
内存与硬盘的速度真相:从晶体管到磁盘,一次说清计算机存储的实现原理
你有没有想过一个看似矛盾的现象:你的程序启动时慢悠悠,但一旦运行起来就飞快?
答案藏在 DDR 内存和硬盘之间——前者用纳秒(ns)级电容充放电工作,后者用毫秒(ms)级机械运动寻址。中间差了整整 6 个数量级。
这篇文章,我们从物理原理出发,把 DDR 内存、机械硬盘(HDD)、固态硬盘(SSD)的实现原理和速度真相,一次讲明白。
一、DDR 内存:纳秒级的速度魔法
DDR SDRAM(Double Data Rate Synchronous Dynamic Random-Access Memory)是计算机的主内存。它是易失性存储——断电即丢数据,但换来了纳秒级的极致速度。
1.1 核心原理:一个晶体管 + 一个电容
DDR 内存的根基是 DRAM(Dynamic RAM),其存储单元的核心结构只有两个元件:一个晶体管 + 一个电容,简称 1T1C。
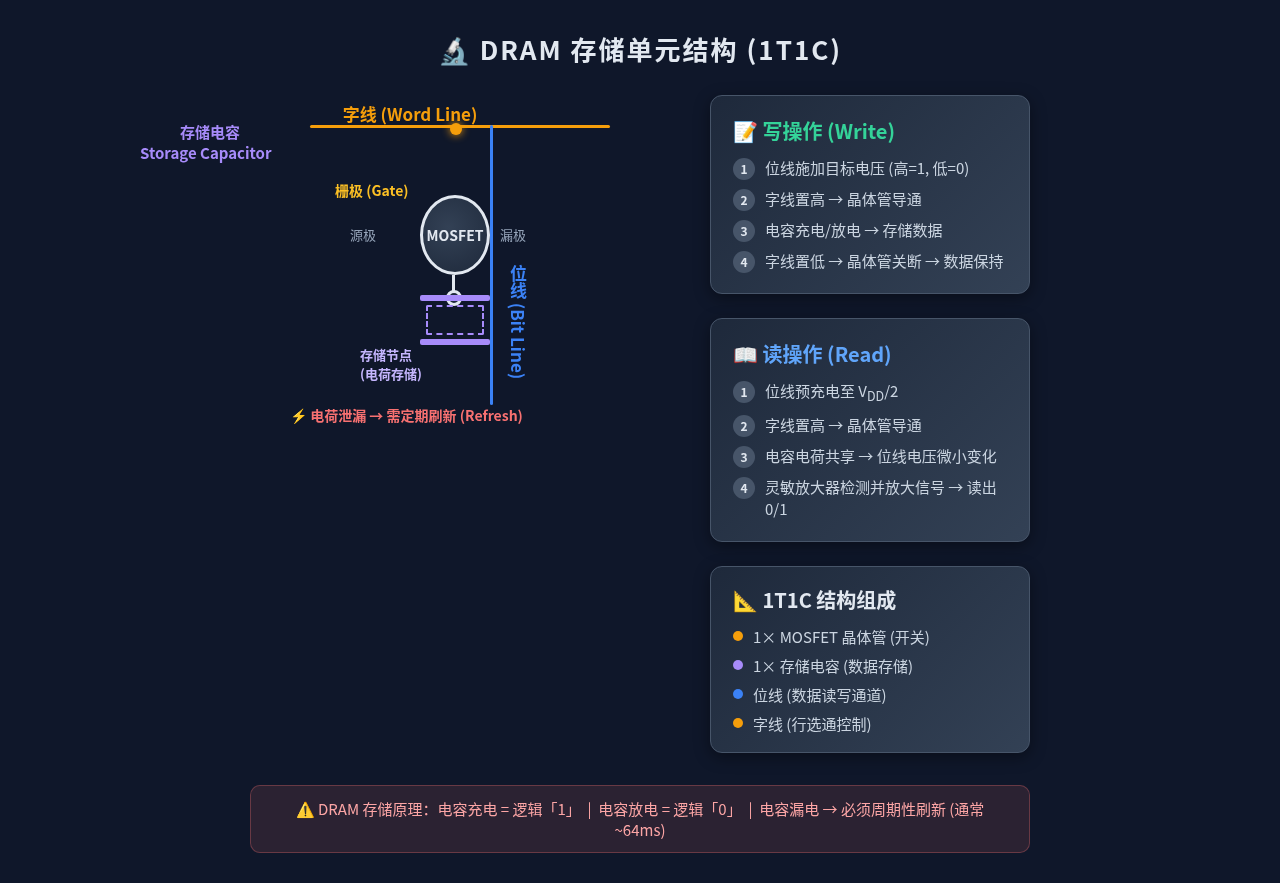
- 电容存储数据:充电代表"1",放电代表"0"
- 晶体管作为开关:字线(Word Line)选中时才将电容导通到位线(Bit Line)
- 电荷泄漏是 DRAM 名字中"Dynamic"的由来——电容中的电荷会在几十毫秒内自然泄漏殆尽,必须由内存控制器定期刷新(Refresh,典型周期 64ms)
读取过程分三步:
- 预充电:将位线电压拉到 Vdd/2
- 字线激活:打开晶体管,电容电荷共享到位线上,产生微小电压摆幅(~几十 mV)
- 读出放大器检测并放大到位线满摆幅,同时回写刷新该行所有电容
写入过程类似,只是将位线强制驱动到目标电压,字线打开后直接对电容充/放电。
正是因为每个单元只需要 1T1C(而 SRAM 需要 6T),DRAM 的单比特成本极低,才能做到 16GB、32GB 甚至 128GB 单条容量。
1.2 六代进化:从 SDRAM 到 DDR5
DDR 并不是一成不变的。自 1990 年代末至今,经历了六代重大进化:
| 参数 | SDRAM | DDR | DDR2 | DDR3 | DDR4 | DDR5 |
| 发布年份 | 1993 | 2000 | 2003 | 2007 | 2014 | 2020 |
| 电压 | 3.3V | 2.5V | 1.8V | 1.5V | 1.2V | 1.1V |
| 最高频率 | 133MHz | 200MHz | 533MHz | 1066MHz | 3200MHz | 6400+MHz |
| 预取位宽 | 1n | 2n | 4n | 8n | 8n | 16n |
| Bank Groups | — | — | — | — | 4 | 8 |
| 最高带宽 | 1.06 GB/s | 3.2 GB/s | 8.5 GB/s | 17 GB/s | 25.6 GB/s | 51.2 GB/s |
| 单条最大容量 | 256MB | 1GB | 4GB | 16GB | 64GB | 512GB |
预取(Prefetch)是理解 DDR 性能的关键概念。DDR 的 I/O 总线频率远高于内部存储阵列的工作频率:
- DDR4 用 8n 预取:内部阵列一次读出 8 个数据字,然后在 4 个时钟周期内分别以双沿(×2)输出 = 8 个数据包
- DDR5 升级到 16n 预取:一次预取 16 个数据字,配合 8 个时钟周期的双沿输出
这样一来,内部阵列只需以 I/O 频率的 1/8(DDR4)或 1/16(DDR5)工作,大幅降低了功耗和设计复杂度。
Bank Groups(存储体组)是另一个关键优化。DDR4 引入 4 个 Bank Group,DDR5 扩展到 8 个。每个 Bank Group 可以独立并行操作——当一个 Bank Group 在执行读取时,另一个可以同时进行刷新或预充电,显著提升了命令总线的利用率。
1.3 DDR5 的独有特性
片上 ECC(On-Die ECC):DDR5 每个芯片内置了错误纠正码。当存储阵列中的数据出现单比特错误时,在芯片内部自动纠正后再发送给 CPU。这不同于传统 ECC 内存(需要额外芯片和数据线),但对提高高密度存储的可靠性至关重要。
双子通道(Dual Subchannels):DDR5 DIMM 将原来的 64-bit 数据总线拆分为两个独立的 32-bit 子通道,每个子通道有自己的命令/地址总线。这使内存控制器能更细粒度地并发访问——相当于把一条高速公路拆成两条独立车道,对小数据块的随机访问更友好。
片上电压调节:DDR5 DIMM 自带 PMIC(电源管理 IC),将主板提供的 5V/12V 在内存条上直接转换为 1.1V 核心电压。相比 DDR4 由主板供电的方式,电压调节更靠近负载,噪声更低,稳定性更好。
1.4 速度公式:带宽怎么算?
DDR 的峰值带宽有一个简单的公式:
带宽 (GB/s) = 数据传输率 (MT/s) × 总线宽度 (bit) / 8以 DDR5-6400 为例:6400 MT/s × 64 bit / 8 = 51.2 GB/s
如果是双通道配置(128 bit),总带宽可达 102.4 GB/s。
但带宽不等于实际性能! 延迟才是决定"快不快"的关键。DRAM 访问延迟由四个核心时序参数决定:
| 时序参数 | 全称 | 含义 | 典型值(DDR5-6400) |
| CL (CAS Latency) | 列地址选通延迟 | 列地址发出到数据就绪的时钟周期数 | 32-40 cycles |
| tRCD | RAS to CAS Delay | 行激活到列选通的延迟 | ~14 ns |
| tRP | RAS Precharge | 关闭当前行到开启新行的延迟 | ~14 ns |
| tRAS | Row Active Time | 行保持激活的最短时间 | ~32 ns |
关键陷阱:CAS Latency 以时钟周期为单位,不是绝对时间!DDR5-6400 的 CL=32 看起来比 DDR4-3200 的 CL=16 "更大",但换算成纳秒:
- DDR4-3200 CL16: 16 / 1600MHz = 10 ns
- DDR5-6400 CL32: 32 / 3200MHz = 10 ns
绝对延迟完全相同! 这是因为延迟受限于 DRAM 存储阵列的物理访问时间,频率提升只增加了带宽,并没有缩短内部延迟。
DDR3、DDR4、DDR5 三代内存的真实 CAS 延迟都稳定在 ~14 ns 左右——这是 DRAM 电容充放电的物理极限。
二、机械硬盘(HDD):毫秒级的机械之美
机械硬盘是计算机中最"古老"的存储设备——从 1956 年 IBM 推出第一台 5MB 硬盘至今,近 70 年。它用磁性材料和精密机械实现了大容量、低成本的数据持久存储,但速度受限于物理运动。
2.1 整体结构:盘片、磁头与电机
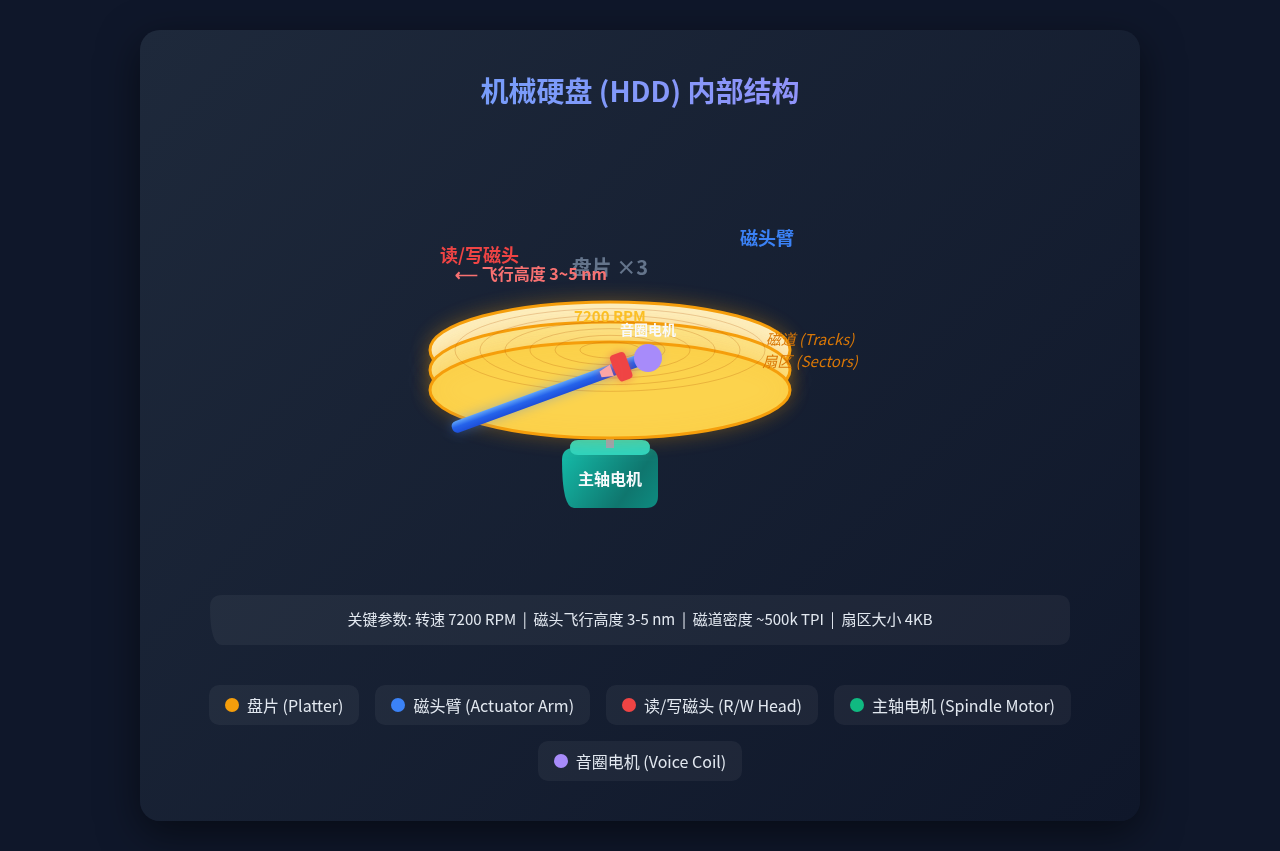
一块现代 HDD 由以下核心组件构成:
| 组件 | 工作原理 | 关键技术 |
| 盘片(Platters) | 铝合金/玻璃基底 + 钴基磁性薄膜 | 表面粗糙度 < 0.3nm |
| 读/写磁头(R/W Head) | TMR(隧道磁阻)传感器读取;单极写入极写入 | 2007 诺奖技术 |
| 音圈电机(VCA) | 类似扬声器音圈,通电线圈在永磁体磁场中移动 | 寻道加速度 30-60G |
| 主轴电机 | 无刷直流电机驱动盘片旋转 | 5400/7200/10000/15000 RPM |
最惊人的数字——磁头飞行高度:盘片高速旋转产生空气轴承效应,使磁头悬浮在盘面上方仅 3-5 纳米,相当于 DNA 双螺旋的直径。一旦磁头坠落接触盘面(Head Crash),数据就永久损坏了。
2.2 数据如何存储:磁畴翻转与 PMR
HDD 的数据存储在磁畴(Magnetic Domain)中。磁畴是盘片磁性薄膜中被磁化的微小区域:
- 数据编码:相邻磁畴之间的磁化方向翻转代表"1",无翻转代表"0"
- 记录方式:
- LMR(纵向记录):磁化方向平行于盘面,面密度极限 ~100-200 Gb/in²(已淘汰)
- PMR(垂直记录):磁化方向垂直于盘面,2005 年突破 LMR 瓶颈,面密度可达 ~1.5 Tb/in²
- SMR(叠瓦记录):磁道像屋顶瓦片一样部分重叠,面密度再提升 25-30%,但随机写入性能下降
超顺磁极限(Superparamagnetic Limit):当磁畴小到一定程度时,热扰动会随机翻转磁化方向——这是 HDD 面密度的理论天花板。HAMR(热辅助磁记录)通过激光瞬间加热写入点至 ~450°C 来突破这个极限,Seagate 已在 2023 年量产 30TB HAMR 硬盘。
2.3 速度分析:三重延迟
HDD 的访问延迟来自三个物理过程叠加:
| 延迟成分 | 7200 RPM 典型值 | 说明 |
| 寻道时间(Seek) | ~9 ms | 磁头移动到目标磁道 |
| 旋转延迟(Rotational) | ~4.17 ms | 等待目标扇区旋转到磁头下方 |
| 传输时间(Transfer) | ~0.05 ms(4KB) | 实际传输数据 |
| 合计 | ~13 ms | 每次随机 I/O |
顺序读写速度:200-250 MB/s(外圈)→ ~150 MB/s(内圈)。由于外圈周长更大,采用 ZBR(区域位记录)技术后外圈比内圈快 50-70%。
随机 IOPS:仅 100-200。每秒钟只能完成约一百多次独立的随机小数据读写——这是 HDD 最致命的短板。
三、固态硬盘(SSD):微秒级的电子存储
SSD 打开了一个新世界:完全去掉机械部件,用半导体存储。从 SATA SSD 到 NVMe Gen5,速度提升了 20 倍以上。
3.1 NAND Flash 存储单元:浮栅晶体管
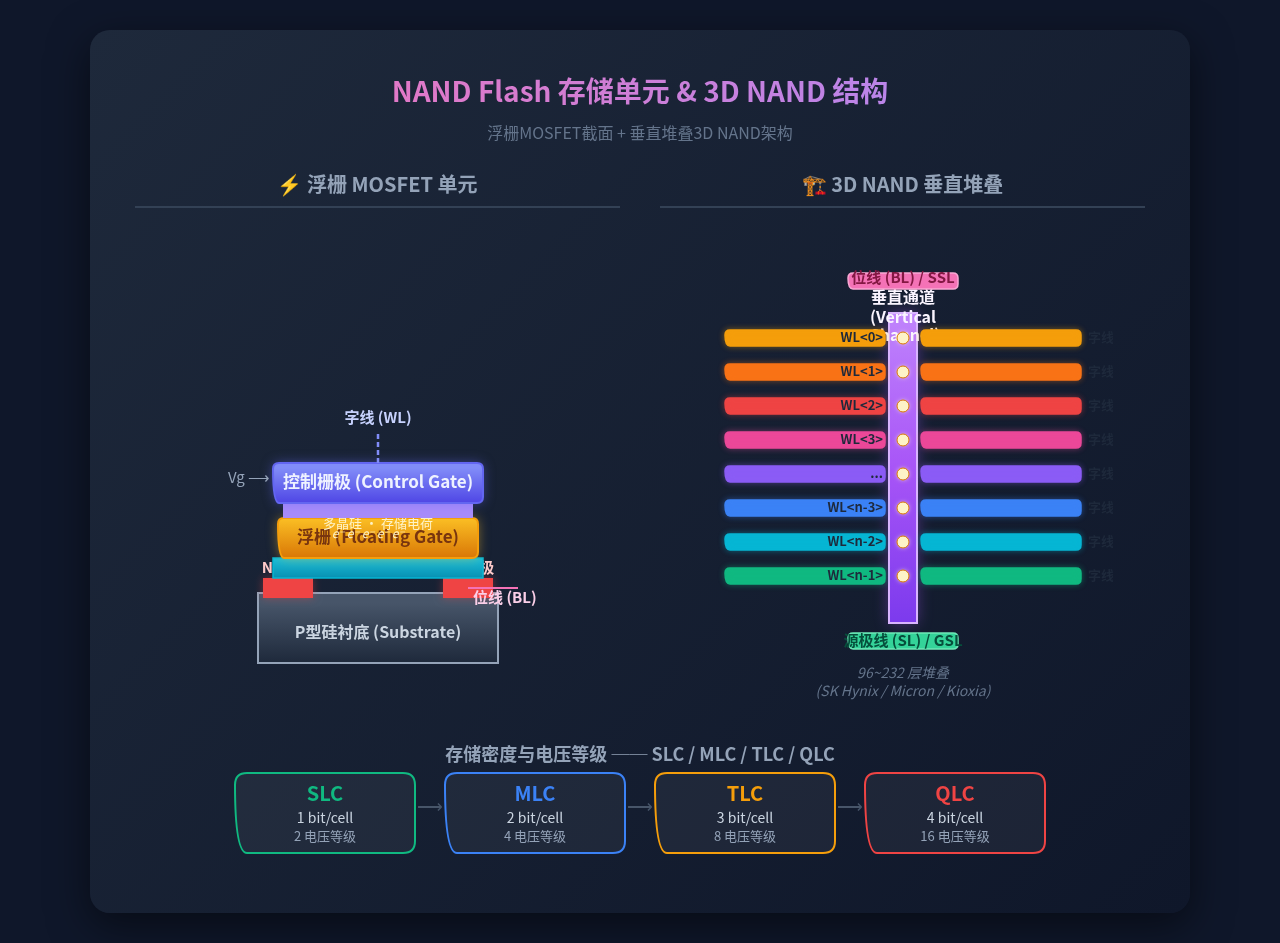
NAND Flash 的基本单元是一个浮栅场效应晶体管(Floating Gate MOSFET)。与传统 MOSFET 不同,它在控制栅极和沟道之间嵌入了一个被绝缘氧化层完全包裹的浮栅。
Fowler-Nordheim 隧穿效应是实现编程和擦除的物理机制:
| 操作 | 原理 | 效果 |
| 编程(Program) | 控制栅极高正压(~20V),电子从沟道隧穿进入浮栅 | 浮栅获得电子 → Vth 升高 → 逻辑"0" |
| 擦除(Erase) | 衬底高正压(~20V),电子从浮栅隧穿回沟道 | 浮栅失去电子 → Vth 降低 → 逻辑"1" |
| 读取(Read) | 控制栅施加读取电压,检测漏极电流 | 电流大 = 低 Vth = "1",电流小 = 高 Vth = "0" |
每单元可存储的比特数决定了 NAND 的类型:
| 类型 | 每单元位数 | 电压等级数 | P/E 周期 | 相对密度 |
| SLC | 1 bit | 2 | 50,000-100,000 | 1× |
| MLC | 2 bit | 4 | 3,000-10,000 | 2× |
| TLC | 3 bit | 8 | 1,000-3,000 | 3× |
| QLC | 4 bit | 16 | 500-1,000 | 4× |
每增加一个 bit,电压等级翻倍,相邻状态间的电压窗口缩小,编程需要更精密的步进脉冲——代价是写入速度下降、误码率上升、寿命急剧缩短。
3.2 3D NAND:从平面到垂直
2013 年三星推出首款 3D V-NAND,将 NAND 从平面"竖起来":
- 多层字线(金属/多晶硅栅极)垂直堆叠
- 垂直通道贯穿所有层,采用Macaroni 结构(高 k 介质空心圆柱 + 通道多晶硅外壁)
- 电荷存储在每一层的 SiN 陷阱层(电荷陷阱闪存 CTF),替代传统浮栅
层数演进(从 2013 年至今,每年增加约 30-50 层):
2013: 24层 → 2016: 64层 → 2020: 128层 → 2022: 232层 → 2024: 321层 → 研发中: 400+层3D NAND 的极限预计在 800-1000 层。
3.3 SSD 控制器:FTL 是灵魂
SSD 的性能不只取决于 NAND,控制器才是核心。它的关键任务是 FTL(Flash Translation Layer,闪存转换层):
| 功能 | 作用 |
| 地址映射 | 将主机 LBA(逻辑块地址)映射到 NAND PBA(物理块地址),支持页级映射 |
| 磨损均衡 | 均衡所有块的擦除次数,防止热数据区域过早耗损 |
| 垃圾回收(GC) | 回收无效页,擦除整块后重新使用 |
| TRIM | 操作系统通知 SSD 哪些数据已删除,减少写放大 |
| SLC 缓存 | 将部分 TLC/QLC NAND 配置为 SLC 模式高速写入,空闲时合并回主存储 |
写放大因子(WAF)是理解 SSD 性能衰减的关键指标:
WAF = NAND 实际写入量 / 主机请求写入量理想状态 WAF=1,但在碎片化严重的 QLC 盘上可达 10+。这就是为什么 SSD 用着用着会变慢——SLC 缓存耗尽后,写入速度可能下降到初始的 1/3 甚至更低。
3.4 速度分析:从 SATA 到 NVMe Gen5
| 接口 | 理论带宽 | 顺序读(典型) | 4K 随机读 IOPS | 访问延迟 |
| SATA III | 600 MB/s | 550 MB/s | ~90,000 | ~100 µs |
| NVMe Gen3 ×4 | 3.94 GB/s | 3,500 MB/s | ~750,000 | ~70 µs |
| NVMe Gen4 ×4 | 7.88 GB/s | 7,000 MB/s | ~1,000,000 | ~50 µs |
| NVMe Gen5 ×4 | 15.75 GB/s | 12,000+ MB/s | ~1,500,000 | ~25-50 µs |
SATA vs NVMe 的本质差异:
- SATA/AHCI:为机械硬盘设计,1 个命令队列,每队列最多 32 条命令,顺序处理
- NVMe:为闪存原生设计,65535 个队列,每队列最多 65535 条命令,完全并行处理
这就像一条单车道 vs 65535 条高速公路并行的区别——SATA 协议本身就是速度瓶颈,即使配再快的 NAND 也无法突破 ~550 MB/s。
四、横向对比:三者巅峰对决
把所有数字放在一起,差距一目了然:
| 指标 | DDR5-6400 | NVMe Gen5 SSD | SATA SSD | HDD 7200RPM |
| 顺序读取 | 51.2 GB/s | 12 GB/s | 0.55 GB/s | 0.25 GB/s |
| 随机 IOPS(4K) | ~5,000,000 | ~1,500,000 | ~90,000 | ~100 |
| 访问延迟 | ~14 ns | ~50 µs | ~100 µs | ~10 ms |
| 延迟(相对) | 1× | 3,600× | 7,100× | 714,000× |
| 容量上限 | 512 GB/条 | 8 TB | 8 TB | 32 TB |
| 每 GB 成本 | ~3.5</td><td>~0.055 | ~0.05</td><td><strong>~0.014 | ||
| 断电数据保持 | 易失(毫秒) | >10 年 | >10 年 | >10 年 |
| 写入寿命 | 无限 | P/E 有限(TBW) | P/E 有限 | 无限 |
几个值得深入思考的结论:
1. "快"和"便宜"不可能兼得。 HDD 每 GB 仅 $0.014,但比 DDR5 慢 70 万倍。DDR5 快到极致,但每 GB 贵 250 倍,且断电即丢。
2. SSD 是当前的最佳折中。 比 HDD 快 3-4 个数量级(延迟),比 DDR 便宜约 60 倍,还能持久存储。NVMe Gen5 的 12 GB/s 速度已经比十年前的 DDR3 内存还快——想想这个进步有多惊人。
3. 层次化存储是必然的设计哲学。 从 CPU 寄存器(1ns)到 L1/L2/L3 缓存到 DDR 内存到 SSD 到 HDD,每下降一层,延迟增加 10-1000 倍,但容量也增加 10-1000 倍,成本降低 10-100 倍。这不是"设计选择",而是物理定律决定的必然结果。
| 层次 | 延迟 | 容量 | 每 GB 成本 | 速度/成本比 |
| L1 缓存 (SRAM) | ~1 ns | 64 KB | 极高 | — |
| DDR5 内存 | ~14 ns | 64-512 GB | ~$3.5 | 高 |
| NVMe SSD | ~50 µs | 1-8 TB | ~$0.055 | 中 |
| HDD 机械盘 | ~10 ms | 4-32 TB | ~$0.014 | 低 |
五、总结与展望
三种存储技术——DDR、HDD、SSD——各自在不同的物理原理上运行,有着截然不同的速度-容量-成本曲线。理解它们的实现原理,才能真正理解为什么你的程序"启动慢但运行快"。
DDR 内存的演进方向是更宽的预取、更多的 Bank Group、更低的功耗(DDR5: 1.1V → 未来 DDR6 可能降至 1.0V 以下)。但 DRAM 的核心物理延迟(~14ns)在可预见的未来很难突破——这是电容充放电的极限。
HDD 机械盘依靠 HAMR(热辅助磁记录)和更多盘片堆叠继续冲击 50TB+ 容量。它在大容量冷数据存储领域的成本优势无可替代——全球数据中心中仍有 60-70% 的数据存储在 HDD 上。
SSD 固态盘的未来是更多层的 3D NAND(2024 年已达 321 层,2026 年向 400+ 层冲刺)、PLC(5 bit/cell)高密度存储、以及 NVMe Gen6(31.5 GB/s)和 CXL 接口的新型存储级内存。但 QLC/PLC 的寿命和性能衰减是必须正视的挑战。
对于普通用户和开发者:了解这三种存储的速度差距,是写出高性能代码的基础。如果你的程序频繁访问磁盘,即使算法是 O(1),实际延迟也是毫秒级——相当于在 DDR 的世界里"等了一个世纪"。
下一站预告:我们将深入 CPU 缓存(L1/L2/L3) 的实现原理,看看 SRAM 是怎么用 6 个晶体管做到比 DRAM 快 10 倍的——以及为什么它只能做这么小。
*本文所有速度数据基于公开的 JEDEC 标准、厂商白皮书和行业基准测试。DDR5 带宽按 JEDEC 标准速率计算,实际 XMP/EXPO 超频配置可达更高频率。*