绿联NAS跑本地向量模型踩坑调优实录:内存、CPU、策略全踩遍了,Hermes终于实现混合检索
大家好啊,我是执着于持续分享数码、家电、NAS、AI、软件技巧相关知识,坚持创作有深度、高质量作品的博主 设计虱聊科技。期待您的关注。
上篇文章,我们介绍了怎么在 NAS 本地通过 Ollama 部署向量模型,来让 Hermes 支持语义搜索。
怎么让你的 AI 真正"理解"你说过的话?本地部署小向量模型搞定而实际上,我在部署完向量模型后,还是遇到了不少问题,比如模型选择、Ollama 设置优化、策略优化等。
好在最终还是完美解决了。
今天我们来说说,在实际使用过程中,我遇到的坑、原因追查、以及最终解决方案。希望对大家有所帮助。
我的NAS能跑什么模型?
我的NAS是绿联 DX4600,跑的是 UGOS Pro 系统。硬件配置是:Intel 赛扬 N5105,4 核心 2GHz,物理内存 8 GB,没有显卡。
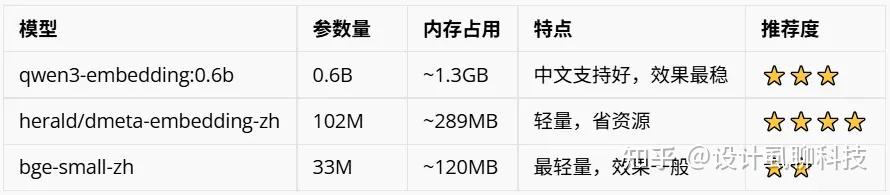
关于用哪个向量模型,上篇文章我直接给了结论(herald/dmeta-embedding-zh),但没告诉你们是为什么。
当时 Hermes 是这样给我建议的:
我寻思0.6B效果肯定最好,那就它了(坑,别学我)。
第一轮失败:模型太大,NAS扛不住
说干就干,先去 Ollama 拉了个模型:qwen3-embedding:0.6b。
告诉 Hermes 我已经部署好向量模型了,跑起来!
然后就卡住了。
Ollama 日志里全是超时:
Retry 1/3 after 5s: TimeoutError: timed out
Retry 2/3 after 10s: TimeoutError: timed out
FAILED after 3 attempts: TimeoutError: timed out
Skip 4: failed after retries一开始以为是网络问题,然后我再仔细看看 Ollama 日志,发现了更离谱的东西:
llama runner process no longer running: signal: killedrunner 进程被系统强制 kill 了。这表示,内存严重不足,NAS 系统为了保证整体稳定,把 Ollama 的向量化进程强制关闭了。

怎么办?换模型吧。
第二轮失败:换模型后,CPU又撑爆
好,换第 2 个选择:herald/dmeta-embedding-zh,跑起来!
这次内存占用大幅下降。OOM 问题消失了。
但我很快发现另一个问题:CPU 满载。
N5105 的四个核心已经快到 100% 了。推理请求排队,响应时间拉到几十秒,客户端等不及就超时。
表面上看到的是"速度慢""一直超时",实际上根因是 N5105 这种低功耗处理器算力不足,跑向量推理还是有点吃力了。
继续想办法优化!
优化CPU:线程数降下来
既然瓶颈在 CPU,那就从 CPU 入手。Ollama 默认用 4 线程跑推理,4 个线程同时抢 N5105 本就不富裕的算力,互相等着反而更慢。
我在 Docker Compose 里给 Ollama 加了个环境变量:
environment:
- OMP_NUM_THREADS=2
让 CPU 处理向量任务时,线程数从 4 减到 2,单线程分到的算力反而更多了,推理速度并没有明显下降,但 CPU 不再满载到 100%。

这下,Ollama 的日志里明显稳了,一排排返回 200 的数据,让人心里安定。
切片策略:数据要分段喂给向量模型
硬件问题解决,下面从软件端继续优化。
dmeta 的上下文窗口是 1024 tokens(约 500 个中文汉字)。超过这个长度的文本,得先切开,分别向量化和取平均。否则,还是会返回错误。

我的处理策略是,告诉 Hermes:
按不大于 500 字符切片,每个切片单独调用 embedding 接口,拿到各切片的向量后,做平均合并。
不用我们做什么,直接让 Hermes 按此执行就行。
实测下来,一条 5000 字的长消息会被切成 10 个 chunk,每个 17-22 秒,串行处理,总耗时约 3-4 分钟。
虽然慢,但是稳定。
更大的问题:我在给噪音建索引?
跑通了,我开始让 Hermes 把历史记忆向量化。
发现——速度真的好慢啊。
跑了几个小时,处理了不到 150 条消息,但总共有 2000 多条历史消息待处理。
按这个速度,全部跑完要好几天。但我很快又发现,速度根本不是真正的问题。
真正的问题是:
我正在让 Hermes 向量化一堆垃圾信息
我去翻了一下 state.db 里的消息分布:
- tool消息: 占 63%——就是 AI 调用工具时的返回结果
- user消息: 大量是"好的"、"嗯"、"继续"、"知道了"
- 真正有信息量的对话轮次,可能不到 200 条
也就是说,我花了两天时间折腾硬件、换模型、写切片脚本,最终目标是向量化 2000 条消息,其中 1200 多条是工具噪声,几百条是"好的好的"。
这就好比你花了一周时间给图书馆编目,结果发现 90% 的书是空白笔记本。
策略转变:全量向量化→对话级摘要
想明白这件事之后,我做了一个关键决定:不再逐条向量化原始消息,改为先生成对话摘要,再向量化摘要。
具体来说:
- 跳过tool消息: 占 63%,检索价值为零
- 过滤短消息: user 消息不到 30 字、assistant 消息不到 100 字的跳过
- 用 LLM 生成结构化摘要: 每个会话一条摘要
- 只向量化摘要文本,不向量化原始消息
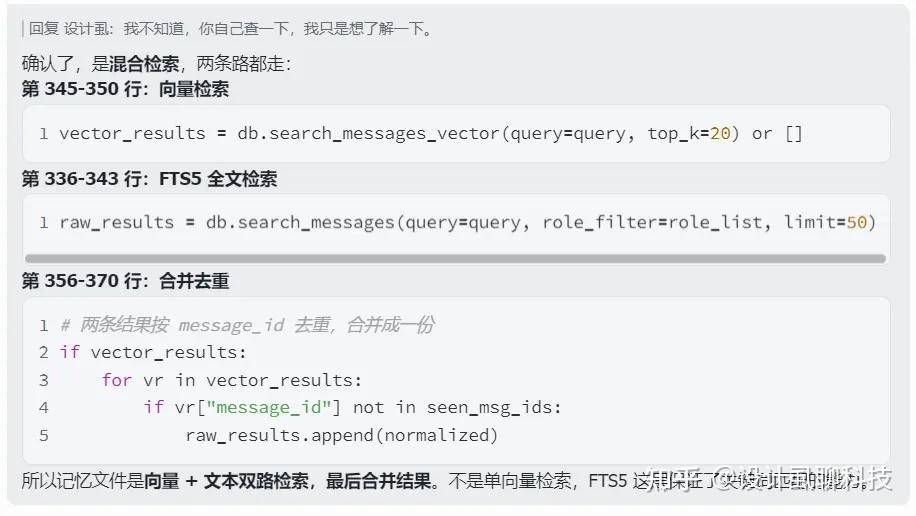
- 混合检索: 原始消息保留做全文搜索(FTS5),摘要向量做语义搜索,两者互补
翻译成人话就是:
每轮对话后,Hermes 会自动生成一段"这次聊了什么、结论是什么、关键数据是什么"的总结,然后把这段总结向量化存起来。
之后搜索的时候,既可以用关键词找原文,也可以用语义找摘要。
这样就科学多了,信噪比提升了一个数量级。
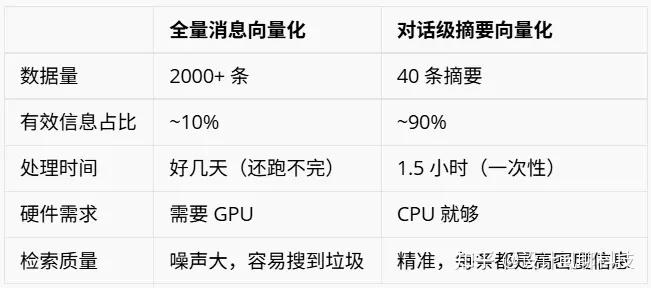
处理了 2000 多条历史记录,实际形成摘要后向量化的切片内容只有 150 条,几十分钟就全部完成。
以后新增的对话,我设置了每 30 分钟运行一次定时任务,自动选择有价值的对话形成摘要,再向量化。整个过程完全自动进行,每次只需要几秒钟,对CPU占用也足够友好。可以说是非常流畅了。
回头看:三个关键结论
折腾了一天,总结出四条经验:
第一,瓶颈在 CPU,不在内存。
N5105 这种低功耗 CPU 跑向量推理,四个核心会直接拉满 100%。可以把 CPU 核心数限制到 2,避免 4 个核心都满了循环排队,造成超时。
第二,策略比优化重要。
全量向量化在任何硬件上都是低效的——问题不在速度,在方向。先想清楚"什么值得向量化",再考虑"怎么向量化更快"。噪音是向量化检索的最大敌人。
第三,针对模型特点处理
herald/dmeta-embedding-zh 的上下文窗口是 1024 tokens,所以我们要向量化的数据必须切片处理,每个切片小于这个上下文窗口,向量化的任务才能稳定运行。
下一篇我们说什么
折腾了这么久,终于跑通了本地向量模型,增强了 Hermes 的语义检索能力。
现在,配合 Hermes 自带的 FTS 5 关键字检索,已经实现混合检索了。
但仅仅是这样,怎么能算是充分发挥了本地向量模型的能力呢?当然是要继续压榨它啊。
我还想通过这个本地向量化模型做什么:
- 一个类似 Mem 0 的本地化高效记忆层,为Hermes提供持久、可检索的长期记忆
- 个人知识库的数据向量化与检索能力
关注我,不错过后续更新。
坚持创作有深度、高质量的作品、致力于分享干货、抵制标题党和网络垃圾,是我的座右铭。
关注我,蹲后续。您的支持对我真的很重要。让我们共同打造互联网内容创作和知识分享的一股清流!ヾ(◍°∇°◍)ノ゙