Pytorch Lightning 和 HuggingFace 的 Trainer 哪个好用?
Transformers的Trainer本身已经集成了Acceletor和DeepSpeed,支持DDP和DeepSpeed-Zero,以及基于Acceletor的朴素流水线并行(GPU吞吐率较低)。而Transformers家的TRL库也是基于BaseTrainer(其基类是Transformers Trainer),又封装了一层,比如SFT-Trainer / DPO-Trainer / GRPO-Trainer。
Trainer本身已经算是封装地比较厉害了,中小型的实验可以快速使用Trainer或TRL,或者魔改。常用的LlamaFactory,也是在Trainer基础上二次开发。
本文主对Trainer源码进行了删改,便于理解其主流程
SFT训练基本代码
import torch
from transformers import TrainerCallback
rank = 64
alpha = rank * 2
lora_config = LoraConfig(
task_type = TaskType.CAUSAL_LM,
target_modules = ["q_proj","k_proj","v_proj","o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode = False, # 训练模式
r=rank,
lora_alpha=alpha, #Lora aLaph,具体作用参见Lora原理
lora_dropout=0.1
)
train_args = TrainingArguments(
output_dir=f"./output/Qwen/test_rank{rank}_alpha{alpha}",
per_device_train_batch_size=1,
gradient_accumulation_steps=3,
logging_steps=4,
num_train_epochs=7, # 小模型要多训练会儿
save_steps=100,
eval_steps=10,
learning_rate=8e-5,
save_on_each_node=True,
gradient_checkpointing=True,
lr_scheduler_type="cosine",
warmup_steps=20,
report_to=["tensorboard"]
)
# Load best model at end=True
logger.info(f"args: {train_args}")
logger.info(f"【Start Training!】")
# 不LoRA
# model = get_peft_model(model, lora_config)
# model.print_trainable_parameters()
class MemoryTraceCallback(TrainerCallback):
def __init__(self, output_dir="memory_trace", target_step=42):
self.output_dir = output_dir
self.target_step = target_step
self.recorded = False
def on_train_begin(self, args, state, control, **kwargs):
# 开启显存历史记录 (包含堆栈信息)
print(f"🚀 [Memory] 开始记录显存分配历史...")
torch.cuda.memory._record_memory_history(
max_entries=100000,
context="all" # 记录 Python 堆栈
)
def on_step_end(self, args, state, control, **kwargs):
# 我们只需要跑几步,比如第 5 步结束后抓取快照
if state.global_step == self.target_step and not self.recorded:
print(f"📸 [Memory] 第 {self.target_step} 步结束,正在保存显存快照...")
try:
# 保存快照
torch.cuda.memory._dump_snapshot(f"{self.output_dir}_snapshot.pickle")
print(f"✅ [Memory] 快照已保存至 {self.output_dir}_snapshot.pickle")
# 停止记录
torch.cuda.memory._record_memory_history(enabled=None)
self.recorded = True
# 可选:直接停止训练,因为我们只想要分析数据
control.should_training_stop = True
except Exception as e:
print(f"❌ [Memory] 保存失败: {e}")
# 在 Trainer 中添加这个 Callback
trainer = Trainer(
model=model,
args=train_args,
train_dataset=tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[MemoryTraceCallback()],
)
trainer.train()完整代码(LoRA训练,注释即为全参SFT)
Qwen3_0_6B_LoRA_自我认知.ipynb
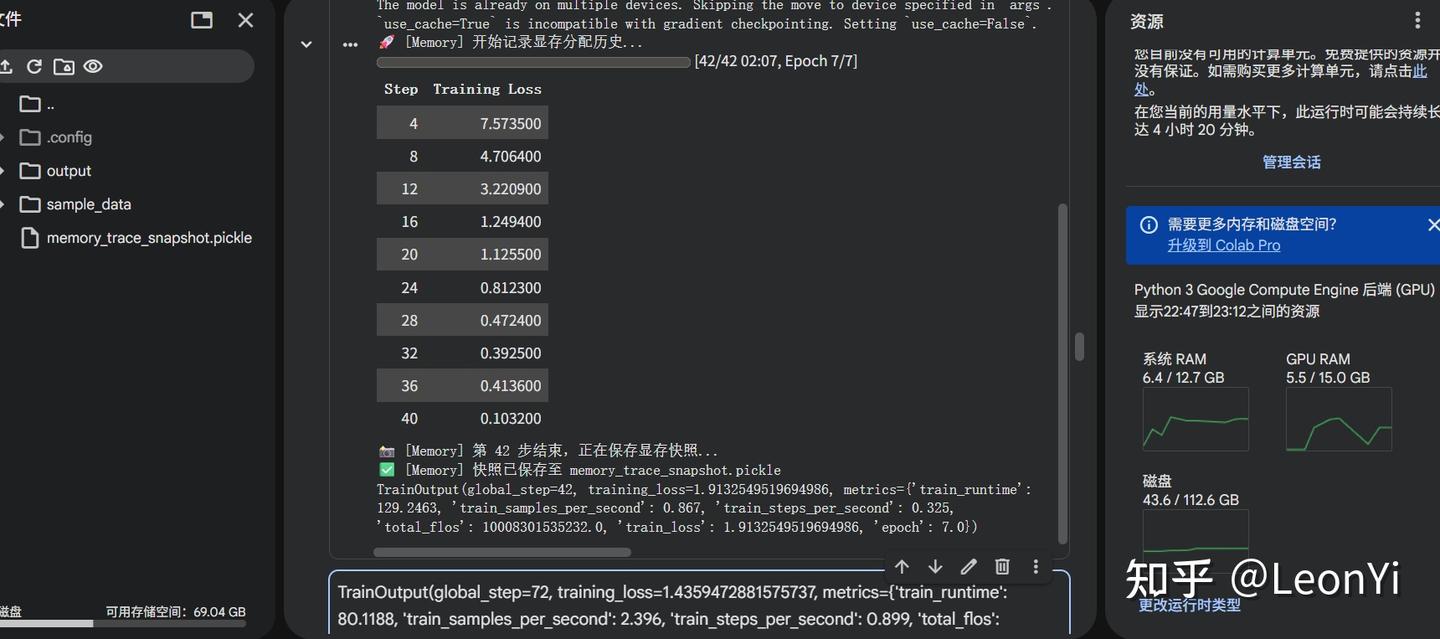
通过注入PyTorch Memory Snapshot代码,并分析结果:
- 拿到生成的 xxx_snapshot.pickle 文件。
- 打开 PyTorch 官方提供的分析页面:https://pytorch.org/memory_viz
- 把文件拖进去。
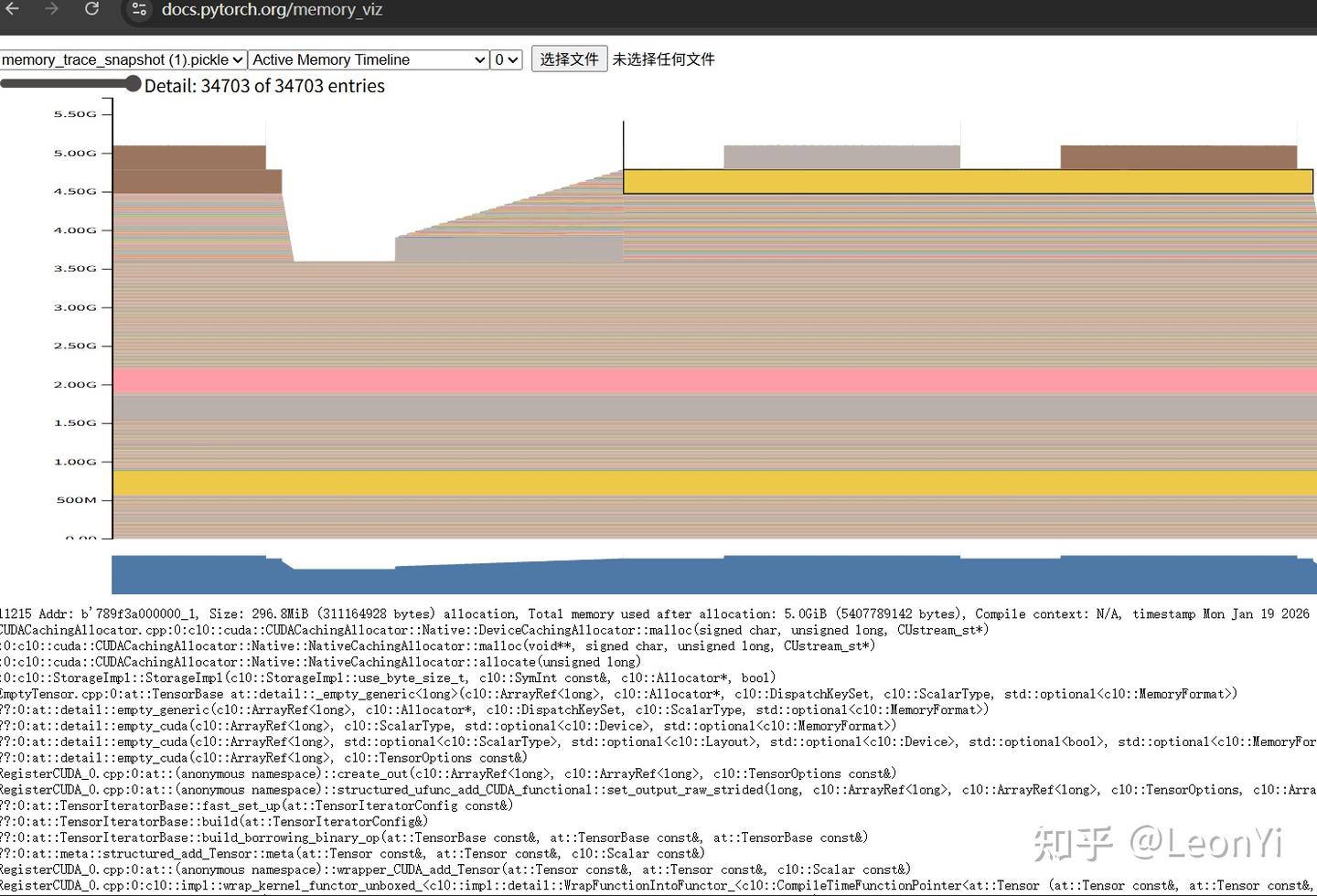
可以看到原生Trainer最小版本全参SFT,显存占用为模型参数的10倍量级左右(猜测是torch.amp简化了混合精度的MasterWeight,而且可能优化器状态也是半精度),0.6B在5GB显存多一点左右
逻辑关系梳理:
SFT-Trainer (trl) -> BaseTrainer(trl) ->Trainer(transformers)
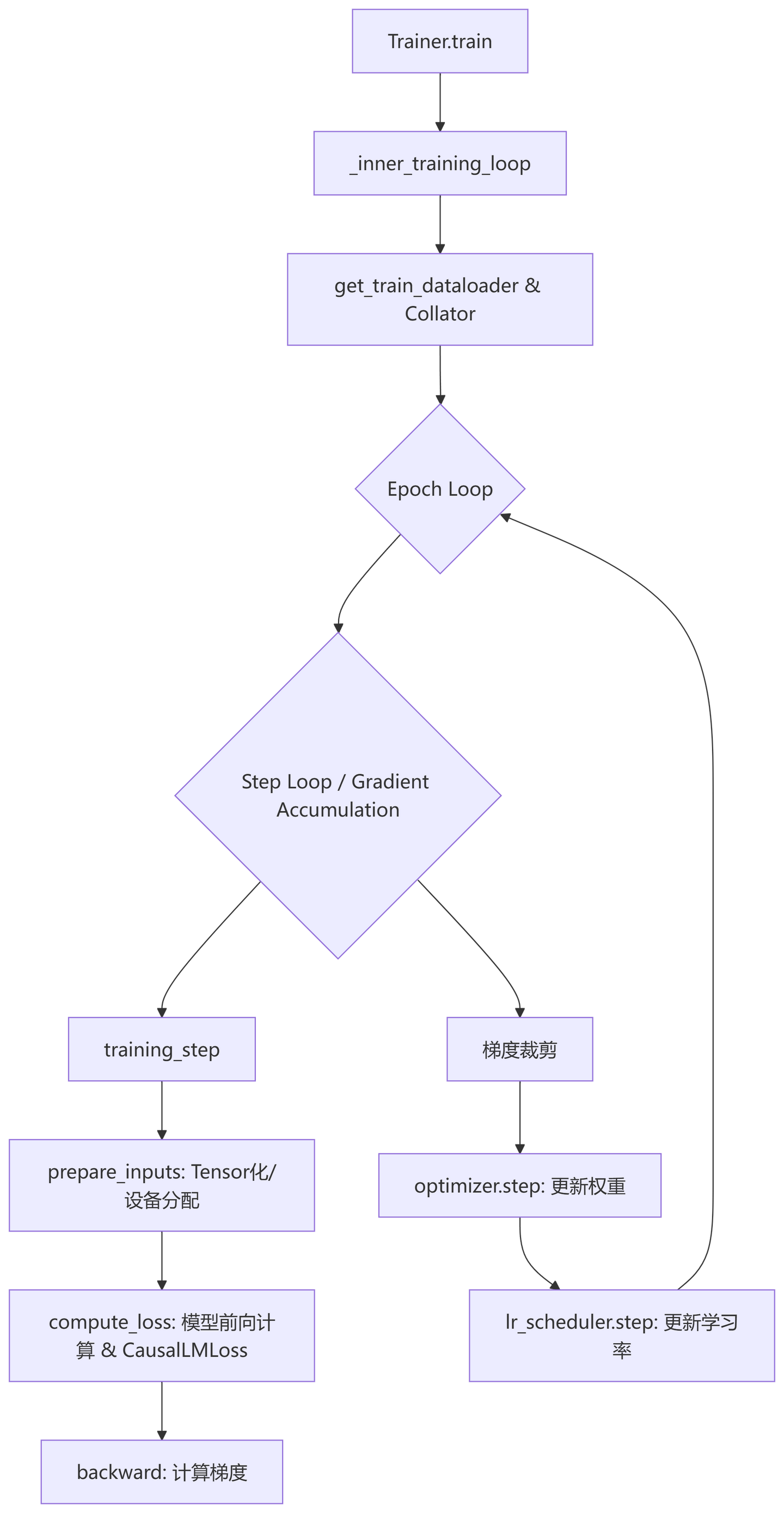
trainer的入参
trainer的train()函数
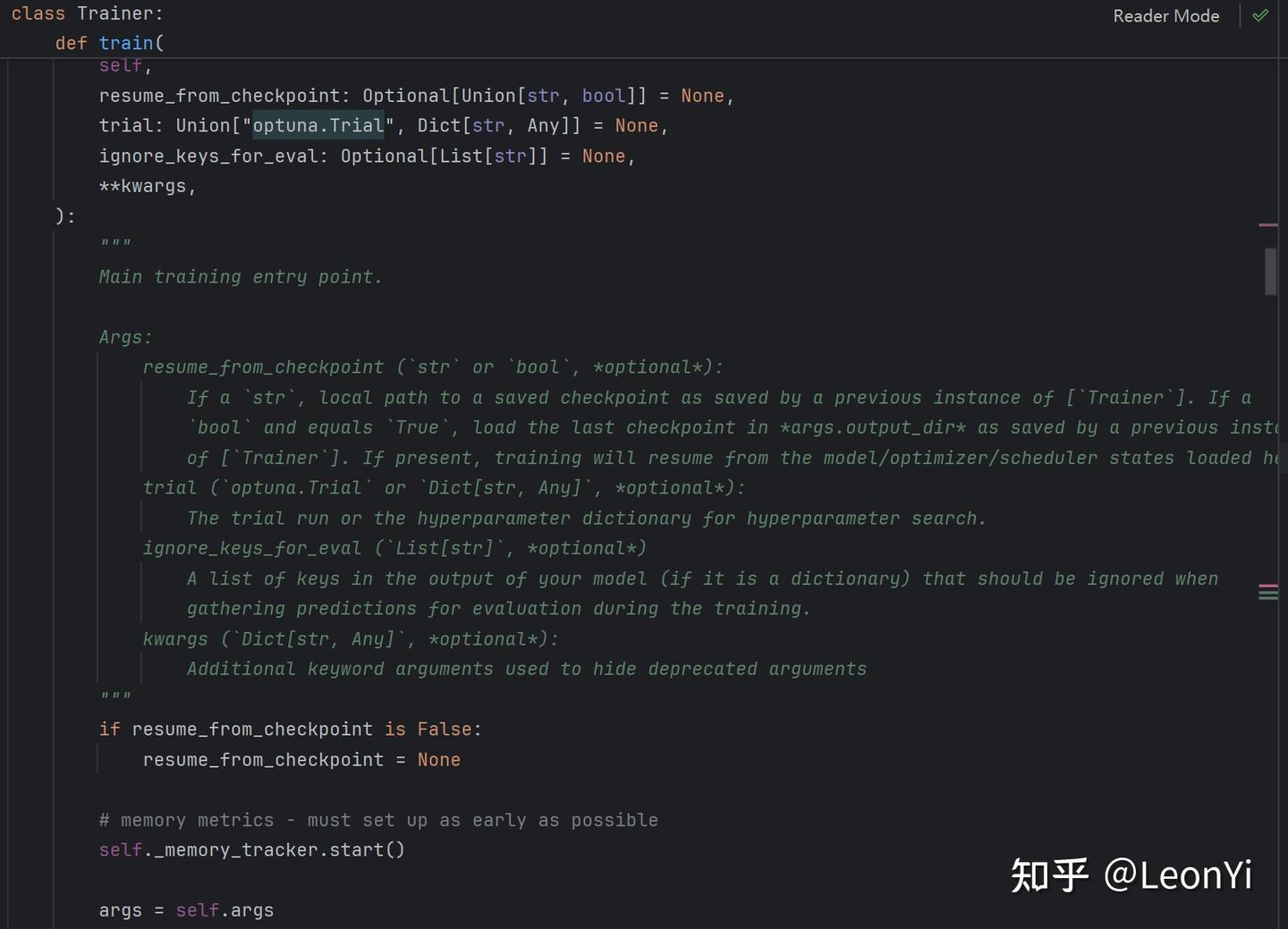
train()函数内部的真正训练调用inner_training_loop()函数
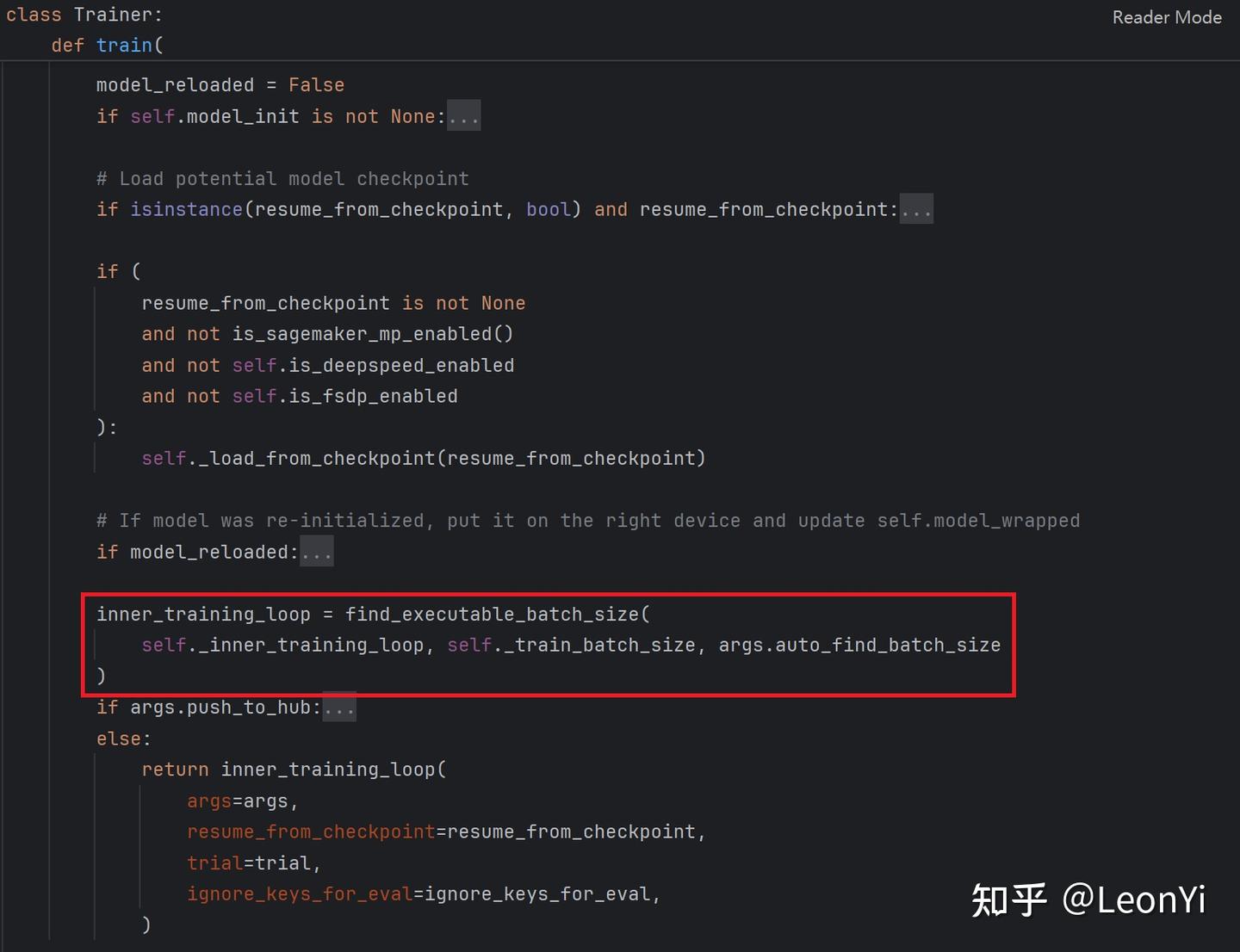
_inner_training_loop()
_inner_training_loop的入口部分代码, 通过self.get_train_dataloader()加载训练样本train_dataloader,并获取一些训练步长相关的超参数。同时根据不同的配置项加载或从checkpoint中恢复模型。
这里的次要逻辑较复杂,故忽略
在微调时get_train_dataloader()可选的dataclloator,本质都是在其内部调用pad_without_fast_tokenizer_warning方法,使用toknizer对已经tokenized的本文即features(features主要由{input_ids,attention_mask,labels}构成)进行padding,并执行label 对齐的 batch 构造器
例如:
>>> features = [
... {"input_ids": [1, 2, 3], "attention_mask": [1, 1, 1]},
... {"input_ids": [4, 5], "attention_mask": [1, 1]},
... ]
>>> tokenizer.pad(features, return_tensors="pt")
{
"input_ids": tensor([[1, 2, 3], [4, 5, 0]]),
"attention_mask": tensor([[1, 1, 1], [1, 1, 0]])
}| collator 名称 | 面向模型类型 | 特点 | GPT 可用吗 |
|---|---|---|---|
| DataCollatorForLanguageModeling(mlm=True) | BERT | 随机 mask 训练 | ❌ |
| DataCollatorForLanguageModeling(mlm=False) | GPT | 自回归 label 构造 | ✅ |
| DataCollatorForSeq2Seq | Seq2Seq (T5/BART),兼容 GPT | 通用 padding、label 对齐、支持 decoder_input_ids | ✅(会自动退化) |
| default_data_collator | 通用 | 简单 pad + tensor 化 | ✅ |
| DataCollatorWithPadding | 通用 | 动态 padding,仅对输入 | ✅(但不处理 labels) |
譬如DataCollatorWithPadding:
class DataCollatorWithPadding:
"""Data collator that will dynamically pad the inputs received."""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
return_tensors: str = "pt"
def __call__(self, features: list[dict[str, Any]]) -> dict[str, Any]:
batch = pad_without_fast_tokenizer_warning(
self.tokenizer,
features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors=self.return_tensors,
)
if "label" in batch:
batch["labels"] = batch["label"]
del batch["label"]
if "label_ids" in batch:
batch["labels"] = batch["label_ids"]
del batch["label_ids"]
return batch这里就是我们用trainer训练开始时,经常看到的命令行日志了。
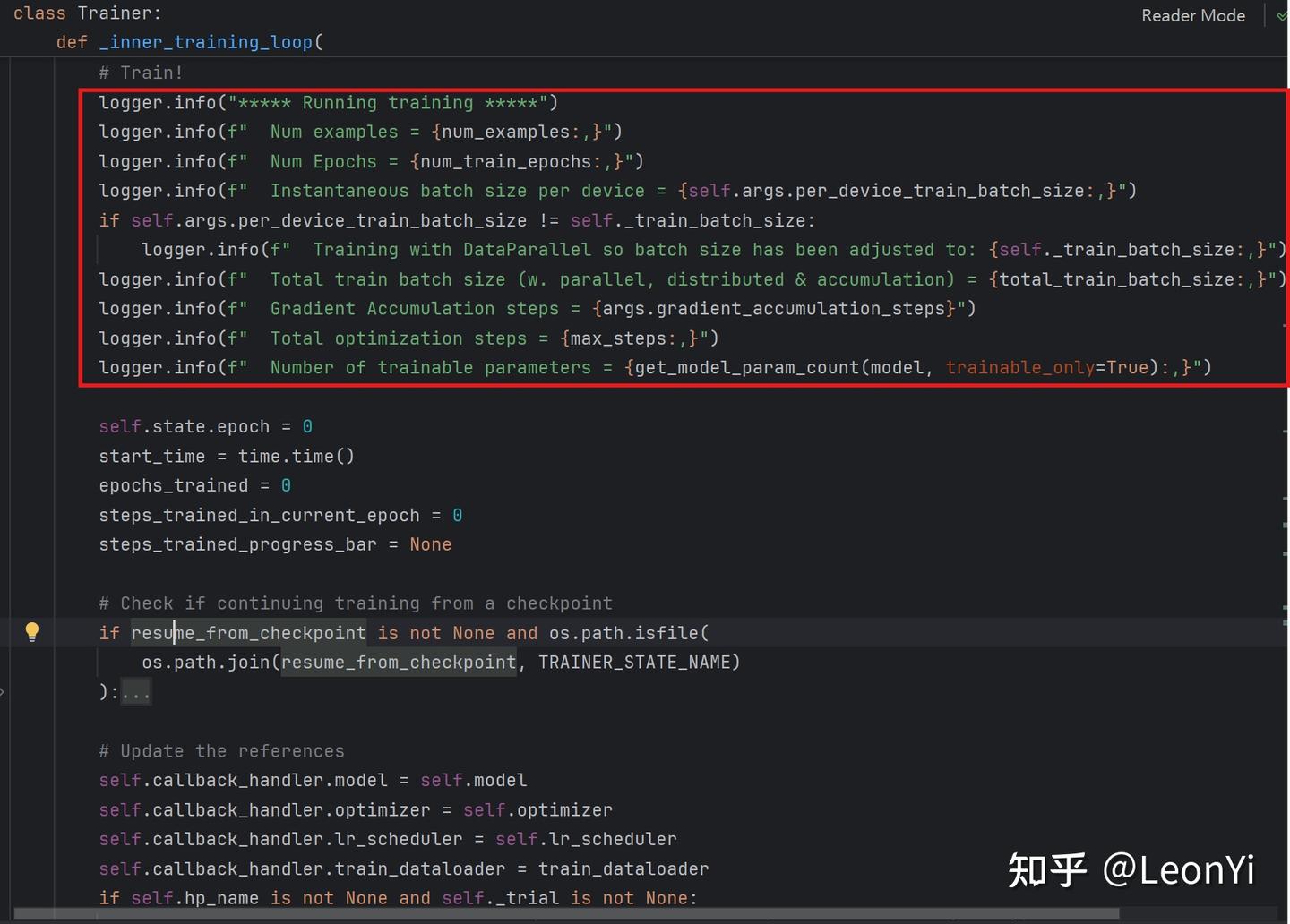
这里就是真正的训练内循环了,按num_train_epochs进行迭代,在这个内循环中取样本做前向传播,得到1个step的损失tr_loss_step
get_batch_samples()函数,将从data_loader的迭代器里面取batch_samples和num_items_in_batch,然后获取单个inputs再调用training_step(),这样来完成单次前向传播和反向传播计算梯度的过程(后面将会详细解释它)。
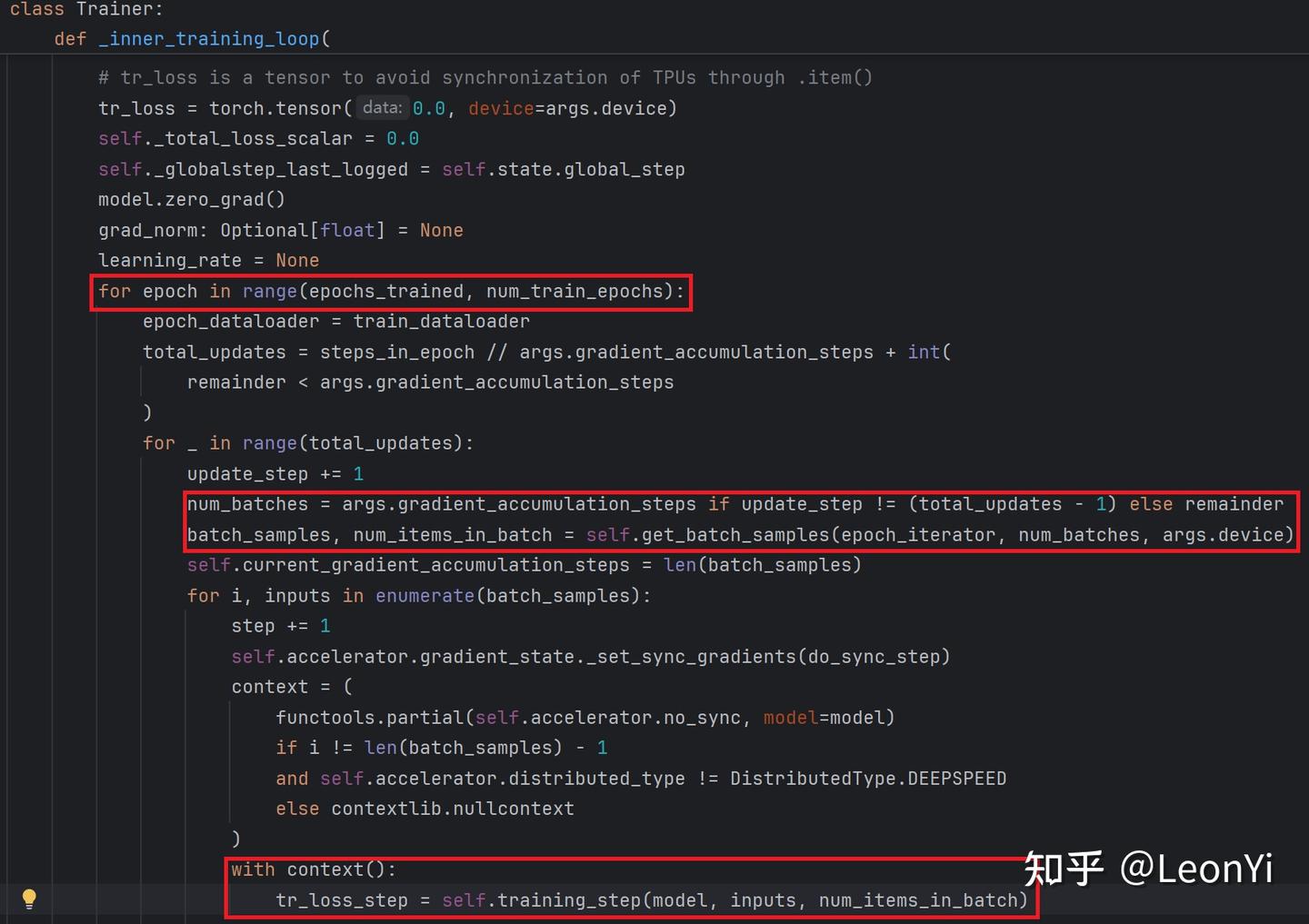
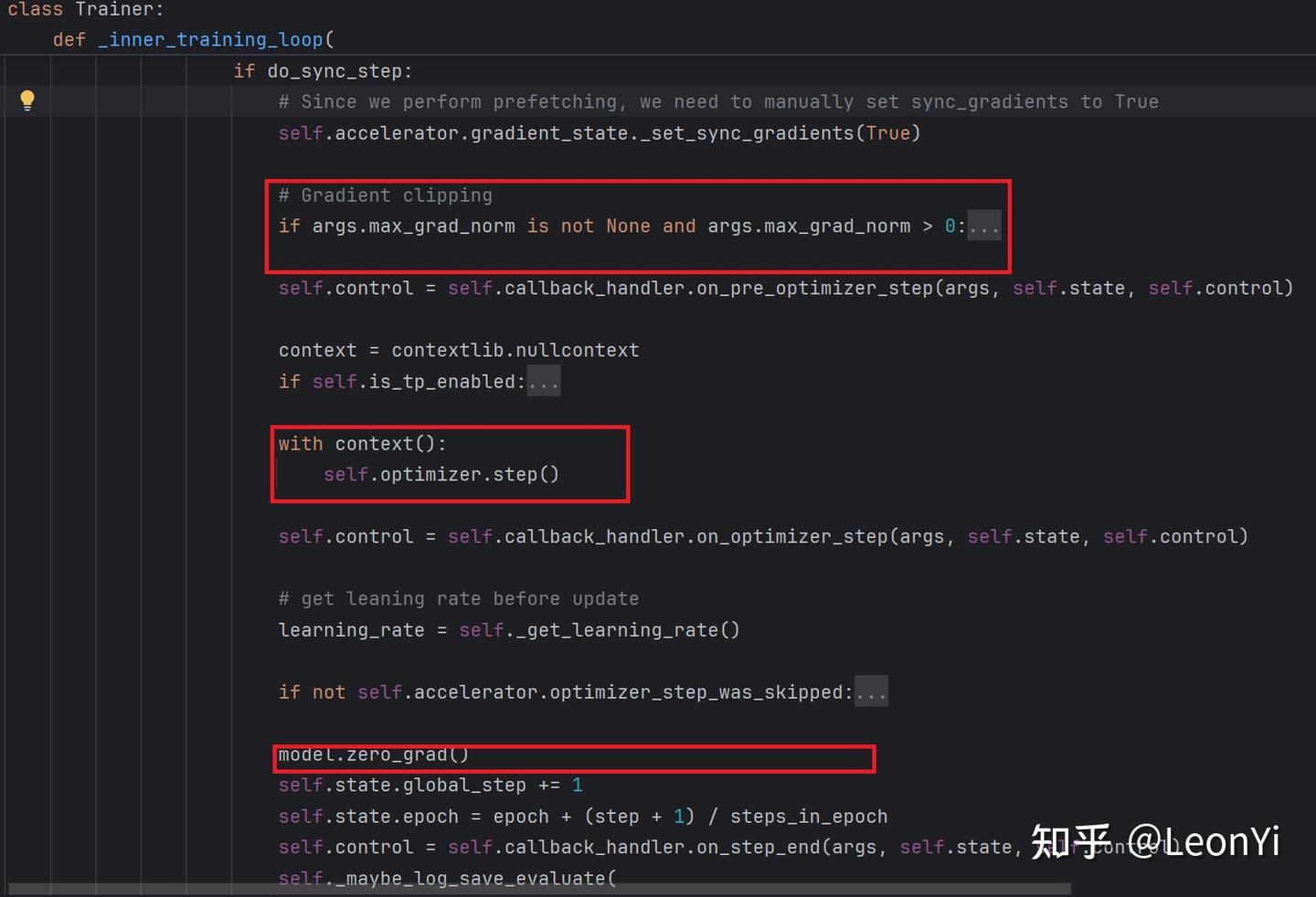
然后,在training_step()之后,做梯度裁剪,并衔接优化器做参数更新optimizer.step()
如果涉及混合精度训练,还有对应的梯度损失缩放
training_step()
那么training_step()的输入是:
model: nn.Moduleinputs: dict[str, Union[torch.Tensor, Any]]num_items_in_batch: Optional[torch.Tensor] = None
training_step()里面做了什么呢,主要分为3步:
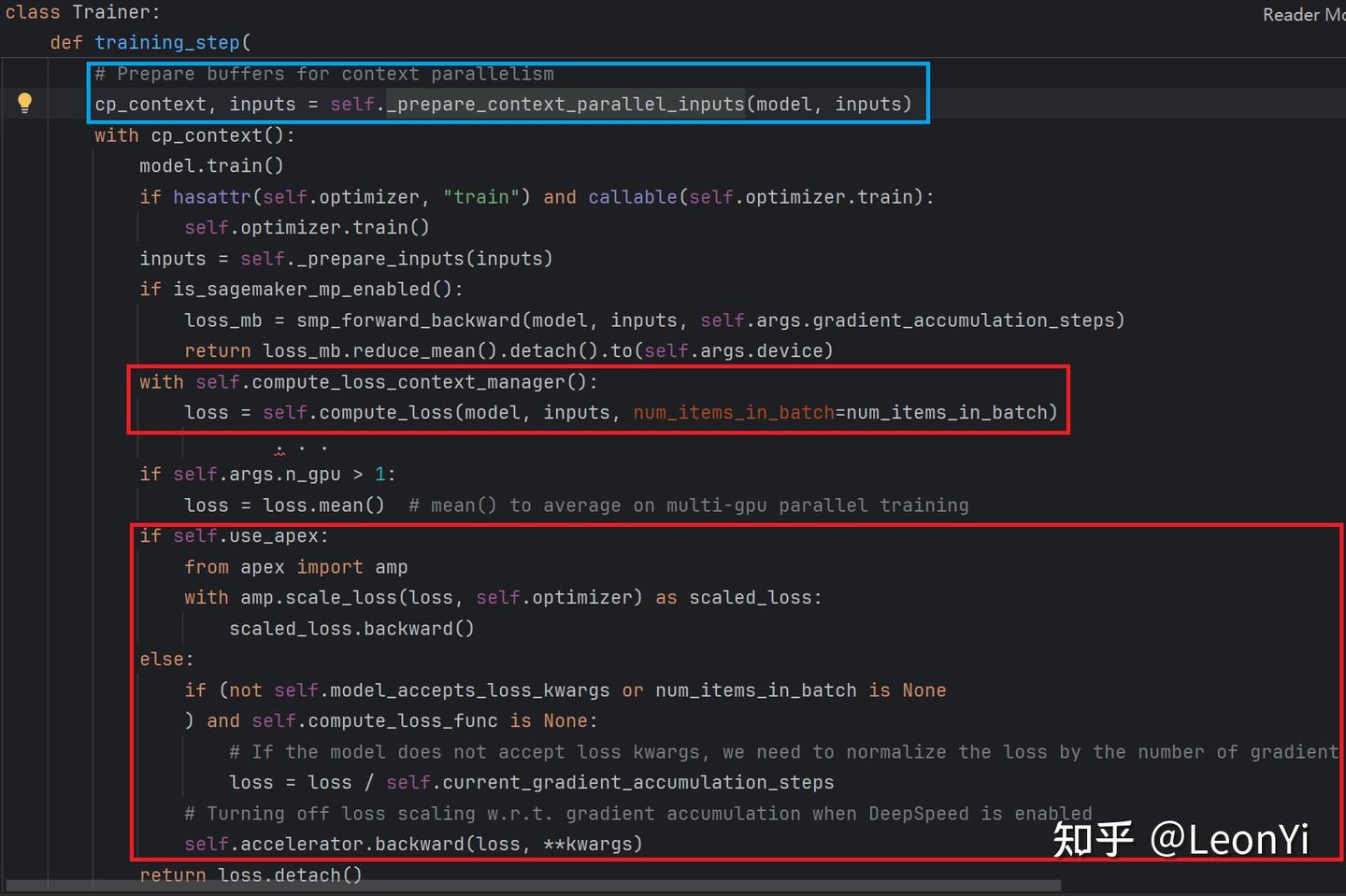
- 输入预处理, _
prepare_context_parallel_inputs(model, inputs)函数, 将用于获取模型输入(包括input_ids,labels或shift_labels,以及position_ids和attention_mask) - 前向传播损失计算, compute_loss(model, inputs),进行这个函数通常可以重写
- 反向传播计算梯度, backward()
compute_loss()部分就是inputs传入model得到输出, 其具体损失计算逻辑如下(在输入有labels的场景下,如果有compute_loss_func()函数或配置了label_smooth标签平滑,此时会将labels pop取出来,单独计算loss):
- 如果有自定义compute_loss且输入有
labels,则执行该损失函数 - 如果label_smooth为
True且输入有labels, 则执行label_smooth()函数 - 否则,直接取模型的内部算出的loss
| 场景 | 是否 pop 掉 labels | 模型是否算 loss | loss 来源 |
|---|---|---|---|
| 自定义 compute_loss | ✅ 是 | ❌ 否 | 用户自定义 |
| label smoothing | ✅ 是 | ❌ 否 | label_smoother |
| 普通训练(无 smoothing) | ❌ 否 | ✅ 是 | 模型内部 loss |
if (self.label_smoother is not None or self.compute_loss_func is not None) and "labels" in inputs:
labels = inputs.pop("labels")
else:
labels = None
if self.model_accepts_loss_kwargs:
kwargs = {}
if num_items_in_batch is not None:
kwargs["num_items_in_batch"] = num_items_in_batch
inputs = {**inputs, **kwargs}
outputs = model(**inputs)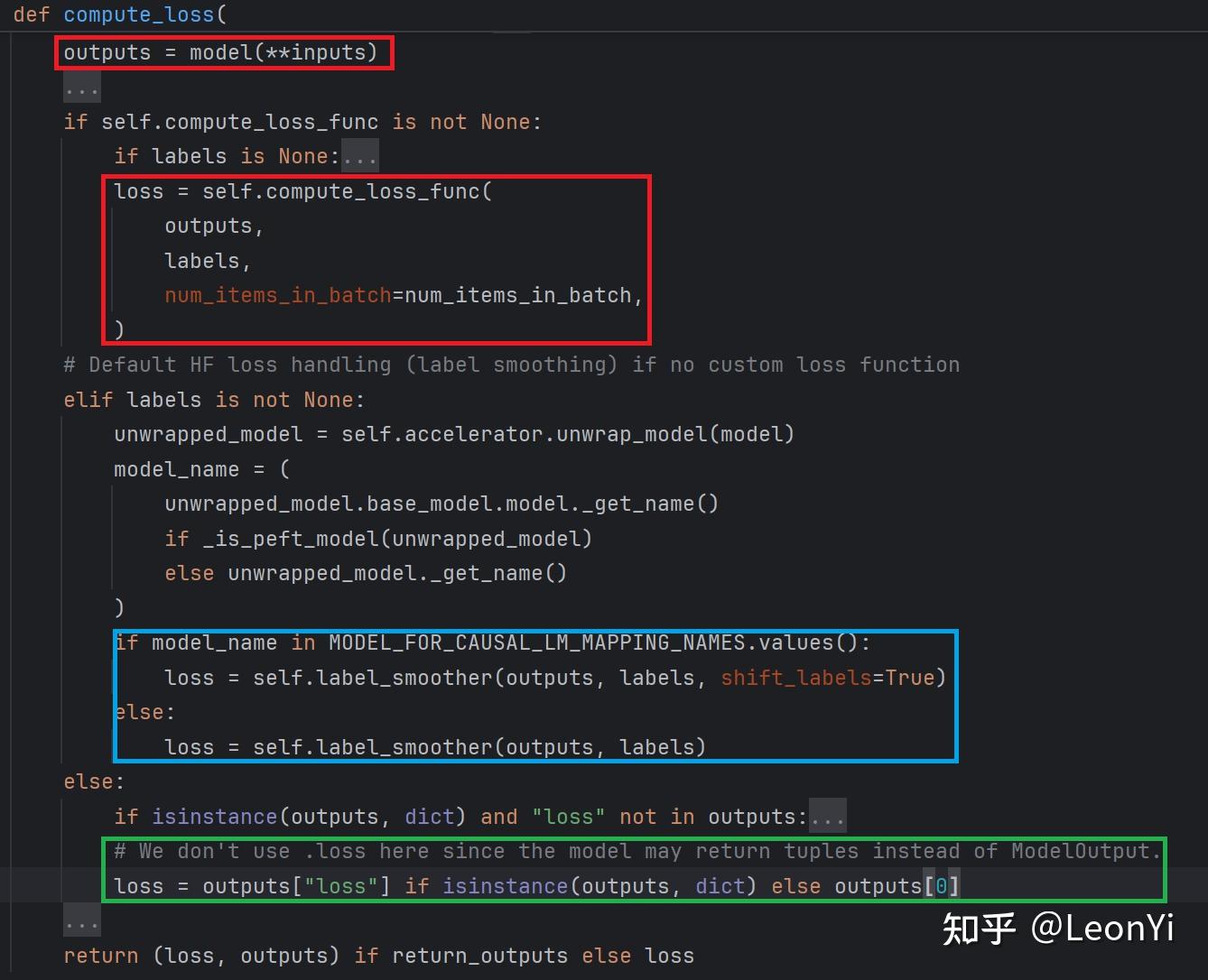
SFT损失函数
本质上SFT和RL-LLM都是Teacher-Forcing的范式,前向传播强制相当于计算一次prefix,然后得到逐token的logit计算损失(RL在LLM就是加权交叉熵)
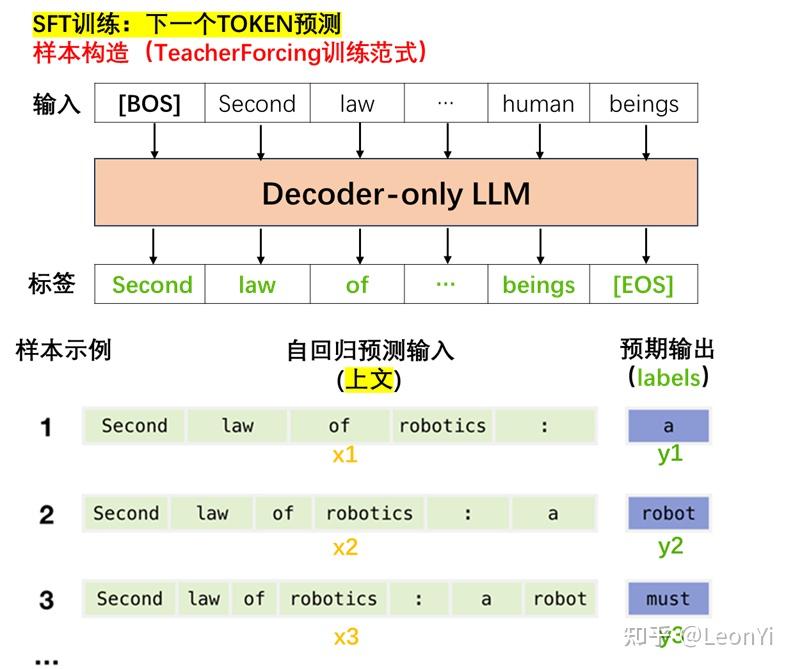
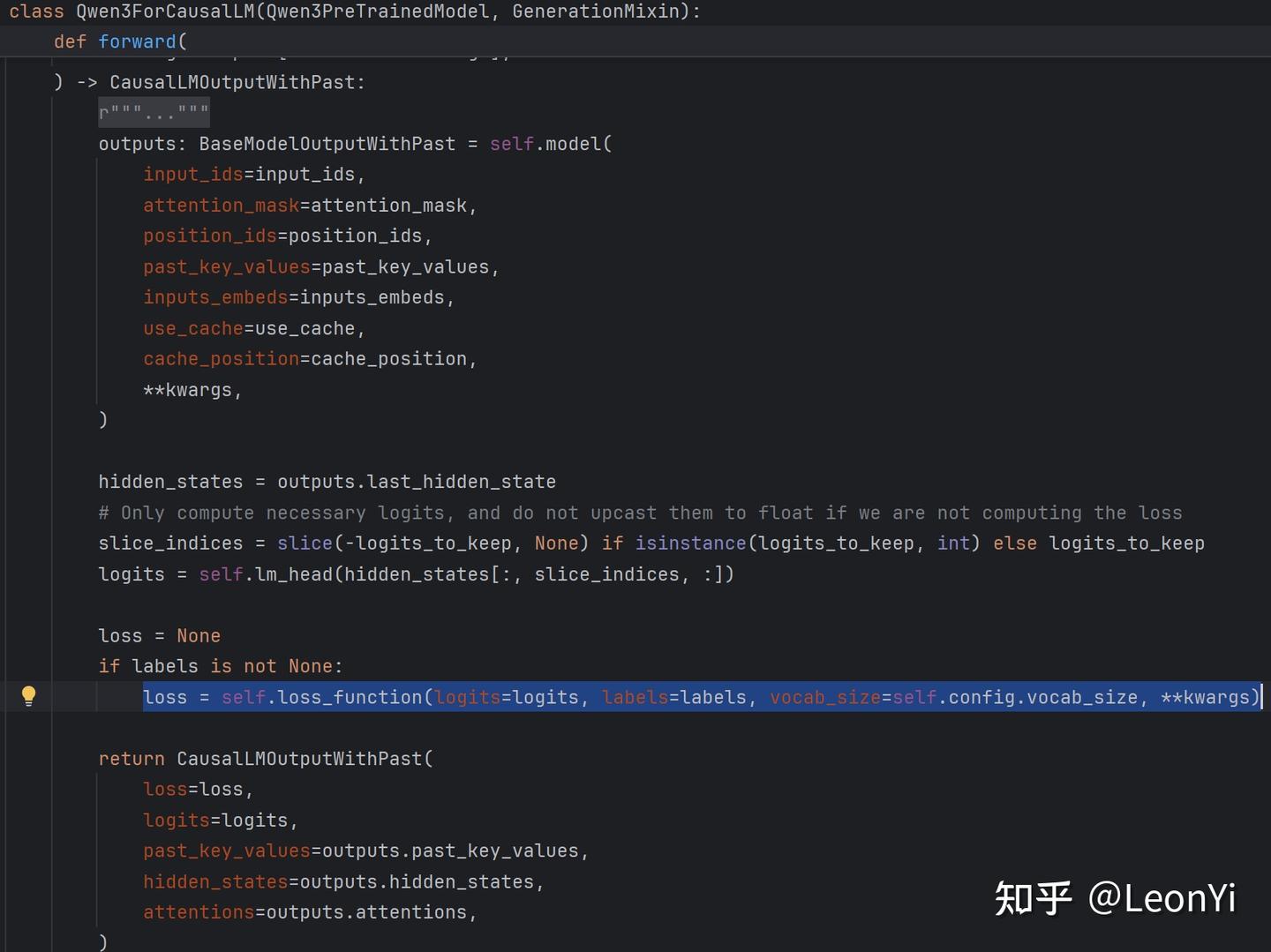
以Qwen3的dense模型为例,在modeling_qwen3.py中Qwen3ForCausalLM继承自Qwen3PreTrainedModel, Qwen3PreTrainedModel又继承自模型基类PreTrainedModel,其loss_fucntion默认是ForCausalLM类别,故然会调用loss/loss_utils中的ForCausalLMLoss函数。
def ForCausalLMLoss(
logits,
labels,
vocab_size: int,
num_items_in_batch: Optional[torch.Tensor] = None,
ignore_index: int = -100,
shift_labels: Optional[torch.Tensor] = None,
**kwargs,
) -> torch.Tensor:
# Upcast to float if we need to compute the loss to avoid potential precision issues
logits = logits.float()
if shift_labels is None:
# Shift so that tokens < n predict n
labels = nn.functional.pad(labels, (0, 1), value=ignore_index)
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
logits = logits.view(-1, vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(logits.device)
loss = fixed_cross_entropy(logits, shift_labels, num_items_in_batch, ignore_index, **kwargs)
return lossForCausalLMLoss函数,又基于fixed_cross_entropy函数。
def fixed_cross_entropy(
source: torch.Tensor,
target: torch.Tensor,
num_items_in_batch: Optional[torch.Tensor] = None,
ignore_index: int = -100,
**kwargs,
) -> torch.Tensor:
reduction = "sum" if num_items_in_batch is not None else "mean"
loss = nn.functional.cross_entropy(source, target, ignore_index=ignore_index, reduction=reduction)
if reduction == "sum":
# just in case users pass an int for num_items_in_batch, which could be the case for custom trainer
if torch.is_tensor(num_items_in_batch):
num_items_in_batch = num_items_in_batch.to(loss.device)
loss = loss / num_items_in_batch
return loss在看源码的时候忘了更新版本,发现是4.32.0的,后面更新到4.57.3了。重新看了下代码,整体流程区别不大。因为trainer本身还只是训练封装的类。
SFT-Trainer和Trainer
SFT-Trainer继承了Trainer,并且添加了SFT的逻辑, 改动很小:
- _prepare_dataset, 加入了
formatting_func()函数匹配样本中的提示词模板将其标签置为-100 - compute_loss()函数基本就是调用trainer的compute_loss()函数
其实GRPO-Trainer的主流程还是继承SFT-Trainer,但是改写了训练前的样本Rollout的过程,生成了一组用优势加权的SFT样本
本文由 Zhihu on Obsidian 创作并发布