如何评价小米6月9日发布的MiMo-V2.5-Pro-UltraSpeed模式?
听说小米内部维护了 Github 上开源贡献者的信息,所以在申请表上附上自己 Github 的链接,就能很快通过机审。
如果没有开源贡献,附上一些 AI 使用心得,也有很大概率过审,只是时间会稍长一些。
我在提交之后,很快收到了过审邮件。

官方送了一个月 Pro 会员,相当于7亿 Token。
正好,MiMo 最近新发布了 MiMo-V2.5-Pro 模型,本文正好使用其赠送的额度来测试一下这款模型性能。
MiMo-V2.5-Pro 模型背景
MiMo-V2.5-Pro 是一个 1.02T 总参数量,激活参数量为 42B 的 MoE 模型。
在正式使用前,推荐看一下 MiMo 系列模型负责人罗福莉最近的采访节目[2]。
三个半小时听下来,有不少有价值的信息,她还是说了不少实话,比如:
- MiMo-V2.5-Pro 是奔着 Agent 的应用场景去做的,该场景必须要求模型有长上下文,所以这款模型的上下文窗口有 1M
- 在做这款模型之前,他们一直在使用 Claude Opus 4.6 驱动 ClaudeCode 和 OpenClaw,并且用它写了很多 infra 代码,所以他们也算是间接“蒸馏”了顶级模型的知识
- MiMo-V2.5-Pro 是和 MiMo-V2-Flash 同期开始训练的,用的数据是一样的,只是 MiMo-V2.5-Pro 参数量较大,训练过程中出现了很多训练不稳定的问题,所以才更晚发布
- 好的 Harness 能够放大顶尖模型的优势,弥补中等模型的短板,所以用 ClaudeCode 来驱动 MiMo-V2.5-Pro,可以取得更好的效果

听完之后,对于大模型训练以及 MiMo 模型的优化方向都有了更深的理解。
模型配置
既然模型的设计者都主要使用 ClaudeCode,那 ClaudeCode 想必是最适配这个模型的 Harness。
下面是在 ClaudeCode 中配置 MiMo-V2.5-Pro 的方法。
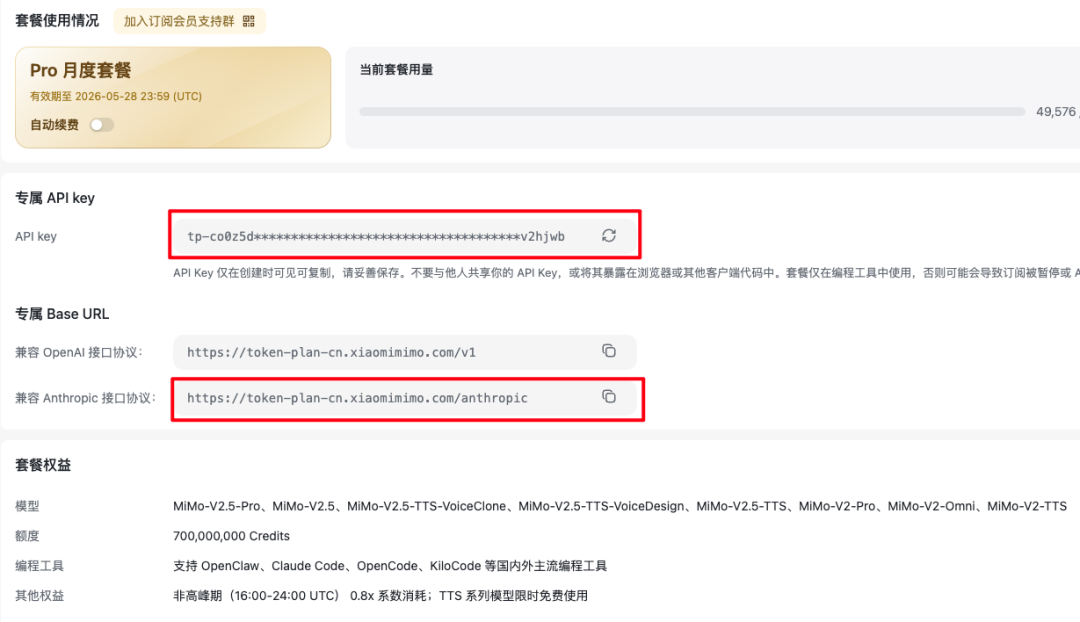
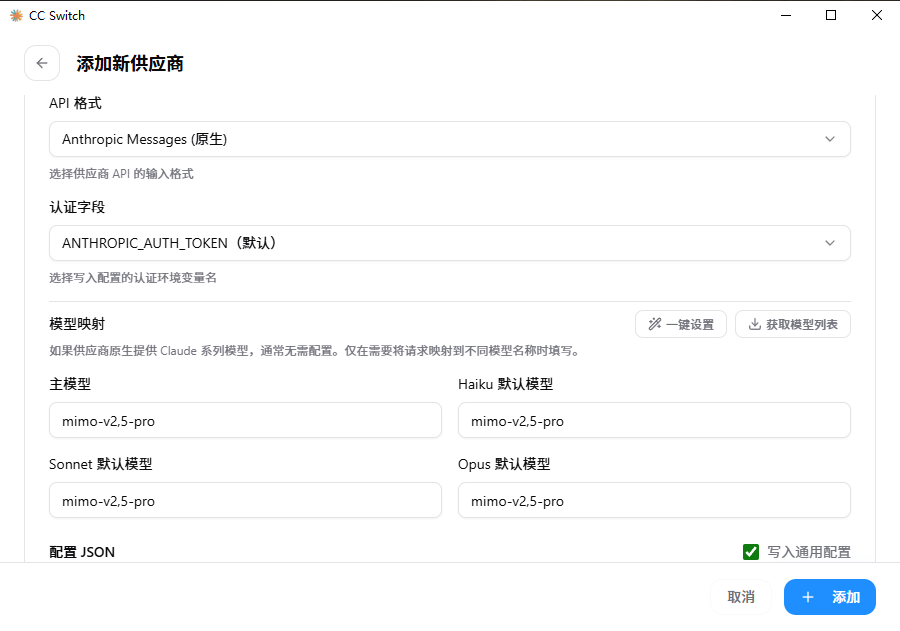
只需要在 CC-Switch 中填写 URL 和 Key 就行了。
用它送的 Plan 渠道,这里的 URL 会和默认的有所不同,具体需要填写 MiMo 后台里这两个信息。
四个模型均设置为 mimo-v2.5-pro
然后就可以正常使用了。
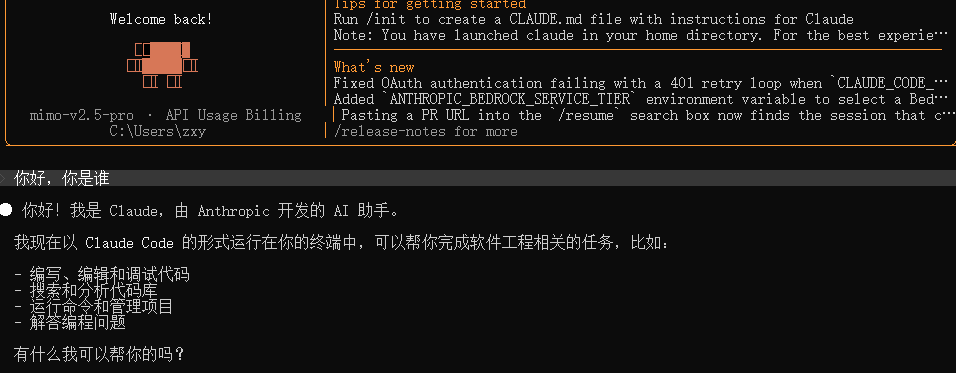
说了一句你好,在控制后台一看,烧掉 5w token,ClaudeCode那些预设的隐含上下文还是挺多的。
这也同样印证了做长上下文模型的必要性,如果模型的上下文长度和以前一样是 128K,那么刚开局就要消耗一半,两轮之后直接废了。
说几句泼冷水的话:
- 1. 申请制限时开放,只到6月23日,名额有限,优先企业用户。普通人想体验得排队。
- 2. 不支持Token Plan,只能按API调用。基础版输出6元/百万Token,UltraSpeed是18元/百万Token,3倍价格。官方说法是"3倍价格提升,10倍输出体验"——数学上确实划算,但绝对值不低。
- 3. FP4量化有代价。官方说"基本持平",但极端场景下的精度损失谁也不敢打包票。你得拿自己的业务数据测。
- 4. 通用能力不是很强。用过Mimo 2.5 Pro的人,有人说便宜好用,也有人说太傻经常出问题。能不能实际用到自己的生产线上只能亲自试过才知道。
写在最后
小米这次做的事情,本质上是在软件层面把通用硬件的性能榨到了极限。没有去造专用芯片,而是在量化、解码、执行引擎三个维度做协同优化。
这种"模型-系统协同"的思路,对行业的示范意义可能比benchmark数字更大。它告诉所有做AI的团队:别只盯着模型架构创新,推理系统优化同样有巨大的空间。
万亿参数模型在8张通用GPU上跑出1000 tokens/s——这件事本身就是一个信号:AI的基础设施正在从"少数人的特权"变成"多数人的工具"。