现在怎么没有人提用AMD MAX395去跑本地大模型了?
讲真,AMD这几年的运气一直都比Intel好。
如果不是内存涨价,这玩意直接就被Intel一波给淘汰了。
我简单说说为什么吧。
我们知道AI MAX+这套统一内存成本是很高的,大家都知道DDR5还要四通道成本必然高,用的颗粒都可以说是特挑中的特挑,必须要产量达到足够高以后才会做这种特挑。那么统一内存有啥优势呢?最直接的优势相对于普通内存,它的推理速度可以提升一倍。
这个我做过对比
AI MAX的集显TOPS算力在50左右(INT8):

因为一般CPU至高就只有10TOPS,而既然NPU占据了50,那么AMD这颗巨大的集显实际就只有50TOPS,最多再高一点点。然后Ultra二代U的核显算力也是60多到70TOPS,也就说实际酷睿Ultra二代的核显算力比这颗巨贵无比的大集显还高!!!
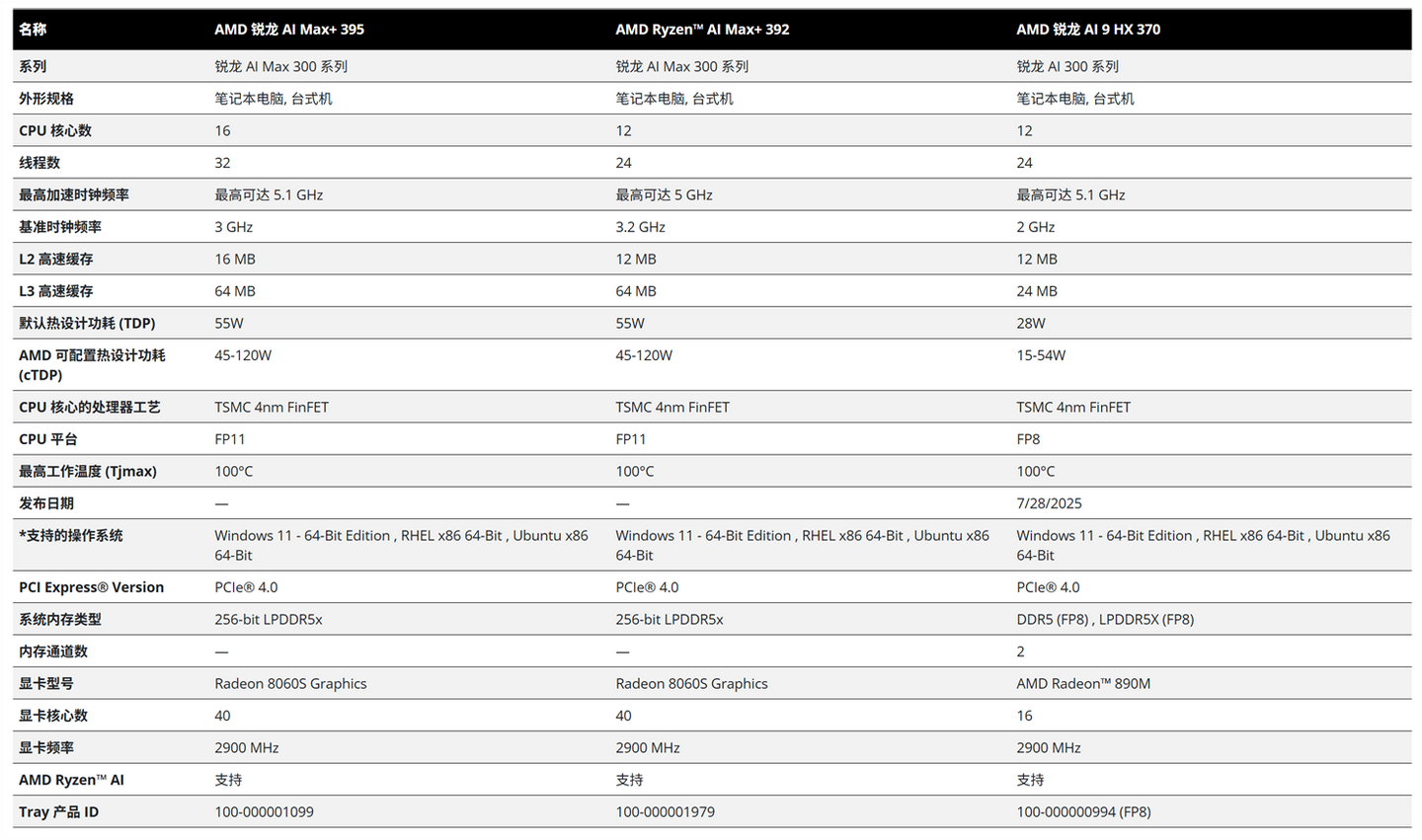
然后首发的395和今年出来的392其实核显和算力都是一样的,没变化。
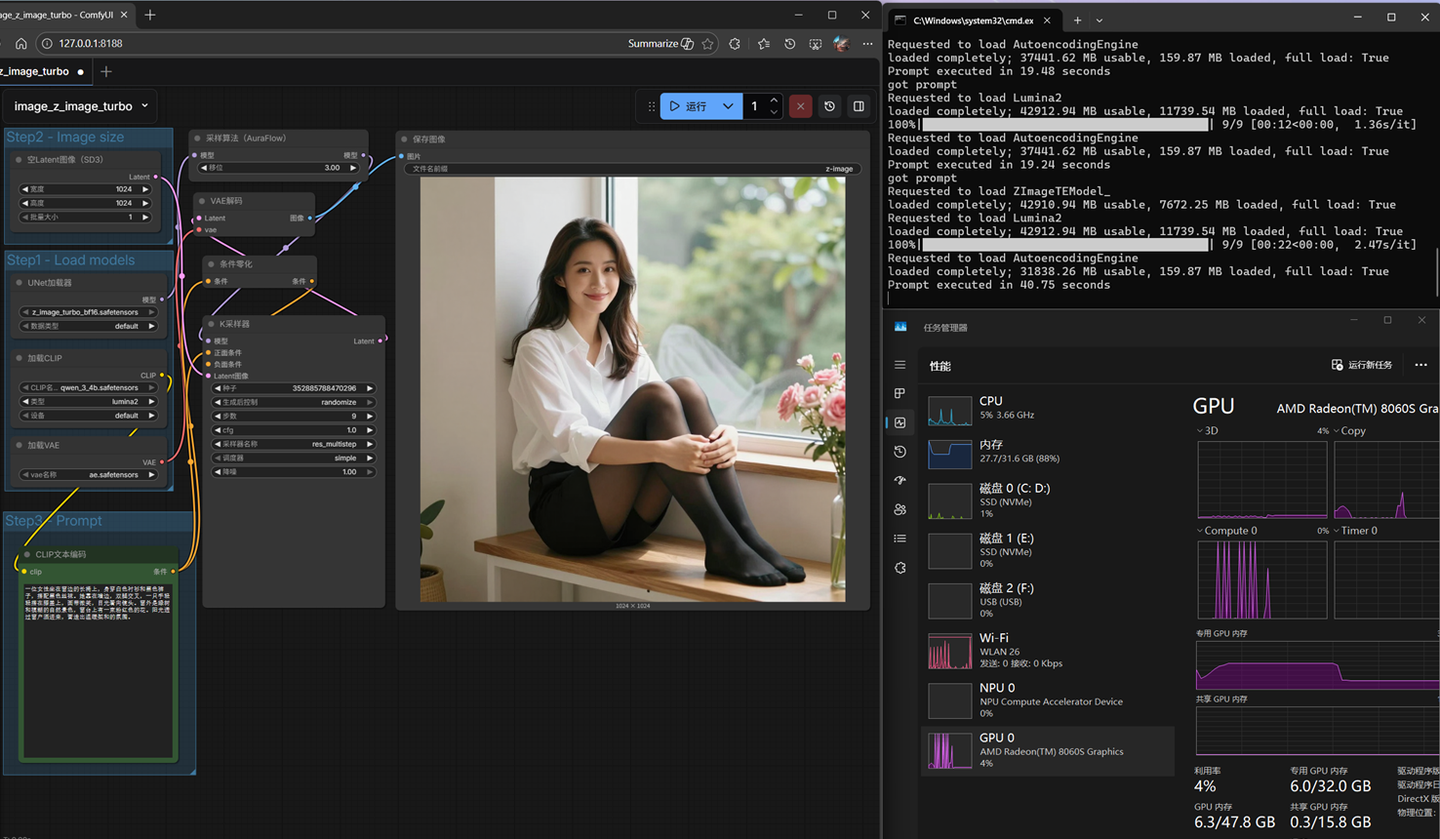
可以看到如上392的这颗8060s集显1024 x1024输出需要40.75秒[1],但实际如果是普通内存,且算力更高的机器对比呢?比如以Ultra9 285H的核显来输出同样的[2]:
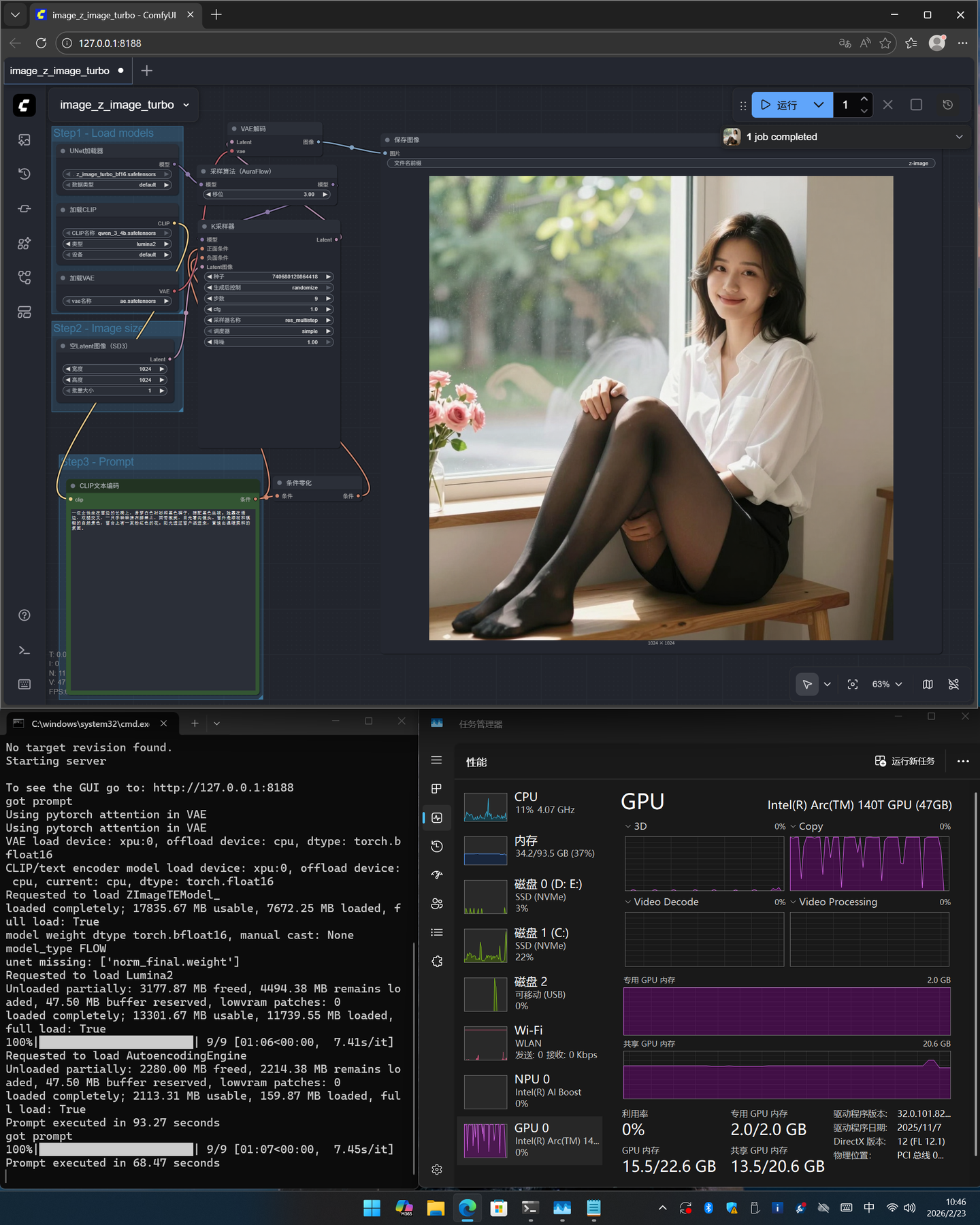
可以看到虽然算力更快,但是受内存的限制,居然不如统一内存。但是这里也会发现内存不同的差距对于AI的影响其实蛮大的,虽然统一内存牛逼,但是也带来了缺陷,且至少两个:
- 它不如独显的显存快
- 虽然AI MAX可选内存够大,但至高仅128G
- 且这套统一内存为独占模式
- 意味着你分配给显卡
- 系统内存又不多
去年Intel干了一件事,可以说把内存的价格推到更高了,为啥呢?
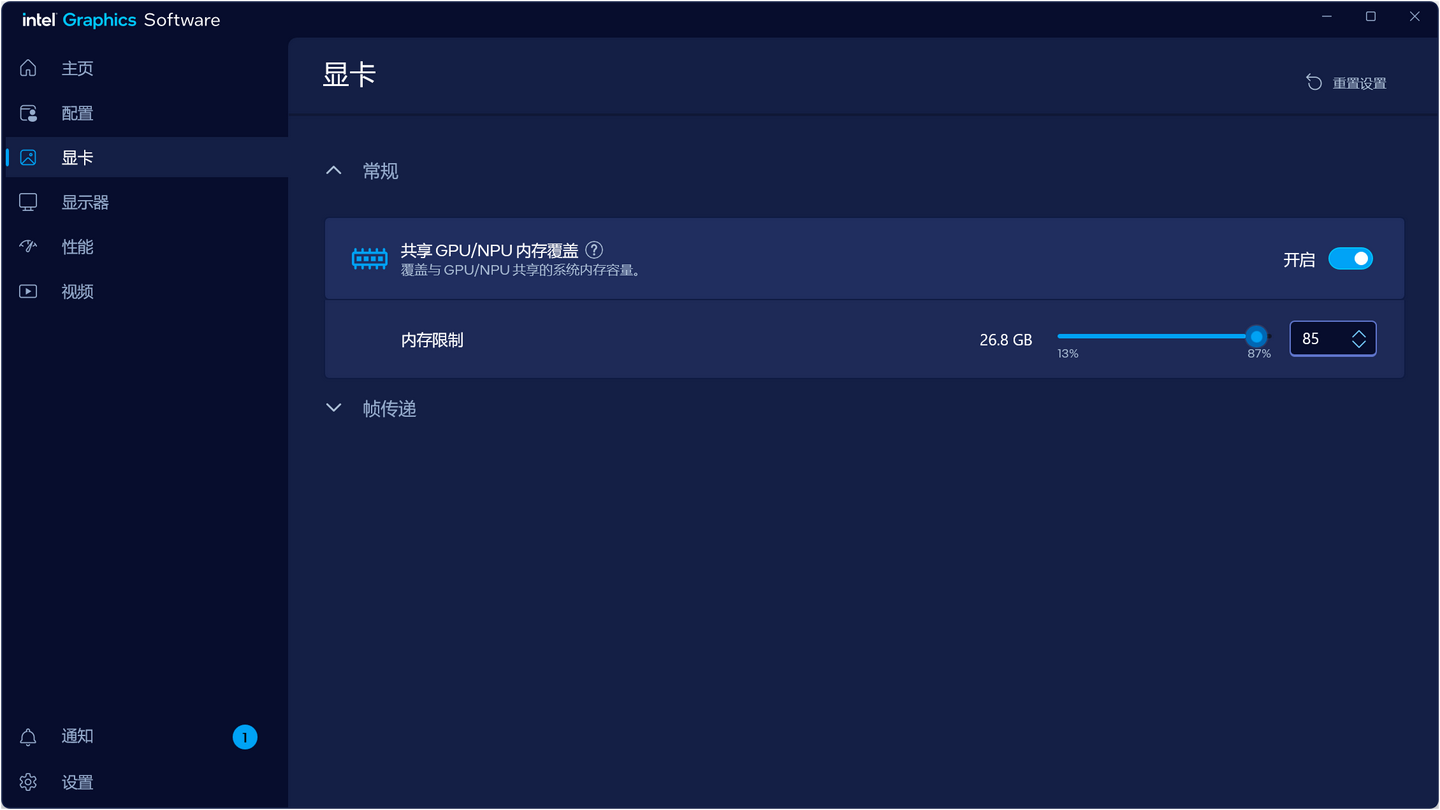
它更新了共享内存的设计,它直接讲CPU和GPU/NPU打通,可以把共享显存拉到近乎【无限大】,也就说哪怕你有英伟达显卡,或者英特尔独显,AI这边显存不够的时候,可以无线的去支持【显存不够】的困境,
编辑于 2026-03-14 · 著作权归作者所有