
聊聊NVidia的六件套
最近CES老黄发布了一堆东西,虽然CPU、GPU、NIC这些老生常谈的东西已经在过去一年反反复复发布过好几次了,不过这次整体讲了一个从聚焦单芯片,到6颗芯片整体系统的故事。具体参数、包括6个芯片的角色和协同已经被Gemini大爹整理得很好,各种解读满天飞了。
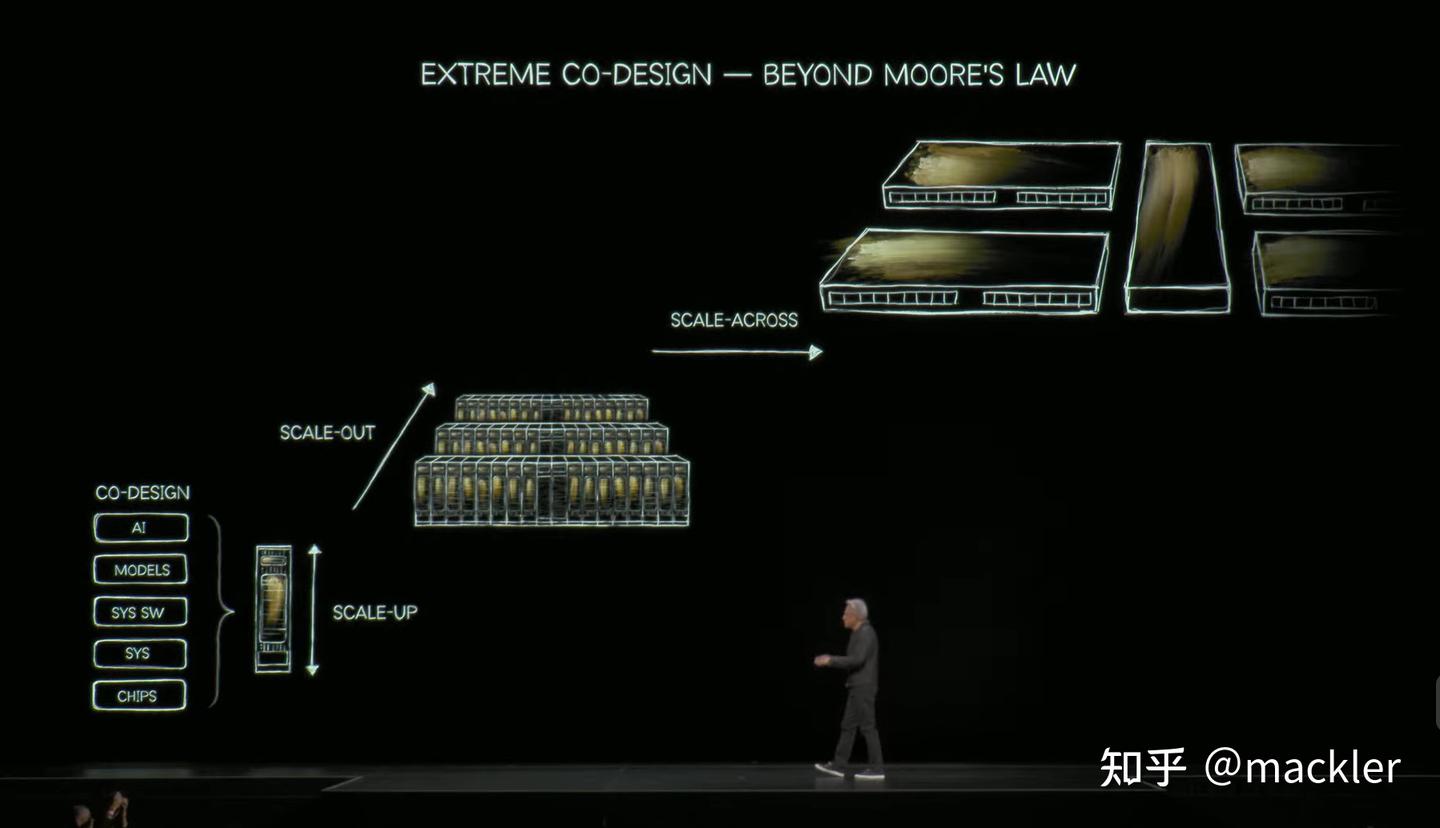
这6件套里面除了CPU和GPU这种标品,剩下的都是关于互联。互联里面NVLink不说了,主要是关于NV自己GPU之间的Scale-Up高带宽的,ConnectX则是用于GPU之间Scale-Out互联的。
DPU是这次讨论最多的,按照之前DPU的定义,是用于卸载CPU负载,提高云CPU利用率的。把CPU容器化的管理负载从CPU上卸载到DPU上,从而使得宝贵的CPU核可以100%用于售卖。这次老黄倒是讲了一个全新的故事,仍然符合DPU叙事的基石:卸载CPU负载。只不过在大模型推理时代找到了新的需要卸载的部分,KVCache的搬运。因为KVCache的管理从kimi的mooncake系统设计时候就进行了HBM、DDR、SSD三个层级的缓存设计和基于NIC的搬运。

这个DPU实际上是Vera上一代的Grace CPU加上ConnectX-9 NIC组合的,再搭配SSD组了一个Storage Server,并取了个高大上的“Context Memory Storage Platform”。
先不论这个方案本身价值几何,在NV的视角下,网络方案也在逐渐复杂化,大致可以分成以下几个:
- GPU之间的互联
- Scale-Up用NVLink:推高带宽匹配单GPU不断提高的算力,推高互联规模提高紧耦合显存规模。
- Scale-Out用ConnectX NIC:保持大规模组网能力的基础上,持续推高带宽。
- CPU之间的互联:DPU,卸载CPU侧涉及数据搬运的工作
进一步看,GPU之间的互联需求在AI时代很好理解,抛开KVCache这一具体的实现,从更长期看CPU之间加剧系统复杂化的价值基础又是什么呢?
是HBM、DDR、NAND的价值差。
一切的起点在于GPU的高算力是AI时代价值分配的基础,而GPU的高算力需要搭配高带宽高价值的HBM,那么所有发生在GPU上的显存利用、GPU上的计算、GPU之间的通信(NVLink + NIC)都是优化好的高性能计算pattern,包括极致的kernel、极致的nccl通信算子、多卡多机并行策略,都是HPC的极致。HBM是这部分高价值计算的载体,很强也很贵。
推理相比训练,最大的区别在于:训练是个单体任务,可以完全用HPC的做事方式解决。但推理是个服务,需要用分布式系统的思路,一切不确定性的请求压力(短时间的请求数量波动)、请求规模(上下文长度)、请求类型的波动(多轮对话、agent、多模态),都需要用分布式disaggregated的方式提供足够的弹性和冗余,而相应的基础是便宜且量大管饱。
而DDR和NAND相比GPU的价值差,CPU相比GPU的价值差,以及DPU相比CPU的价值差,都成为了弹性和冗余的基础,因为你不能拿金子一样贵的HBM和GPU机时来维持弹性。所以冗余的DDR和NAND就成了量大管饱的冗余载体,靠分布式系统的设计思路,把所有请求前期不确定性的部分都准备成HPC核心部分(GPU+HBM+NVLink+NIC)最友好的形态(例如立刻要参与计算的KVCache已经传输到当前节点的CPU上,甚至传递到GPU显存上了)。
当然上面这些技术细节我觉得永远是仁者见仁,智者见智。谈论这些技术的合理性、不合理性,都是为了追求技术上的名正言顺。我今天更多想借着这个从单芯片到6芯片系统的叙事逻辑变化,聊一聊NV的变化。
一个“屠龙少年”终成“恶龙”的变化。
NV已经度过了争夺计算机产业CPU Centric的阶段(“屠龙“阶段),计算机产业90%的蛋糕和价值都在它肚子里了。所以NV怎么增长?
- 去标准化,把GPU之外的其他模块替换成自己的。我们看到了Grace CPU、Vera CPU,也看到了ConnectX NIC、Spectrum Switch。
- 增加系统的复杂性,让用户在计算机系统中买更多组件。我们看到了六件套,看到了一个互联搞出一堆方案,包括之前Rubin GPU也分出了CPX转门做Prefill。
所以NV现在越来越多讲Hardware-Software Extremely Co-design,最好能根据Infra的形状拆解成每个Infra的组件一种单独的硬件,全面异构化。
当然你说实际上需要不需要这么异构,有些可能需要,有些可能实际上不需要。比如Grace CPU一定比x86好么,不见得。NV强推了几年GB200,市场还是倒逼出了B200、B300,但NV肯定还是会持续不断的推。DPU也是一样的,两年前业界就用x86 + NIC + SSD搭建了KVCache的分布式系统,过去一年也基本成为业界标配方案,扩展性兼容性也都足够好。
说到底,核心目的还是要在GPU之外扩展更多的高溢价的产品,异构非标肯定是最适合的路径。解读来解读去,无非是讲究一个技术上的名正言顺。Hardware-Software Extremely Co-design往正面讲,是推动超摩尔定律的技术手段,往另一个角度讲,也是在系统里放更多co-design引入的心硬件。当然水面上这些无论业界有怎样的争议,搬到发布会上讲的,总归还是会搭配技术上的叙事的。
发布会上没有讲的,还有推动ddr去标准化。例如整个GB200的方案里没有一颗标准的DDR内存条,如果能把内存非标化,那又是一个巨大的蛋糕。Grace、Vera CPU支持标准内存很困难吗?显然不是,但CPU本身控制着内存的标准。LPDDR相比标准DIMM条有巨大优势吗?NV进一步推动的用LPDDR打造的SOCAMM相比标准DIMM条有优势吗?但是更贵,而且未来要用NV的东西大概率得搭配着这些东西用才能拿到最不拧巴的性能。

如果不去标准化,这部分市场的利润分成是不会经过NV的,非标才有分成的空间。NAND也是一个潜在市场,如果DPU的NAND成为主流,保不准下一步就是非标的NAND。
只是这几个东西暂时找不到腾笼换鸟在技术上比较大的名正言顺,就先水下慢慢搞了。
非标的另一个好处是可以制造很多系统瓶颈来推动更多有利于NV的Extremely Co-Design,如果系统的自由度下降了,那么NV想推什么都可以先创造问题,所有的需求和瓶颈在系统级都是可以被设计出来的。其实NV的异构方案很多人诟病的一点就是系统太死板了,缺少弹性。性能虽然好,但又贵又缺少组合性,业务需求变化了怎么办?
从Infra的角度,硬件的自由度才是最大的Co-Design空间。
系统领域不缺聪明的脑袋,开放、廉价的硬件能够自由组合搭配,创新的速度将大幅度提升。这里面可以迸发出的Co-Design空间要远远超过一个封闭系统贴合应用需求的调整。
今天硬件系统的自由度源于x86奠定的开放体系,一颗CPU也就是从几百到几万的价格,但可以支持从单路到双路甚至四路的不同组合,内存也可以支持从1根到32根随意挑选,PCIe通道可以支持到上百lane随意组合各类硬件。虽然Intel已经半个身子入土了,但整个x86体系遗留的开放性还是拴住NV持续推动非标硬件的一个枷锁。
其实今天真正要提高硬件大模型基础设施的能力,恰恰不是做越来越多昂贵的异构组件,而是反过来尽可能拆掉一切不必要的组件。而不是反过来增加更多异构组件让用户买更多“技术上看起来合理”的东西,最后制造出全球性的ROI问题和泡沫化最严重的AI基础设施。