MacBook Pro M5 Max 128G 性能测试
05/14 更新 ===============================================
现在主力使用配置是:
模型:DeepSeek v4 Flash q2-q4 iMartix
引擎:antirez/ds4
Harness:ClaudeCode
参见:antirez d4s Deepseek V4 Flash项目评测
下面是最开始四月初原文,模型和框架都过时了,一个月沧海桑田,大家参考相对性能就好。
=== 早期分割线 ============================================
4/2入手后测试好几个模型架构,最后使用oMLX比较简洁,而且内置基准测试。
(第二版:基本把大家关心的和适合这个配置的八种测试了)
先给结论:
M5 Max 128G这种大统一内存的Apple架构适合运行中等体积的MOE模型最能发挥优势,例如122B或更高精度的Q8。而密度模型因为内存带宽限制相比4090/5090没有明显优势,大致一个水平。
在128G统一内存下有效的本地模型是:
Qwen 3.5 122B 4bit 这是智能和性能综合起来最好的
gemma 4 26B 8bit 这是目前智能和性能综合起来第二好
测试这八个模型的特点是:
1 在M5下速度在30-130t/s,基本达到API水平。 有些dense模型太慢,不在这里。
2 精度尽量利用机器能力,能Q8的不Q4。太小的4B9B之类不能充分利用机器性能放弃。
一、 基准测试 (Benchmark) 结果对比
下表汇总了各模型在 MMLU、TruthfulQA 和 HumanEval 三个基准上的表现。
| 模型 (Model) | MMLU 准确率 | TruthfulQA 准确率 | HumanEval 准确率 | 总耗时 (秒) |
|---|---|---|---|---|
| Qwen3.5-35B-A3B-4bit | 81.0% | 84.9% | 89.0% | 904.6 |
| Qwen3.5-35B-A3B-8bit | 83.4% | 86.4% | 89.6% | 1025.7 |
| Qwen3.5-27B-4bit | 86.4% | 88.5% | 93.9% | 2612.6 |
| Qwen3.5-122B-A10B-4bit | 88.1% | 90.0% | 89.6% | 2099.5 |
| Qwen3-Coder-Next-MLX-8bit | 83.2% | 87.3% | 89.6% | 1340.6 |
| gemma-4-26b-a4b-it-8bit | 83.9% | 85.4% | 97.0% | 1244.0 |
| gemma-4-31b-it-4bit | 86.1% | 88.9% | 95.7% | 2912.8 |
| NVIDIA-Nemotron-3-Super-120B-A12B-MLX-4.5bit | 77.8% | 84.5% | 90.8% | 1967.1 |
注: HumanEval 总数为 164 题,MMLU 为 1000 题,TruthfulQA 为 817 题。总耗时是完成这三项测试的时间之和。
二、 推理性能 (Inference Performance) 结果对比
下表汇总了各模型在标准测试 pp1024/tg128(输入1024个token,生成128个token)下的单请求表现,以及在批处理 (Batch=4) 时的吞吐量提升情况。
| 模型 (Model) | 单请求 E2E 耗时 (s) | 单请求生成速度 (tg TPS) | 单请求峰值显存 (GB) | Batch=4 生成速度 (tg TPS) | Batch=4 吞吐量提升倍数 |
|---|---|---|---|---|---|
| Qwen3.5-35B-A3B-4bit | 1.357 | 139.7 | 19.25 | 334.8 | 2.40x |
| Qwen3.5-35B-A3B-8bit | 1.746 | 101.7 | 35.36 | 249.1 | 2.45x |
| Qwen3.5-27B-4bit | 5.163 | 33.1 | 15.85 | 79.1 | 2.39x |
| Qwen3.5-122B-A10B-4bit | 2.871 | 66.5 | 65.59 | 138.4 | 2.08x |
| Qwen3-Coder-Next-MLX-8bit | 2.143 | 79.3 | 80.13 | 180.7 | 2.28x |
| gemma-4-26b-a4b-it-8bit | 1.961 | 86.5 | 25.73 | 179.2 | 2.07x |
| gemma-4-31b-it-4bit | 6.321 | 26.7 | 17.56 | 54.0 | 2.02x |
| NVIDIA-Nemotron-3-Super-120B-A12B-MLX-4.5bit | 3.562 | 60.3 | 68.54 | 116.1 | 1.93x |
三、 综合分析与结论
1. 准确率与模型规模、架构的关系
- 绝对王者:
Qwen3.5-122B-A10B-4bit在 MMLU (88.1%) 和 TruthfulQA (90.0%) 这两项考验知识和真实性的测试中均位列第一,展现了其作为百亿级稀疏 MoE 模型的强大知识容量。 - 代码生成专精:
gemma-4-26b-a4b-it-8bit在 HumanEval 上以 97.0% 的惊人成绩夺冠。这表明 Gemma 4 架构或其特定的训练数据在代码生成任务上具有非常明显的优势。 - 均衡全能选手:
Qwen3.5-27B-4bit和gemma-4-31b-it-4bit在三个测试集上均表现优异,位列第二梯队,是综合能力的佼佼者,非常适合通用场景。 - 量化对准确率的影响:对比
Qwen3.5-35B-A3B的两个版本,8bit 量化的准确率全面领先 4bit 版本(MMLU +2.4%, TruthfulQA +1.5%)。这说明对于同一个模型,更高的量化精度能更好地保留模型能力,但代价是推理速度变慢(E2E 从 1.357s 增加到 1.746s)。 - 表现异常:
NVIDIA-Nemotron-3-Super-120B-A12B尽管参数量巨大,但在 MMLU 上的表现却垫底(77.8%)。这可能与模型训练数据分布、MLX 转换过程的适配程度或基准测试的评估方式有关,表明参数规模大并不绝对等于知识准确率高。
2. 推理速度与成本(显存)的权衡
- 速度之王:
Qwen3.5-35B-A3B-4bit是无可争议的推理速度冠军。其单请求生成速度(139.7 TPS)比第二快的模型快 60%,且端到端延迟最低(1.357s)。这得益于其 MoE 架构(每次推理仅激活部分参数)和激进的 4bit 量化。 - 显存友好型冠军:
Qwen3.5-27B-4bit和gemma-4-31b-it-4bit的峰值显存占用仅为 15.85GB 和 17.56GB。这意味着它们可以轻松运行在消费级的 24GB 显存显卡(如 RTX 4090)上,同时还能保留强劲的综合能力,是个人开发者和预算有限场景的理想选择。 - MoE 的批处理劣势:观察 "Batch=4 吞吐量提升倍数",两个参数量较大的 MoE 模型(
Qwen3.5-122B-A10B-4bit和NVIDIA-Nemotron)的倍数明显低于其他模型。这是因为 MoE 模型在批处理时,不同请求可能激活不同的专家网络,导致计算访存模式更加复杂,显存带宽压力骤增,从而降低了并行效率。 - Gemma 4 的架构优势:
gemma-4-26b-a4b-it-8bit展现出了很好的综合性能。它在保持较快生成速度(86.5 TPS)和较低显存占用(25.7GB)的同时,取得了最高的 HumanEval 分数,是性能和效率平衡的典范。
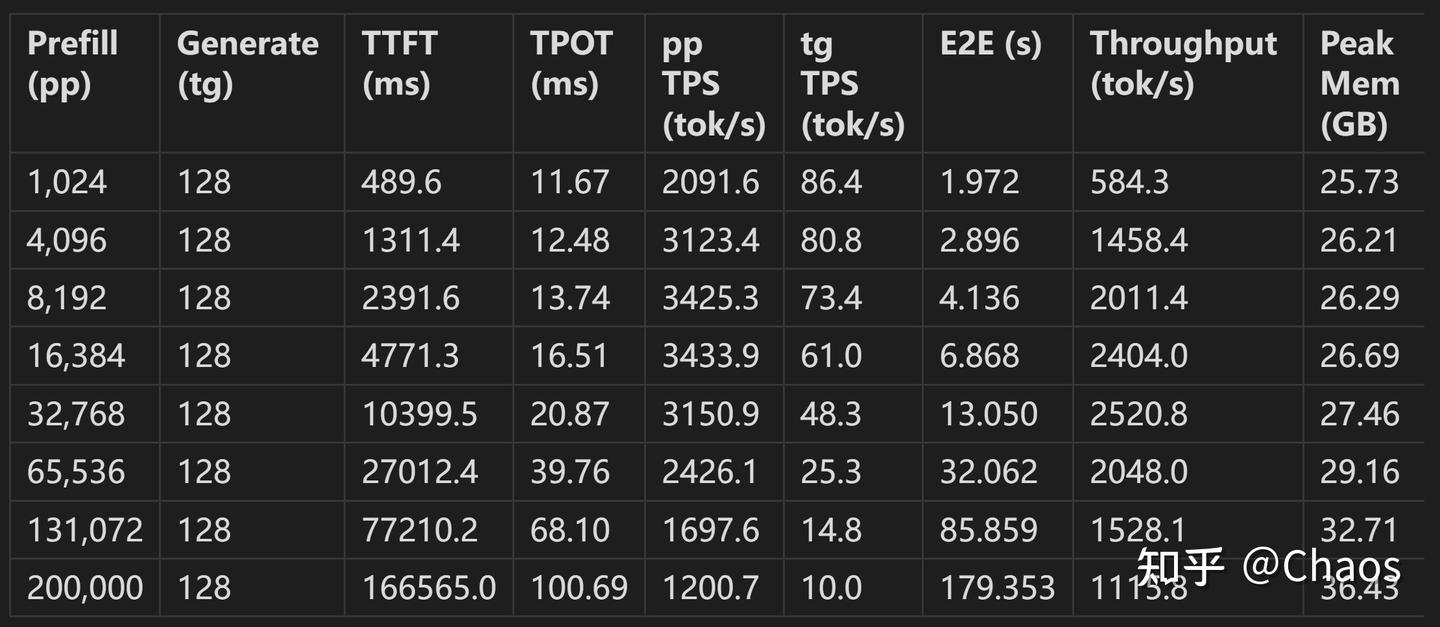
四、上下文长度敏感性测试结果 Gemma-4-26b-A4B-IT-8bit为例
上面的上下文1024推理速度只有模型间相互比较价值,真正有价值的是实际发生的上下文长度时候的速度,agent时代一般是32-64-128K这个区间。在上下文长度增长的时候速度大幅度下降,KV缓存大幅度增长,这才是高带宽大显存发挥作用的时候。
五、密度模型的问题
Mac架构目前受限于内存带宽限制,在dense模型上表现完全没有惊喜。例如gemma 31B号称很强,但是充分发挥精度的bf16只能达到7t/s,8bit达到15t/s,没有实用价值。4bit达到25t/s,基本和在4090上差不多,毕竟4090有1T的带宽。
经过计算目前M5 Max 128G的内存带宽是614G,利用率应该是达到73%,实测450G/s。导致31B密度模型8bit是15t/s,这就是带宽限制。如果M5 Ultra出来天价内存带宽达到1500G/s,8bit能达到40t/s。能用,但是不能太高期望。
总结:
如果你有本地资料需要处理,那么这机器是可以入的,已经达到可以初步干活的门槛。用它来处理obsidian里的文档工作速度完全可以接受。而且你也没啥选择,这性能已经是目前笔记本能提供的极限了。单模型对比,甚至超过之前王者M3 Ultra。M5 Ultra出来也只是装更大一些的模型,速度不会本质提高。
现在的限制最大其实是大模型厂商的良心,其实在这个算力的机器上完全已经可能释放出具有生产力的中等模型了,就看大厂愿意不愿意了。说实话,如果愿意收费卖,我也愿意买的。如果传说的gemma 124B出来应该将是近期的王者,最适合128G,不过感觉google不会便宜大家,除非Qwen3.6出新的120B再强压一头,刺激google。
至于国产御三家GLM、Kimi、Maxmini原则上是开源模型但不提供中小高可用性版本,其实很难被个人利用。它们应该能用6月份发布的MacStudio 256G/512G跑起来,不过那个成本就高多了,现在M3Ultra512G价格都上天了,M5Ultra512G更不知道哪里去了。
最后虽然没那么之前期待的惊喜提高,但是回头对比手头原有4090卡的数据,总体上很有优势的,在选择模型上有了更大的空间。
=======================================================
后记:很高兴买了这个机器 M5 max 128G + omlx + Hermes + Gemma 26 Q8。基本可以本地满足我80%的要求,处理各种本地事物和讨论问题。除了要求特别高的代码事务。