24GB 显存能不能本地跑数字人?7900 XTX + LTX-2.3 同步音频实测
7900 XTX 本地跑数字人,到底能不能用?我拿 LTX-2.3 实打实测了 15 组带音频的
这两年数字人火得不行,但玩过的都知道,大部分方案都挺烦的:
要么得走云端,按分钟计费,传个音频都怕数据流出去; 要么就是闭源平台,素材全捏在别人服务器上,你想二次开发都没门; 再就是某些效果好的,对显卡的要求高得离谱,没块4090好像不配玩似的。
所以我就很想搞明白一个非常具体的问题:
一张 AMD 的 7900 XTX 24GB 显卡,能不能就在本地,跑出真正能用的数字人口播视频?
不是那种一张图随便动两下的玩具效果,也不是静帧头像上贴个音频波形,而是实打实地——给一张头像照片,再喂一段真人录音,让 LTX-2.3 生成嘴型跟着语音走、同时输出带同步音频的视频。
直白点说,就是看它能不能在本地做出“数字人张口说话”那味儿。
先不卖关子,结论我直接放在前头。
先说结论
这台搭载 7900 XTX 的机器,确实可以在本地跑通 LTX-2.3 的数字人同步音频视频。但并不是“想跑多长就跑多长”,也不是“768×1024 高清竖屏随便批量生成”那么美好。
准确点说:
- 640×640 / 10 秒:眼下最实用的长口播档位
- 544×960 / 7–8 秒:最合适做竖屏口播
- 768×768 / 7 秒:方形高清的上限了
- 768×1024 / 5–6 秒:高清竖屏的短视频还能撑住
- 768×1024 / 7 秒往上:别跟自己过不去,速度已经失去实用意义了
这次折腾下来我最大的感受是:
7900 XTX 不是跑不动,是得选对分辨率和时长。真正卡脖子的不是系统内存,而是采样速度。
假如你只是想做短视频口播、AI 博主开场、产品小介绍、课程片头或者付费文章的导流视频,这套方案真的可以进实用测试阶段了。可要是你打算批量出 10 秒以上的高清竖屏、嘴型还得稳如老狗,那要么继续打磨工作流,要么直接加钱上更大显存的卡。
我的机器配置
这次测试用的是我平时折腾 AI 的主力机:
| 项目 | 配置 |
|---|---|
| 系统 | Ubuntu 24.04 |
| CPU | Ryzen 7 3700X |
| GPU | AMD Radeon RX 7900 XTX 24GB |
| 内存 | 48GB + 4GB swap |
| ROCm | 7.2.4 |
| PyTorch | 2.11.0+rocm7.2 |
| ComfyUI | 本地部署 |
注意,这是 AMD 卡,不是 NVIDIA。现在好多视频生成模型的教程张口就是 CUDA,但我就是好奇,7900 XTX 这种 24GB 大显存的消费级 A 卡,在 ROCm 环境下到底能不能扛起本地数字人的活儿。
为啥我没直接跑官方那个 BF16 工作流?
懂行的可能会问,LTX-2.3 不是有官方工作流吗,直接拿来跑不就得了?
问题是,官方 BF16 方案吃显存吃得太猛了。LTX-2.3 的 22B 模型本身就很大,完整的 BF16 路线基本是冲着 32GB 甚至更高显存去的。我的 7900 XTX 就 24GB,多卡?ComfyUI 这种视频工作流可不会自动把两张 24GB 拼成 48GB 给你用。
所以这次我没头铁去硬啃原版 BF16,而是走了更接地气的低显存方案:
- 主视频模型:
LTX-2.3-22B-distilled-1.1-Q3_K_M.gguf - 文本模型:
gemma-3-12b-it-Q4_K_M.gguf - video VAE:
LTX23_video_vae_bf16.safetensors - audio VAE loader:
ltx-2.3-22b-distilled-fp8.safetensors - 输出节点:
VHS_VideoCombine
所以这里的结论不是“7900 XTX 能完整跑通 LTX-2.3 官方全量 BF16 工作流”,而是:在 24GB 显存 + 48GB 内存的本地环境下,用 GGUF/Q3 这种低显存工作流,能稳定跑出 5 到 10 秒的数字人带音频视频。 这个界限得先划清楚。
测试用的素材
为了控制变量,后面所有的测试我全用的同一张头像图,同一段音频。
- 图片:一张年轻男生正脸照,穿灰色卫衣
- 音频:一段大概 10 秒的真人说话录音
测试的时候就只动三个参数:分辨率、时长和对应的帧数。这样对比起来才清楚,不同分辨率和时长对速度、内存压力、稳定性的影响到底有多大。
第一阶段:竖屏摸底
我先拿竖屏比例开的刀。
1. 544×960 / 3 秒:只为了看链路通不通
第一把非常保守,纯粹验证整套流程能不能跑。
结果:
- 分辨率:544×960
- 时长:3.04 秒(24fps,73 帧)
- 输出:成功,MP4 带 AAC 48kHz 立体声音频流
这一轮确认了三件事:LTX-2.3 能吃进去头像和音频;生成出来的视频不是静帧,嘴型有变化;输出 MP4 里音频流确实在。也就是说,“头像 + 语音 → 数字人说话视频”这条路是走通的。
2. 544×960 / 5 秒:基础可用
第二次直接拉到 5 秒。
跑出来的结果:
- 时长:5.04 秒,121 帧
- 执行时间:206.58 秒
- 采样速度:大约 16.27 秒/次迭代(s/it)
这个可以算“基础可用了”,5 秒视频能正常生成,音频也顺利进了 MP4。
3. 768×1024 / 5 秒:高清竖屏也能撑
这次我把分辨率从 544×960 提到了 768×1024,别看数字好像只加了一点,像素数直接从 52 万多蹦到了 78 万多,差不多是 1.5 倍的压力。
实测:
- 时长:5.04 秒,121 帧
- 执行时间:291.16 秒
- 采样速度:约 26.46 s/it
- 内存最低可用:约 21.28 GiB,swap 峰值才 0.03 GiB
这轮特别说明问题。同样 5 秒,544×960 花了 206 秒,768×1024 花了 291 秒,慢了四成多。所以 768×1024 能当高清短视频档位用,但不能无脑拉长。
4. 768×1024 / 6 秒:快到实用天花板了
再往上拉到 6 秒看看。
- 时长:6.04 秒,145 帧
- 执行时间:368.11 秒
- 采样速度:约 34.82 s/it,最大单步耗时到了 35.53 秒
- 内存最低还有 18.95 GiB,swap 只有 0.05 GiB
能跑通,但真的接近我能接受的极限了。6 秒视频生成要 6 分钟,偶尔搞一条高质量片头还行,批量这么干肯定受不了。
5. 768×1024 / 7 秒:不是爆显存,是慢得没法用
想试一把 7 秒,结果中止了。
- 目标:7.04 秒,169 帧
- 中止原因:单步采样耗时直接飙到 50.60 秒,超过我设定的心理红线
- 此时内存还有 18.29 GiB 可用,swap 才 0.22 GiB,根本不是 OOM
这一次中止太有意义了。它证明瓶颈不是内存,而是速度。第一步就 50 多秒一次迭代,完全没法拿来日常出片。所以结论就是,768×1024 / 7 秒在当前工作流下,不适合实战。
第二阶段:测测方形画幅
竖屏摸完底,我又补了一波方形分辨率的测试。很多口播场景根本不需要全屏竖屏,比如 AI 博主头像口播、知识卡片、课程片头、产品小介绍、导流视频之类的,把数字人放在中间窗口,外面加标题、字幕、背景包装,方形画幅其实更实用。
方形 5 秒基线:640 / 768 / 896
先跑三组 5 秒看个底:
| 分辨率 | 时长 | 执行时间 | 平均 s/it | 最低内存 | swap |
|---|---|---|---|---|---|
| 640×640 | 5.04s | 172.08s | 12.71 | 27.86 GiB | 0.04 GiB |
| 768×768 | 5.04s | 226.11s | 18.33 | 23.43 GiB | 0.04 GiB |
| 896×896 | 5.04s | 290.14s | 25.98 | 21.74 GiB | 0.04 GiB |
这里面有几个有意思的发现。640×640 是当前跑得最快的档位,12.7 s/it,甚至比之前 544×960 的 16.3 s/it 还要快。896×896 的像素量跟 768×1024 很接近,速度也就差不多 26 s/it 左右。方形 letterbox 这条路完全走得通,不用改工作流的裁剪逻辑。
拉长时长看看
基线跑完,我就继续试试这些方形和竖屏分辨率在更长时长下的表现。
640×640:8 秒、10 秒全成功
| 项目 | 8.04 秒 | 10.04 秒 |
|---|---|---|
| 帧数 | 194 | 242 |
| 执行时间 | 240.12 秒 | 290.14 秒 |
| 平均 s/it | 20.18 | 25.99 |
| 最低内存 | 23.02 GiB | 21.63 GiB |
| swap | 0.04 GiB | 0.04 GiB |
这个结果对我鼓舞很大。640×640 跑 10 秒都稳住了,而且速度还在 26 s/it 左右。这意味着它真能当主力档位用。假如我要做一条 60 秒的数字人视频,不用傻到一次生成 60 秒,拆成 6 段 × 10 秒来跑,后期拼起来就行。
768×768:7 秒可以,10 秒跪了
| 项目 | 7.04 秒 | 10.04 秒 |
|---|---|---|
| 帧数 | 170 | 242 |
| 执行时间 | 302.15 秒 | 中断 (122秒) |
| 平均 s/it | 26.62 | 50.10 (第一步) |
| swap | 0.05 GiB | 0.06 GiB |
768×768 跑 7 秒没问题,速度跟 640×640 跑 10 秒差不多。但拉到 10 秒第一步就 50 s/it,直接撞红线。所以 768×768 更适合做那种 5 到 7 秒的高清头像短句,比如视频开头一句话、个人 IP 介绍、课程片头,长口播还是算了。
544×960:7 秒、8 秒、10 秒都能跑
| 项目 | 7.04 秒 | 8.04 秒 | 10.04 秒 |
|---|---|---|---|
| 帧数 | 170 | 194 | 242 |
| 执行时间 | 264.13 秒 | 298.16 秒 | 442.24 秒 |
| 平均 s/it | 22.98 | 26.73 | 43.75 |
| 最低内存 | 22.39 GiB | 21.46 GiB | 15.32 GiB |
| swap | 0.06 GiB | 0.06 GiB | 0.06 GiB |
这么一看,544×960 比 768×1024 更适合做竖屏长一点的口播。同样 7 秒,768×1024 直接 50 s/it 中止了,544×960 才 23 s/it 顺利跑完。如果你需要竖屏口播,记住先选 544×960 7 到 8 秒,偶尔需要更长的可以试试 10 秒,但那会儿 43.8 s/it 的速度已经快到我忍耐极限了,不适合大批量搞。
最终测试矩阵一览
前前后后总共跑了 15 项有效测试,汇总一下:
| 分辨率 | 5s | 7s | 8s | 10s | 可用上限 |
|---|---|---|---|---|---|
| 640×640 | 成功,12.7s/it | — | 成功,20.2s/it | 成功,26.0s/it | 10s 很稳 |
| 768×768 | 成功,18.3s/it | 成功,26.6s/it | — | 中止,50.1s/it | 7s 稳 |
| 896×896 | 成功,26.0s/it | 未测 | — | — | 只建议 5s |
| 544×960 | 成功,16.3s/it | 成功,23.0s/it | 成功,26.7s/it | 成功,43.8s/it | 10s 能跑 |
| 768×1024 | 成功,26.5s/it | 中止,50.6s/it | — | — | 6s 稳 |
从这个表能很直观地看出来:方形长口播就选 640×640;方形高清短句用 768×768;竖屏口播别一上来就冲 768×1024,544×960 的实用性好得多;高清竖屏 768×1024 只能做 5-6 秒的短镜头;896×896 拉长了压力跟 768×1024 差不多,5 秒内玩玩还行。
真正的瓶颈到底在哪?
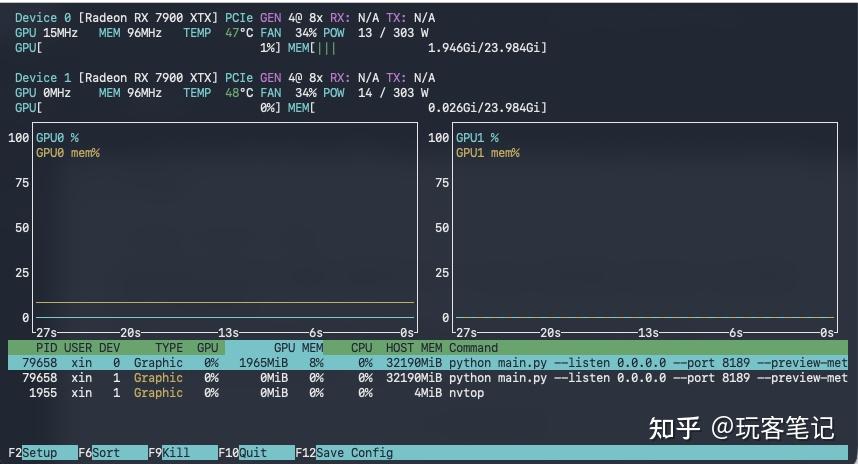
测了这么多,我得出了一个非常明确的结论:瓶颈真不是系统内存。 整个测试过程中 swap 的使用量都非常低,哪怕是 544×960 跑 10 秒,swap 峰值也就 0.06 GiB。我加到 48GB 内存是对的,系统没掉进 swap 地狱。
真正让人头疼的是采样速度。我按照自己的感受,把速度分了几档:
- 30 s/it 以下:绿色档,能日常用
- 30–40 s/it:黄色档,能用但开始慢了
- 40–50 s/it:红色档,只能偶尔测试,别当主力
- 50 s/it 以上:别跑了,太遭罪
按这个标准一套,640×640 10 秒、544×960 8 秒、768×768 7 秒这些都还在绿色或黄绿色区域。544×960 10 秒就摸到红色档边缘了,768×1024 7 秒直接拉倒。这比简单说“能不能跑”更有实际指导意义,因为本地跑 AI 不是一次性玩具,得反复用、稳定出片才行。
别总想一口气出长片,拼接才是王道
测完我最大的体会是:用 7900 XTX 玩 LTX-2.3 数字人,最现实的路线根本不是一次生成一整条高清长视频,而是生成一堆 5 到 10 秒的口播片段,然后再进剪辑软件包装成完整短视频。
我推荐的流程大概是:
- 写出 45 到 60 秒的口播稿子
- 按句子语义切成 5–10 秒的短句
- 每一句单独生成数字人视频片段
- 后期统包成 1080×1920 竖屏
- 加上标题、字幕、BGM、背景和转场
- 输出最终成片
举个例子,一条 50 秒的视频可以这样拆:
- 开场钩子:768×1024 / 5 秒
- 痛点说明:544×960 / 8 秒
- 测试结论:544×960 / 8 秒
- 参数展示:640×640 / 10 秒
- 使用建议:640×640 / 10 秒
- 结尾引导:768×768 / 5 秒
这样每段生成时间都不会失控,画质也有保障。
现在我会怎么选参数
如果你也想试试,我的建议很直接:
1. 速度最快、批量做长口播 就用 640×640 / 8–10 秒。适合 AI 博主口播、模型评测、博客导流、课程讲解、产品介绍这些。这是我现在最常用的主力档。
2. 竖屏口播性价比 选 544×960 / 7–8 秒。适合抖音、小红书、YouTube Shorts 那种竖屏口播,比 768×1024 实用得多。
3. 方形高清短视频 768×768 / 5–7 秒,做头像口播、课程片头、品牌介绍、高质量开场刚好。
4. 高清竖屏短镜头 768×1024 / 5–6 秒,适合视频开头、高质量展示、重点镜头、样片,别拿它做长口播。
5. 这些组合我建议绕开
768×768 / 10 秒768×1024 / 7 秒以上896×896 / 6 秒以上544×960 / 10 秒批量生成
不是说完全不能跑,而是时间成本高得划不来,日常出片耗不起。
这次测试的局限
得老实说,这次测试也有不完美的地方。
第一,我没跑官方 BF16 工作流,用的是 GGUF/Q3 低显存方案,所以结论不代表官方原版满血方案的表现。
第二,我只测了一张头像、一段音频。后面还得试试不同的性别声音、中英文、快慢语速、明显停顿、真人头像/3D 头像/卡通头像,还有戴眼镜、胡子、侧脸这些复杂情况。
第三,最终成片还得依赖后期包装,LTX 出来的只是数字人片段,不是直接能发的短视频,标题字幕背景那些活儿一样不少。
这套方案适合谁?
我觉得几类人挺适合:
- 本地 AI 玩家:手里有 7900 XTX、4090、3090、A6000 这种大显存卡,愿意动手搭工作流的
- AI 博主、教程作者:用它生成自己的数字人开场,做模型评测、教程导流、课程片头
- 在意数据本地化的人:不想把头像、声音素材传到任何云端平台
- 有自动化想法的人:如果愿意搭个本地 Agent,把音频切片、调用 ComfyUI、生成预览图、拼合视频自动化,这套方案价值会更大
不适合谁?
也得说实话,如果你想要的是:
- 一键出 1 分钟完整数字人视频
- 直接就是 1080×1920 全屏高清口播
- 唇形百分百逼真
- 商业级的真人分身效果
- 完全不想折腾环境、不想管节点工作流,只想开个网页点一下生成
那本地方案 LTX-2.3 对你来说还不够省心。目前云端数字人平台在这些诉求上还是方便得多。本地方案的优势本来就不是“省事”,而是可控、可折腾、可自动化,而且所有数据都留在自己手里。
最后再啰嗦几句
这一圈测下来,我对 7900 XTX 跑本地数字人的判断挺清楚了。
第一,7900 XTX 24GB 确实能在本地跑通 LTX-2.3 数字人同步音频,已经跑出了好几组带嘴型变化和音频流的 MP4。
第二,最实用的策略不是硬刚高清长视频,而是短片段拼接。768×1024 只适合 5-6 秒的高清短镜头,日常出片更舒服的参数是 640×640 10 秒和 544×960 7–8 秒。
第三,系统内存不是主要瓶颈,48GB 完全够用,swap 压力很低,真正拖慢节奏的是采样速度。
本地数字人已经能进入实用测试,做短视频开场、口播、片头绰绰有余。我的定位很简单:就是在本地生成 5-10 秒的口播片段,再自动化包装成片,不替代云平台,但数据在手里,可玩性更高。