如何评价小米6月9日发布的MiMo-V2.5-Pro-UltraSpeed模式?
这个话题写起来好像有点复杂,我就用相对科普一点,大部分人都能看懂的角度来说一说吧。。
首先我觉得只要用ai的朋友就知道,ai的结果虽然很重要,但速度其实更重要。就比如DeepSeek大家都觉得它好用,但就是速度有点慢。
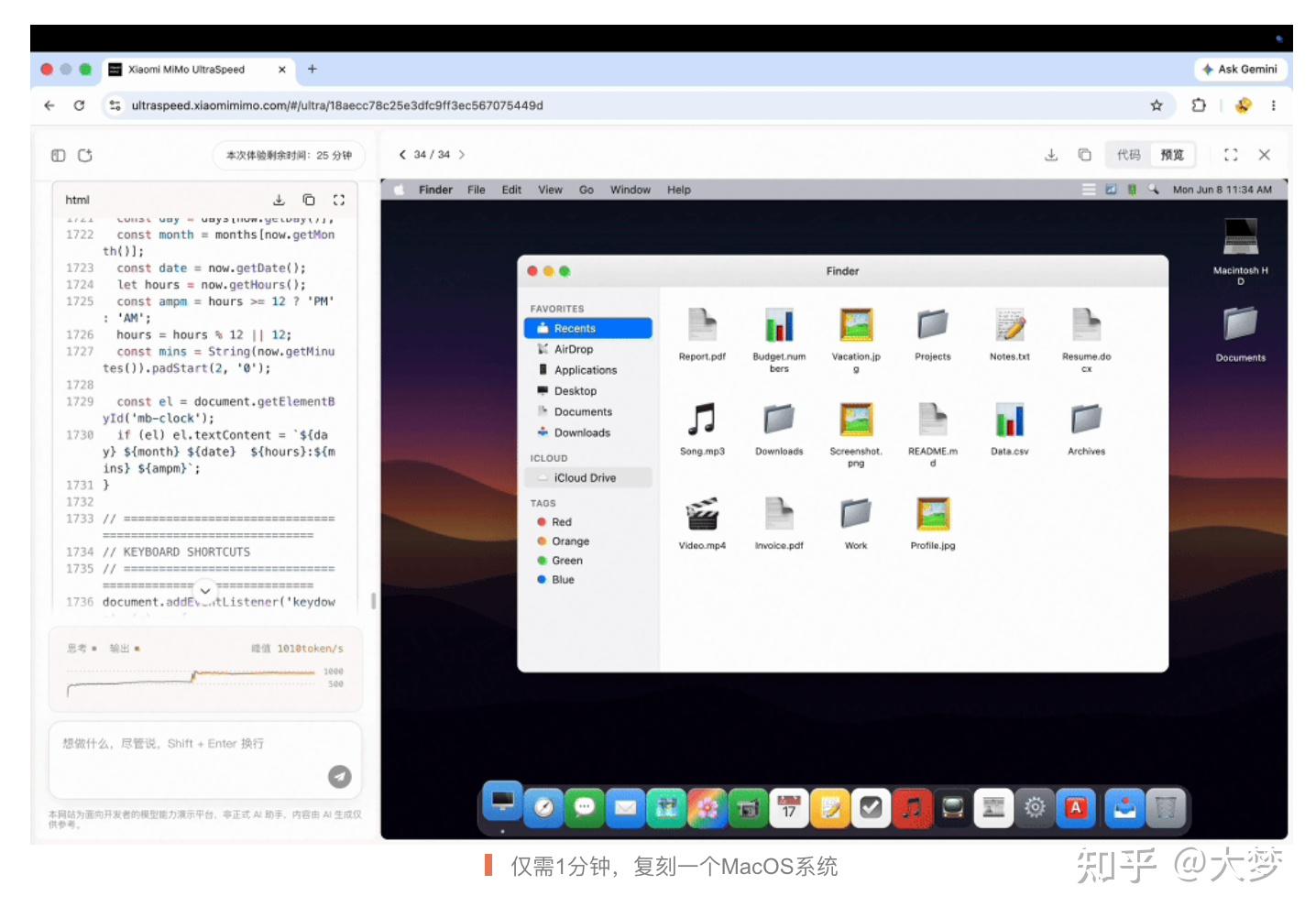
小米这次看官方的演示确实很强,1分钟就能复刻一个MacOS,速度太狠了...我已经申请内测了,回头试用下来给大家写体验。
我的审核过了,给大家拍个小视频:
 https://www.zhihu.com/video/2047947111191386039
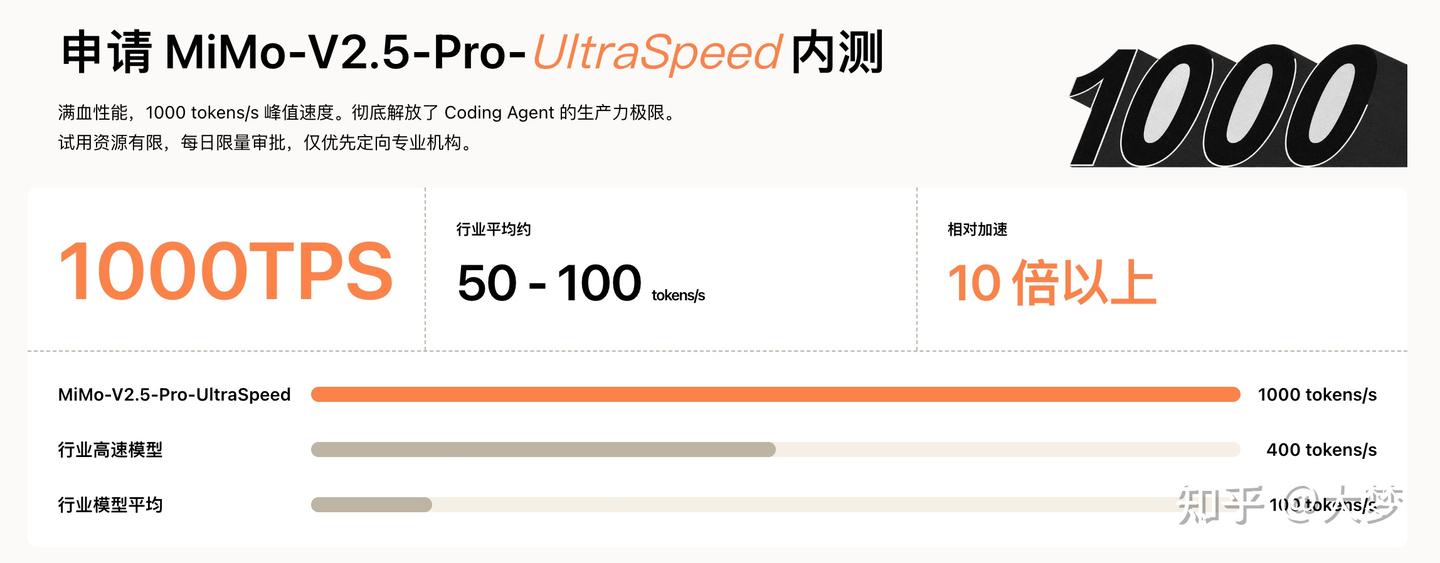
https://www.zhihu.com/video/2047947111191386039MiMo-V2.5-Pro-UltraSpeed,这名字挺长的,你就记住一个数字:1000。
什么意思呢,它一秒钟能输出1000个token。
token你可以理解成AI的"基础语素",大约1个token对应1.5到2个中文字,所以1000 tokens/s换算过来差不多一秒1500到2000个字。普通人看文章的速度大概是一秒4到5个字,所以意思就是MiMo现在写东西比你读还快几百倍。
说到这儿你可能有个疑问,老听人说"万亿参数大模型",参数到底是什么?为什么参数越多AI越聪明?
你可以把参数理解成AI大脑里的"神经连接"。人脑有860亿个神经元,神经元之间通过突触连在一起,你学到的每一个知识、形成的每一个习惯,本质上都是某些突触连接变强了。
AI的参数就是它版本的"突触",每一个参数存着一个微小的数值,几万亿个参数加在一起,就构成了AI"理解世界"的方式。
参数越多,相当于这个AI的"脑容量"越大,能记住更多的知识、理解更复杂的关系、做出更细腻的判断。
打个不太严谨但很直观的比方,一个小模型可能只有几十亿参数,就像一个刚读完高中的学生,常识题能答,但遇到复杂的推理就吃力了。
万亿参数的大模型就像一个读了二十年的学术大佬,见多识广,什么领域都能聊两句。
但问题也来了,脑容量大的人"思考"也慢,你让学术大佬当场解一道题,他脑子里要翻的知识太多了,反应自然比高中生慢。
这就是大模型一直以来的死结:越聪明越慢。
以前这种万亿级别的AI慢得跟堵车似的,现在突然飙到1000 tokens/s,小米是怎么做到的?
先说一个常识,大模型提速最简单的办法就是让它变笨。
你想啊,一个博士做奥数题肯定比小学生做1+1慢,但博士能解出正确答案。
你要想快,换成1+1来算就快了,但遇到难题也傻眼了。之前很多AI提速就是这个思路,砍掉参数让它变轻变快,代价就是变笨。
小米这次没这么干。它的思路特别像一个公司优化:不动核心团队,只减后勤冗余。
万亿参数的大模型里,真正做决策的模块其实不大,大部分参数是负责"搬砖"的执行层,你可以理解成一个公司里真正拍板的是老板和几个总监,剩下几百号人都是干活的。
小米只给"干活的"做了压缩,"拍板的"原封不动保留。结果就是活照样干得动,决策质量一点没掉。
第二招更聪明,叫投机推理。什么意思呢,我打个比方。
假设你是一个大老板,每次写文件都要你亲自过目签字才能发出去,一个字一个字看,效率当然低。投机推理的思路是雇一个便宜的助理,让助理先帮你把文件草稿拟好,一次拟8条,你只需要一次性扫一眼,对了的6、7条直接盖章,错的1、2条打回去重写就行。
你看,你出场次数从8次变成了1次,但最终发出去的文件跟你亲自一个字一个字审过的完全一样。这不是偷懒,这是聪明地干活。在写代码这个场景下,8条里能蒙对6到7条,效率直接翻倍。
第三招是减少"等人"的时间。还是用公司来比喻,以前流水线上每道工序之间都要交接、等下一道工序准备好才能开工,中间全是空闲时间。
小米把工序之间的等待时间压到了微秒级,相当于流水线不停机,上一道刚做完下一道立刻接上,全程零等待。
这三招叠在一起才有了1000 tokens/s这个数字,缺了任何一招都到不了。不是某一个黑科技的单点突破,是三件事配合打出来的组合拳。
然后说第二个问题,为什么是小米做出来的,别人怎么不行。
你可能会想,投机推理、算子调度这些技术别人也能用啊,怎么就小米跑到了1000?
这里面有个关键的点,就像苹果为什么做芯片比别的手机厂强,不是因为苹果买的原材料更好,是因为苹果同时控制着硬件和软件,可以两边一起调。
小米也是一样的道理。压缩方案不是拿个通用工具套上去就行的,是针对自家模型一个一个参数调出来的。投机推理里的那个"助理模型"也不是随便找的,是跟主模型一起训练的,两个人的默契是从根上就设计好的。
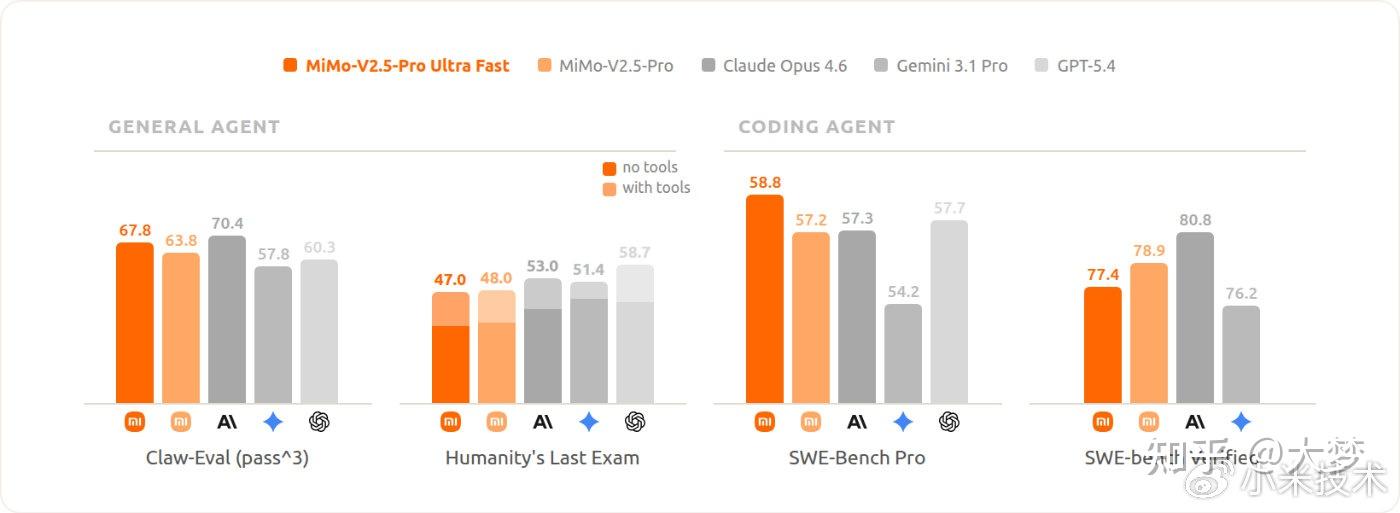
你可以理解成一对双胞胎打乒乓球,他们从小一起练,配合的默契程度不是临时组队的人能比的。友商同类方案的公开数据普遍还在几百tokens/s的量级,差距不在工具,在"人"身上。
更重要的一点是,这种能力是可以复用的。下一代模型出来,同样的优化思路再来一轮,模型升级了系统跟着升级,两边一起往前走。这不是跑了一次百米冲刺的成绩,是建了一条能持续跑的赛道。
最后说说对咱们普通人意味着什么。
大模型行业一直有个死结:越聪明的AI用起来越贵。你可以理解成越好的医生挂号费越贵,很多企业想用顶尖AI,但一算账,算了用不起。
1000 tokens/s不只是快,它直接把每次使用的成本压下来了,理论上同样的预算约莫能服务一个量级以上的用户。这个经济账才是真正能让AI大规模落地的关键。
还有一大堆之前被卡住的场景现在有机会了。
比如你用代码助手写程序,需要它跟你来回对话几十轮不卡顿,以前到第5轮它就开始转圈了;比如实时客服,用户问一句话AI得秒回,慢半拍用户就跑了;再比如广告竞价,100毫秒之内必须做出决策,以前大模型根本进不了这个时间窗口。
现在门开了,万亿参数的AI第一次能进到这些"需要又快又准"的场景里。
还有一点容易被忽略,小米跑出这个成绩用的是通用GPU,不是什么专门定制的芯片。
这意味着不依赖某一家供应商,不担心被卡脖子,换一批显卡、出新模型,优化可以再来。这是长期主义的牌,不是赌一家芯片厂能不能按时交货,是把自己的能力变成谁也拿不走的东西。
说到这儿你可能觉得这就差不多了,但我觉得这件事还有一层更深的意味值得聊聊,就是小米在AI上的整体布局。
卢伟冰之前在Q1业绩电话会上把小米的AI战略讲得很透了,
三层架构:底层是基础大模型,就是MiMo这系列;中间层是把大模型用到智能驾驶和具身智能上;上层是让大模型走进你每天用的应用里。
三层叠在一起,大方向就八个字:"用AI重构人车家全生态"。
别的厂做AI,要么做模型卖API,要么做某个垂直应用,但小米有手机、有汽车、有全屋智能,全球几亿台活跃设备摆在那,这是别家想抄都抄不来的底子。
今年3月小米发了国内首个手机端Agent产品miclaw,它能直接调用你手机上27项系统级工具,底层就是MiMo在驱动,而MiMo的推理速度直接决定了miclaw给你的体验够不够丝滑。
你想想,如果Agent帮你操作手机,每一步都要等3秒,你早就没耐心了,但如果每一步都是毫秒级响应,那感觉就跟自己操作一样流畅,你才会真的离不开它。
所以小米这次把推理速度拉到1000 tokens/s,不是单纯在跑分,是在给Agent的体验铺路。
Agent要好用,核心不是智商多高,而是反应得多快。你想让AI帮你同时操作好几件事,读短信、查日历、调空调、设闹钟,每一步都要大模型做推理判断,速度慢了整个链条就卡住了,速度快了才是真正的"你说一句它全给你搞定"。
这次的技术突破,说白了就是让小米的Agent在未来能同时处理更复杂的多步任务,而不至于在你面前转圈等加载。
还有个事儿挺值得琢磨的,下半年小米要出的一款重磅新品,据说是自研芯片玄戒、自研操作系统澎湃OS、自研AI大模型MiMo三项技术第一次在同一个终端上深度整合,现在网上都叫"技术大会师"。

如果MiMo的推理速度已经能做到1000 tokens/s,那这台新品的AI体验大概率会是一个质变级别的跃升。
更长远地看,小米未来五年要投2000亿搞研发,核心就是让AI渗透到人车家的每一个环节。
你手机上的miclaw帮你管生活,你车里的大模型帮你管驾驶和座舱体验,你家里的Miloco全屋智能系统帮你管家居,三端共享同一个底层模型能力。
这种全链路的好处是,你在手机上教AI的偏好和习惯,到了车里和家里它都记得,不需要每个设备重新"认识"你。而这整个体验能不能成立,底层就取决于模型够不够聪明、推理够不够快。
今天这1000 tokens/s,就是在给这张大网打最关键的地基。
之前我们觉得大模型就是"越强越慢越贵",这个常识今天被打破了。万亿参数进实时推理,通用硬件跑出这个成绩,你把这两件事拆开看,任何一个单独拿出来在一年前都够开一场发布会了,现在是同时兑现。
而且它不只是现在快,它背后是一整套能跟着模型一起进化的优化体系,是小米用"人车家全生态"织起来的AI大网,这张网的天花板取决于底层模型的推理速度,而今天这个速度,才刚刚开始。
昨天刚看完星辰变动漫,不知道有没有朋友看啊!想到一个比喻可以来形容小米这些UltraSpeed…
小说里面的话,秦羽飞升神界前,因为炼器大师比较稀缺,所以整个神界想要炼造神器都很贵,一些水平比较拉的炼器大师就坐地起价,技术差不说还贼浪费资源。
小米这个UltraSpeed就跟秦羽有点像了,只需要普通材料,就可以炼造出上品神器,就像UltraSpeed只需要跑在通用GPU上一样。
你稍微给点资源,秦羽就能给你搞出一堆一流鸿蒙灵宝…以至于秦羽后来家里鸿蒙灵宝都用来当板凳了。
怎么说呢?大概这就是天赋型选手卷技术的成果,就是又快又便宜还比你搞得好。
