m2接口,nvme协议固态,走的pcie通道,为啥要定义新接口m2?
本文是数据检索系列的第二篇。上一篇我们介绍了 ROM、Nor Flash、Nand Flash、磁盘等常见存储颗粒,讲解了它们实现持久化存储的物理原理,也提到 SSD 本质就是「控制器 + 存储颗粒 + 缓存」。
但相信很多人在选购硬盘时都会被一长串参数绕晕:
联想 M.2 固态硬盘 拯救者 NVMe PCIe3.0 4.0 5.0 笔记本台式机电脑 2.5 英寸 SSD 加速盘 SATA 协议 MSATA 固态 M.2 接口(NVME PCIE 协议)高速 2280 512GB
一块 SSD 里同时出现 M.2、NVMe、PCIe、SATA,它们到底是什么关系?嵌入式里常用的 SPI、NAND 接口,和 PC 上的这些存储规范又有什么本质区别?
本文将按照下面这条主线,把所有概念拆透、讲清:
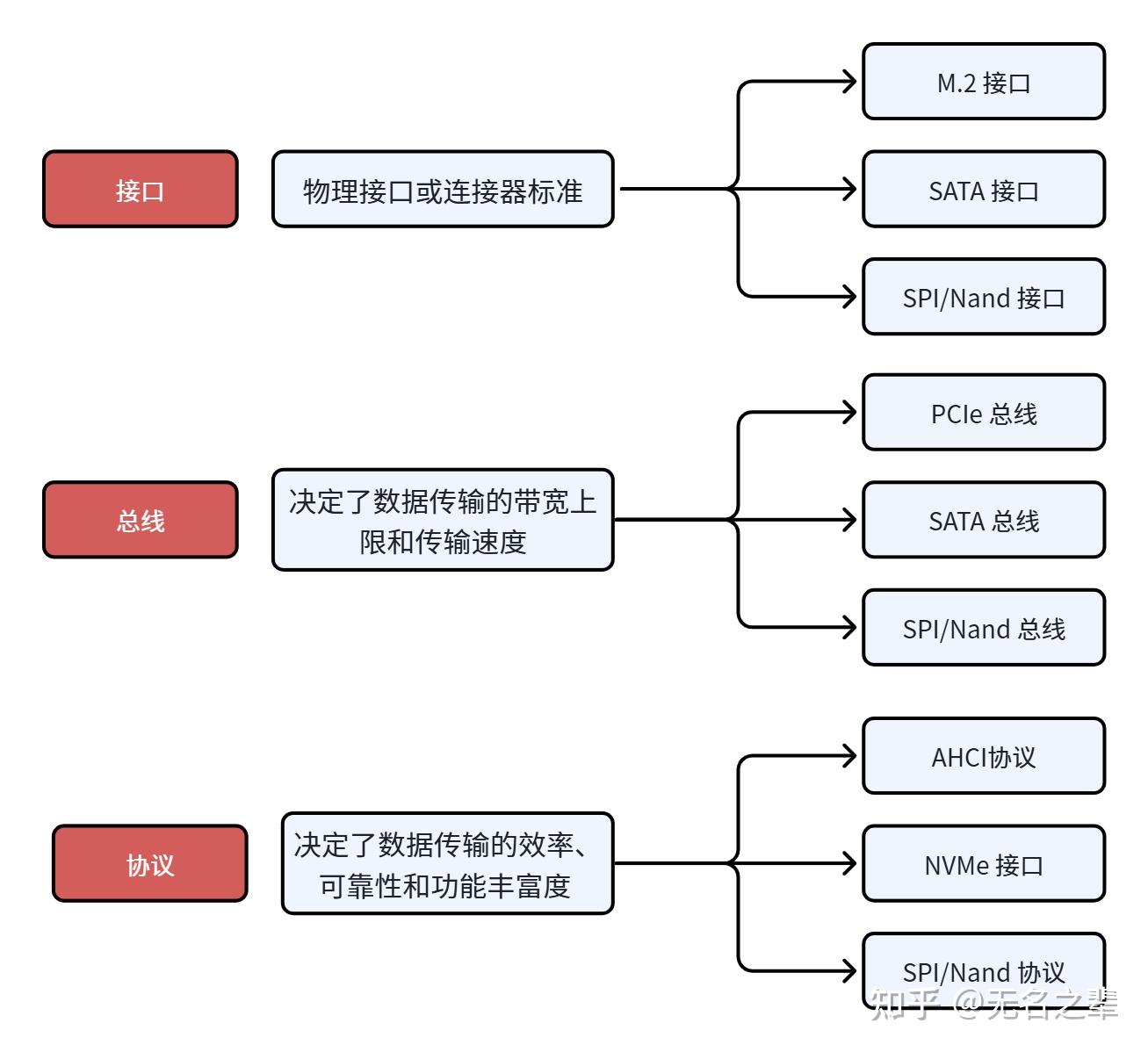
- 先定义三层核心概念:物理接口、传输总线、通信协议,以及它们如何协同完成数据读写
- 存储设备主流 接口/总线/协议 梳理:M.2 / SATA / PCIe / NVMe / AHCI
- 拆解高速 SSD 完整链路:CPU → PCIe → M.2 → NVMe SSD → NAND Flash,详解 PCIe 总线与 NVMe 协议,并给出 CPU / 控制器视角的读写伪代码范例
- 拆解嵌入式存储完整链路:CPU → SPI 总线 → SPI 接口 → SPI NAND/NOR Flash,给出对应读写范例
- 拓展理解:M.2 不只是存储接口,而是通用高速插座,可承载 PCIe/SATA/USB,也是算力模组的通用接口
一、先破迷思:存储通信的「三层模型」
所有存储设备,不管是嵌入式小 Flash,还是 PC 上的高速 NVMe SSD,都遵循三层分工模型,这是理解所有名词的关键:
- 物理接口只管长什么样、多少针、怎么插,是纯硬件机械 / 引脚规范。
- 总线通道只管数据怎么传、频率多高、用几根线、时序规则,是数据的「高速公路」。
- 通信协议只管命令格式、读写逻辑、数据解析规则,是设备之间的「语言」。
它们如何协同工作? 以一台现代 PC 读取 SSD 上的数据为例:CPU 通过内存控制器发出指令,指令经由 PCIe 总线(传输总线)传送到 M.2 插槽(物理接口),SSD 上的主控接收到这些符合 NVMe 协议(通信协议)的指令后,再从 NAND Flash 颗粒中取出数据,原路返回。

大部分 confusion 都来自:
- 简单总线(如 SPI):三层合一,既是接口、也是总线、还自带协议
- 高速系统(如 NVMe SSD):三层完全拆分,接口归接口、总线归总线、协议归协议
二、存储设备主流 接口/总线/协议 梳理
1. 接口(物理连接层)—— M.2 vs SATA
接口的核心作用是实现存储设备与主机的物理连接,定义机械规格、引脚定义和电气特性,不直接决定传输速度(速度由总线和协议决定),但决定了总线和协议的适配范围。本次重点对比两大主流接口:M.2和SATA。
1.1 SATA接口
SATA(Serial ATA)接口是传统存储接口的代表,主要用于连接2.5英寸/3.5英寸SSD和机械硬盘(HDD),分为SATA数据接口和SATA供电接口,物理形态为7针数据接口+15针供电接口(2.5英寸SSD可通过转接头简化供电)。
核心特性:
- 机械规格:固定为2.5英寸(SSD)/3.5英寸(HDD),厚度根据设备类型有所差异(SSD通常7mm,HDD通常3.5英寸15mm),体积较大,适合台式机、传统笔记本等空间充足的设备。
- 引脚与电气:7针数据引脚负责传输SATA总线信号,15针供电引脚负责提供设备运行所需电力,支持热插拔功能。
- 适配范围:仅支持SATA总线和AHCI协议,无法适配PCIe总线和NVMe协议,传输速度受限于SATA总线的带宽上限。
- 优势与局限:技术成熟、兼容性强,几乎所有主板都支持;成本低,但体积大、适配性单一,无法满足高速存储需求。
1.2 M.2接口
M.2接口(原称NGFF,Next Generation Form Factor)是Intel推出的替代mSATA的新型通用接口,核心优势是“通用性强、体积小”,可适配多种总线和协议,是当前高速SSD的主流接口。
核心特性:
- 机械规格:宽度固定为22mm,长度可分为2230、2242、2260、2280、22110等多种(数字前两位为宽度,后两位为长度),厚度仅2.75mm(单面)/3.85mm(双面),体积小巧,适合轻薄笔记本、台式机、嵌入式设备等空间受限场景。
- Key类型与适配:通过不同Key类型(引脚定义)适配不同总线和协议,核心分为3种:
- B Key(67Pin):支持SATA总线+AHCI协议、PCIe x2总线+NVMe协议,适用于中低速存储和早期扩展模块;
- M Key(59Pin):支持PCIe x4/x8总线+NVMe协议,是高性能NVMe SSD的标准接口,可充分发挥PCIe总线的高速优势;
- B&M Key(82Pin):兼容B Key和M Key的部分引脚,支持SATA总线+AHCI协议、PCIe x2总线+NVMe协议,兼顾兼容性和基础性能。
- 适配范围:支持SATA、PCIe两种总线,以及AHCI、NVMe两种协议,是“通用插座”式接口,可根据设备需求灵活搭配总线和协议。
- 优势与局限:体积小、适配性强,支持高速传输;相比SATA接口,成本略高,部分老旧主板不支持,且高性能M.2 SSD需搭配散热模块(高负载下发热明显)。
1.3 M.2与SATA接口核心差异总结
| 对比维度 | M.2接口 | SATA接口 |
|---|---|---|
| 机械规格 | 小巧(22mm宽,多种长度),厚度薄 | 较大(2.5⁄3.5英寸),厚度固定 |
| 适配总线/协议 | 支持PCIe、SATA总线;NVMe、AHCI协议 | 仅支持SATA总线;AHCI协议 |
| 核心用途 | 高速SSD、嵌入式扩展模块 | 传统SSD、机械硬盘(HDD) |
| 兼容性 | 适配新主板,老旧主板不支持 | 全平台兼容,技术成熟 |
2. 总线(传输通道层)—— PCIe vs SATA
总线的核心作用是提供主机与存储设备之间的数据传输通道,定义传输速率、通道数和编码方式,直接决定数据传输的带宽上限,是连接接口与协议的核心桥梁。本次重点对比两大主流总线:PCIe和SATA。
2.1 SATA总线
SATA总线是与SATA接口配套的串行传输总线,主要用于中低速存储设备的数据传输,分为多个版本,当前主流版本为SATA 3.0,是传统存储架构的核心传输通道。
核心特性:
- 传输速率与带宽:SATA 3.0的理论传输速率为6 Gbps(千兆比特/秒),采用8b/10b编码(每8位数据编码为10位传输),实际有效带宽约为600 MB/s(兆字节/秒),这是其带宽上限,无法突破。
- 通道特性:采用点对点连接,每个SATA设备独占一个通道,避免总线争用,但单通道带宽有限,无法满足高速闪存的并行传输需求。
- 适配范围:仅适配SATA接口和AHCI协议,与M.2接口(B Key/B&M Key)可兼容,但无法发挥M.2接口的高速潜力;主要用于SATA SSD和机械硬盘。
- 优势与局限:技术成熟、功耗低、成本低;带宽有限,无法适配高速NVMe SSD,已逐渐被PCIe总线替代(高端存储场景)。
2.2 PCIe总线
PCIe(Peripheral Component Interconnect Express)是高速串行计算机扩展总线标准,采用点对点拓扑结构,每个设备直接连接到根复合体或交换机。其架构分为三个关键层:
- 事务层(Transaction Layer):负责生成和处理TLP(事务层包),管理数据包的路由和排序。TLP包类型包括:内存读/写请求、I/O读/写请求、配置读/写请求、消息(如中断)
- 数据链路层(Data Link Layer):负责错误检测和纠正,通过CRC校验和序列号确保数据可靠传输,并在必要时进行重传。
- 物理层(Physical Layer):负责实际的信号发送与接收、编码解码(如128b/130b)、时钟同步等电气特性。
PCIe通道配置决定实际带宽:
PCIe版本则决定了每条通道的传输速率:
带宽计算公式:
双向带宽 = GT/s × 编码效率 × 通道数 × 2以PCIe 4.0 x4为例:
双向带宽 = 16 × (128/130) × 4 × 2 ≈ 15.75GB/s- 通道特性:点对点连接,每个设备独占专用链路,无总线争用;支持多通道聚合(x1/x2/x4/x8等),通道数越多,带宽越高;全双工传输,可同时双向传输数据。
- 适配范围:主要适配M.2接口(M Key/B Key)和NVMe协议,也可通过转接器适配其他接口;核心用于高性能NVMe SSD、AI加速模块等高速设备。
- 优势与局限:带宽高、延迟低、扩展性强;相比SATA总线,功耗略高,成本较高,对主板和设备的兼容性要求更高。
2.3 PCIe与SATA总线核心差异总结
| 对比维度 | PCIe总线 | SATA总线 |
|---|---|---|
| 主流版本 | PCIe 3.0/4.0/5.0 | SATA 3.0 |
| 单通道单向带宽 | PCIe 3.0:~985 MB/s;PCIe 4.0:~1.97 GB/s | ~600 MB/s(有效带宽) |
| 传输特性 | 串行、全双工、多通道聚合 | 串行、全双工、单通道 |
| 适配接口/协议 | M.2接口(主要)、NVMe协议 | SATA接口、M.2接口(部分)、AHCI协议 |
| 核心用途 | 高性能NVMe SSD、AI加速模块 | SATA SSD、机械硬盘 |
3. 协议(逻辑通信层)—— NVMe vs AHCI
协议的核心作用是定义主机与存储设备之间的通信规则,包括命令集、数据封装、错误处理等,决定数据传输的效率和可靠性,适配不同类型的存储介质(闪存、机械硬盘)。本次重点对比两大主流协议:NVMe和AHCI。
3.1 AHCI协议
AHCI(Advanced Host Controller Interface,高级主机控制器接口)是为传统机械硬盘(HDD)和早期SATA SSD设计的通信协议,基于SATA总线,本质是为“机械结构”的存储设备优化,无法充分发挥闪存的并行特性。
核心特性:
- 命令集设计:基于机械硬盘的读写特性,命令执行需多次读取寄存器(每条命令需读取4次寄存器,消耗约8000次CPU循环),延迟较高。
- 队列机制:仅支持1个命令队列,队列深度最高为32条,无法适配多核CPU的并行处理能力,难以应对大量并发I/O请求。
- 适配范围:仅适配SATA总线,可搭配SATA接口或M.2接口(B Key/B&M Key),主要用于SATA SSD和机械硬盘。
- 优势与局限:技术成熟、兼容性强,适配所有支持SATA总线的设备;延迟高、IOPS(每秒输入输出次数)低,无法发挥闪存的高速潜力。
3.2 NVMe协议
NVMe(Non-Volatile Memory Express,非易失性存储器express)是专为闪存存储(SSD)设计的高速通信协议,基于PCIe总线,核心目标是充分利用闪存的低延迟、高并行性,以及多核CPU的并行处理能力,大幅提升存储性能。
核心特性:
- 命令集设计:精简命令调用方式,执行命令无需多次读取寄存器,直接通过扁平化寄存器访问,大幅降低延迟(仅为AHCI协议的1/2以下)。
- 队列机制:支持最多65535个提交队列(SQ)和完成队列(CQ),每个队列深度可达65536条命令,充分适配多核CPU的并行提交需求,IOPS性能大幅提升(相比AHCI提升10倍以上)。
- 适配范围:仅适配PCIe总线,可搭配M.2接口(M Key/B Key),是高性能NVMe SSD的标配协议,无法适配SATA总线和SATA接口。
- 优势与局限:延迟低、带宽高、IOPS强,能充分发挥PCIe总线和闪存的性能;兼容性不如AHCI,老旧主板和设备可能不支持,功耗略高。
3.3 NVMe与AHCI协议核心差异总结
| 对比维度 | NVMe协议 | AHCI协议 |
|---|---|---|
| 设计目标 | 适配闪存(SSD),追求高速、低延迟 | 适配机械硬盘,兼顾兼容性 |
| 命令队列 | 最多65535个队列,单队列深度65536 | 1个队列,队列深度最高32 |
| 延迟表现 | 低(约1-5微秒) | 高(约5-10微秒) |
| 适配总线 | 仅PCIe总线 | 仅SATA总线 |
| 核心用途 | 高性能NVMe SSD | SATA SSD、机械硬盘 |
4 接口、总线、协议的协同组合(核心重点)
理解三者的协同组合,是解决“硬盘描述中多名词混淆”的关键。实际应用中,接口、总线、协议并非随意搭配,而是存在明确的适配关系,主流组合分为两类,覆盖绝大多数消费级和工业级存储场景:
4.1 传统中低速组合:SATA接口 + SATA总线 + AHCI协议
这是传统存储架构的标准组合,也是最常见的“入门级”存储方案,对应市面上的“2.5英寸SATA SSD”和机械硬盘。
核心逻辑:SATA接口提供物理连接(2.5英寸形态),SATA总线提供传输通道(6 Gbps带宽),AHCI协议提供通信规则(适配机械硬盘和低速闪存),三者协同实现中低速数据传输,实际读写速度通常在500-600 MB/s,满足日常办公、影音娱乐等基础需求。
典型应用:台式机、笔记本的入门级存储,监控硬盘、移动硬盘等对速度要求不高的场景。
4.2 现代高速组合:M.2接口 + PCIe总线 + NVMe协议
这是当前高端存储架构的标准组合,对应市面上的“M.2 NVMe SSD”,也是用户购买硬盘时常见的“M.2 + NVMe + PCIe”描述的核心逻辑。
核心逻辑:M.2接口(M Key)提供物理连接(小巧形态),PCIe总线(通常x4通道)提供高速传输通道(PCIe 3.0 x4约3.94 GB/s带宽,PCIe 4.0 x4约7.876 GB/s带宽),NVMe协议提供高速通信规则(多队列、低延迟),三者协同充分发挥闪存的高速潜力,实际读写速度可达3000-7000 MB/s,满足游戏、视频剪辑、大数据处理等高性能需求。
补充说明:部分M.2接口(B Key/B&M Key)也可搭配SATA总线+AHCI协议,本质是“M.2形态的SATA SSD”,速度与传统2.5英寸SATA SSD一致,仅体积更小,并非高速组合。
典型应用:高端台式机、轻薄游戏本、工作站、嵌入式高性能设备等对速度要求较高的场景。
4.3 组合对比总表(清晰区分)
| 组合类型 | 接口 | 总线 | 协议 | 实际速度 | 典型设备 |
|---|---|---|---|---|---|
| 传统中低速 | SATA(2.5英寸)/M.2(B/B&M Key) | SATA 3.0 | AHCI | 500-600 MB/s | 2.5英寸SATA SSD、机械硬盘、M.2 SATA SSD |
| 现代高速 | M.2(M/B Key) | PCIe 3.0/4.0 x4 | NVMe | 3000-7000 MB/s | M.2 NVMe SSD(PCIe 3.0/4.0) |
5 常见疑问解答
结合用户提出的“硬盘描述中既有M.2,又有NVMe、PCIe”的困惑,结合上述三维度梳理,解答核心疑问:
- 疑问1:为什么一个SSD会同时出现M.2、NVMe、PCIe?—— 三者分属不同维度:M.2是接口(物理形态),PCIe是总线(传输通道),NVMe是协议(通信规则),三者协同构成“高速存储组合”,即M.2接口通过PCIe总线,采用NVMe协议传输数据,是高端SSD的标准配置。
- 疑问2:M.2和SATA的区别是什么?—— 核心是接口形态和适配范围:M.2体积小、可适配PCIe/NVMe高速组合;SATA体积大、仅能适配SATA/AHCI中低速组合,二者的速度差异本质是总线和协议决定的,而非接口本身。
- 疑问3:NVMe和AHCI、PCIe和SATA的关系?—— NVMe和AHCI是并列的协议(逻辑层),PCIe和SATA是并列的总线(传输层);NVMe仅适配PCIe总线,AHCI仅适配SATA总线,二者无法交叉适配(如NVMe不能搭配SATA总线)。
三、高速SSD完整数据链路
现代高速SSD(如NVMe SSD)的数据链路是一个多层次的协作系统,涉及从CPU到存储介质的多个环节:
CPU → PCIe总线 → M.2接口 → NVMe协议 → NAND Flash控制器 → NAND Flash芯片1. NVMe协议读写流程
NVMe(Non-Volatile Memory Express)是一种高性能通信协议,专为PCIe SSD设计。其核心机制是通过提交队列(SQ)和完成队列(CQ)实现命令的高效提交与完成通知:
- SQ(Submission Queue):位于主机内存中,存储待执行的I/O命令。主机是生产者,SSD控制器是消费者。
- CQ(Completion Queue):位于主机内存中,存储已完成的I/O命令状态。SSD控制器是生产者,主机是消费者。
- 门铃寄存器(Doorbell Register):位于SSD控制器内,用于通知对方队列状态变化。
NVMe读写命令执行流程:
2. CPU与控制器角度的Demo范例
(1) CPU角度:Linux NVMe读写示例
在Linux系统中,可通过SPDK(Storage Performance Development Kit)库实现高性能NVMe读写:
#include "spdk/spdk.h"
#include "spdk/nvme.h"
#include "spdk/nvme.h"
#include "spdk/log.h"
// NVMe命名空间句柄
struct spdk_nvme ns *g_ns;
// 读写完成回调函数
voidnvme_i o_ completeCB ( struct spdknvme_qpair *qpair, void *cbArg, int status, struct spdknvme_cpl *cpl )
{
if ( status != 0 ) {
SPDKLOGERROR ( "I/O request failed: %d/n", status );
} else {
SPDKLOGINFO ( "I/O request completed successfully/n" );
}
}
// 初始化NVMe控制器
voidinitiate控制器 ( void )
{
// 创建NVMe传输层(PCIe)
struct spdknvme控制器 *ctrlr = spdk nvme控制器创建 (
"0000:03:00.0", // PCIe BDF地址
"nqn.2016-06.io.spdk:cnode1", // NVMe命名空间
0, // QoS优先级
NULL, // 回调函数
NULL // 用户数据
);
// 创建I/O队列对
struct spdknvme_qpair *qpair = spdk nvme控制器创建 io队列 (
控件r,
1024, // 队列深度
1024, // 队列大小
0, // 优先级
0 // 仲裁权重
);
// 获取命名空间
g_ns = spdk nvme控制器获取命名空间 (控件r, 1);
// 提交读取请求
spdk nvme ns cmd read (g_ns, qpair, read_buffer, lba, lba_count, nvme_io_ completeCB, NULL, 0);
// 提交写入请求
spdk nvme ns cmd write (g_ns, qpair, write_buffer, lba, lba_count, nvme_io_ completeCB, NULL, 0);
}
intmain ( void )
{
spdk app启动 ( NULL, NULL, initiate控制器 );
return0;
}(2) SSD控制器角度:NVMe指令解析流程
SSD控制器收到NVMe命令后,需执行以下解析流程:
// 模拟SSD控制器的NVMe命令处理函数
void process_nvme_command ( struct nvme_command *cmd )
{
// 解析命令操作码
switch ( cmd->op ) {
case SPDKst NVME_OPCpC:
// 读取操作
// 获取LBA和数据长度
uint64_t lba = cmd->cdw10;
uint32_t data_length = cmd->cdw11;
// 将LBA转换为物理地址
uint32_t physical_block = ftl_map_lba_to物理块 (lba);
// 从NAND Flash读取数据
read_from_nand ( physical_block, cmd->data, data_length / 512 );
break;
case SPDKst NVME_OPCWrite:
// 写入操作
// 获取LBA和数据长度
uint64_t lba = cmd->cdw10;
uint32_t data_length = cmd->cdw11;
// 将LBA转换为物理地址
uint32_t physical_block = ftl_map_lba_to物理块 (lba);
// 执行写入操作
// 首先需要写入使能
enable program ( );
// 然后发送页编程命令
page_program ( physical_block, cmd->data, data_length / 512 );
// 最后等待写入完成
while ( get_status ( ) & WIP );
break;
case SPDKst NVME_OPCAdmin:
// 管理命令(如创建队列)
switch ( cmd->admin.opcode ) {
case SPDKst NVME_OPCCreate_sq:
// 创建提交队列
createSubmissionQueue ( cmd );
break;
case SPDKst NVME_OPCCreate_cq:
// 创建完成队列
createCompletionQueue ( cmd );
break;
}
break;
default:
// 不支持的命令
cmd->status = SPDKst NVME Status InvalidOpCode;
break;
}
// 更新完成队列
updateCompletionQueue ( cmd );
}四、嵌入式存储SPI完整链路
与高速NVMe SSD不同,嵌入式设备(如微控制器)通常使用SPI(Serial Peripheral Interface)接口连接存储设备:
CPU → SPI总线 → SPI接口 → SPI NAND/SPI NOR Flash1. SPI总线协议与分层
SPI是一种全双工、同步的串行通信协议,由摩托罗拉开发,广泛应用于嵌入式系统。其协议分层包括:
- 物理层:定义四个信号线:
- SCK(串行时钟):由主设备生成,同步数据传输
- MOSI(主出从入):主设备发送数据到从设备
- MISO(主入从出):从设备发送数据到主设备
- CS(片选):用于选择特定从设备
- 协议层:定义四种工作模式(由CPOL和CPHA组合决定)和命令帧格式:
- 模式0(CPOL=0,CPHA=0):时钟空闲低电平,数据在上升沿采样
- 模式1(CPOL=0,CPHA=1):时钟空闲低电平,数据在下降沿采样
- 模式2(CPOL=1,CPHA=0):时钟空闲高电平,数据在上升沿采样
- 模式3(CPOL=1,CPHA=1):时钟空闲高电平,数据在下降沿采样
- 应用层:定义针对特定设备的命令集,如SPI NOR Flash的读取命令和SPI NAND Flash的块擦除命令。
2. SPI NAND与SPI NOR Flash的区别
SPI NOR Flash和SPI NAND Flash在操作和应用场景上有显著差异:
- SPI NOR Flash:
- 支持随机读取,无需擦除即可直接编程
- 命令集简单,主要包含读取、页编程和块擦除命令
- 常用于存储启动代码(如BIOS、固件)
- 支持XIP(eXecution In Place)就地执行
- SPI NAND Flash:
- 需要擦除整个块后才能编程新数据
- 命令集更复杂,包括写使能、块擦除、页编程等
- 需要闪存转换层(FTL)管理地址映射和坏块
- 适合大容量数据存储
3. CPU与控制器角度的Demo范例
(1) CPU角度:STM32 SPI驱动示例
以下代码展示了如何在STM32微控制器上实现SPI接口与SPI NOR Flash的交互:
#include "SPI.h"
#include "GPIO.h"
// 定义SPI参数
SPI_HandleTypeDef hspi1;
GPIO_InitTypeDef GPIO_Initure;
// 初始化SPI
void SPI_Init ( void )
{
// 配置GPIO引脚
GPIO_Initure . Mode = GPIO_MODE_AF_PP;
GPIO_Initure . Pull = GPIO拉高;
GPIO_Initure . Speed = GPIO的速度_高速;
GPIO_Initure . AF = GPIO_AF5 SPI; // AF5为SPI1映射
// SCK
GPIO_Initure . Pin = GPIO_PIN_5;
GPIO_Init ( GPIOA, &GPIO_Initure );
// MOSI
GPIO_Initure . Pin = GPIO_PIN_6;
GPIO_Init ( GPIOA, &GPIO_Initure );
// MISO
GPIO_Initure . Pin = GPIO_PIN_7;
GPIO_Init ( GPIOA, &GPIO_Initure );
// CS
GPIO_Initure . Pin = GPIO_PIN_4;
GPIO_Initure . Mode = GPIO_MODE r_ PP;
GPIO_Initure . AF = 0; // 无复用功能
GPIO_Init ( GPIOA, &GPIO_Initure );
// 配置SPI句柄
hspi1.Instance = SPI1;
hspi1.Init.Mode = SPI_MODEc_ PP;
hspi1.Init的方向 = SPI团向_2LINES;
hspi1.Init.DataSize = SPI_DATASIZE_8BIT;
hspi1.Init.CLKPolarity = SPI Polarity_低;
hspi1.Init.CLKPhase = SPI Phase_1EDGE;
hspi1.Init.NSS = SPI_NSS SOFT;
hspi1.Init.BaudRatePrescaler = SPI_BAUDRATEPRESCALER_16;
hspi1.Init s . FirstBit = SPI s . FirstBIT MSB;
hspi1.Init s . TIMode = SPI s . TIMODE_DISABLE;
hspi1.Init s . CRCCalculation = SPI s . CRCCALCULATION_DISABLE;
// 初始化SPI
HAL SPI Init ( &hSpi1 );
}
// 发送一个字节并接收一个字节
uint8_t SPI传送接收 ( uint8_t data )
{
// 发送数据
HAL SPI transmit ( &hSpi1, &data, 1, 1000000 );
// 接收数据
HAL SPI receive ( &hSpi1, &data, 1, 1000000 );
return data;
}
// 向SPI NOR Flash发送命令
void SPI_NOR an derCommand ( uint8_t command, uint32_t address )
{
// 拉低片选
HAL_GPIO_WritePin ( GPIOA, GPIO_PIN_4, GPIO_PIN_RESET );
// 发送命令字节
SPI送收 ( command );
// 发送地址字节
SPI送收 ( ( address >> 16 ) & 0xFF );
SPI送收 ( ( address >> 8 ) & 0xFF );
SPI送收 ( address & 0xFF );
// 拉高片选
HAL_GPIO_WritePin ( GPIOA, GPIO_PIN_4, GPIO_PIN_SET );
}
// 从SPI NOR Flash读取数据
void SPI_NOR an derRead ( uint32_t address, uint8_t *data, uint32_t length )
{
// 拉低片选
HAL_GPIO_WritePin ( GPIOA, GPIO_PIN_4, GPIO_PIN_RESET );
// 发送读取命令
SPI送收 ( 0x03 );
// 发送地址
SPI送收 ( ( address >> 16 ) & 0xFF );
SPI送收 ( ( address >> 8 ) & 0xFF );
SPI送收 ( address & 0xFF );
// 读取数据
for ( uint32_t i = 0; i < length; i++ ) {
data[i] = SPI送收 ( 0xFF );
}
// 拉高片选
HAL_GPIO_WritePin ( GUIOA, GPIO_PIN_4, GPIO_PIN_SET );
}
// 向SPI NOR Flash写入数据
void SPI_NOR an derPageWrite ( uint32_t address, uint8_t *data, uint32_t length )
{
// 确保地址在页边界内
assert ( ( address % 256 ) + length <= 256 );
// 发送写使能命令
HAL_GPIO_WritePin ( GPIOA, GPIO_PIN_4, GPIO_PIN_RESET );
SPI送收 ( 0x06 );
HAL_GPIO_WritePin ( GPIOA, GPIO_PIN_4, GPIO_PIN_SET );
// 等待写使能完成
while ( ( hal GPIO ReadPin ( GPIOA, GPIO_PIN_4 ) & 0x02 ) == 0 );
// 拉低片选
HAL_GPIO_WritePin ( GPIOA, GPIO_PIN_4, GPIO_PIN_RESET );
// 发送页编程命令
SPI送收 ( 0x02 );
// 发送地址
SPI送收 ( ( address >> 16 ) & 0xFF );
SPI送收 ( ( address >> 8 ) & 0xFF );
SPI送收 ( address & 0xFF );
// 发送数据
for ( uint32_t i = 0; i < length; i++ ) {
SPI送收 ( data[i] );
}
// 拉高片选
HAL_GPIO_WritePin ( GPIOA, GPIO_PIN_4, GPIO_PIN_SET );
// 等待写入完成
while ( ( hal GPIO ReadPin ( GPIOA, GPIO_PIN_4 ) & 0x01 ) != 0 );
}(2) SPI NAND控制器角度:块擦除伪代码
以下伪代码展示了SPI NAND Flash控制器如何处理块擦除命令:
// 处理块擦除命令
void handle_block Erase ( uint32_t block_address )
{
// 检查写使能状态
if ( !is_write_enable ( )) {
// 如果未启用写使能,发送错误状态
set_status ( Erase_Busy );
return;
}
// 检查块地址是否有效
if ( block_address >= total_blocks ) {
// 发送无效地址错误
set_status ( Invalid地址 );
return;
}
// 检查块是否已擦除
if ( is_block_eraed ( block_address )) {
// 如果块已擦除,直接标记完成
mark_block_eraed ( block_address );
set_status ( Erase completes );
return;
}
// 设置擦除状态
set_status ( Erase_Busy );
// 执行增量步进脉冲擦除(ISPE)
for ( int i = 0; i < MAX ERASE STEPS; i++ ) {
// 应用擦除脉冲
apply erase pulse ( block_address, i + 1 );
// 验证擦除
if ( verify erase ( block_address )) {
// 擦除成功
mark_block_eraed ( block_address );
set_status ( Erase completes );
return;
}
}
// 多次擦除失败
set_status ( Erase Fail );
}五、拓展理解:M.2 不只是存储接口
M.2 接口最初是为超极本设计的小型扩展接口,但它远不止用于 SSD。M.2 规范定义了一个物理插座,其引脚可以配置为多种功能,通过不同的“Key”来区分:
- B Key (Socket 2):通常支持 SATA 和 PCIe x2,常见于一些无线网卡或旧款 SSD。
- M Key (Socket 3):通常支持 PCIe x4,是如今 NVMe SSD 的主流接口。
- A/E Key:常用于无线网卡(WiFi/BT)、蓝牙、NFC 等模块。
因此,一块 M.2 插槽的主板,既可以插 NVMe SSD(需要 M Key),也可以插无线网卡(需要 A/E Key),甚至有些扩展卡可以转接出额外的 USB 或 SATA 接口。近年来,随着算力需求的提升,M.2 接口也被用作 AI 加速卡、FPGA 加速卡等算力模组的通用接口,因为它们同样需要高速 PCIe 总线。这就使得 M.2 成为一个极其灵活的物理标准,为小型化设备提供了丰富的扩展可能。
AI 加速模块的典型应用包括:
- 寒武纪 MLU220:基于 MLUv02 架构,集成 8TOPS 理论峰值性能,功耗仅 8.25W,采用 M.2 2280 B+M key 接口(PCIe 3.0 x2)
- Hailo-10H:使用标准 M.2 外形,可插入现有的 PC 和边缘设备的 M.2 插槽,实现实时深度学习推理
- DEEPX DX-M1:提供 25 TOPS 的 AI 推理性能,功耗仅 1-5W,采用 M.2 M-Key 接口,支持 PCIe Gen3 x4
- MemryX MX3:采用四个 MX-3”数字内存计算”AI ASIC,通过直接在内存中处理 AI 工作负载,提供无与伦比的效率和性能
总结:
通过理清物理接口、传输总线、通信协议这三个层次,我们不仅能看懂 SSD 的参数,更能理解从 PC 到嵌入式系统,数据存储的完整链路。无论是 PCIe 的高速并行,还是 SPI 的简洁低功耗,它们都是构建现代数字世界的基石。