
今日问题-ddr或hbm怎么使用数据更快
1.前言
我再群里看到这个消息。
鹏哥说,hbm2e 最多8层,每层2g,一个stack 16gb,6个stack就是96gb,一个stack可以做到1024 bit位宽,所以6个stack用12个512bit的内存控制器。感觉他每个page都是交织在各个hbm stack上的
只要你以64byte(64=512/8)读写。hbm的性能总能打满。
1.1 分析
我见过的npu的ddr,比如2g*8等于16g内存的内存,连接到一个npu,地址线是并行连接到每个内存的地址引脚的,所以数据是交叉存储的,但是虚拟地址连续。
1)例子
下面描述8个ddr,每个ddr的位宽是32bit。
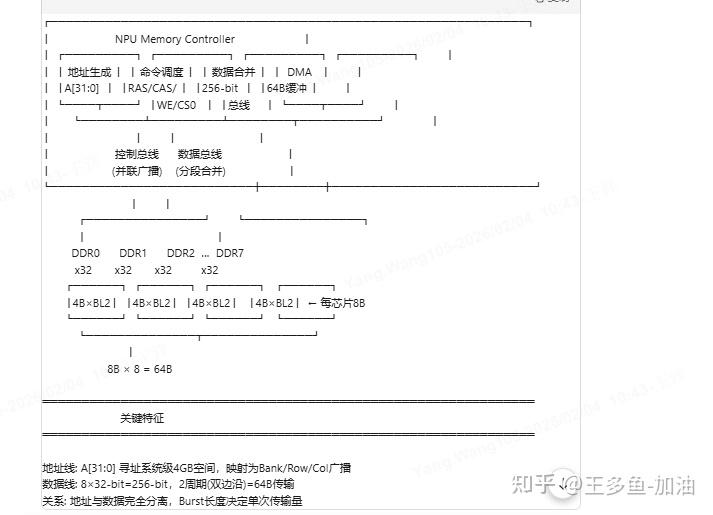
8B是一个芯片的能力参数,由芯片规格决定。
芯片能力参数分解
| 参数 | 典型值 | 决定因素 |
|---|---|---|
| 位宽 (x16/x32) | 16-bit 或 32-bit | 芯片引脚设计 |
| Prefetch | 8n (DDR4/5) | 芯片内部架构 |
| Burst Length | BL=2 或 BL=4 | 模式寄存器配置 |
8B 如何计算
以 x32 DDR4 为例: 芯片内部: 32-bit × Prefetch(8) = 256-bit = 32B (一次内部读取)
但受限于引脚位宽,分多次输出: BL=2 模式: 32-bit × 2 = 64-bit = 8B (芯片实际输出)
BL=4 模式: 32-bit × 4 = 128-bit = 16B (芯片实际输出)8B = 芯片引脚位宽(32b) × Burst Length(2) / 8
所以,我只要一次访问全部ddr的数据位宽对应的数据size,就能充分利用npu的ddr的带宽。
1.2 dma的区别
传统多DDR配置:
CPU/DMA → 内存控制器 → 广播地址到8个DDR芯片
↓
每个DDR返回64-bit数据
↓
合并为512-bit返回
HBM配置:
CPU/DMA → 内存控制器 → 独立通道控制(128-bit x 8)
↓
TSV直接访问各层
↓
1024-bit并行返回DDR并行架构(如NPU常用的LPDDR4/5):
- 不是"每个DDR芯片都有独立DMA"
- 而是:一个内存控制器管理多个rank/bank,通过 address mapping 将连续地址分散到不同物理芯片
- 例如:8个DDR芯片组成512-bit接口,地址线并行,但每个芯片提供64-bit数据,组合成512-bit bus
HBM的演进:
- 传统DDR:通过增加芯片数量扩展位宽(外部并行)
- HBM:在Stack内部完成位宽扩展(3D堆叠),对外已是1024-bit宽接口
| 概念 | 传统DDR的做法 | HBM的做法 |
|---|---|---|
| 地址线连接 | 共享地址总线,所有芯片接收相同地址 | 每个Stack独立寻址,或内部通道独立 |
| 数据交织 | 通过 Burst长度 和 Bank interleaving 实现 | 通过 Wide interface + Channel interleaving |
| 物理结构 | 多芯片并联,位宽扩展(如64-bit→512-bit) | 3D堆叠,TSV垂直互联 |
1.3如果我访问的数据比较小,或者分布比较散。那我有什么代价
✓ 对齐访问: 地址 % 64B == 0
✓ 连续访问: 64B, 128B, 256B...
✓ 顺序访问: 地址递增
✗ 随机8B访问: 只用到1/8带宽
✗ 非对齐访问: 跨边界需两次传输| 条件 | 操作 | 结果 |
|---|---|---|
| 访问粒度 = 总线位宽 ÷ 8 | 一次读/写 | 100%带宽利用率 |
| 访问粒度 < 总线位宽 ÷ 8 | 多次传输 | 带宽浪费 |
1)画图总结:


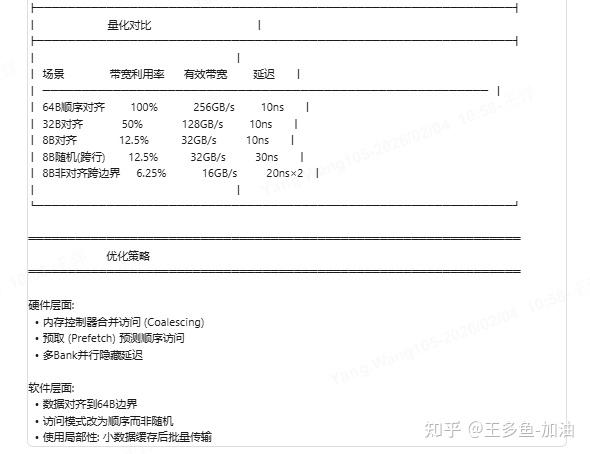
到这里我们就发现了,不同数据块,这带宽利用率有非常大区别。并且我们都知道模型运行主要的瓶颈是访问瓶颈。无论是vit还是llm都是访存瓶颈。
2. 这和cuda的多线程访存合并有什么关系
┌─────────────────────────────────────────────────────────────┐
│ CUDA访存合并 ↔ NPU DDR并行访问 本质相同 │
├─────────────────────────────────────────────────────────────┤
│ │
│ CUDA GPU NPU DDR │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ 32线程/Warp │ │ 8芯片并行 │ │
│ │ 同时发地址 │ │ 同时发地址 │ │
│ │ 合并成1次 │ ←────────────→ │ 广播同地址 │ │
│ │ 128B事务 │ │ 取64B数据 │ │
│ └─────────────┘ └─────────────┘ │
│ │
├─────────────────────────────────────────────────────────────┤
│ 核心原理 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 都是: 零散地址 → 合并/广播 → 宽总线传输 → 带宽最大化 │
│ │
│ CUDA合并条件: │
│ • 线程0-31访问连续地址 (如0x1000, 0x1004, 0x1008...) │
│ • 合并为128B (32线程×4B) 或 256B事务 │
│ • 分散地址 → 多次事务,性能暴跌 │
│ │
│ NPU并行条件: │
│ • 访问64B对齐地址 │
│ • 广播到8芯片,各取8B │
│ • 小访问 → 带宽利用率低 │
│ │
├─────────────────────────────────────────────────────────────┤
│ 类比关系 │
├─────────────────────────────────────────────────────────────┤
│ │
│ CUDA Warp (32线程) ≈ NPU 8-DDR并行 │
│ Thread访问粒度(4B) ≈ 单芯片位宽(4B/8B) │
│ 合并后事务(128B) ≈ 总线传输粒度(64B) │
│ 分散访问(非合并) ≈ 小/随机访问 │
│ Bank Conflict ≈ 行缓冲失效 │
│ │
├─────────────────────────────────────────────────────────────┤
│ 共同优化策略 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 1. 地址对齐: 线程id×4 对齐128B / 地址对齐64B │
│ 2. 连续访问: 线程顺序访问 / 顺序扫描数据 │
│ 3. 避免分散: 结构体SOA布局 / 数据预取合并 │
│ │
│ 本质: 将随机/小访问模式 → 转换为宽总线突发传输 │
│ │
└─────────────────────────────────────────────────────────────┘编辑于 2026-02-04 · 著作权归作者所有