内存泄露就让它漏,可行吗?
可行,重启解千愁,我曾经就这么干过,当时做了个定时重启。
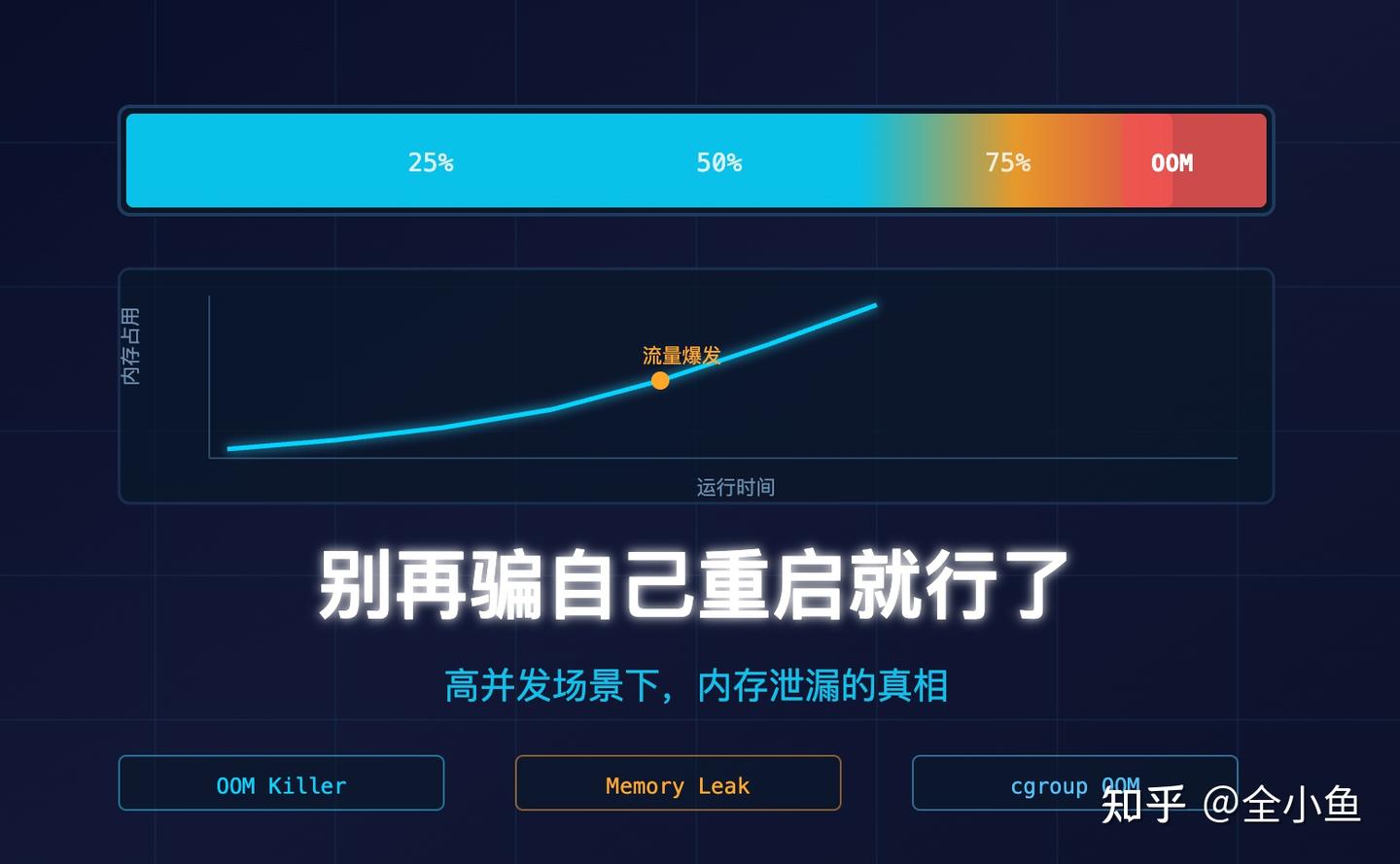
但那一年,在流量爆发时,我直接被虐的体无完肤。
那一年,我深刻理解了,高并发场景下,内存泄漏的速率被放大,原本能撑一天的内存,在几小时内迅速打满并触发 OOM,导致服务在业务高峰期彻底宕机。
一、重启理论上确实成立
每个进程有独立的虚拟地址空间,页表把虚拟地址映射到物理页框。进程exit() 也罢,被 SIGKILL 也罢,内核二话不说,遍历 mm_struct,回收该进程名下的所有物理页。
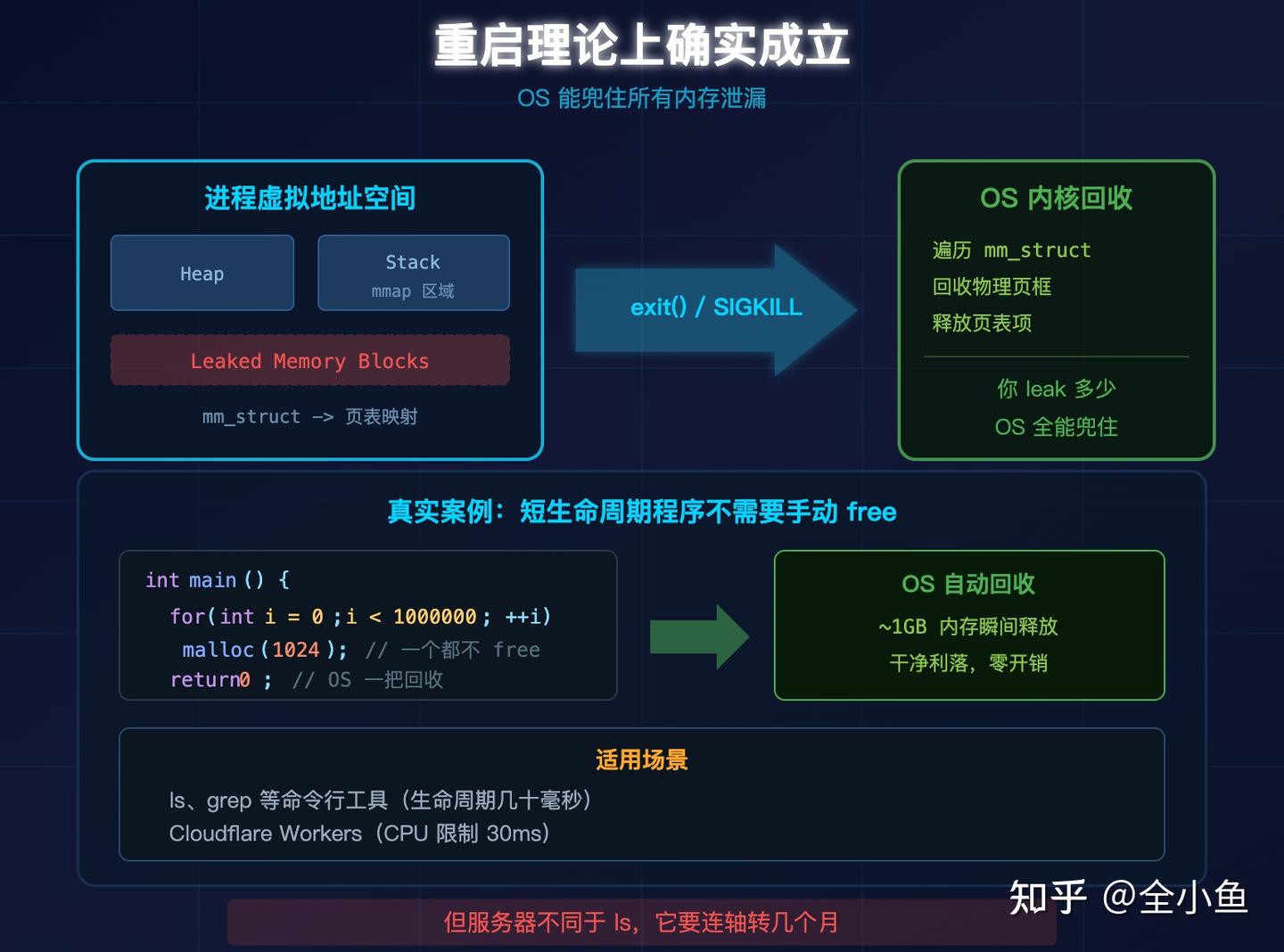
你 leak 了多少,OS 全能兜得住。
int main() {
for (int i = 0; i < 1000000; ++i)
malloc(1024); // 一个都不 free
return 0; // OS 一把回收,干净利落
}
ls、grep 这些命令行工具,生命周期几十毫秒,退出前逐块 free 纯属浪费 CPU。Cloudflare Workers 的 CPU 限制 30ms,分配了就不释放,让 OS 兜底,这是一项真实的工程策略。
但服务器不同于 ls,它要连轴转几个月。
二、四个致命死穴,个个能单杀你的服务
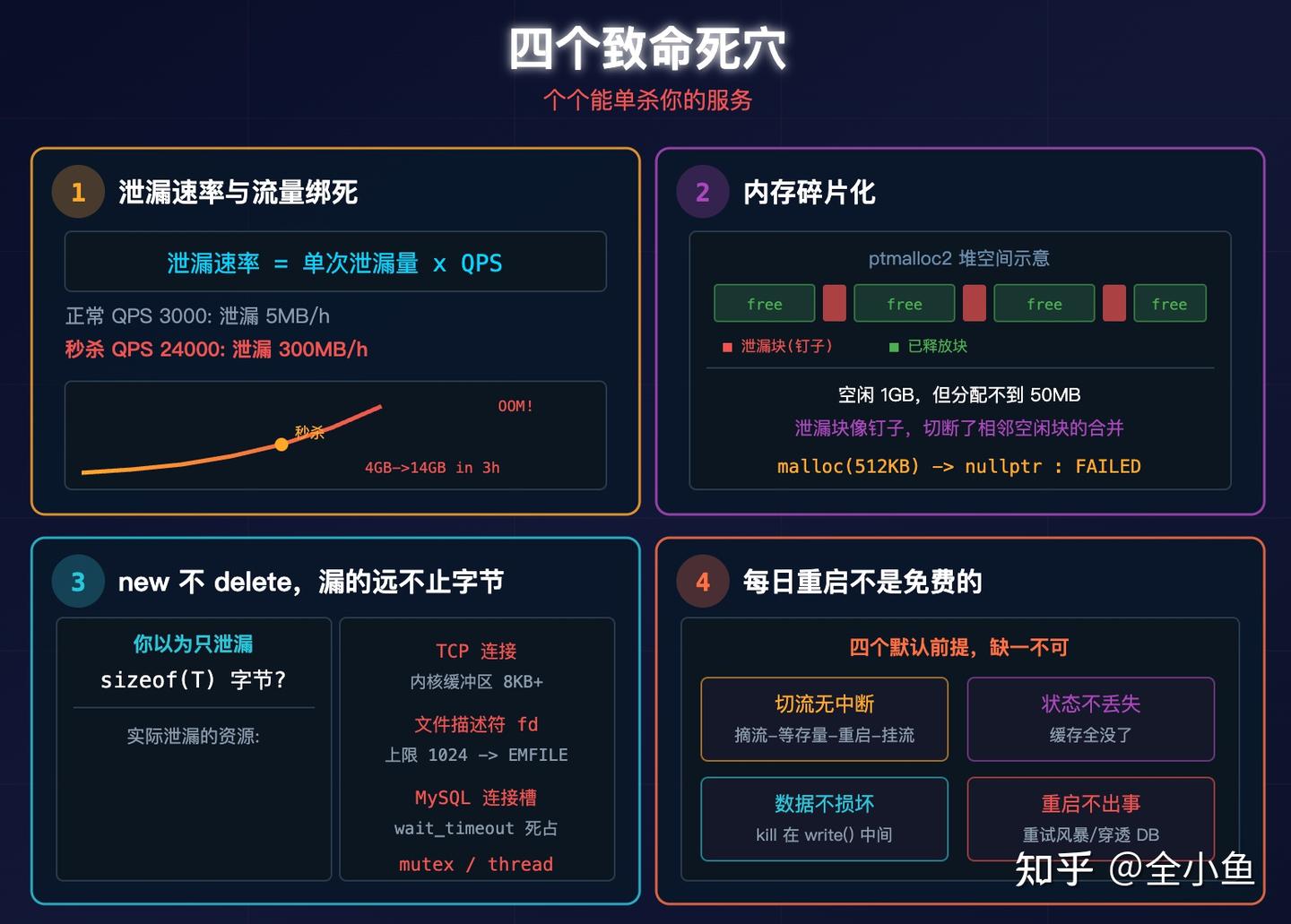
内存泄漏速率与流量是绑死的
假设一天漏 100MB,16GB 内存能撑 160 天。
但对于一个调度服务来讲,正常 QPS 3000,泄漏速率每小时 5MB。
秒杀时,流量冲到八倍,泄漏速率直接飙到了 300MB/h。三小时内,容器内存从 4GB 飙到 14GB,cgroup 16GB 限制直接触发 OOM Killer。
[1638734.234567] oom-kill:constraint=CONSTRAINT_MEMCG
[1638734.234568] Memory cgroup out of memory: Killed process 31829泄漏速率 = 单次泄漏量 × QPS。流量一爆,内存直接炸。你假设的那条线性泄漏曲线,在真实业务里根本不存在。
碎片化导致,即使空闲 1GB,也分配不到 50MB
glibc 的 ptmalloc2 把堆分成 arena 管理。频繁分配不同大小的对象,其中一些永久泄漏,这些小泄漏块像钉子一样钉在堆里,把原本连续的空闲空间切成碎块。
int main() {
std::vector<void*> blocks;
for (int i = 0; i < 1000; ++i) {
blocks.push_back(malloc(1024)); // 稍后释放
malloc(64); // 永久泄漏
}
for (auto p : blocks) free(p);
// 释放了 1000KB,但每 1024 字节之间卡着 64 字节的泄漏块
void* p = malloc(512 * 1024); // 找不到连续 512KB,返回 nullptr
printf("%s\n", p ? "OK" : "FAILED"); // FAILED
}
STL 容器加剧了这个问题。std::vector 扩容、std::unordered_map,每次重新分配都在堆上换位置,正常情况 allocator 能把相邻的空闲块合并。一旦有块被永久泄漏卡死,合并就堵了。
# 看进程的内存碎片状态,用 smaps
$ cat /proc/$(pidof my_service)/smaps | grep -E "^([0-9a-f]+|Pss:)"new 不 delete,漏的远不止那几字节
C++ 对象的分配远比 malloc 一个 sizeof(T) 复杂。构造函数里可能打开文件、建 TCP 连接、锁 mutex。当你跳过 delete,你跳过的是整个析构链。
class DatabaseConnection {
MYSQL* conn_;
public:
DatabaseConnection(const std::string& host, int port) {
conn_ = mysql_init(nullptr);
mysql_real_connect(conn_, host.c_str(), ...);
}
~DatabaseConnection() { mysql_close(conn_); }
};
void handleRequest() {
auto* db = new DatabaseConnection("10.0.1.5", 3306);
// 忘了 delete ⇒ mysql_close() 永不执行
}
你以为每次请求只泄漏 sizeof(DatabaseConnection) 那几十个字节?实际漏的是:
- 一个 TCP 连接,内核 socket 缓冲区收发各至少 4KB
- 一个文件描述符,进程上限默认 1024,满了之后
accept()直接报 EMFILE - MySQL 一个连接槽,
wait_timeout八小时内死占着
$ ls /proc/$(pidof my_service)/fd | wc -l
1020 # 还差四个,服务就该挂了std::thread 不 join/detach 就析构 → std::terminate。std::ofstream 不关 → 数据没刷盘。重启解决不了这些,因为在你重启之前,错误已经造成了。
每日重启不是免费的
服务定时重启,要有四个默认前提:切流无中断、状态不丢失、数据不损坏、重启不出事。
微服务+负载均衡,摘流→等存量→重启→挂流,至少有几秒不可用。你是链路关键节点的话,上游看到连接拒绝,触发重试风暴。
内存缓存,SIGTERM 一声响全没了。重启后前几分钟所有请求穿透到数据库,瞬时压力是平时的十倍。
kill 卡在 write() 中间,文件直接损坏。
三、不用重启的写法
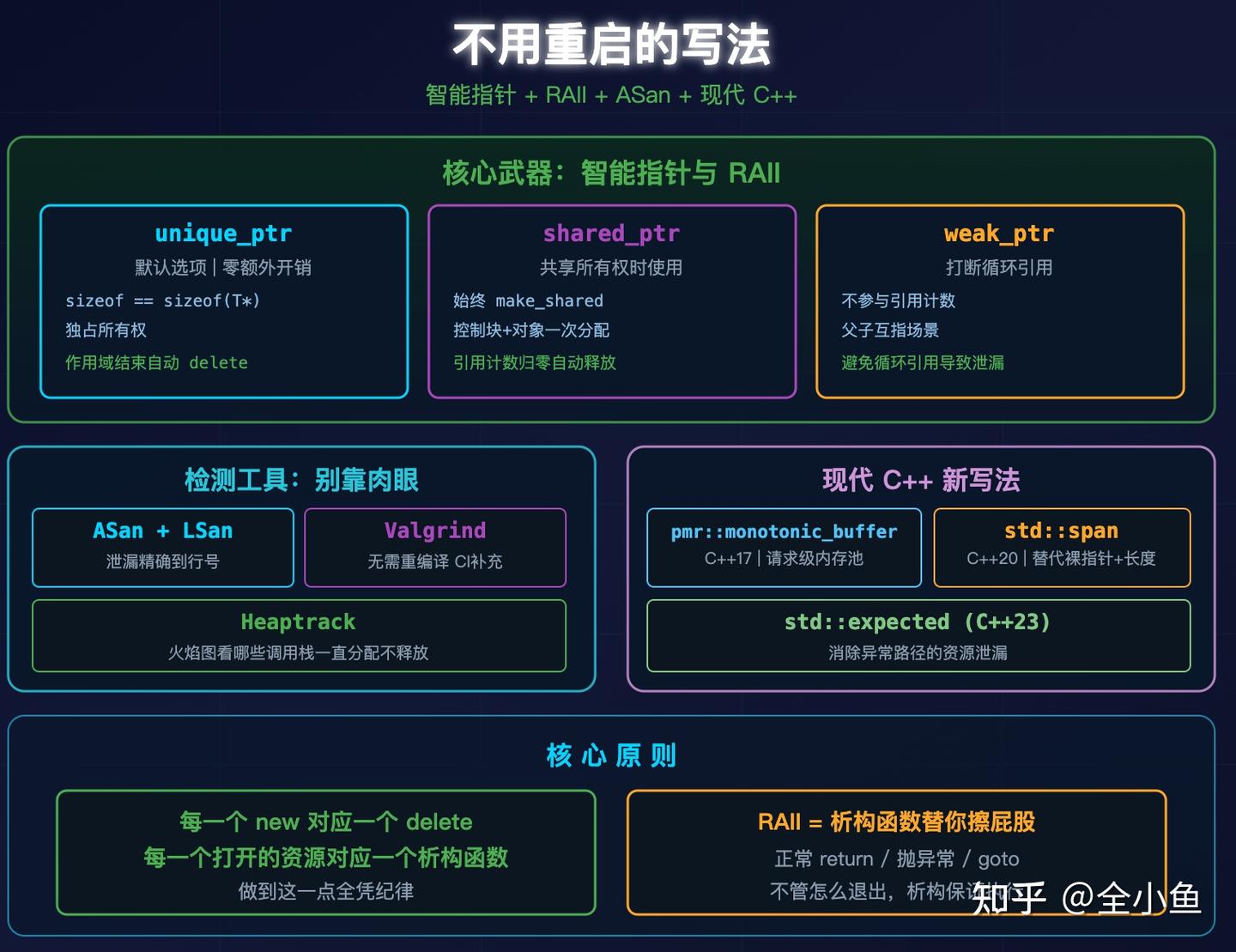
智能指针和 RAII 都是让析构函数替你擦屁股。
// 这种代码不该出现在生产环境
void legacy() {
Widget* w = new Widget();
// 中间如果抛异常?w 永不释放
delete w;
}
// 正确写法
void modern() {
auto w = std::make_unique<Widget>();
} // 正常 return、抛异常、goto,不管怎么退,~unique_ptr() 保证 delete
unique_ptr 是默认选项:sizeof(unique_ptr<T>) == sizeof(T*),一个指针的大小,零额外开销。
shared_ptr 只在确需共享所有权时用,且始终 make_shared 控制块和对象一次分配,比 new shared_ptr<T>(new T) 少一次 malloc。
weak_ptr 用来打断循环引用:
class Node {
std::vector<std::shared_ptr<Node>> children_;
std::weak_ptr<Node> parent_; // 不参与引用计数,父子互指不会泄漏
};
智能指针的自定义删除器能接管包括内存在内的任何资源:
auto file = std::unique_ptr<FILE, decltype(&fclose)>(
fopen("data.log", "w"), fclose);
// 离开作用域,fclose 自动调用,不需要写 close
对于 POSIX 的 fd 也一样:
class ScopedSocket {
int fd_;
public:
explicit ScopedSocket(int fd) : fd_(fd) {}
~ScopedSocket() { if (fd_ >= 0) close(fd_); }
ScopedSocket(const ScopedSocket&) = delete;
ScopedSocket& operator=(const ScopedSocket&) = delete;
ScopedSocket(ScopedSocket&& other) noexcept : fd_(other.fd_) {
other.fd_ = -1;
}
};
每一个 new 对应一个 delete,每一个打开的资源对应一个析构函数。做到这一点全凭纪律。
检测别靠肉眼。
# ASan + LSan,泄漏精确到行号
$ clang++ -g -fsanitize=address -fno-omit-frame-pointer my_service.cpp
$ ASAN_OPTIONS=detect_leaks=1 ./a.out
# Direct leak of 1024 byte(s) ... my_service.cpp:42Clang 3.1+ / GCC 4.8+ 内置,开发阶段跑一遍就能把泄漏抓在 QA 之前。Valgrind 不用重编译也能检,开销 10-20 倍,CI 上做补充。Heaptrack 用火焰图看哪些调用栈一直在分配不释放:
$ heaptrack ./my_service --run-for 300
$ heaptrack_gui heaptrack.my_service.XXXXX.gz现代新写法:
std::pmr::monotonic_buffer_resource(C++17)。每个 HTTP 请求分配一个独立的内存池,请求处理完整个池一次性析构,所有临时对象一把清,不碰全局堆,不出碎片:
char buf[4096];
std::pmr::monotonic_buffer_resource pool(buf, sizeof(buf));
std::pmr::vector<int> v(&pool); // 所有分配走池,作用域结束整池释放
std::span(C++20)替代裸指针+长度。编译器知道边界,ASan 能抓 use-after-free:
void process(std::span<int> data) {
for (auto& x : data) x *= 2;
}
int arr[100];
process(arr); // 自动推导大小,零拷贝
std::expected(C++23)消除异常路径的资源泄漏:
auto result = connect("10.0.1.5");
if (result) {
auto& db = *result; // 正常使用
} else {
log_error(result.error()); // 失败路径,资源已自动释放
}
// 不需要在 catch 块里补 delete
四、这事说到底是个态度问题
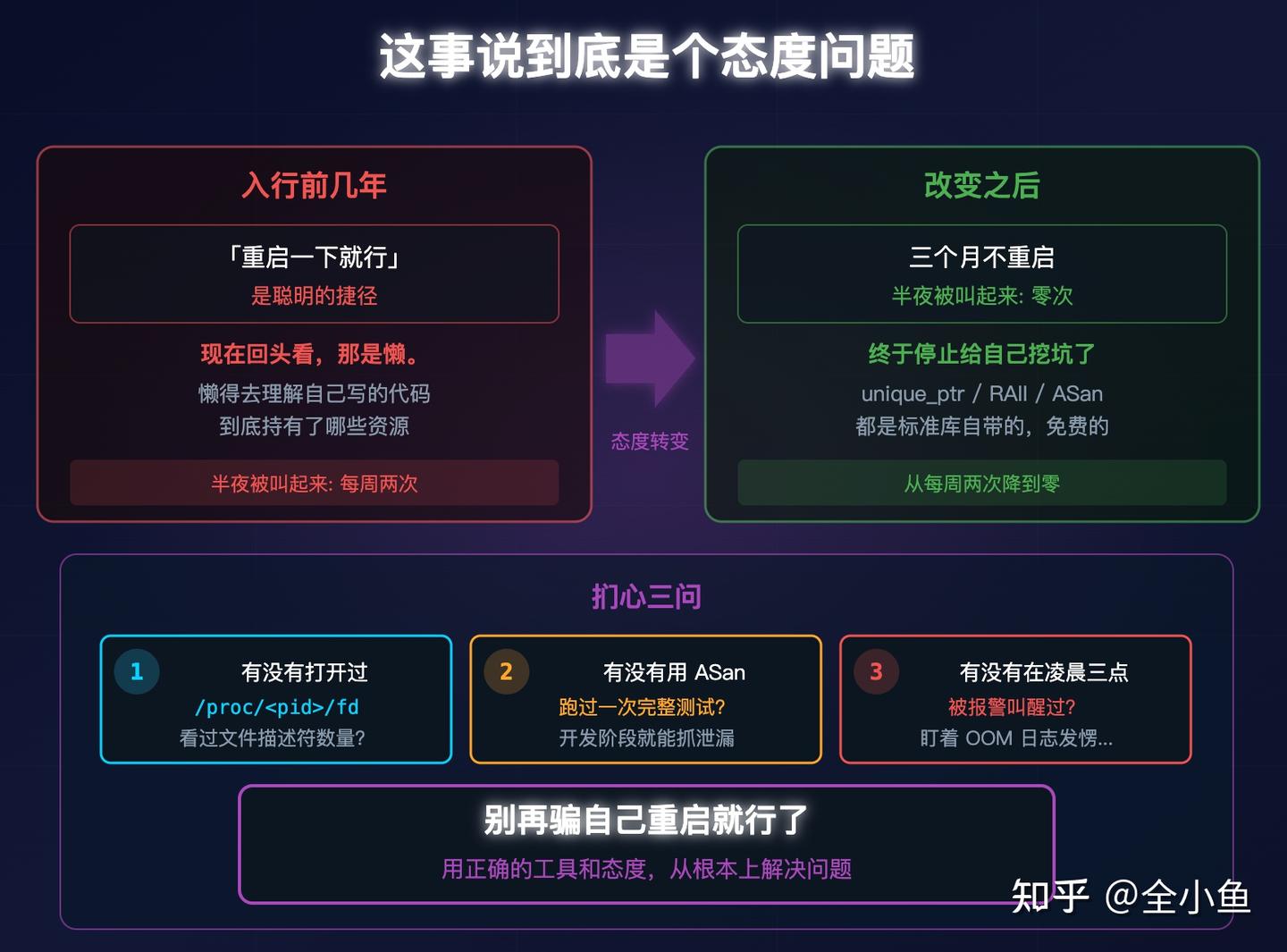
入行前几年,觉得「重启一下就行」是聪明的捷径。现在回头看,那是懒。懒得去理解自己写的代码到底持有了哪些资源。
你有没有打开过 /proc/<pid>/fd 看过你服务的文件描述符数量?
有没有用 ASan 跑过一次完整的测试?
有没有在凌晨三点被报警叫醒、盯着 OOM 日志发愣?
我都经历过。
从每天定时重启改成三个月不重启之后,半夜被叫起来的次数从每周两次降到了零。
其实就是终于停止给自己挖坑了。
std::unique_ptr、RAII、ASan、std::pmr,都是标准库和编译器自带的,免费的。
别再骗自己重启就行了。