ai时代买不是独显的电脑还有意义吗?
说明你不了解AI大模型。
显存大小决定了你能跑多大的模型。
显存带宽大小决定了你跑模型有多快。
当然,你不在乎速度,你用CPU+内存都能硬跑。
CPU多则几十个核心,128bit双通道内存带宽约为128GB/s。
GPU普遍有数千甚至上万个核心,高端GPU显存带宽能接近1000GB/s。
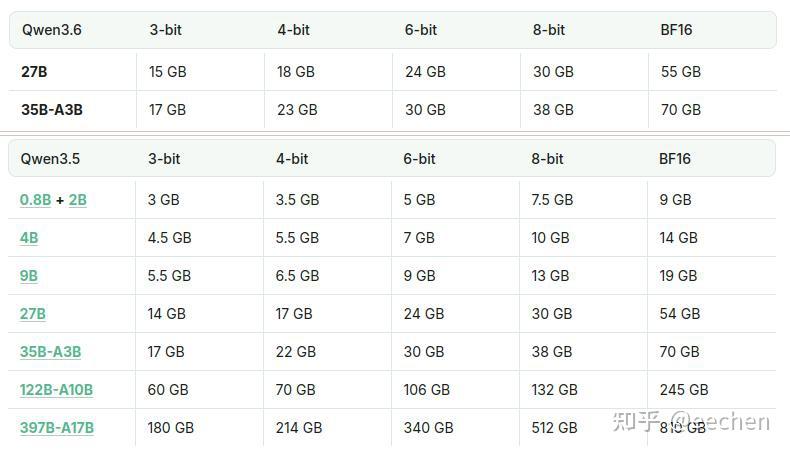
现在的甜点显卡,普遍都是8GB显存,看看上图unsloth量化的Qwen模型,勉强能跑4位量化的Qwen 3.5 9B模型,而且对话上下文(KV Cache)还不能设置得太大,大一点爆了显存,那就得offload到CPU内存,连接GPU和CPU的PCIe通道带宽,跟显存带宽比起来,夸张点说,就是音速和光速的差距,尤其是稠密模型,推理时每生成一个token都需要从显存完整遍历一遍模型的所有权重到计算核心,一旦触发CPU offload,速度会大幅下降。
爆显存的情况下,独显推理的性能还不如采用统一内存的核显快。
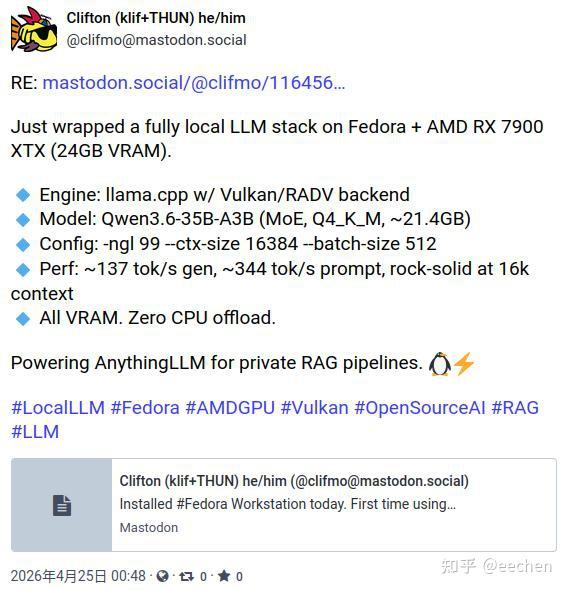
就拿AMD的AI Max+系列APU来说,采用四通道256bit统一内存,带宽达到256 GB/s,虽然只有独显显存带宽的一半,但不会发生CPU offload走PCIe,所以推理速度并不慢,AMD 395处理器8060S核显(2560个核心)跑Qwen3.6-35B-A3B-Q4_K_M这个4位量化的MoE模型,生成速度也能达到60+ tok/s,完全可用。这个速度你拿16GB显存960GB/s带宽的5080都不一定跑得出来,更别提5060这种8GB显存448GB/s带宽的甜点卡了。
AMD预计2027年推出的下一代Halo核显方案——Medusa Halo更值得期待:
- 内存位宽从256bit提升到384bit,内存带宽至少提升50%。
- GPU计算单元从40CU提升到48CU(3072个核心),算力至少提升20%,并采用新架构RDNA5(又名UDNA,支持FP8格式和FSR4超分)。
- CPU架构则从Zen5(4nm)升级到Zen6(2nm),采用台积电2nm工艺,也会有实际的性能和能效提升。
除了统一内存核显本,想更快地跑本地模型,如果你能搞到一张32GB的显卡也是不错的,不过价格普遍过万,比如AMD的专业卡Radeon AI Pro R9700(国内售价1万出头),采用跟游戏卡9070XT一模一样的核心,只因显存增加到了32GB,价格就贵了1倍多,这卡如果卖6500的价位(跟5070Ti一个价位),那真有可能成为爆款。至于Nvidia的5090,那就更贵了,而且国内还买不到32GB版本的5090。
预算不够,那就只能看看24GB显存的A卡7900XTX和N卡4090,这两张卡也能把最新的Qwen3.6的27B和35B-A3B这两个开源模型跑起来。至于Qwen开源的122B和397B这些大模型,普通人本地部署不现实,看看就好。
PS:
我比较抠,9K预算买了32GB统一内存双通道的365处理器880M核显本外接16GB显存640GB/s带宽游戏卡RX9070,打算本地用llama.cpp(Vulkan后端)跑跑8位量化的Dense模型Qwen3.5-9B和4位量化的MoE模型Qwen3.6-35B-A3B(这个35B模型能理解并重写混淆后的PHP代码,智商还是相当在线的)。不在乎性价比的话,完全可以64GB统一内存四通道的395处理器8060S核显本外接32GB显存专业卡R9700。

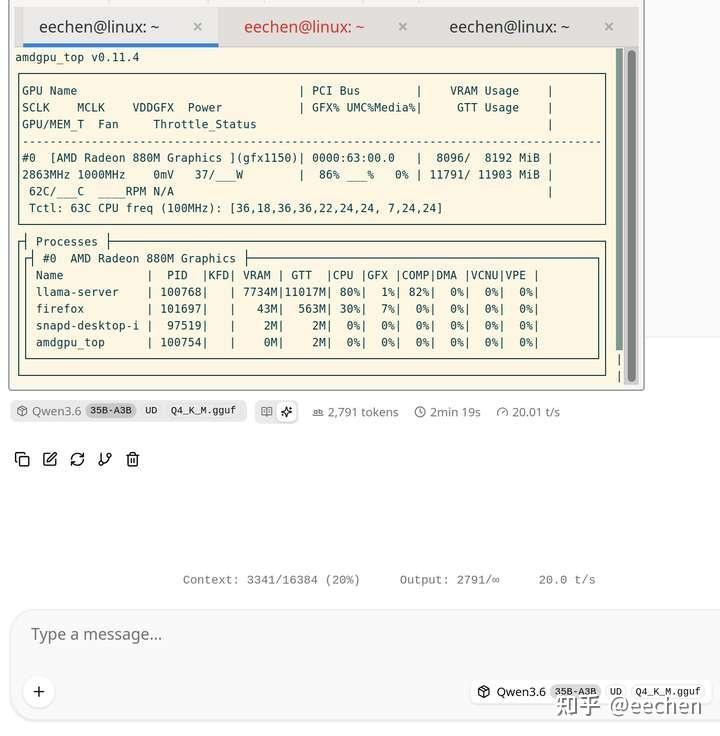
只用365处理器880M核显跑Qwen3.6-35B-A3B-Q4_K_M,速度可达20 tok/s,属于可用的水平,关键是APU功率仅为37W,CPU占用率仅为0.8个核心,能效比相当不错。
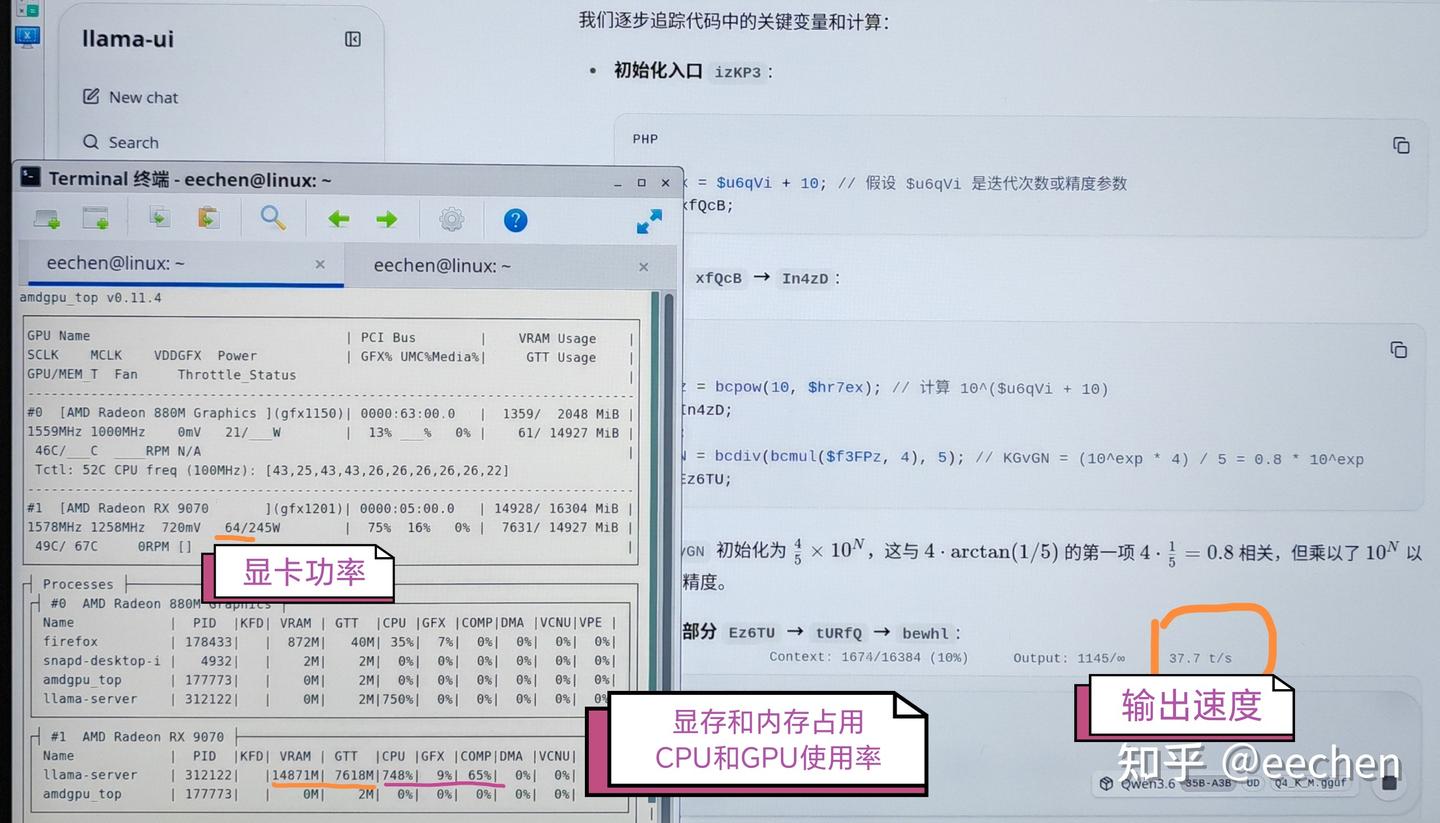
外接RX9070跑Qwen3.6-35B-A3B-Q4_K_M也是可以的,速度可达38 tok/s,完全可用。显卡功率64W,根本跑不满245W,显卡风扇都不带转的,就是CPU也要参与到推理中(可添加参数--threads 2限制llama.cpp使用的CPU线程数降低CPU使用率提高能效,速度只不过降到35 tok/s),内存也要吃掉将近8个G。也可以用iGPU+eGPU双卡推理(--device Vulkan0,Vulkan1 --tensor-split 7,1),速度能达到45 tok/s。