苹果 M5Max 游戏性能将超 RTX5070Ti,这会给独立显卡市场带来哪些冲击?
我愿称这个为,硅基的终局,我们一起来深度解析M5 Max如何以“架构之优雅”终结RTX 5070 Ti的“暴力美学”
第一章:当“现实扭曲力场”遭遇物理高墙
在科技爱好者的圈子里,有一种循环往复的争论:Mac 到底能不能打游戏?
六年前,如果你问这个问题,我会让你出门左转买外星人;四年前,M1 Max 发布时,我会说“未来可期”;但今天,当台积电N3P工艺的良率报告和 M5 系列的架构图谱摆在案头,作为一名见证了苹果从至暗时刻走向万亿帝国的死忠粉,我隐约听到了远方传来的雷声,那是旧时代崩塌的前奏。
这个问题的核心不在于“能不能”,而在于“代价”。Nvidia用300W的功耗、巨大的散热器和独立的GDDR7显存堆砌出的性能堡垒,如果被一颗功耗仅为其三分之一、封装在轻薄机身内的SoC攻破,那么整个PC硬件产业赖以生存的“摩尔定律+功耗堆叠”逻辑将被彻底改写。这不仅是产品的迭代,这是计算哲学的战争:是继续拥抱力大砖飞的离散架构,还是转向高能效比、高集成度的统一内存架构?
第二章:M5 Max的心脏,台积电N3P与SoIC的化学反应
要理解M5 Max凭什么挑战RTX 5070 Ti,我们首先要看它的出身。芯片行业的铁律是,制程决定下限,架构决定上限。

1.工艺制程:N3P的终极压榨
根据供应链的最新情报,M5系列将成为台积电N3P工艺的首发客户,这并非简单的数字游戏。
M4这一代使用的 N3E 工艺虽然解决了N3B的良率和成本问题,但在性能上限上有所保留。而N3P是3nm 家族的“完全体”。数据表明,N3P相比N3E提供了5% 的频率提升或者10% 的功耗降低,更关键的是,它允许1.1 倍的晶体管密度提升。
对于M5 Max这样规模的芯片,10%的密度提升意味着苹果可以在不增加芯片面积的前提下,额外塞入数以亿计的晶体管。这些晶体管会被用在哪里?答案是显而易见的:更多的GPU核心和更庞大的神经引擎。
作为苹果粉丝,我们肯定知道Johny Srouji的刀法。他不会无的放矢。N3P赋予了M5 Max 在热设计功耗受限的笔记本机身内,运行更高频率的基础物理能力。
2.封装革命:SoIC-mH的战略意义
如果说制程是地基,那么封装就是摩天大楼的结构。传闻M5 Max及其大哥M5 Ultra将首次引入 SoIC-mH封装技术 。
传统的单片SoC设计面临着光罩面积的物理天花板,要挑战RTX 5070 Ti甚至5080的性能,单靠单片设计已经捉襟见肘。SoIC允许苹果将计算模块、IO模块和缓存模块垂直或水平堆叠,实现3D甚至2.5D的异构集成。
与传统的PCB板级互联不同,SoIC是晶圆级的键合,这意味着模块之间的通信带宽极高、延迟极低,且热量可以通过专门设计的硅通孔导出。这对于M5 Max至关重要,因为它必须在极其紧凑的 MacBook Pro机身内,压制住数十个GPU核心全速运转产生的热量。
3.神经图形单元:GPU的AI进化
这是M5架构中最令我兴奋的改动,苹果终于决定打破 CPU、GPU、NPU 的物理隔阂。在M5系列中,每一个GPU核心都将集成专用的神经网络加速器。
在M1到M4时代,AI任务主要由独立的Neural Engine处理。但在游戏渲染中,超分辨率、光线降噪、帧生成等等任务需要GPU和AI单元极其频繁地交互。数据在GPU和NPU之间搬运会产生巨大的延迟。
将AI算力下沉到GPU核心内部,意味着M5 Max可以像Nvidia的Tensor Core一样,在渲染流水线中“零延迟”地调用AI算力。苹果宣称这带来了4倍于M4的AI峰值性能 。这意味着MetalFX的效率将迎来质变,为挑战RTX 5070 Ti提供了软件基础。
第三章:统一内存vs离散显存的终极辩论
1.带宽与容量的非对称打击
M5 Max预计将支持最高128GB甚至更大的统一内存。M5 Max 的统一内存带宽传闻将突破500GB/s 甚至更高。虽然这个数字在纸面上低于RTX 5070 Ti 的 896 GB/s,但我们不能忽略架构差异。Nvidia的896GB/s是GPU内部的带宽。当GPU需要读取 CPU 处理后的数据时,受限于PCIe 5.0 x16 的带宽,这是一个巨大的瓶颈。苹果的UMA架构允许CPU和GPU访问同一块物理内存地址。数据不需要在“内存”和“显存”之间复制。这意味着,M5 Max 省去了数据搬运的时间和功耗。
2.延迟的秘密:TBDR的魔法
有人会反驳:GDDR7的延迟比LPDDR5X低得多,这对游戏帧数至关重要。没错,物理上GDDR7的延迟确实更低。但苹果使用了TBDR架构来规避这一问题。传统的Nvidia GPU采用立即渲染模式,凡是生成的图元都立即丢给显存。这导致对显存带宽和延迟的极高依赖。M5 Max 的GPU会将画面分割成小块,在GPU内部极其快速的片上缓存中完成渲染,最后才写入内存。这极大地减少了对外部内存的读写需求。配合 M5 架构中巨大的系统级缓存,苹果成功地“隐藏”了内存延迟。
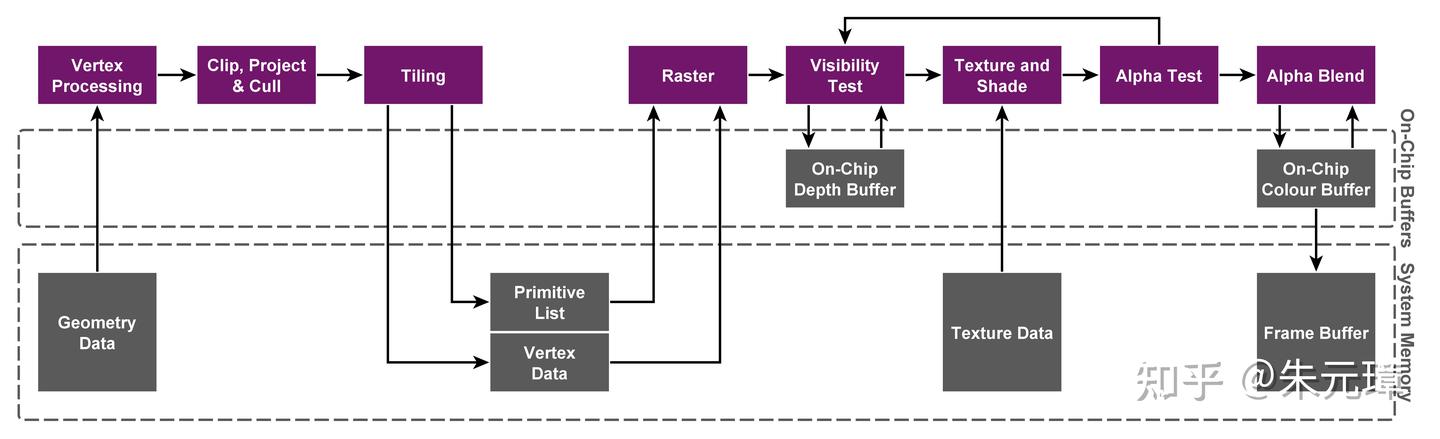
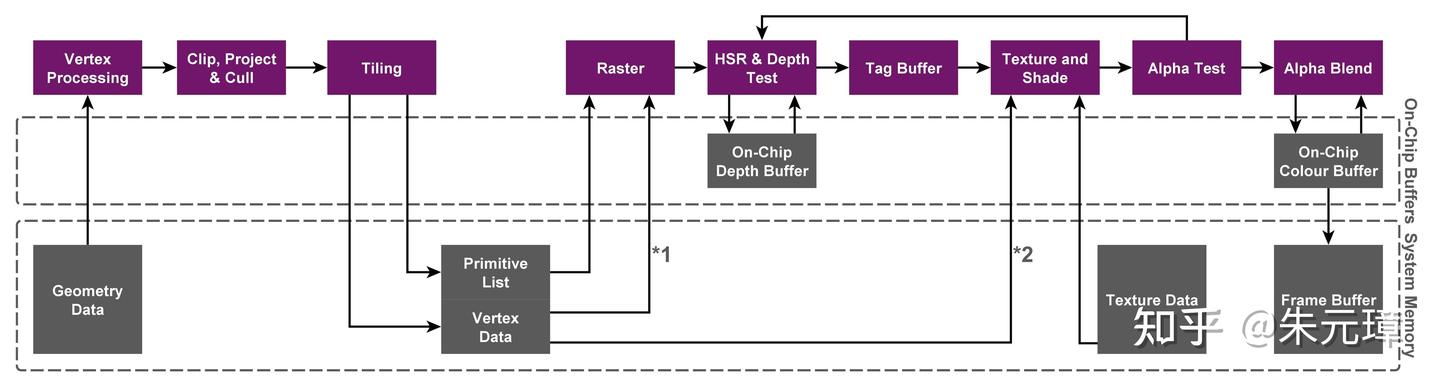
在 4K 高分辨率下,RTX 5070 Ti 依靠暴力带宽可能在纯光栅化性能上略占优势;但在复杂场景、大纹理加载以及多任务并行时,M5 Max 的 UMA 架构将展现出惊人的平滑度。
第四章:M5 Max 游戏性能的量化预测
作为“理中客”的果粉,我们不能只谈哲学,必须看数据。基于M4 Max的性能基线和M5的提升幅度,我们可以构建一个数学模型来预测M5 Max的表现。
1.基准线:M4 Max 的位置
目前,M4 Max在Blender Open Data中的得分为 5208。
这个分数处于什么水平?
- RTX 4070 Desktop:约 5129 分
- RTX 4090 Laptop:约 6863 分
- RTX 4090 Desktop:约 10880 分
也就是说,M4 Max已经拥有了超越桌面版RTX 4070的渲染能力,大约相当于RTX 3080 Ti或 RTX 4080 Laptop的水平。
2.M5 Max 的跃升幅度
苹果官方宣称,M5 GPU 的图形性能提升高达 45% 。
如果我们把这个提升代入计算:
再来看RTX 5070 Ti,RTX 5070 Ti比4070 Ti多了16%的核心,架构效能提升约15-20%。预计其性能将接近或略低于RTX 4080 Desktop。
- RTX 4080 Desktop Blender Score:约 7000 - 8000 分段。
在理论渲染性能上,M5 Max 的预测得分已经完全落入了RTX 5070 Ti的预期性能区间(7500-8500)。
这就解释了为什么会有“M5 Max 战平 RTX 5070 Ti”的说法。这并非空穴来风,而是基于严格的数据推算。
游戏场景的特殊性
当然,Blender不等于游戏,游戏还需要看驱动优化、API开销和光线追踪效率。
Nvidia 的优势在于RTX 5070 Ti 拥有第四代 RT Core,这是物理硬件上的壁垒。M5 Max 搭载第三代光线追踪引擎。虽然代数上落后,但M5引入了AI加速的降噪和插帧技术。如果 《赛博朋克 2077》开启路径追踪,RTX 5070 Ti可能依靠DLSS 4.0 领先;但在常规光追下,M5 Max有望持平。
DLSS 4.0 传闻将引入多帧生成,利用 Transformer 模型预测未来帧。MetalFX Upscaling和Frame Interpolation。随着M5神经引擎算力的4倍提升,MetalFX的画质和帧率增益将大幅缩小与DLSS 的差距。在原生支持Metal的3A大作中,M5 Max在4K分辨率下的帧数表现将与RTX 5070 Ti互有胜负。而在转译游戏中,M5 Max可能仍会落后10-15%,但这已经是“可玩”与“流畅”的区别,而非“不能玩”。
第五章:生态的觉醒,GPTK 2 与 3A 大作的“投名状”
硬件是躯体,软件是灵魂,M5 Max最强的盟友不是台积电,而是 Game Porting Toolkit 2 ,如果说GPTK 1.0 让玩家看到了希望,而 GPTK 2.0 则让开发者看到了商机。许多游戏依赖 AVX2 指令集,以前M芯片不支持导致无法运行或效率极低。GPTK 2 完美解决了这个问题,性能损耗极低。GPTK 2提供了从HLSL直接到Metal的转换工具。这意味着开发者不需要重写数百万行代码,只需要做少量的适配工作。Metal HUD、GPU Capture等工具的加入,让开发者可以像在Windows 上一样分析每一帧的渲染耗时。
- 育碧:《刺客信条:影》首发登陆 Mac
- CDPR:《赛博朋克 2077》终极版原生登陆 Mac,且支持光线追踪
- Capcom:《生化危机》系列几乎全家桶登陆 Mac
- Hideo Kojima:《死亡搁浅》导演剪辑版
这说明了什么?说明Mac的游戏市场潜力已经被3A厂商认可。当M5 Max的性能足以在4K下跑满这些游戏时,Mac将不再是游戏荒漠,而是一个高端、精致的游戏平台。
第六章:独立显卡市场的“灰犀牛”
回到问题的核心:M5 Max会给独立显卡市场带来什么冲击?
这种冲击不是“明天 Nvidia 就倒闭”,而是“温水煮青蛙”式的市场份额侵蚀。
冲击一:高端游戏本的“去魅”
RTX 5070 Ti 的 TBP 是 300W ,搭载它的游戏本,必然是为了散热,机身厚度感人,风扇起飞时的噪音堪比直升机,拔掉电源,性能瞬间腰斩,续航不足2小时。
而 M5 Max 的 MacBook Pro依然是 1.6cm - 2cm 的厚度,日常使用风扇停转,满载噪音极低,拔掉电源,性能 100% 保持,续航依旧长达 10 小时以上。
对于那些既需要性能又需要移动性的用户,M5 Max 将成为唯一的选择,高端 Windows 游戏本的市场空间将被大幅压缩,能轻便谁又愿意背着两块砖头出门呢?
冲击二:AI 民主化与 VRAM 的战争
这是 Nvidia 最不想看到的局面。
在AI 时代,显存即王道
RTX 5070 Ti 只有 16GB 显存,跑 Llama-3-70B那是痴人说梦,你必须进行极其激进的量化到2-bit 甚至更低,模型智商大幅下降。
M5 Max可以选配128GB内存。你可以轻松地把整个70B模型以FP16或Q8精度加载进内存,并且还能剩下几十G给系统。
大量的 AI 研究员、学生、独立开发者将抛弃Nvidia游戏卡,转投Mac阵营。因为买一张RTX 6000 Ada(48GB)要 5 万人民币,而一台128GB的MacBook Pro只要3万。性价比高下立判。M5 Max 将成为 “个人AI工作站” 的代名词。
冲击三:Nvidia的自我革命(ARM 计划)
最有趣的冲击在于,Nvidia自己也意识到了危机。
传闻Nvidia正联手联发科开发基于ARM 架构的 PC 芯片,代号 "DGX Spark" 或 "N1X" 31。
集成 Blackwell GPU 核心,MediaTek ARM CPU,目标性能直指RTX 4070移动版,功耗仅65W。这说明 Nvidia 承认了苹果路线的正确性——SoC+统一内存+ARM才是移动计算的未来。
M5 Max的强势表现,实际上是在逼迫Nvidia革自己的命。未来的笔记本市场,将不再是Intel/AMD CPU + Nvidia GPU的天下,而是Apple M系列 vs Nvidia-MediaTek SoC vs AMD Strix Halo的“三国杀”。独立显卡这一形态,在移动端将逐渐消亡。
M5 Max 能否彻底击败 RTX 5090?不能。那代表了人类在600W功耗下堆砌晶体管的物理极限,是工业级的暴力美学。
但M5 Max是否会击败 RTX 5070 Ti?大概率会,而且是在功耗仅为其 1/3、体积仅为其 1/10 的情况下击败它。
作为一名果粉,我看到的不仅仅是跑分的胜利,更是 “优雅”对“暴力”的胜利。
苹果用 M5 Max 告诉整个行业:
- 用户不需要为了性能忍受噪音和高温。
- 用户不需要为了 AI 忍受吝啬的显存。
- 用户不需要为了兼容性忍受低效的指令集。
这会给独立显卡市场带来什么冲击?
它敲响了 “中高端移动独显” 的丧钟。未来的笔记本,要么是极致轻薄的核显本,要么是全能强大的SoC本。那个“CPU + 独显”的拼凑时代,正在M5 Max的光芒下,缓缓落幕。