AMD 统一内存架构有望应用于桌面 CPU,有何技术突破?
果粉不会以为AMD在2025年初推出AI Max系列产品才引入统一内存方案吧。
互联网是有记忆的,给果粉扫下盲。
AMD在2011年发布首款APU处理器的时候就引入了统一内存的技术方案。
后续在笔记本、迷你主机、游戏主机PS和Xbox、甚至Steam Deck掌机上被广泛使用。
统一内存其实不太适合桌面CPU,桌面CPU对能耗的容忍度比较高,而且普遍会配备性能更强的独立显卡,桌面CPU集成大核显的需求,其实已经被迷你主机这个产品市场覆盖。AMD自己也推出过搭载780M核显的桌面CPU——R7-8700G,显然并没有获得市场追捧。
近年来AMD最成功的APU方案应该是集成780M核显的laptop处理器7840HS及其马甲,你敢信,2023年发布的产品,直到今年,仍有专门的200系列比如255、260之类的780M核显APU,这颗APU,强就强在价格便宜又能打,你可以1080P玩3A,也可以用32GB统一内存跑今年最新的Qwen3.6-35B-A3B这些模型。关键是在内存价格暴涨的今年,仍能在4000以内的价格买到32GB统一内存的780M核显本。AMD在移动端放弃独显推核显的战略是正确的。
AMD营销还是差,苹果那边,Mac mini养虾,MacBookNeo高性价比都出来了。AMD这边的780M迷你主机和轻薄本,好像不存在一样,实际上用户群体并不少,但买了的人好像也没有话语权,发声总被淹没在苹果、Intel、Nvidia的舆论宣传之中。
我今年4.6K入的比780M新一代的880M核显本,32GB统一内存,跑Q4量化的Qwen3.6-35B-A3B,生成速度也能达到20+t/s,此时APU功率为37W,推理引擎llama-server占用的预留显存VRAM和动态显存GTT加起来为7734M+11017M将近19个GB。
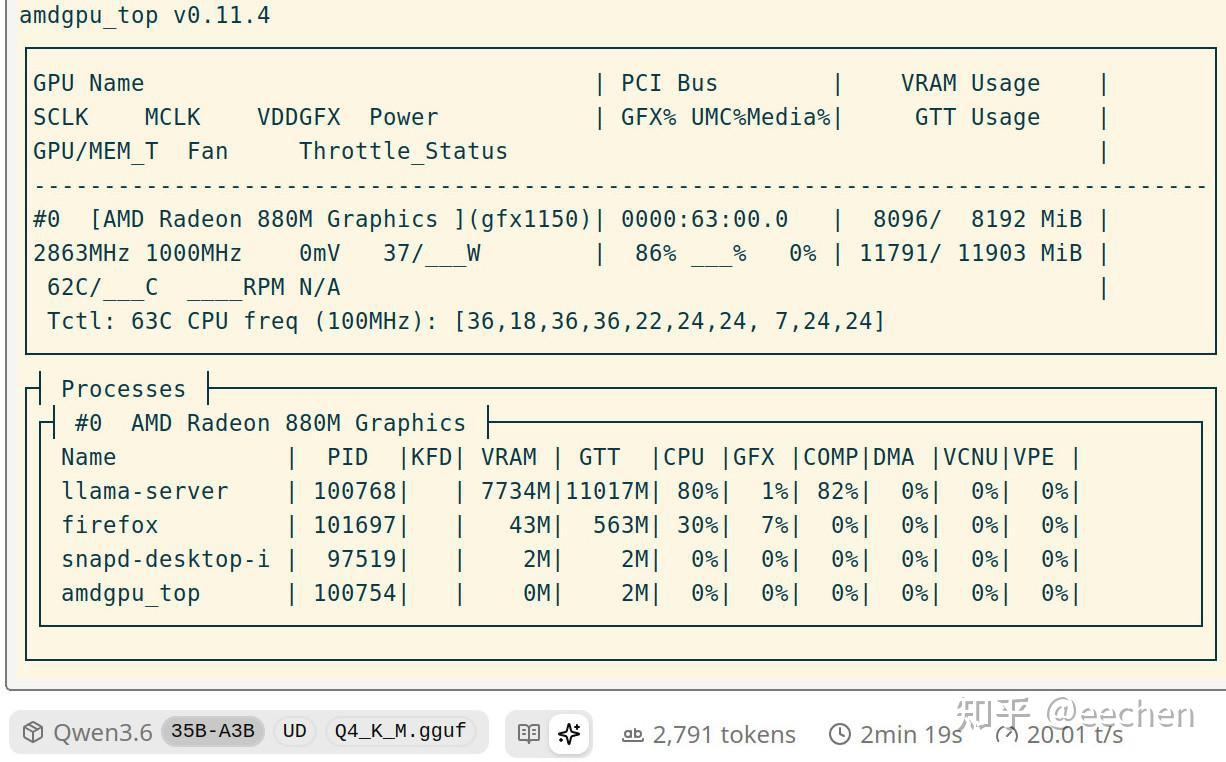
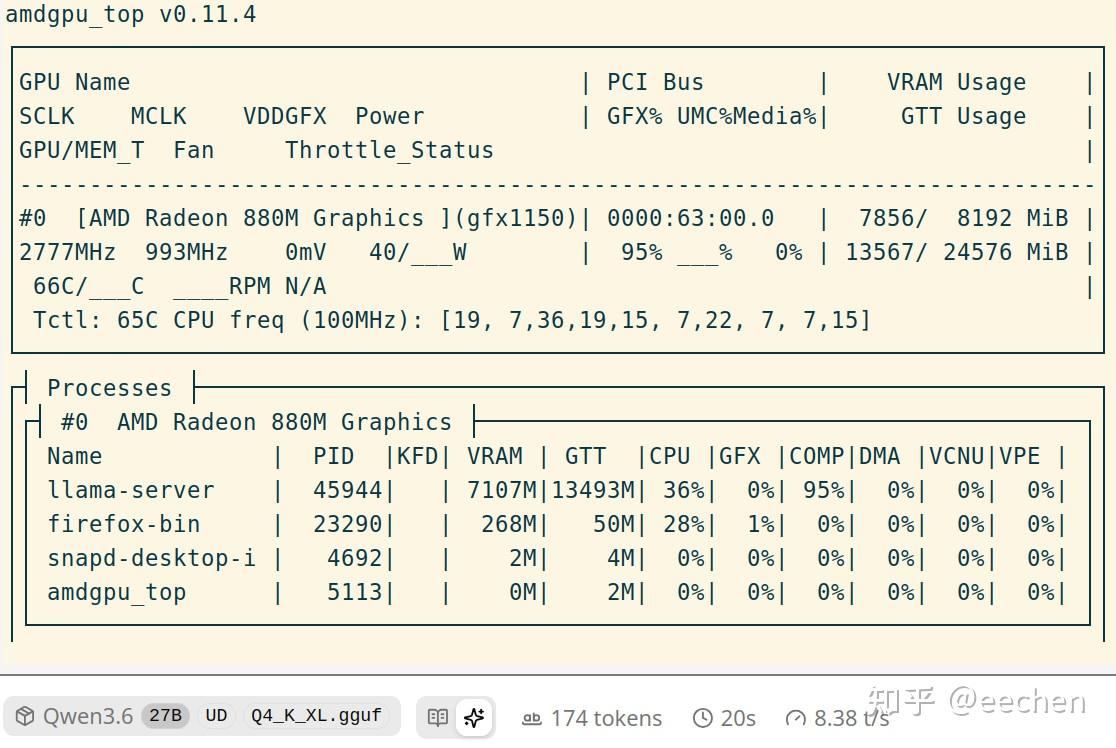
880M核显甚至还能跑Q4量化的Qwen3.6-27B这种稠密模型,虽然速度只有8t/s。
AMD平台UMA统一内存可用显存的计算方法如下:
- VRAM是在BIOS里定义好的预留显存,不需要太大,一般设置为2GB即可。
- GTT是AMD核显的动态显存,最大值默认为系统内存的一半。
- AMD平台UMA统一内存下的的可用显存总数就是VRAM+GTT。
比如32GB统一内存的AMD核显本,如果你预留了2GB VRAM,那GTT=(32-2)/2=15GB,那实际可用显存就是2+15=17GB。如果你经常要玩3A游戏或者跑大模型,我建议你预留8GB VRAM,避免你需要玩游戏跑模型时系统腾不出大量内存。
实际上这套方案也适用于AMD独立显卡,只不过独显GPU要访问内存里的数据,需要经过PCIe总线,速度会受到PCIe带宽限制,这也是统一内存的优势所在,不受PCIe带宽限制。
AI Max系列Halo大核显处理器相比之前的APU,主要是大幅提高内存位宽,从128bit提升到256bit,从而让内存带宽翻倍,核显从16个计算单元的890M提升到40个计算单元的8060S,从而提高大模型推理速度和游戏性能。
从Nvidia发布DGX Spark迷你主机到最近发布的RTX Spark笔记本,再一次印证了AMD AI Max方案的前瞻性。
据传AMD预计2027年推出下一代Halo大核显将再次提升内存位宽至384bit,并采用LPDDR6内存和新一代Zen6架构的CPU和新一代RDNA5架构的GPU。
如果真是这样,那AMD真的是诚意满满。