 原生支持 |
| LoRA 微调 | ⚠️ MLX 框架支持部分模型 | ✅ 全面支持 |
CUDA 生态是双 4090 的隐形核弹。 不只是聊天推理,生图、语音、视频、微调训练——整个 AI 工具链都是为 CUDA 建的。Mac 上能用的工具不到 Linux 的三分之一。
vLLM 的 Metal 后端已经在路上(vLLM Metal 插件可让 Apple Silicon Mac 运行 vLLM),但距离 CUDA 版的稳定性和性能还有代差。
4. 综合对比
| 维度 | Mac Studio | 双 4090 | 胜出方 |
|---|---|---|---|
| 35B MoE 生成速度 | 45-75 t/s | 65-105 t/s | 4090 |
| 35B MoE 首字延迟 | 0.35-1.2s | 0.5-1.6s | Mac(差距小) |
| 70B Dense 生成速度 | 8-16 t/s | 25-45 t/s | 4090(碾压) |
| 70B + 128K 上下文 | ✅ 能跑 | ❌ 跑不了 | Mac(碾压) |
| 35B + 128K 上下文 | ✅ 从容 | ⚠️ 能跑但紧张 | Mac |
| CUDA 生态兼容 | 弱 | 完美 | 4090(碾压) |
| 满载功耗 | ~250W | ~1000W | Mac |
| 噪音 | 几乎无声 | 满载吹风机 | Mac |
| 部署难度 | 编译即用 | 装系统+驱动+调双卡 | Mac |
| 可升级性 | 焊死不可升级 | 可换卡加内存 | 4090 |
| 年电费(8h/天) | ~360 元 | ~1440 元 | Mac |
电费计算:按 0.5 元/度。双 4090 满载 1000W × 8h = 8 度/天 = 240 度/月 = 120 元/月 = 1440 元/年。Mac 250W × 8h = 2 度/天 = 60 度/月 = 30 元/月 = 360 元/年。一年电费差约 1080 元。
双 4090 赢了 3 局(生成速度、70B 速度、生态),Mac 赢了 5 局(延迟、长上下文、功耗、噪音、部署)。但权重不同——生成速度和生态的权重更高。
5. 踩坑实录
Mac 端的坑
坑 1:70B 的 10-16 t/s 是”能用”和”想用”之间的鸿沟
35B 跑 55-75 t/s 的时候你觉得 Mac 是真神,一换 70B 掉到 10-16 t/s 瞬间破防。文字生成的速度跟不上你切换 tab 的速度。等它生成的时候你早就去刷手机了。
坑 2:Metal MPS 框架还在追赶
Apple 的 MPS 每年都在进步,但跟 CUDA 十几年的积累比差距依然大。llama.cpp 的 Metal 后端能跑是因为 ggerganov 一个人肝出来的,不是 Apple 官方主推的。某些新特性(如动态 batch 优化、部分 attention 变体)Metal 版不支持或晚几个版本。
坑 3:192GB 焊死,终身不可升级
今天 192GB 够用,两年后呢?如果出了 200B 级别的模型,Q4 量化要 120GB,你依然塞得下。但要是 Apple 出了 384GB 版本的 M3 Ultra,你这台机器就永远差一档。
坑 4:内存压缩导致的系统卡顿
跑 70B Q4 + OpenWebUI + Chrome 几十个标签页,内存占用冲到 160GB+。macOS 的内存压缩机制介入,切窗口有延迟、打字有卡顿。跑大模型时关掉 Chrome 是唯一解。
Linux 双 4090 的坑
坑 1:双 4090 的物理尺寸是噩梦
4090 是三槽厚、34cm 长的巨无霸。两张插在一起需要 6 槽空间,大部分 ATX 机箱塞不下。我最后买了联力 120R 开放式机箱——没有侧板,所有硬件裸露。放在桌面上像一台外星飞船。
坑 2:双卡没有 NVLink,显存不能合并
两张 4090 之间没有 NVLink 桥接,显存不能合并成一个 48GB 池。llama.cpp 的 --tensor-split 1,1 是把模型按层切分到两张卡上,走 PCIe 通信。这意味着单层特别大的模型可能没法优雅切分,且 PCIe 带宽是瓶颈。
坑 3:驱动和 CUDA 版本的版本地狱
NVIDIA 550 驱动 + CUDA 12.6 + llama.cpp 某个 commit——这三个版本必须对齐,否则编译不过或运行时 segfault。每次升级 llama.cpp 都要重新确认兼容性。Mac 端更新个 Xcode CLT 就完事。
坑 4:70B + 长上下文随时 OOM
43GB 模型 + 16K 上下文的 KV cache 接近 48GB 上限。多开一个 Chrome 标签页占 1GB 显存,直接爆。跑 70B 时必须清掉所有 GPU 进程,包括桌面环境的 compositor。
6. 避坑指南:4 万块,到底往哪花?

选 Mac Studio,如果:
- 你的核心需求是 超长上下文(128K+)或 超大模型(120B+),容量优先
- 你在意 噪音和功耗,机器放在卧室/书房/办公室,不想听吹风机
- 你想要 开箱即用,不想折腾 Linux 驱动和双卡调优
- 你跑的主要是 35B 级别 MoE 模型,对极致生成速度的追求不强烈
- 你已经在 Apple 生态里,iPhone + iPad + Mac 联动是刚需
选双 4090 Linux,如果:
- 你要跑 70B Dense 模型 且要求流畅体验(30-45 t/s vs 10-16 t/s,差距巨大)
- 你需要 CUDA 生态(ComfyUI 生图、IndexTTS 语音、vLLM 部署、LoRA 微调)
- 你能接受 噪音和功耗,机器放机房/阳台/独立房间
- 你有 折腾能力(装 Ubuntu、调 NVIDIA 驱动、配双卡 tensor-split)
- 你看重 可升级性(未来换 5090、加内存、换 CPU,每一部分都能单独升级)
7. 观点:没有银弹,只有取舍
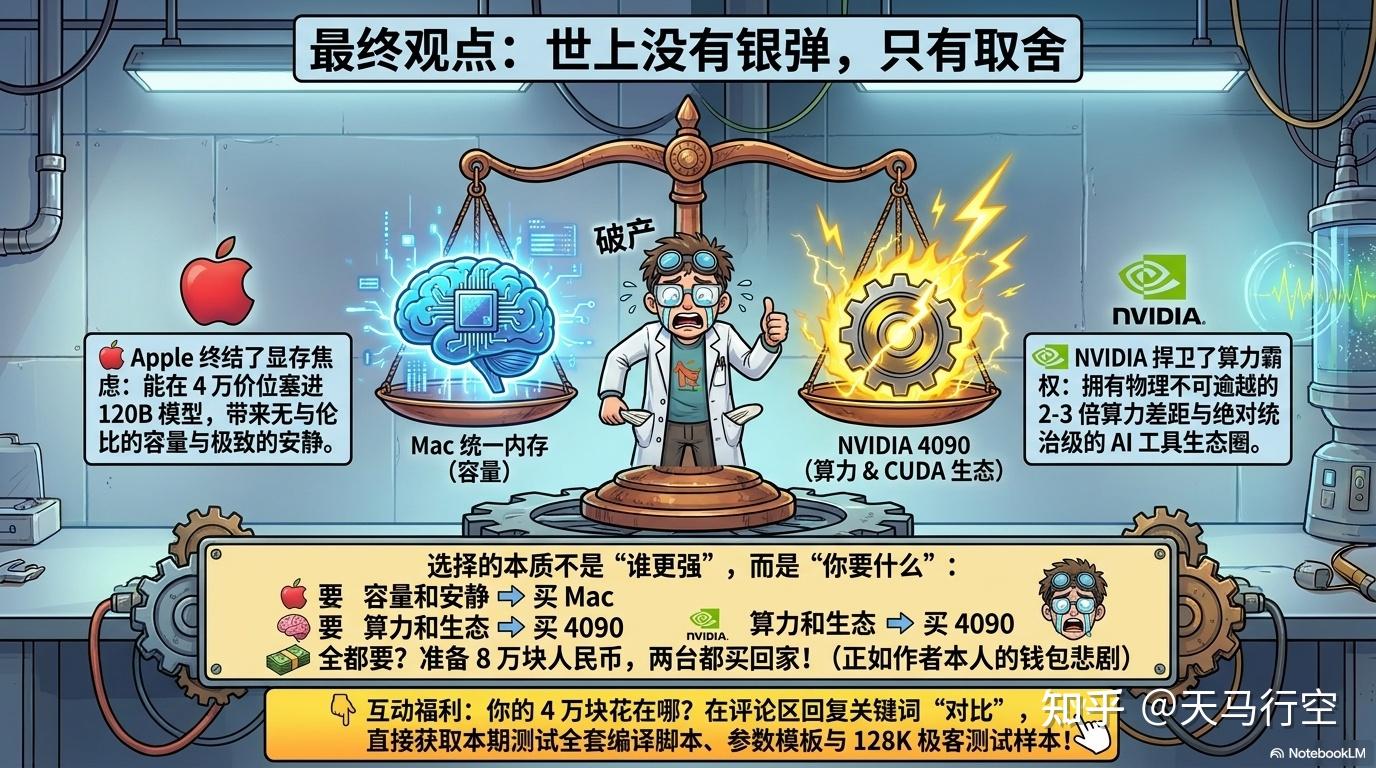
说几句可能两边都得罪的话。
Apple Silicon 在本地 AI 领域是真实的威胁,但不是对 CUDA 算力的威胁,而是对”显存焦虑”的终结。 192GB 统一内存解决了消费级用户最大的痛点——显存不够。你能把 120B 的模型塞进一台 4 万的机器里,这在 NVIDIA 的消费级产品线里做不到(双 4090 才 48GB,且不能池化)。这一点,Apple 赢了。
但 Apple 赢不了算力和生态。 双 4090 跑 70B 的速度是 Mac 的 2-3 倍,这不是优化能追回来的差距,是物理架构决定的——Tensor Core 的稀疏计算能力 MPS 目前追不上。更致命的是 CUDA 生态:整个 AI 工具链从推理到训练到生图到语音都是为 NVIDIA 建的。Metal 上的 llama.cpp 能跑已经是个工程奇迹,别指望 ComfyUI、vLLM、TensorRT 的完整功能都能移植。
所以最终的选择不是”谁更强”,而是”你要什么”。
- 你要 容量和安静,买 Mac。
- 你要 算力和生态,买 4090。
- 你想要 容量 + 算力 + 生态 全都要?抱歉,4 万不够,准备 8 万——Mac 一台 + Linux 一台。
我就是这样干的。两台都买,各跑各的场景。这不是极客的浪漫,这是钱包的悲剧。
你的 4 万块准备花在哪台机器上?
是买一台安静如鸡、192GB 统一内存的 Mac Studio 放在书房?还是自组一台双 4090 的 Linux 怪物扔进阳台?
评论区说说你的主要场景——你平时跑什么模型?最看重速度、容量还是生态?我在线帮你分析,不忽悠。
福利时间: 在评论区回复关键词”对比“,我整理了一份两台机器完整的 llama.cpp 编译脚本、启动参数配置模板、以及 128K 上下文测试用的长文本样本,直接拿走就能跑。
下期预告: 《OpenClaw + 本地 RAG 打造零云端 AI 数字员工》——不管你是 Mac 还是 Linux,这套方案都能接入你的本地模型,把过去三年的笔记变成 AI 的”第二大脑”。
作者:旅行者 标签:#MacStudio #RTX4090 #本地大模型 #AppleSilicon #CUDA #M2Ultra #Qwen3.6 #玩客笔记
关注「玩客笔记」,不站队,不吹票,只说真话。