
单卡1000 TFLOPS,摩尔线程旗舰级计算卡首曝,性能逼近Blackwell
摩尔线程 MTT S5000 实现了对 GLM-5 的 Day0「发布即适配」。
在国产 AI 算力领域,硬件性能的堆叠往往只是入场券,而软硬协同的生态适配才是决定胜负的关键。随着智谱 AI 最新一代「国模顶流」GLM-5 的发布,这一 Coding 能力位居全球开源第一、总榜第四的模型迅速引发了行业热议。
与此同时,摩尔线程宣布其 AI 旗舰级计算卡 MTT S5000 实现对 GLM-5 的 Day0「发布即适配」,并首次披露了硬件性能参数,不仅单卡算力 1000 TFLOPS,并提供原生 FP8 支持,在显存容量、互联带宽上也与英伟达 H100 对标。从 2024 年推出至今,这款专为训推一体设计的全功能 GPU 智算卡,不仅在纸面参数上对标国际主流产品,更在智源研究院、硅基流动等头部机构的实战检验中,展现出挑战英伟达高端算力的统治力。
摩尔线程究竟做对了什么,使其能够从 GLM-4.6 一路无缝衔接到 GLM-5,让「零时差」适配成为国产算力的常态?
生态的飞跃,GLM-5「Day-0」适配背后的全栈协同
此次 GLM-5 发布即适配的背后,是摩尔线程软硬协同技术路线的集中爆发。作为定位 Agentic Engineering 的旗舰模型,GLM-5 相较上一代性能提升 20%,对长序列推理和复杂系统工程能力提出了极高要求。MTT S5000 凭借充沛的算力储备与对稀疏 Attention 的架构级支持,在大规模上下文处理中依然保持了高吞吐与低延迟,完美承接了 GLM-5 在长程 Agent 任务中的计算需求。
更关键的是,MUSA 软件栈的敏捷性成为了实现「Day-0」适配的胜负手。基于 MUSA 架构的 TileLang 原生算子单元测试覆盖率已超过 80%,使得绝大多数通用算子可直接复用,极大降低了移植成本。
通过高效算子融合及框架极致优化,MTT S5000 在 GLM-5 的运行中展现了极低的首字延迟(TTFT)和流畅的生成体验,特别是在函数补全、漏洞检测等 Coding 核心场景中表现优异。
硬实力的底气,S5000 性能逼近 Blackwell
MTT S5000 性能的首次全面曝光,揭示了国产 GPU 在架构设计与集群扩展上的成熟度。作为摩尔线程第四代 MUSA 架构「平湖」的集大成者,S5000 在单卡规格上能力接近国际一流水平,搭载 80GB 显存,显存带宽高达 1.6TB/s,卡间互联带宽达到 784GB/s,单卡 FP8 算力更是飙升至 1000 TFLOPS,在显存、卡间互联、单卡算力上与英伟达 H100 基本一致。
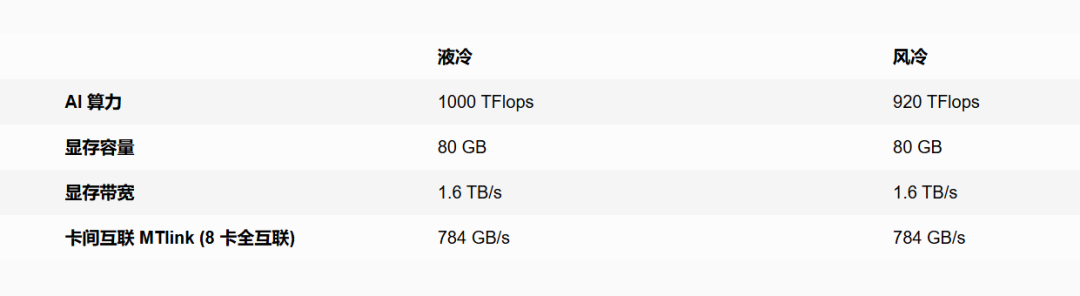
此外,MTT S5000 对 FP8 到 FP64 全精度计算的完整支持,特别是硬件级 FP8 Tensor Core 的引入,成为了其性能跃升的核心引擎。据接近测试项目的行业人士透露,MTT S5000 在产品精度层面已超越 H100,技术特性更逼近英伟达下一代 Blackwell 架构。
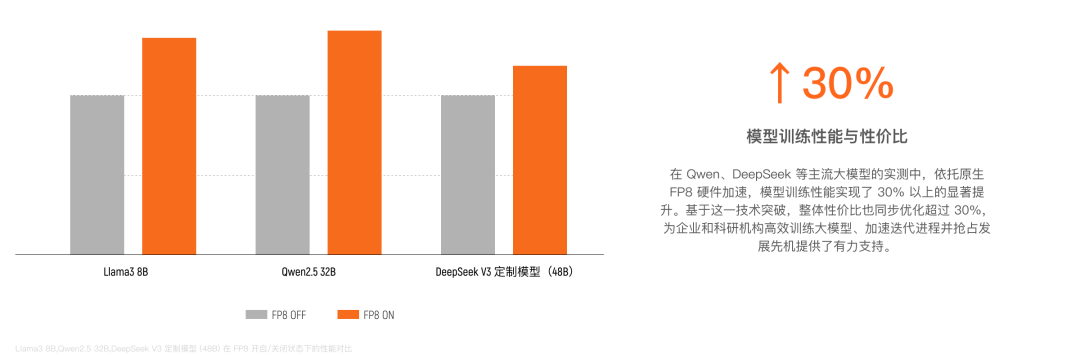
来自互联网厂商场景的实测反馈,进一步印证了其在算力上的优势。数据显示,在典型端到端推理及训练任务中,MTT S5000 的性能约为竞品 H20 的 2.5 倍。分析指出,这主要得益于其高达 1000 TFLOPS 的单卡算力,在绝大多数计算密集型场景中,该卡不仅能提供更强劲的算力输出,也在整体性价比上展现出显著优势。
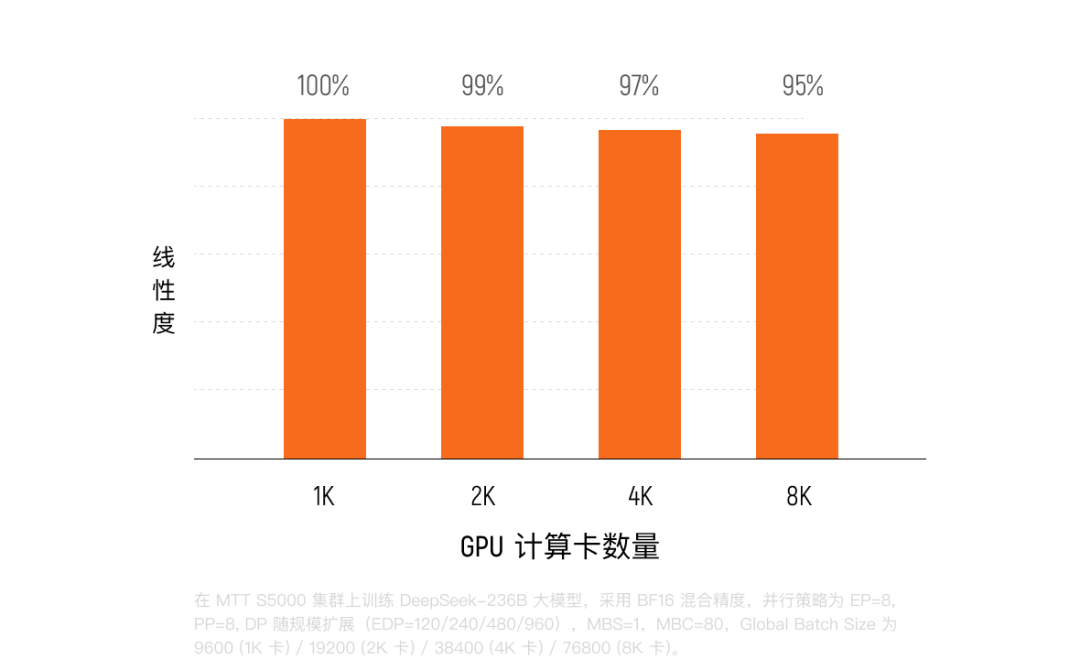
基于 S5000 构建的「夸娥」万卡集群,其浮点运算能力已达 10Exa-Flops 级别,标志着国产算力在超大规模集群层面迈入了世界前列。在该集群的实测中,S5000 展现了极高的算力利用率(MFU),Dense 模型训练中 MFU 达 60%,MoE 模型维持在 40% 左右,Flash Attention 算力利用率更是超过 95%。这得益于摩尔线程独创的 ACE 技术,该技术通过将复杂的通信任务从计算核心卸载,实现了物理级的「通信计算重叠」,从而释放了 15% 的被占算力。

实测数据显示,从 64 卡扩展至 1024 卡,系统始终保持 90% 以上的线性扩展效率,这意味着训练速度随算力增加几乎实现了同步倍增,有效训练时间占比超过 90%。
顶尖模型训练与推理中的实战中,对标 H100
参数之外,真实的落地案例是检验算力成色的唯一标准。摩尔线程 S5000 在训练与推理两大核心场景中,均交出了令人信服的答卷。在训练端,2026 年 1 月,智源研究院利用 S5000 千卡集群完成了前沿具身大脑模型 RoboBrain 2.5 的端到端训练与对齐验证。结果显示,其训练过程与英伟达 H100 集群高度重合,训练损失值(loss)的差异仅为 0.62%,这证明了 S5000 在复现顶尖大模型训练流程上的精准度与稳定性。用户依托 MUSA 全栈软件平台,能够原生适配 PyTorch、Megatron-LM 等主流框架,实现「零成本」的代码迁移,真正做到了兼容国际主流 CUDA 生态。

在推理端,S5000 的表现同样刷新了国产 GPU 的纪录。2025 年 12 月,摩尔线程联合硅基流动,针对 DeepSeek-V3 671B 满血版进行了深度适配与性能测试。得益于 S5000 原生 FP8 能力与 SGLang-MUSA 推理引擎的深度优化,在 PD 分离的部署中,单卡 Prefill(预填充)吞吐量超过 4000 tokens/s,Decode(解码)吞吐量超过 1000 tokens/s。这一成绩不仅大幅降低了显存占用,更在高并发场景下保证了极低的响应延迟。配合首创的细粒度重计算技术,S5000 将开销降至原有的 1/4,全方位提升了系统吞吐量,证明了其作为高性能在线推理服务底座的卓越实力。

从 GLM-4.6、GLM-4.7 到如今的 GLM-5,摩尔线程通过一次次「发布即适配」的实战,证明了国产全功能 GPU 及 MUSA 软件栈已具备极高的成熟度。这种对前沿模型结构与新特性的快速响应能力,不仅为开发者提供了第一时间触达最新模型能力的通道,也为行业筑牢了一个坚实、易用且具备高度兼容性的国产算力底座。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。