
把一个「隐形翻译官」戴在脸上是什么体验?——讯飞AI眼镜测评
2023、2024年,大家还都在讨论大模型、参数、榜单、Prompt工程,那是 AI 的炫技期。
而到了2025、2026 年,讨论的风向变了。特别是像Claude Code之类的出现,大家开始发现真正厉害的 AI,不再需要你打开一个网页、输入一段文字、等一个回答。AI正在从你去找它变成它就在那里。
比如,Rabbit R1 的爆火与速朽,证明了AI 硬件不是把 ChatGPT 塞进一个盒子;Ray-Ban Meta 的成功密码是它看起来根本不像 AI 设备。
大模型的下一站,不是更大的模型,而是更自然的载体。AI 产品竞争的战场,已经从谁更聪明转向了谁更无感。
而翻译这个需求,其实很适合隐身AI的战场。因为语言交流天然需要eye contact和即时反应,任何需要你低头看手机、等待翻译、再抬头回应的方案,都会破坏交流的自然感。
想象一下,当在地铁上遇到外国人问路,对方说完一串英语,我本来还想说pardon?眼镜已经把译文显示在眼前了。
参加一场日本客户的线上会议,全程靠眼镜同传,会后对方惊讶地问你会日语?
2026 年了,不会外语已经不是问题,问题是你的眼镜会不会。
一、为什么突然测这副眼镜?
其实我算是语言工具重度用户,翻译 App、翻译笔基本上都用过,但都有各自的痛点。
翻译 App的尴尬在于需要来回递手机,明明应该是自然顺畅的沟通,变得尴尬又低效。
线上会议的同传软件要么贵、要么延迟严重。
我一直在想,有没有一种方案,能让我既不用递手机、又能看到文字、还能在各种场景下无缝切换?
于是拿到讯飞AI眼镜,用了一周,写了这篇实测。
想看看AI 眼镜这种人机交互形态,到底是噱头,还是真正能让AI落地成人的关键一步?
二、外观与佩戴:它首先得是一副能戴得住的眼镜
先从最基本的开始,我认为AI眼镜测试的底层逻辑:如果戴不住,后面都是白搭。
- 重量:约40g,基本上和一只口红差不多重,同类的AI 眼镜 50g+,一副普通近视镜约 25-30g,佩戴体感上基本不会给增加额外负担。
- 佩戴体验:我测试了连续戴 2 小时(约一场会议的时间)的感受,完全没有夹头的感觉,耳部鼻梁压力也比较适当,能感受到佩戴结构是经过打磨的。
- 外观:摄像头、麦克风、充电口和按键的设置都比较小巧近乎隐形,镜腿比常规近视镜略宽一点,刚好把麦克风、电池等硬件收纳进去,整体依然轻巧自然。可以说AI眼镜进化到现在,已经算是不像科技产品的科技产品了,基本我们走在办公室/地铁里也不会突兀,不会说像是未来人穿越到现代。
- 近视方案:我自己有近视并且不习惯佩戴隐形眼镜,所以特别关注这款眼镜对近视眼的友好度。官方是有定制的配镜放方案的,包括一体式贴合镜片和卡扣式近视镜片。
三、核心功能深度实测
1、面对面翻译:再也不用跟外国人说pardon了
- 测试场景:在咖啡店和一位说英语的朋友聊天,模拟真实面对面交流。店里背景音不算小,磨豆机时不时轰一下,隔壁桌还在大声开会。
- 体验细节:
对方说话:对方说话的译文会出现在眼镜屏幕上。译文流畅自然,日常面对面沟通的准确度完全够用,对话节奏跟得上、不卡壳,比之前我用手机翻译 App 来回递、来回等的感觉强太多。
也要特别提醒近视的同学:屏幕采用虚像成像,近视的同学下单时一定要选官方配镜方案,才可清晰显示,无需另戴眼镜。
自己说话:我们自己就可以说中文,译文会出现在手机端来给对方看。这个交互逻辑还挺清晰的,眼镜在你脸上负责接收,手机朝向对方负责展示,分工自然,上手很快。
这里想多聊两句这副眼镜的收音方案。
它用了 5 颗气导麦克风 + 1 颗骨传导麦克风的阵列。什么意思呢?不是单纯把声音"收进来"就完事了,而是先判断声音从哪个方向来,再定向拾音。外观上完全看不出来藏了这么多麦,设计上藏得很干净。
同时还上了一个唇动识别降噪技术。前置摄像头会捕捉对方讲话时的嘴部状态,把视觉信号和声音信号做融合分析。实际效果就是:咖啡店里隔壁桌再吵,只要你的视线对着正在说话的人,看谁翻谁,旁边人的声音会被大幅过滤掉。

2、线上同传:跨国会议的最佳外挂
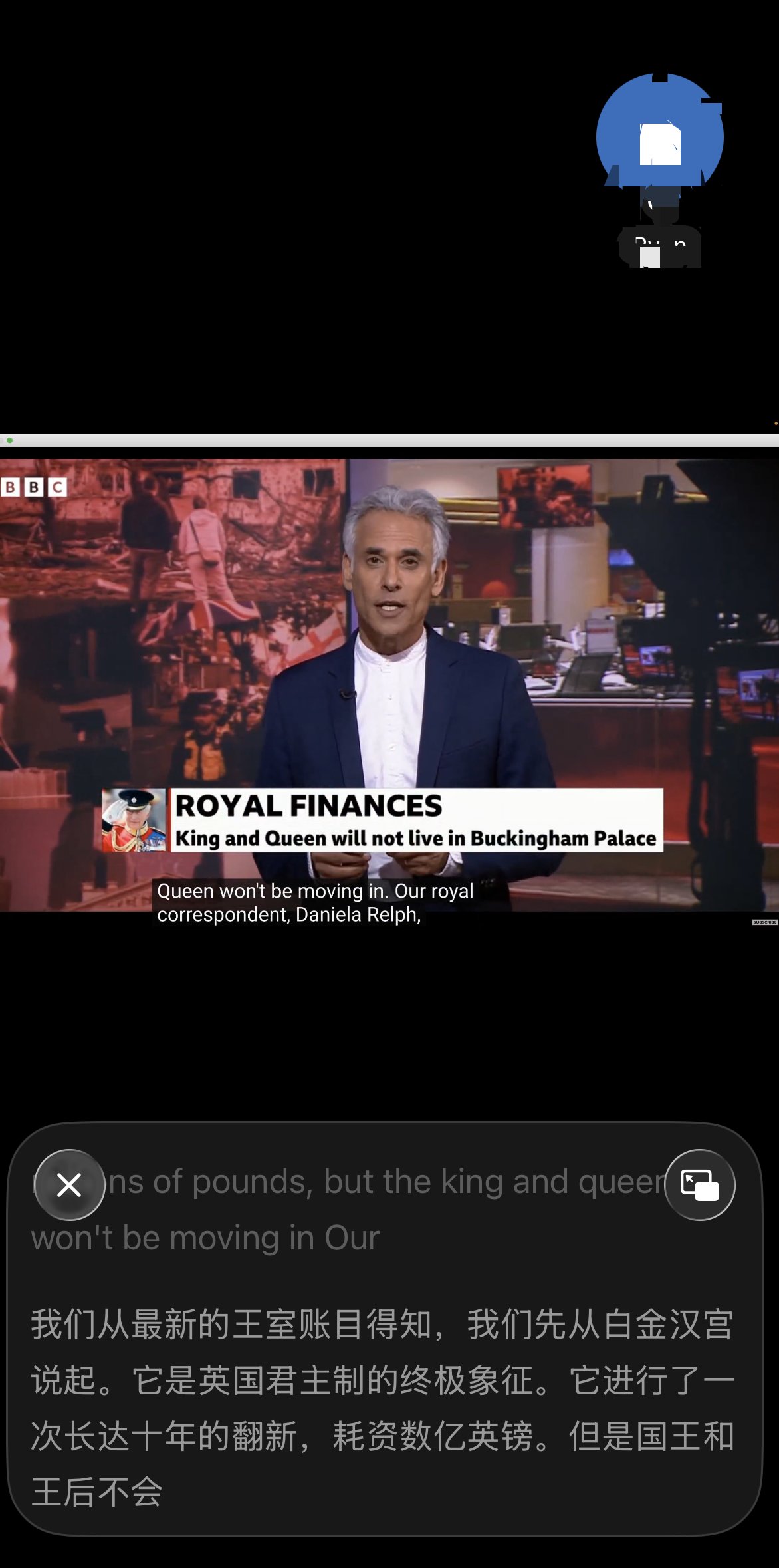
- 测试场景:参加一场英文 Zoom会议,全英文,讲的是海外市场数据复盘
- 体验细节:
连接步骤不复杂:眼镜和手机蓝牙配对 → 打开翻译 App → 点"线上同传" → 当前会议界面下方会出现双语字幕的悬浮窗。整个流程半分钟内搞定。
翻译延迟方面,跟上文面对面翻译差不多,大概小半句话的延迟。对于“听懂会议信息”这个需求来说完全够用。真正要参与讨论的时候,还是需要结合自己的英语基础去判断语境,不能 100% 依赖译文,但至少,再也不会出现整场会议只听懂了Hello everyone的尴尬。
3、旁听同传:听讲座、看脱口秀听懂全场的神器
测试场景:参加一场线下英文分享会,坐在约 5 米远的位置,大概第5排
这个功能的核心逻辑是“你只需要听懂,不需要互动”。 戴眼镜去听外国人的脱口秀、去听学术讲座、甚至去看海外演唱会,你的目的就是听懂台上在说什么,不是跟他对话,用这个模式就对了。
5 米距离实测:收音完全没问题,译文稳定实时显示。官方说推荐 0-8 米,最远能到 8-10 米拾音。我没有测极限距离,但 5 米这种常规座位表现很扎实。
还有一个我特别喜欢的设计:眼镜端可以直接操作。在眼镜的触控板上滑动,焦点选中翻译功能,双击就能开关。开启后还支持四件事:暂停/继续、字号调节、双语/仅原文/仅译文切换、结束翻译。完全不用掏手机,开会听讲座的时候特别体面,不会出现一直低头看手机的尴尬。

4、通话翻译:给老外打电话不再心跳加速
- 测试场景:打了一个真实的英文电话,订海外酒店。
- 体验细节
这是五个翻译模式里我最紧张的一个,因为打电话本身就有延迟+信号干扰的叠加风险。
实际体验下来,有一个设计让我印象深刻,接通后眼镜会先播放一段合成音:“您好,我正在使用翻译设备与您沟通,请不要挂断,谢谢!”(对方语种会自动匹配,英文就说英文版)。这个细节太重要了,因为老外接到一个不说话或者开场很奇怪的通话,第一反应就是挂断,这段提示音直接把信任成本降到了零。
双向翻译的延迟也在可接受范围。对方说的内容翻译成中文显示在眼镜上,我说中文、译文播报给对方。体感上没有明显冷场,对话节奏比我想象中流畅。作为"能顺利订到酒店"这个目标完全达标,对话节奏也比想象中流畅。
有一点要注意:通话翻译需要在 App 上手动开启,眼镜端目前不能直接触发。而且开启后翻译 App 可以放到后台,悬浮窗会继续显示译文,不影响用手机做别的事。
5、拍照翻译:菜单/路牌/说明书,看一眼就懂
- 测试场景:翻译一份英文菜单
- 体验细节:
对着菜单说"小飞小飞,拍照翻译",眼镜会自动拍照,照片传到 App 再上云端,多模态大模型处理后,翻译结果直接显示在眼镜屏幕上,同时 TTS 语音播报出来。
实测速度:从说话到看到译文,大概 3秒左右。准确度方面,菜单这种结构化文本表现很好,菜名翻译基本准确。菜单、说明书等文字识别都很准,复杂长句也能抓住关键信息,理解大意毫无障碍。
我个人觉得最实用的场景:出国点菜、看药品说明书、过边检看指示牌。 尤其是过边检的时候,掏出手机翻译看起来很慌张,戴眼镜扫一眼就优雅多了。

四、一些意外的亮点
翻译之外,有几个我本来没抱期待、但用了之后觉得还挺香的功能。
- 智能提词器:演讲或录视频的时候,眼镜屏幕上可以滚动显示你准备的讲稿内容。滚动方式有四种:匀速(慢/中/快速)、语义自动跟随(你讲到哪就自动跳到哪)、遥控器翻页、触控板滑动。我个人觉得语义跟随是最实用的,尤其是开会做汇报的时候,不用背稿、不用看手机、不用低头翻纸,照着念就行,体面又自然。
- AI 会议总结:针对翻译记录,可以生成会议摘要和待办事项,支持导出和二次编辑。实测摘要质量还挺靠谱的,不是那种"本次会议讨论了若干议题"的废话文学,关键信息和行动项基本能抓出来。
五、结语
测试下来,小遗憾当然是有的,包括目前不支持配老花镜,防水仅 IPX4,不是运动眼镜,下雨天要小心。
不过我已经感觉到对于像外贸/跨国业务从业者、经常参加国际会议/线上英文会议的人、留学生/访问学者,讯飞的这款AI眼镜确实能成为实打实的生产力工具,而对于经常出国自由行的人,也能够减轻语言带来的障碍。
的确,AI 翻译发展到今天,语言壁垒正在快速消融。但工具只是工具,真正跨越文化隔阂的,还是人本身。眼镜能翻译语言,翻译不了真诚。但至少,它让我们有了表达真诚的机会。
大模型卷到今天,参数量、多模态、推理速度已经不是瓶颈。瓶颈在哪里?在你愿意让它介入你的生活多深
手机上的 AI App 存在感太强:解锁、打开 App、输入文字、等回复,每一步都在提醒你“我在用 AI”。而 AI 眼镜的终极命题,就是把这个流程压缩到零。讯飞AI眼镜给出了一个清楚的路线图:随身、自然交互、场景自适应,这才是大模型落地的正确姿势。
也就是说,当技术隐身,人的连接才开始。这一次,我们终于不是在和机器对话,而是在和世界对话。