图片转Word表格识别的大幅优化
《扫描仙人》春节期间也没闲着,主要对表格识别(图转word中的表格)的效果做出了一定优化。写这篇文章之前,我随便找了几个表格,尝试了一下,给各位用户老爷展示一下。下面的表格,都是从老演员《扫描全能王》母公司的财报中获得的,绝对随便截图的。以下为了统一,全部先放原图,再放表格识别后的Word截图。
1个大表格

总体上内容基本是正确的,但有2个问题:
- 字号总体偏小了。由于现在还没有开发字号预估的模型,字号,列宽,行高等,都是通过后处理规则实现的,所以经常会出现字号不是大了,就是小了的问题。在后面几个测试用例中,也存在相同的问题,后面还需要优化。
- 最后一行没显示全。这次优化的重点就是让表格的列宽尽可能符合原图,文字也尽量填满单元格,不溢出到单元格外面。但是在表格的边缘行和列,还是有些问题,没想到第一个测试用例就把这个问题给暴露了,我就说测试用例真的是随便挑的。
我一共测试了5张图,第3章,第4张,第5张,也基本是类似的情况,所以就不赘述了。
一个bad case
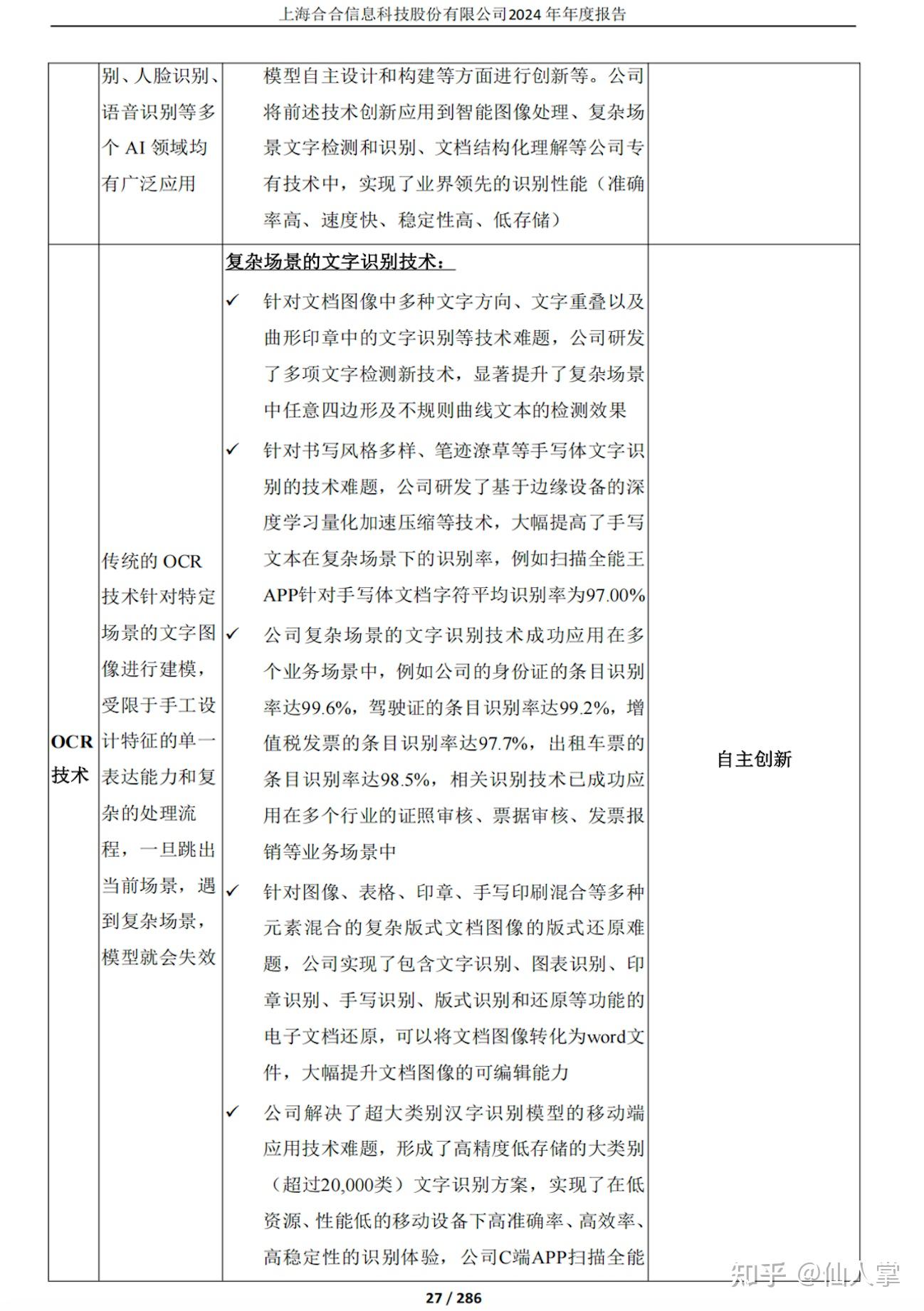
这个表格看上去不难,但是识别的结果应该说完全错了。因为我目前的做法是,先对图片进行了版面识别,然后再将版面识别的结果送入大模型。看了下这倒霉的版面识别结果。。。表格的位置切分错了,所以传给大模型的根本就不是一个表格,也就导致了产生了一个完全乱套的表格。
不过这个问题也不用太担心,优化后的版面识别已经在路上了,只不过我个人时间,能力着实有限,进度没有规模化的公司搞的那么快罢了。
总的来说,优化后的表格识别,在图转word的表格显示上,比之前有了大幅进步,在同等价格的扫描产品中,是不是“遥遥领先”了?
还有一件事
整个2月份,除了上述优化外,《扫描仙人》的首页也被升级了,升级后的首页,终于支持在全部文件中任意的搜索和排序了。带有新首页的1.1.3版本,已经提交到应用商店审核,不日将上线,首页符合您的审美吗?
编辑于 2026-03-04 · 著作权归作者所有