如何评价 AMD Ryzen AI Halo ?
Zen 5 CPU 核心只是配角,真正的关键是那块 307mm² 的 SoC 芯片——上面塞了 40 个 RDNA 3.5 计算单元、32MB MALL 缓存、XDNA 2 NPU,还有 256 位宽的 LPDDR5x 内存控制器。它把统一内存架构做进了 x86 里,不再需要显存这条线。
重点来了,那个所谓性能块3 倍的数字有猫腻
苏妈说Ryzen AI Max+ 395 比 RTX 5080 快 3 倍——这虽然是真实数据,真实测试。但这个测试考的不是速度,是容量。
DeepSeek R1 满血版跑不起来,因为 RTX 5080 只有 16GB 显存,2350 亿参数塞不进去。塞不进去怎么办?溢到系统内存里,通过 PCIe 总线慢慢传——这条总线比显卡自带显存慢一个数量级,结果就是输了。
AMD 这台机器赢,不是因为快,是因为它能跑动,而 5080 压根跑不动。
所以这个 3 倍,正确翻译是:
这台机器能跑一些 5080 物理上跑不了的模型,但跑起来很慢。
重点是
大家说的的 1499 美元的价格,和跑 235B 的那台,不是同一台机器
1499 美元那台是 GMKtec EVO-X2,配置是 64GB 内存加 1TB 硬盘。
2350 亿参数塞不进去。70B dense 模型开正常量化也塞不进去。
跑发布会的演示机是 128GB 版本,价格是 2199 到 2299 美元。你看到的 1499 和跑 235B 的那台之间,差着 700 美元。
AMD 自己出的官方版 Ryzen AI Halo 开发者 PC,Micro Center 售价 3999 美元,同样 Strix Halo 加 128GB,比第三方盒子贵 1800 美元。差在哪里?官方 logo 加开发者计划套餐。
所以如果你要的就是演示里那台机器,真实价格是 2200 美元左右,不是 1499
性能数据
CPU 这边,Max+ 395 在 Geekbench 6 里多核跑到 18071,超越了桌面级的 Ryzen 9 7900X。这颗芯片 TDP 上限是 125W,在 14 寸笔记本里塞进这种性能,算是工作站级别。
GPU 这边是真正让人意外的。Radeon 8060S(40 CU)在 1080p Ultra 设置下,
《赛博朋克 2077》75.6 fps,
《博德之门 3》85.3 fps,
《侠盗猎车手 5》83.5 fps。
已经非常屌了。
AI 推理表现
这是最重要的部分,也是最分裂的部分。
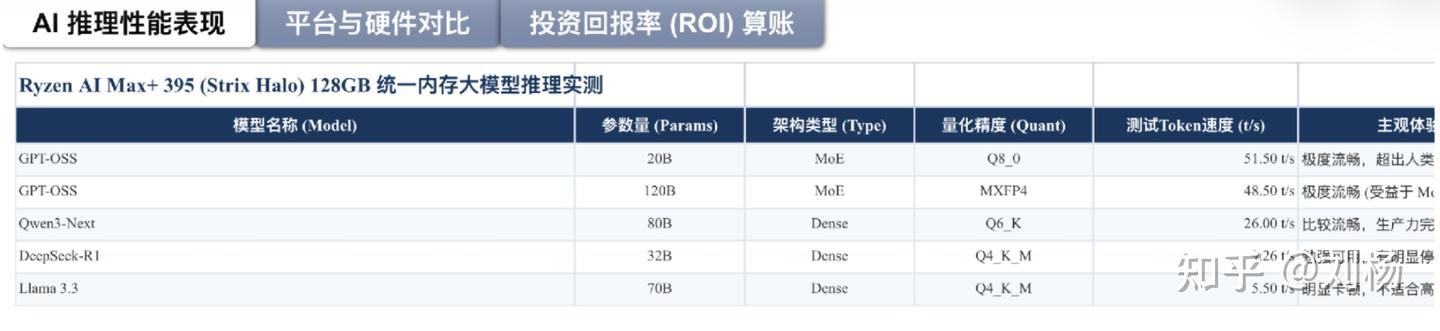
128GB 统一内存配置下:MoE 模型可以跑到 50 t/s,流畅到超出阅读极限。Dense 模型只有 5-6 t/s,能感觉到卡顿。Llama 3.3 70B 在这个配置下,体验就是慢。
为什么 MoE 快 Dense 慢?因为 MoE 每次只调部分权重,MALL 缓存拦截率高,带宽压力小。Dense 模型每个 token 都要把全部参数过一遍,256GB/s 带宽喂不饱这个数据量。
NPU 这边比较尴尬。XDNA 2 硬件标称 50 TOPS,实际跑 Llama 3.2 1B 只有 4.4 t/s。分析底层发现:75% 的时间花在了驱动调度开销上,而不是真正的张量计算。硬件到位了,软件还差很远。
和苹果 M4 Max 比怎么样
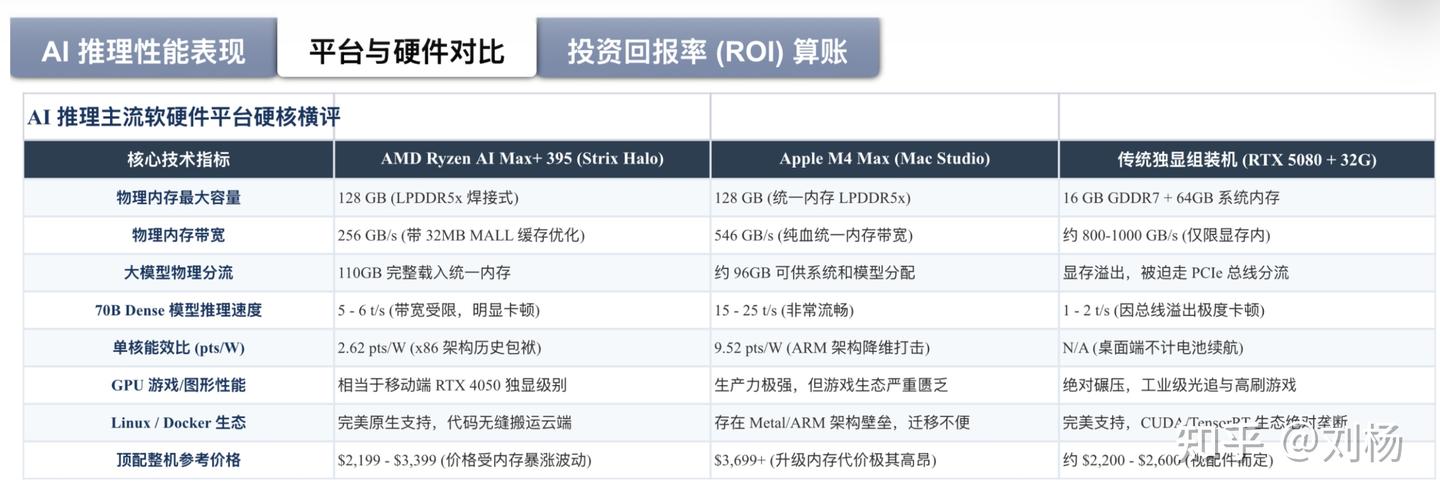
说实话,单从 AI 推理角度,苹果赢了。Mac Studio M4 Max 统一内存带宽是 546 GB/s,Llama 70B 能跑到 15-25 t/s,Ryzen AI Halo 只有 5-6 t/s。这不是小差距,是代差。
但性价比上:Mac Studio 128GB 版本 3699 美元,Ryzen AI Halo 配置差不多的情况下 1999-3299 美元。而且 AMD 支持 Linux,可以把 Docker 镜像从本地直接搬到服务器,macOS 做不到。
如果你的工作流是本地训练加云端部署,AMD 的性价比突出。
真实算账
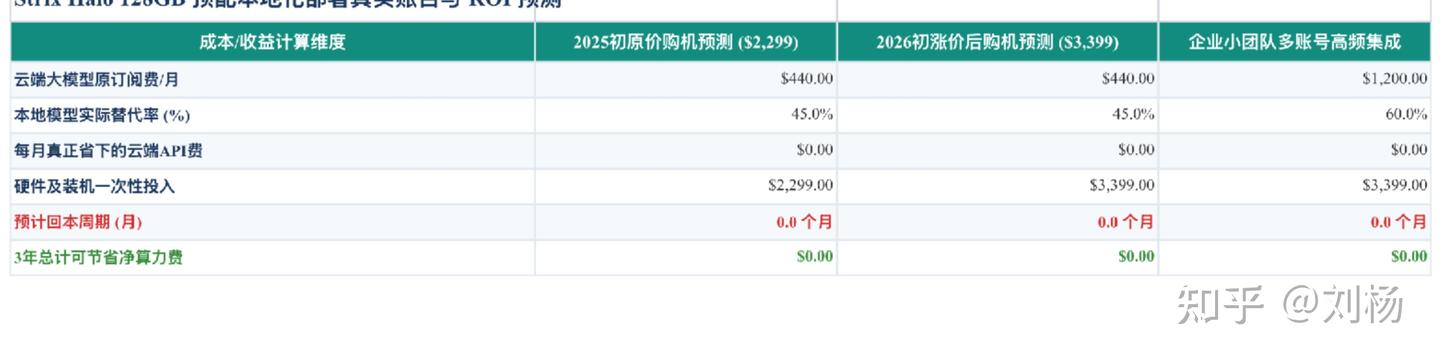
订阅 440 美元每月,5280 美元每年,9 个月回本,我有点看不懂这个算法
因为 5280 美元每年是 GAIA 云端订阅的价格,不是本地机器的价格。
你买这台机器是为了不用订阅,所以这个数字不应该出现在回本计算里。
真实计算应该是:
如果你每个月在 Claude Max(200 美元)加 ChatGPT Pro(200 美元)上花 400 美元,把 200 美元的用量迁移到本地,11 个月回本,之后这台机器就是免费的。
但迁移 200 美元每月是乐观估计。你不会完全放弃云端——本地模型跑不动最硬的任务,frontier 模型还没被开源替代。那 10% 需要最强推理能力的工作,你还是会回到云端。所以实际回本周期是 11 个月,不是 5 个月。
个人感受
AMD 在硬件层面做了一个非常激进的赌注,而且赌赢了——芯片本身是出色的。统一内存做到了,GPU 性能做到了,x86 生态里没有先例。
但它有几个硬伤:NPU 软件 75% 的调度开销,这个坑还没填平;Dense 模型体验差,256 GB/s 带宽喂不饱 70B 的 Dense 模型;价格受 DRAM 市场影响,溢价已经很高;单核能效落后苹果很多。