AMD R7 8845H (780M核显) 在 Ubuntu 24.04 开启 Ollama GPU 加速的避坑指南
📝 背景与痛点
在使用搭载 AMD R7 8845H(集成 Radeon 780M 核显)的迷你主机或轻薄本作为本地 AI 服务器时,许多人会选择部署 Ollama。然而在 Ubuntu 24.04 环境下,初次安装 Ollama 后通常会遇到一个致命问题:系统完全使用 CPU 进行推理,780M 核显处于沉睡状态(利用率为 0%),导致大模型出字速度极其缓慢。
通过查看日志(journalctl -u ollama | grep vram),通常会发现 Ollama 识别到的显存为 total_vram="0 B"。
💣 避坑警告:不要盲目使用 ROCm 参数
网上的常规教程通常会建议 AMD 用户注入环境变量 HSA_OVERRIDE_GFX_VERSION=11.0.0 来强行握手 ROCm 引擎。 注意:对 8845H 这种最新的 APU 架构,此方法大概率会失效! 由于 APU 采用的是与 CPU 共享物理内存的机制,强制使用独立显卡的 SDMA(直接内存访问)通道,会导致底层冲突,触发 Segmentation fault(段错误)甚至服务直接崩溃。
终极解法:放弃挑剔的 ROCm,改用兼容性极佳的 Vulkan 引擎!
以下是经过实战验证的完整保姆级通关步骤:
🚀 成功开启 GPU 加速的完整步骤
第一步:解决 Linux 底层硬件权限问题
Linux 出于安全考虑,默认不允许后台服务直接调用显卡底层算力。Ollama 在后台是作为一个独立名为 ollama 的系统服务账号运行的,所以我们需要把这个打工人拉进显卡的 VIP 用户组。
在终端依次执行以下命令:
sudo usermod -aG render ollama
sudo usermod -aG video ollama(注:网上的教程通常只让加 $USER 当前用户,这无法解决后台服务无权限看显存的问题,必须赋予 ollama 账号权限。)
第二步:开启 Vulkan 跨平台加速引擎
Vulkan 不依赖 AMD 官方 ROCm 驱动的天坑,它直接调用显卡最基础的图形管线进行矩阵运算,完美兼容 780M 核显。
执行以下命令,将 Vulkan 开关写入 Ollama 的系统服务配置中:
sudo mkdir -p /etc/systemd/system/ollama.service.d
echo -e "[Service]\nEnvironment=\"OLLAMA_VULKAN=1\"" | sudo tee /etc/systemd/system/ollama.service.d/override.conf第三步:重载并重启服务
配置写入后,让系统重新读取服务文件并重启 Ollama:
sudo systemctl daemon-reload
sudo systemctl restart ollama第四步:验证是否成功
方法一:查看底层日志 运行以下命令查看 Ollama 的启动日志:
journalctl -u ollama -n 50 --no-pager | grep -i -E "vulkan|vram"如果输出信息中出现了类似于 type=iGPU total="17.6 GiB" 和 total_vram="17.6 GiB" 的字样,说明 Vulkan 已经成功识别出 780M,并且调用了系统共享内存作为显存!
方法二:实机满载测试
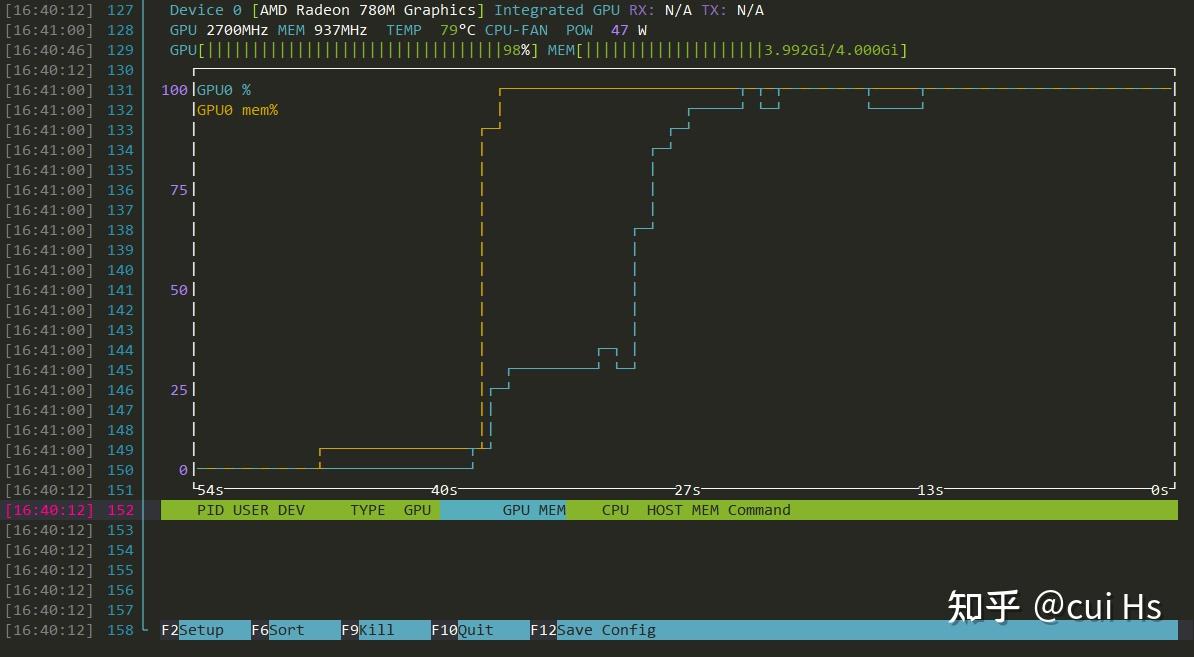
- 安装并运行 AMD 显卡监控神器:
sudo apt install nvtop -y,然后输入nvtop保持界面开启。 - 新开一个终端窗口,运行大模型:
ollama run qwen3:14b "请用200字形容一下赛博朋克的世界。" - 切回 nvtop 界面,你会看到
AMDGPU那一行的GPU%飙升至 90% 以上,出字速度呈瀑布式倾泻,大功告成!
💡 附加运维小知识:为什么跑完任务 GPU 显存没释放?
当你跑完一次问答后,你会发现 nvtop 里的 GPU 利用率虽然降到了 0%,但 VRAM(显存)依然被占用了几个 G。 不要慌,这是正常的,并非内存泄漏。
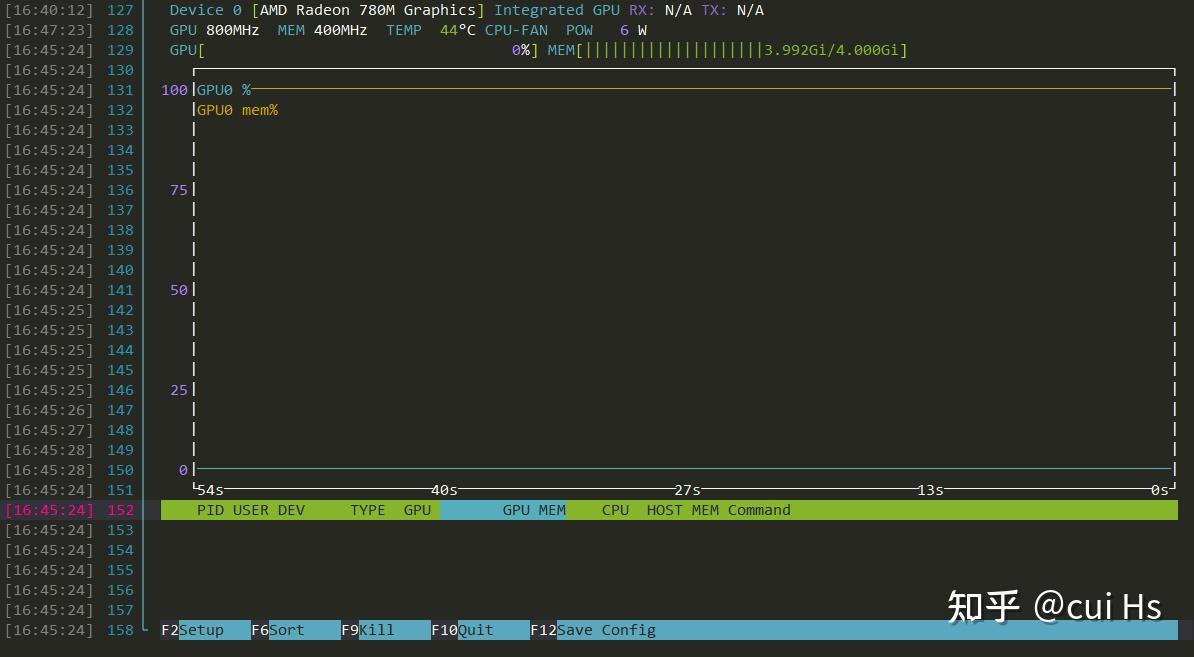
这是 Ollama 官方设计的 “模型常驻(Keep-Alive)” 机制。为了避免下次对话时再花几十秒重新从硬盘(SSD)将十几 G 的模型冷启动加载到显存中,Ollama 默认会将大模型在显存中保留 5分钟(OLLAMA_KEEP_ALIVE: 5m0s)。 如果你 5 分钟内没有发起新的对话,它就会自动将显存释放清空,把空间还给系统。这种机制保证了你连续对话时的“毫秒级热启动”。
本文基于实机折腾总结,希望能帮到同样在使用 AMD 迷你主机折腾本地 AI 大模型的朋友们,少走弯路!