如果黄仁勋愿意,凭借英伟达目前造算力卡的技术,最高可以造出什么水平的游戏显卡?
把B300那套东西拿来造游戏卡,4K原生干到200帧以上没问题。
——但不是完全照搬,而且建议大家来看看天花板级游戏卡的收益VS成本。
关键是算力卡上那些技术不是搬过来就管用。
- HBM显存带宽8 TB/s看起来厉害,但延迟比GDDR高四倍,游戏场景下反而可能更差。
- 双die封装NV-HBI互联10 TB/s,但跨die延迟抖动会极大影响帧生成时间。
- CoWoS-L封装成本高到显存部分就逼近一张4090的BOM。
一、算力卡和游戏卡的差距在哪
| RTX 5090 (GB202) | B200 (Blackwell) | Rubin R100 | |
|---|---|---|---|
| 工艺 | TSMC 4NP | TSMC 4NP | 3nm |
| 晶体管 | 922亿 | 2080亿(双die) | 3360亿 |
| die面积 | ~750mm²(单die) | 2×~800mm²(双die) | 更大 |
| CUDA核心 | 21,760(满血24,576) | ~2×更多 | — |
| 显存 | 32GB GDDR7, 512-bit | 192GB HBM3e, 6144-bit | 288GB HBM4 |
| 显存带宽 | 1.79 TB/s | ~8 TB/s | 更高 |
| 功耗 | 575W(实测峰值过600W) | ~1000W | — |
5090的21,760个CUDA核心并没有开满,满血GB202有24,576个。但是12V-2×6接口额定600W,575W的TDP打满后裕量极小,已有用户报告接口熔毁。
5090和B200的差距主要在带宽,B200的8 TB/s对5090的1.79 TB/s,4.5倍。

游戏每帧的纹理采样、帧缓冲读写、深度缓冲操作全吃带宽。按Rubin R100规模做游戏卡,光栅理论能达到5090的5到6倍。但理论值跟实际之间的鸿沟比倍率本身复杂得多。
二、逐项拆解
2.1 大die:光刻机天花板
reticle limit是光刻机单次曝光最大面积,TSMC当前约26mm×33mm,约858mm²。B200两颗die都到顶了。
GB202是750mm²,比AD102大24%。堆到850mm²理论上多塞13%的SM,满血24,576基础上加约3,000个CUDA核心,配合架构改进单精度浮点能提升15%到20%。
代价是良率暴跌。一片4NP晶圆约两万美元,750mm²切出约70颗,大die良率40%到60%,每颗可用芯片500到800美元。堆到850mm²良率跌到35%以下,单颗成本破千。花两万买张晶圆,切出来一大半废品,好的那几颗平均下来成本爆炸。
2.2 Chiplet:NVIDIA研究了七年却不敢用在游戏卡上
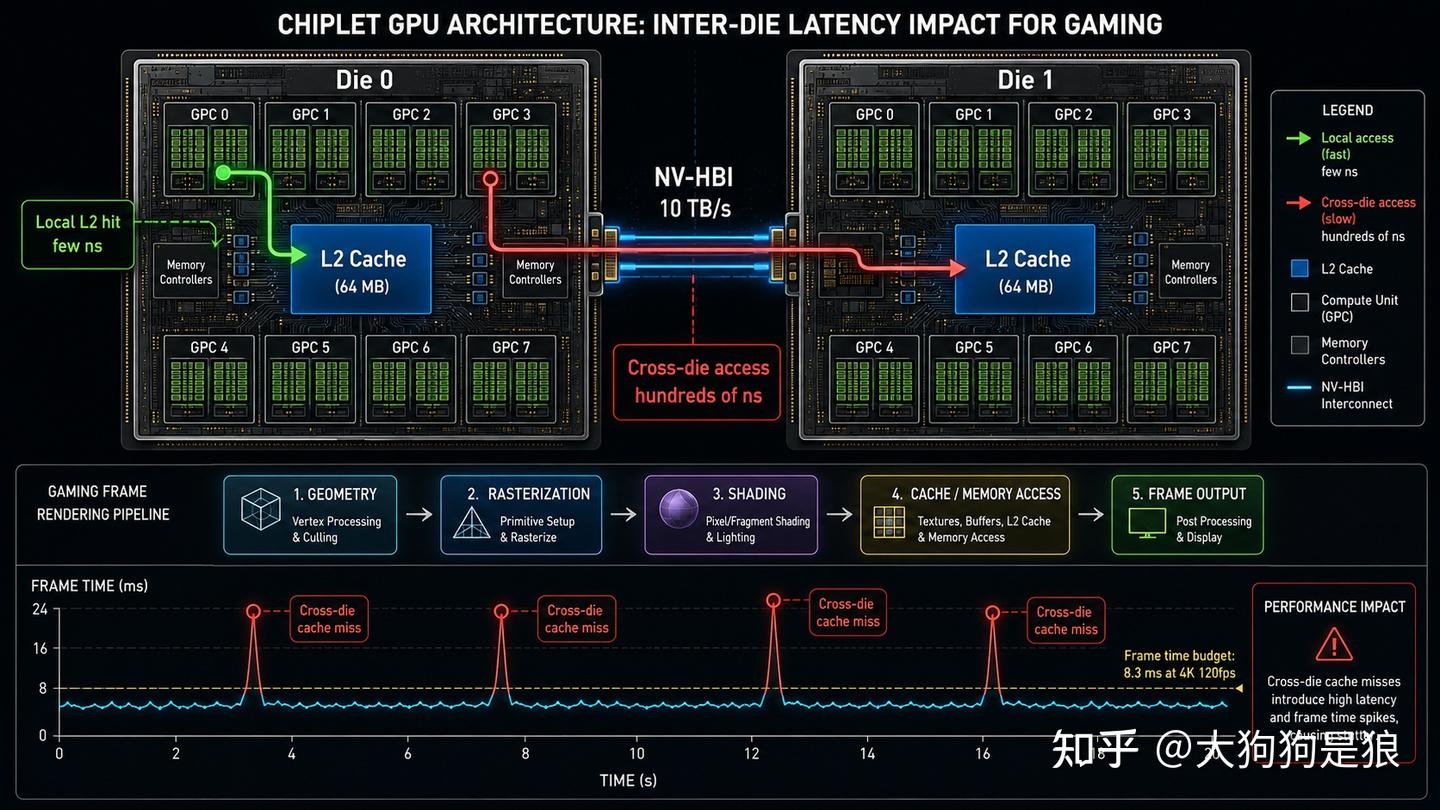
NVIDIA在2017年发了MCM-GPU论文(ISCA 2017,第一作者Akhil Arunkumar)。数字很漂亮:优化后MCM-GPU比大面积单die GPU快45.5%,比同等规模多GPU SLI快26.8%。但论文同时指出这需要优化数据局部性——把常用数据尽量放在发起访问那颗die的本地缓存,减少跨die带宽依赖。七年过去游戏卡还是单die,原因就藏在这句话里。
B200虽然用了两颗die,但Chips and Cheese说得直白:它不是真正意义上的chiplet,”两块巨大单片用胶水粘在一起”,NV-HBI提供10 TB/s互联。反观AMD在MI300上才是真正的模块化——GPU die、CPU die、显存die各自独立可组合。
4K 120fps每帧预算8.3毫秒。一帧渲染数百万次内存访问,任何一次走了跨die路径就被NV-HBI的互联延迟拖住。带宽10 TB/s没问题,但物理距离就是距离,信号走线需要时间。同一个渲染pass里有些访问命中本地die的L2(几个纳秒),有些跨die(几百纳秒),这种延迟抖动在帧时间上表现为随机尖刺(frame time spike)。
SEECHIP(ACM 2023)在分析电气互联延迟和能耗瓶颈后提出的光子互联方案可能是瓶颈的突破方向之一。
AMD在MI200 CDNA2踩过同样的坑:统一显存池暴露了,但跨die访问的NUMA效应导致延迟不对称。后来AMD申请了带集成缓存的主动桥接chiplet专利,在die之间加共享末级缓存,把跨die访问变成缓存命中。方向对了,但距离消费级GPU落地至少还要一两代。
矩阵乘法天然适合均分到两颗die——每颗die各算各的矩阵分块,最后归约。游戏渲染管线做不到:一个draw call可能同时需要纹理A(在die 0)和几何数据B(在die 1),这种跨die依赖在矩阵乘法里不存在但在图形渲染里到处都是。
2.3 HBM延迟:带宽翻四倍为什么打游戏可能更差
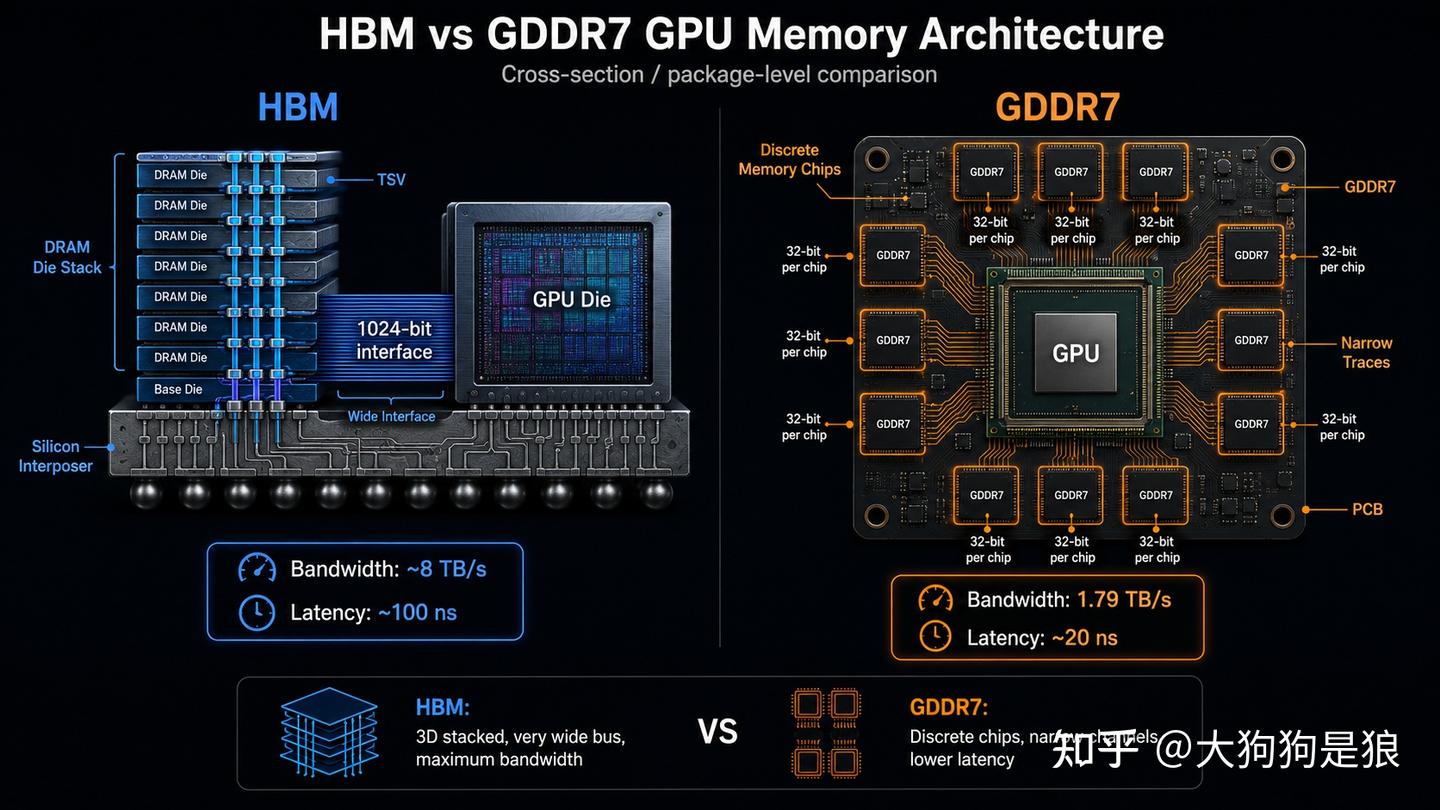
HBM通过TSV把多个DRAM die垂直堆叠,整体紧贴GPU die。等效位宽极大但时序远差于GDDR,HBM靠位宽补频率的策略意味着单次访问的响应速度不如GDDR,随机访问延迟是GDDR7的数倍。
矩阵乘法数据访问高度规则,GPU靠大规模预取和双缓冲完全隐藏延迟。但游戏的纹理采样二维空间相关但渲染顺序不确定,物理模拟、特效渲染、粒子系统同时争带宽,HBM的高延迟下GPU核心要频繁等数据。
钱的问题更直接。
HBM需要TSMC CoWoS-L先进封装,单颗HBM3e堆叠约50到80美元,六颗300到480美元。这还没算CoWoS-L封装费,光”显存+封装”就逼近RTX 4090的BOM(约450到500美元)。
HBM堆叠后的封装高度和散热跟传统PCB上的GDDR不兼容,如果使用的话,消费级显卡散热器又要大改。
GDDR7的28 Gbps配合512-bit做到1.79 TB/s,延迟低、成本低、PCB布局灵活。对游戏来说现阶段GDDR7可能反而比HBM更适合——至少HBM4能把延迟降下来之前是这样。
2.4 功耗
B200约1000W。GB200 NVL72机柜约125 kW,标准机柜12到20 kW。
5090的575W已经让12V-2×6接口(额定600W)裕量极小。
算力卡规模搬过来至少1500W——水泵、冷排、专用电源,本质上是小型工作站的散热方案塞进一张显卡。

2.5 PCIe带宽
PCIe 5.0 x16双向带宽64GB/s。GPU算力翻三四倍而PCIe带宽不变的话,CPU到GPU的draw call、场景数据、物理计算结果这条通路会成为新瓶颈。NVIDIA推Resizable BAR和DirectStorage就是让数据尽量留在GPU端减少过PCIe的次数。况且消费级主板最高就只支持到PCIe 5.0 x16。
三、不计成本的天花板是什么样子?
3nm工艺(Rubin级别),两颗接近reticle limit的die通过改进版NV-HBI互联,总晶体管约3000亿。关键的一点是砍掉算力卡上AI训练专用单元、HPC科学计算专用的FP64单元和大量冗余寄存器文件,这些在游戏场景完全用不到,省下来的面积全给CUDA核心、RT Core和Tensor Core。这样等效CUDA核心数量能达到5090的3到4倍。
显存的选择比较纠结。上HBM4的话带宽约2到3 TB/s、容量能达到128~512GB,但前面分析过的延迟问题仍在。更现实的路线可能是下一代GDDR,在保持低延迟的前提下把带宽推到3到4 TB/s、容量48到64GB,对游戏来说低延迟可能比高带宽更关键。封装用CoWoS-L,双die互联10 TB/s,配合跨die缓存一致性协议和共享末级缓存来缓解延迟抖动。功耗800W到1000W,需要定制一体式水冷。
性能层面,4K原生光栅约5090的3到5倍,光线追踪约4到6倍。Tensor Core也翻3倍意味着DLSS超分和帧生成的吞吐量同步翻3倍。在《黑神话:悟空》4K全影视级画质下,5090原生大约60帧的水平可能直接跳到180帧以上,开DLSS帧生成后奔300到400帧——前提是引擎能喂饱这么多核心,这又说到了后面第四章的问题。
售价保守估计1万美元。

四、芯片设计以外的限制
引擎适配。 双die架构需要引擎感知数据局部性——哪些纹理和几何数据放在哪颗die的本地缓存。UE5和Unity都按单GPU设计。驱动层透明调度的效率远不如引擎显式配合。MCM-GPU论文里那个45.5%的提升就建立在优化数据局部性上,这需要改引擎渲染管线。
图形API。 DirectX、Vulkan的调用路径全要适配双die。B200双die在软件层暴露为单GPU,那是CUDA计算优化的结果。图形驱动复杂度远高于计算——渲染管线状态管理、命令缓冲区提交、同步机制全要重写,每种API每个版本单独测试。
经济学。 据多家媒体报道NVIDIA 2026年可能不发布新游戏显卡,游戏显卡产能砍40%。AI加速卡利润是游戏显卡的十倍以上。NVIDIA包了TSMC 70%的CoWoS-L产能,全造算力卡都不够卖。同样CoWoS产能,造一张B200赚的钱够造好几张5090。
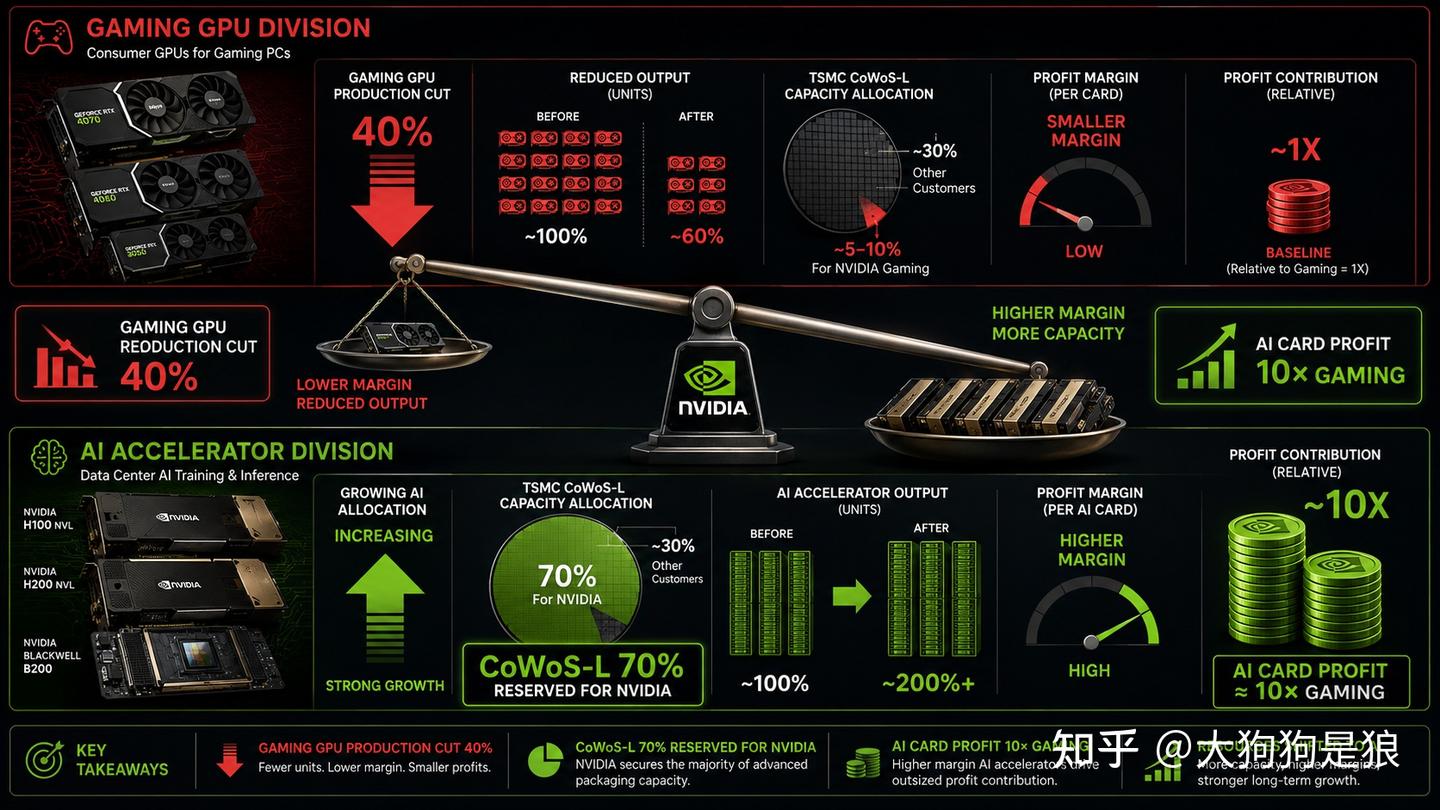
5090不是NVIDIA技术能力的上限,是NVIDIA愿意给游戏市场分配的技术上限。下一个真正让游戏GPU性能跃升的变量,可能不是NVIDIA的芯片设计,而是AMD把chiplet架构的消费级GPU真正做出来,只有竞争压力下NVIDIA才会把压箱底的技术拿出来。不过看AMD当前的GPU业务状况,这一天可能还要等很久。