
英特尔 Panther Lake 的 12 核 Xe 集成显卡性能比 Lunar Lake 提升 50% 以上
英特尔强调,Xe3 并非基于 Celestial 架构,尽管其名称恰好与英特尔过去路线图中该代号的位置相契合。
英特尔将 Xe3 GPU 归类为 Battlemage 系列的一部分,因为该芯片向软件呈现的功能与现有的 Xe2 产品相似。因此,它将把 Panther Lake 集成 GPU 纳入 Arc B 系列的范畴。
事实上,一旦深入研究英特尔为 Xe3 强调的那些变化,你就会发现,它更多的是对现有 Battlemage 架构系列的持续改进,而非全新设计。下一次 “彻底的” 代际飞跃将出现在 Xe3P Arc GPU 上,但目前尚不清楚这些产品何时会问世,英特尔在 Panther Lake 活动中对 Xe3P 产品缄口不言。
基本组成部分
基本的 Xe3 Xe Core(以下简称 Xe3 Core)沿用了 Xe2 的基本布局:八个用于浮点和整数运算的 Xe Vector Engine,八个用于加速 AI 应用矩阵运算的 XMX Engine,以及一个光线追踪单元。英特尔表示,Xe3 的改进旨在解决两个痛点:一是更好地利用可用资源(这是 Arc GPU 的一个持续项目),二是提高架构的可扩展性,这对于构建更大、更高性能的产品至关重要。
之前的 Xe2 渲染切片最多包含四个 Xe 核心,从 Lunar Lake 的 iGPU(两个渲染切片)到 Arc B580(五个渲染切片)这样的大型图形处理器都是由此构建的。

另一方面,Xe3 渲染切片从六个 Xe 核心开始,目前已经用于制造两个 iGPU。

最引人注目的是拥有两个渲染切片、12 个 Xe3 核心的 Panther Lake SoC 最高性能版本,它将为游戏、内容创作和 AI 工作负载提供动力。

另一款是四核 Xe3 处理器,为低端 Panther Lake 产品提供图形功能。
细心的读者可能会疑惑,既然 Xe3 渲染切片初始配置有六个 Xe 核心,为什么 Panther Lake 上的 Xe3 GPU 只有四个 Xe 核心?
英特尔一直以来都对其图形引擎的规模进行精细控制(早在 Arc 时代之前就已如此),以满足各种产品需求。因此,即使 Xe3 每个渲染切片初始配置有六个 Xe 核心,其核心数量可以缩减也并不奇怪。
大大小小的改进
英特尔表示,与上一代产品相比,每个 Xe3 Xe Core 可以同时运行多达 25% 的线程——从 8 个增加到 10 个——并且该核心可以为每个线程灵活地分配每个 Xe 向量引擎寄存器文件的分区,以实现更好的利用率。
可变寄存器分配是 Xe3 架构的一项全新技术。之前的 Arc GPU 采用的是较为粗糙的线程级寄存器分配策略,这给充分利用核心可用资源带来了挑战。英特尔表示,这是 Xe3 架构的一项关键改进,并称其对性能有“显著提升”。
Xe3 的另一项重大结构性变化(至少对于 Arc 集成显卡而言)是增加了每个 Xe 核心的共享本地内存。Xe3 现在包含 256KB 的共享本地内存,高于 Lunar Lake 上的 Xe2 和 Meteor Lake 上改进的 Xe-LPG 架构的 192KB。英特尔表示,工作负载溢出共享本地内存是导致老款 Arc 集成显卡性能瓶颈的主要原因,因此增加共享本地内存容量是一种合理且相对简单的架构改进,能够显著提升性能。
值得注意的是,此次改动仅仅是将 Xe3 集成显卡的资源配置与桌面级 Xe2 产品的基本资源保持一致。Arc B580 和 B5700 的每个 Xe 核心原本就拥有 256KB 的本地内存,因此不要指望此次提升会带来性能上的飞跃。英特尔此次增加本地内存配置或许表明,Battlemage 独立显卡采用的这种架构规模是正确的,并且值得沿用到 Arc B 系列显卡架构中。
更多重大变化发生在缓存层级结构的更底层。在最大的 12 核 Xe 核心配置中,Panther Lake 的 Arc GPU 现在拥有 16MB 的共享 L2 缓存,是 Lunar Lake 八核 Xe 核心图形引擎的两倍。对于这种尺寸的 GPU 来说,这绝对是海量的 L2 缓存;相比之下,Arc B580 芯片虽然拥有比 Panther Lake 多 67% 的 Xe 核心,但 L2 缓存却只有 18MB(仅多出 12.5%)。
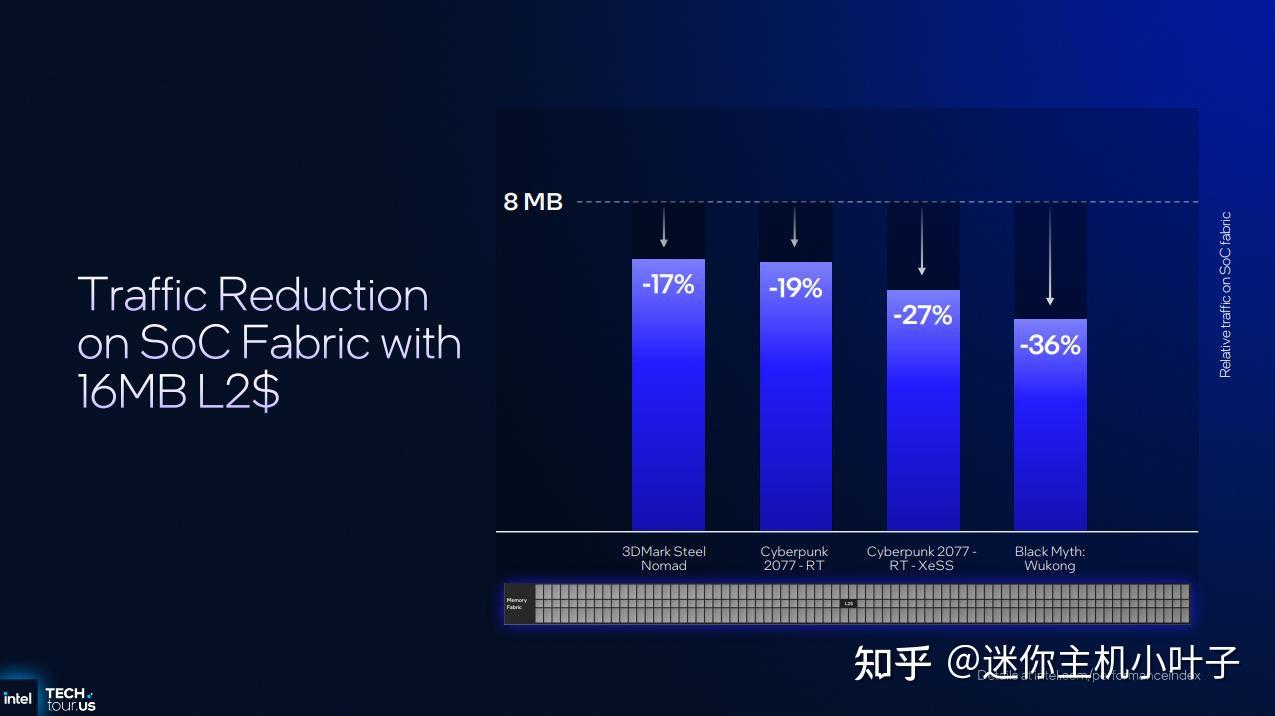
英特尔表示,更大的二级缓存可以减少 Panther Lake 芯片封装内连接图形处理器和主内存的互连架构上的流量——对于可能需要与 CPU 和 NPU 争夺内存访问权限的集成图形处理器而言,这一点至关重要。英特尔展示了一张图表,声称与以 8MB 二级缓存为基准的产品相比,互连架构流量减少了 17% 到 36%。

Xe3 还包含一些虽小但同样重要的改进。Xe2 的光线追踪引擎允许异步计算光线与三角形的交点,但这些测试结果必须按顺序处理。这项任务由线程排序单元负责,而该单元之前可能会导致光线追踪流水线出现阻塞。英特尔表示,Xe3 中改进的光线追踪引擎可以在排序单元处理完所有线程之前,动态地减慢新光线的发送速度。
英特尔还提升了名为统一返回缓冲区(URB)的缓存性能,URB 是一种在 GPU 上的各个功能单元之间传递数据的方式。该公司为 Xe3 URB 配备了一个新的管理代理,该代理可以对该缓冲区进行部分更新,而无需在每次上下文切换时都进行完全刷新,从而降低了跨功能单元通信的成本。
Xe3 还对固定功能硬件进行了改进,以提升某些常见图形任务的性能。该公司表示,各向异性过滤速率和模板测试速率预计分别可提升至两倍。
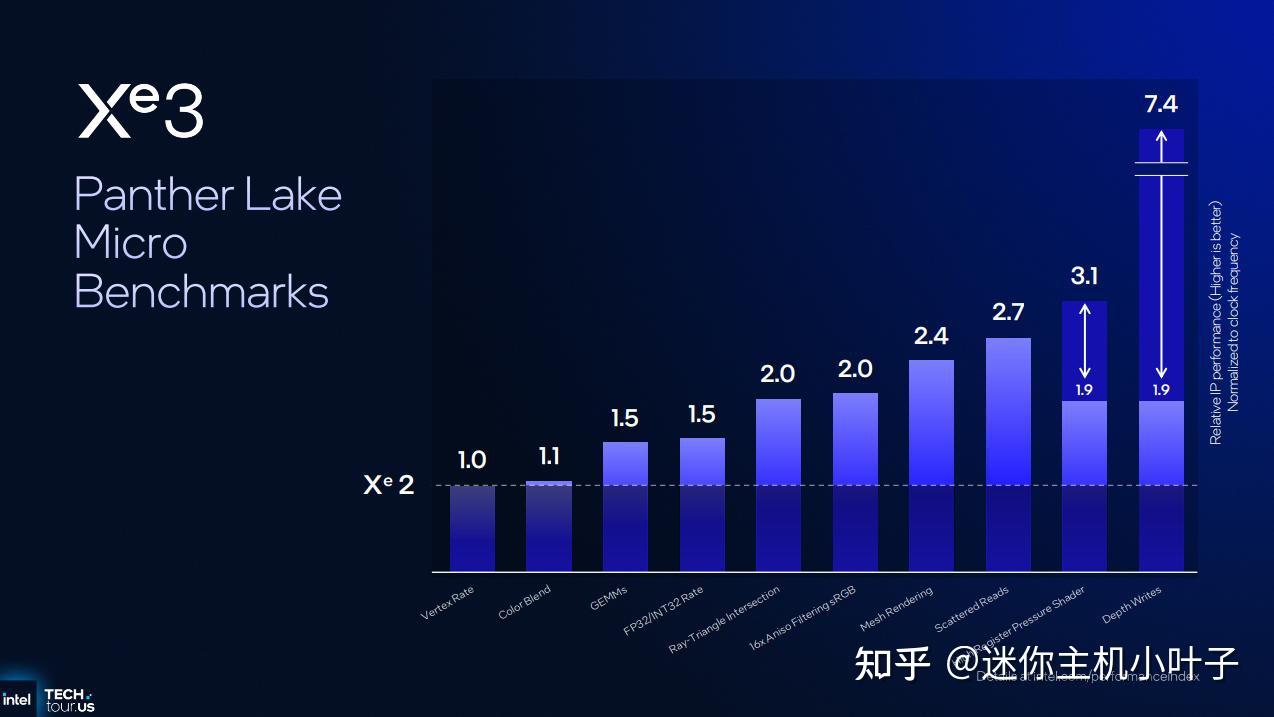
在针对 Lunar Lake 上的 Xe2 GPU 进行的一系列专有微架构基准测试中,我们可以看到,在某些运算中,12 核 Xe3 GPU 的性能在 Xe2 和 Xe3 之间并没有变化,这仅仅是因为每个渲染切片的可用资源并没有增加。英特尔则证明,其他一些运算的性能随着 Xe 核心数量从 Lunar Lake 增加到 Panther Lake 的 12 核配置而呈线性增长。
诸如光线三角形相交测试、各向异性过滤、网格渲染和从内存中分散读取等操作,开始在 Xe3 中展现出微架构和扩展性的改进;与 Xe2 相比,所有这些操作的速度都提高了 2 倍或更多。
对于占用大量寄存器的着色器,Xe3 的动态寄存器分配技术在英特尔内部微基准测试中可带来 1.9 倍到 3.1 倍的性能提升。深度测试操作——现代渲染管线中极其重要且基础的组成部分——速度提升幅度更是高达 1.9 倍到惊人的 7.4 倍。
英特尔目前还没有公布 Xe3 GPU 的详细规格,例如时钟速度,但该公司确实提供了一组大致的功耗与性能图表,这在早期芯片预览中很常见。
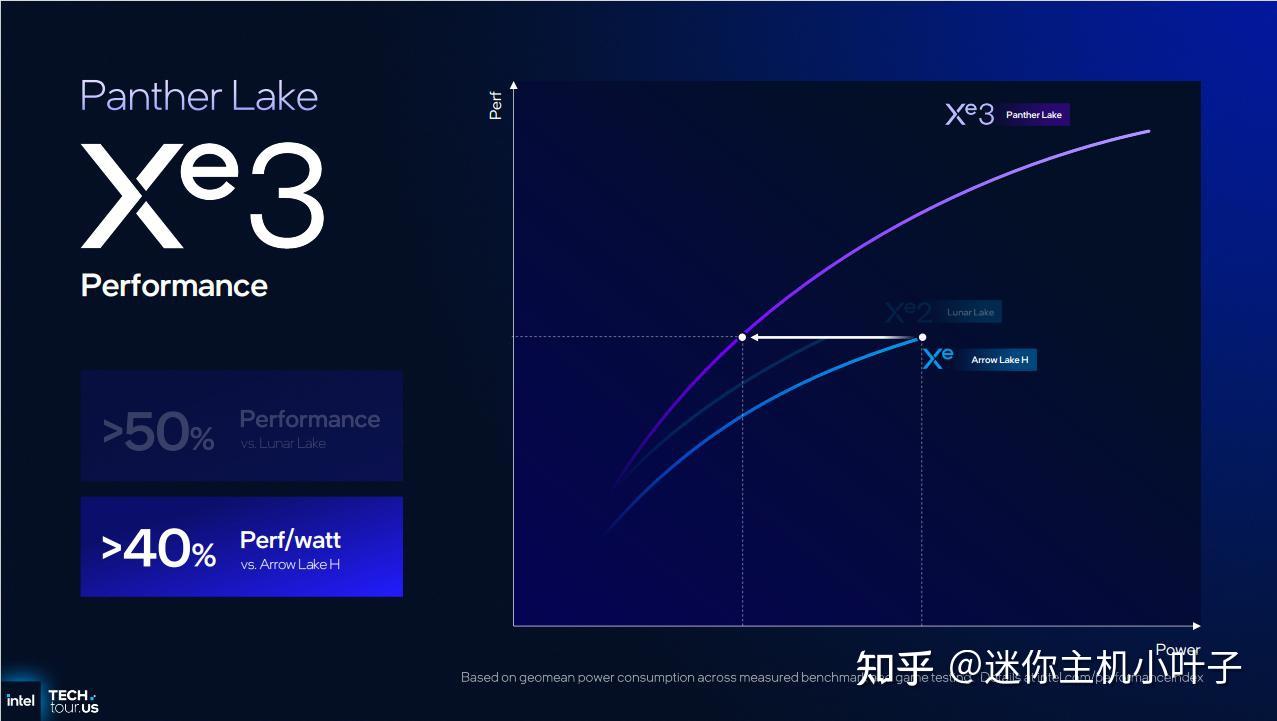
第一项数据表明,12核Xe架构GPU的性能扩展范围比Lunar Lake更广。如果给予Lunar Lake更高的功耗,12核Xe架构Arc GPU的性能可以提升50%甚至更多。如果我们在图表中比较与Lunar Lake相同的功耗水平,性能提升则要小得多,但仍然存在。
在讨论每瓦性能提升时,英特尔反而将目光投向了Arrow Lake-H集成显卡,声称其在相同性能下能效提升超过40%。我们当然希望Panther Lake在这场对比中能够带来每瓦性能的提升,因为Arrow Lake-H集成显卡基于老旧的Xe-LPG架构,该架构最早出现在近两年前的Meteor Lake处理器中,其前身则是三年前的Alchemist架构。
如果直接比较 Panther Lake 和 Lunar Lake 的能效,Xe3 仍然能提供更高的每瓦性能,但提升幅度较小(目测可能不到 20%)。暂且不论比较的相关性,我们应该关注的是,Lunar Lake 的集成显卡(至少在其 12 核 Xe 版本中)相比该公司以往的集成显卡,不仅在每瓦性能方面有所提升,而且在性能扩展性方面也更胜一筹。
然而,令人印象深刻的是,这些改进全部源于架构优化。英特尔表示,其用于制造GPU芯片的工艺技术并未改变(据推测是指与Arrow Lake相比),因此,功耗和性能的提升完全来自上述架构改进。
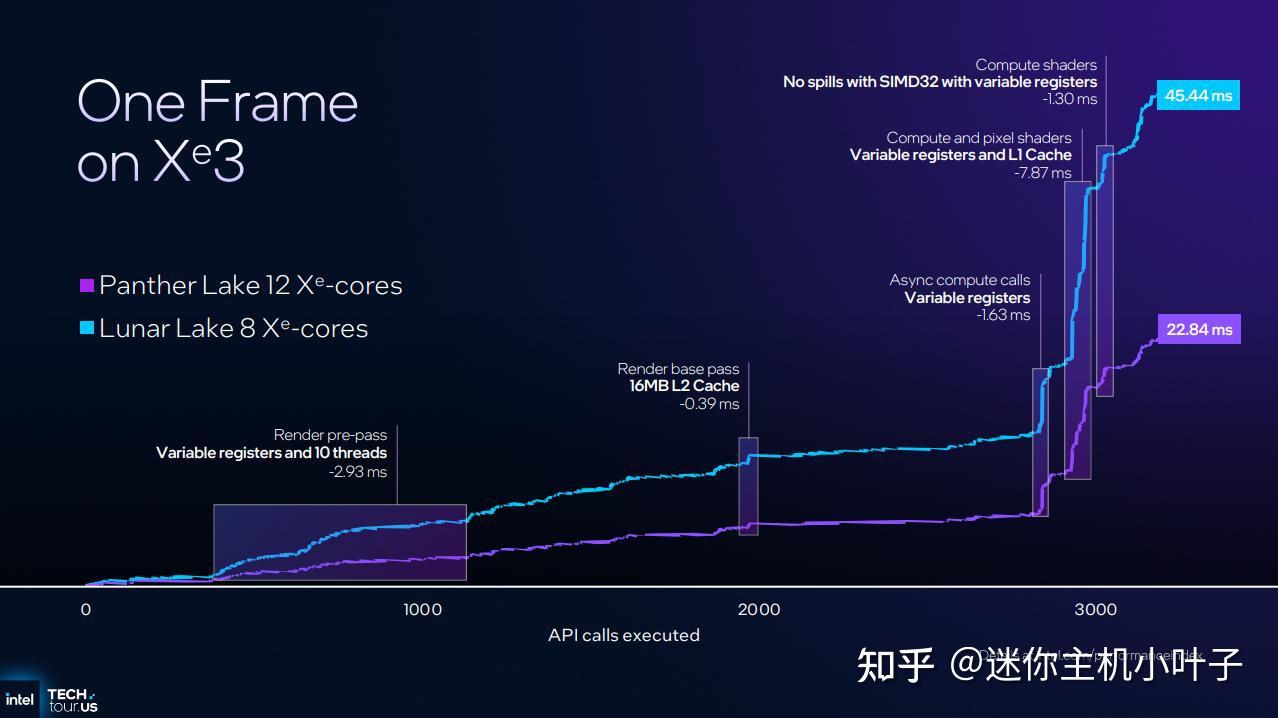
英特尔展示 Xe3 性能的另一种方式是,分别测试 Lunar Lake 和 Panther Lake 处理器渲染一帧画面所需的时间。任何图形性能爱好者都知道,平均帧时间越短,帧速率就越高。虽然单帧渲染作为基准测试意义不大,但英特尔通过帧时间测试展现了 Xe3 微架构改进带来的几项关键提升。总体而言,在 12 核 Xe3 GPU 上渲染同一帧画面仅需 22.84 毫秒,比 Lunar Lake 快了 50%。
亲身体验 Xe 多帧生成
当然,如今的GPU不仅仅是一颗芯片,它是整个软硬件堆栈的一部分。英特尔正持续投资其XeSS技术套件,以跟上英伟达和AMD的步伐。除了XeSS 2中的图像放大和2倍帧生成支持外,即将发布的XeSS版本还将为英特尔的技术库增添AI加速的多帧生成功能。
与英伟达的DLSS多帧生成技术类似,XeSS MFG将提供2倍、3倍和4倍模式(分别生成一帧、两帧或三帧)。此外,它无需游戏开发者更新其XeSS 2游戏以明确支持该功能。
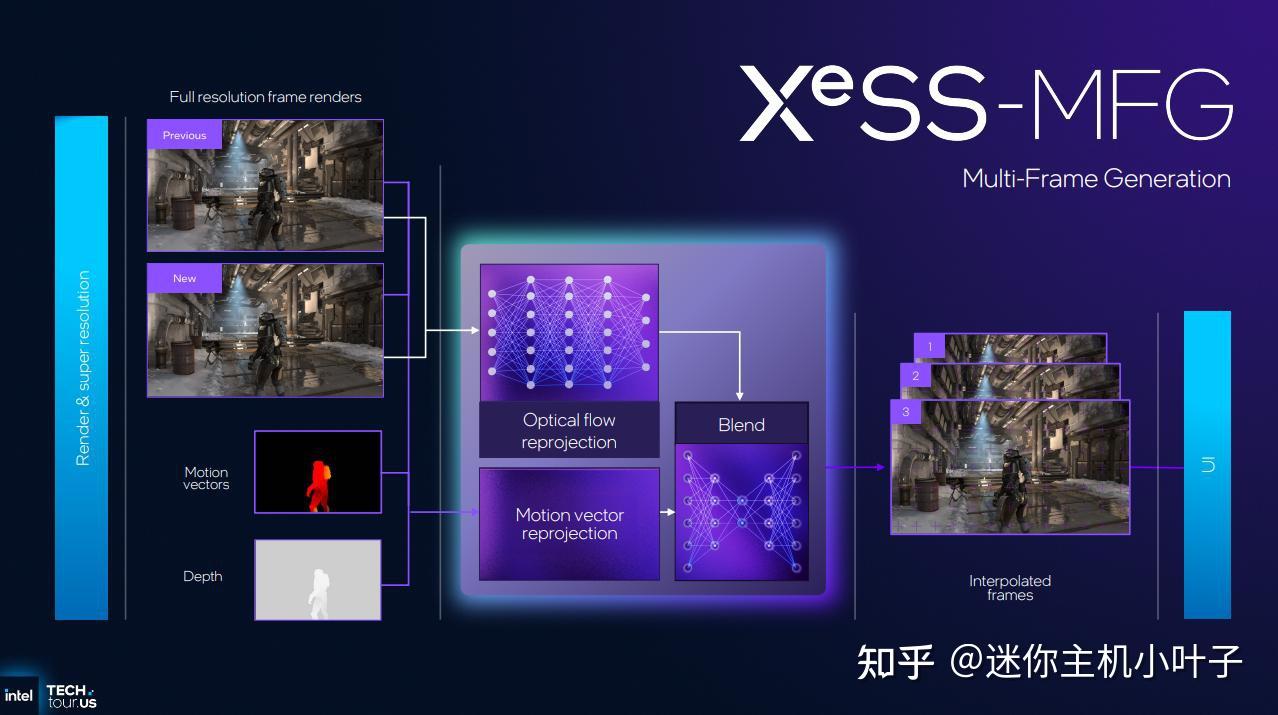
任何已支持 Xe Frame Generation 的(少数)游戏都可以通过在 Intel 图形软件控制面板中进行覆盖设置来与 XeSS MFG 配合使用。
在技术巡回活动中,我们有机会在一台搭载 Panther Lake 处理器的工程系统上亲身体验了 XeSS 多帧生成技术。根据我有限的体验时间,XeMFG 的图像质量令人印象深刻。我没有发现任何会暴露帧生成器提升帧率的干扰性伪影。
然而,对于像即将推出的《Painkiller》这样快节奏的射击游戏来说,输入延迟还是有点超出了可接受的范围,无法带来良好的游戏体验。不过,我相信我可以通过调整画面放大和画质设置来获得更流畅的游戏体验。
我对英特尔使用基准帧率作为 XeMFG 可接受输入延迟的替代指标感到有些失望。我们已经进行了一些高层次的测试,证明这两种测量方法并不一定相关,而且英特尔的代表提出的基准帧率在我看来低得离谱,根本无法保证良好的帧生成体验。
我们需要观察 PresentMon 与 XeMFG 的交互情况,以确定它是否能够可靠地衡量游戏的输入延迟以及是否适合在给定的 Arc 图形平台上与 XeMFG 一起使用。
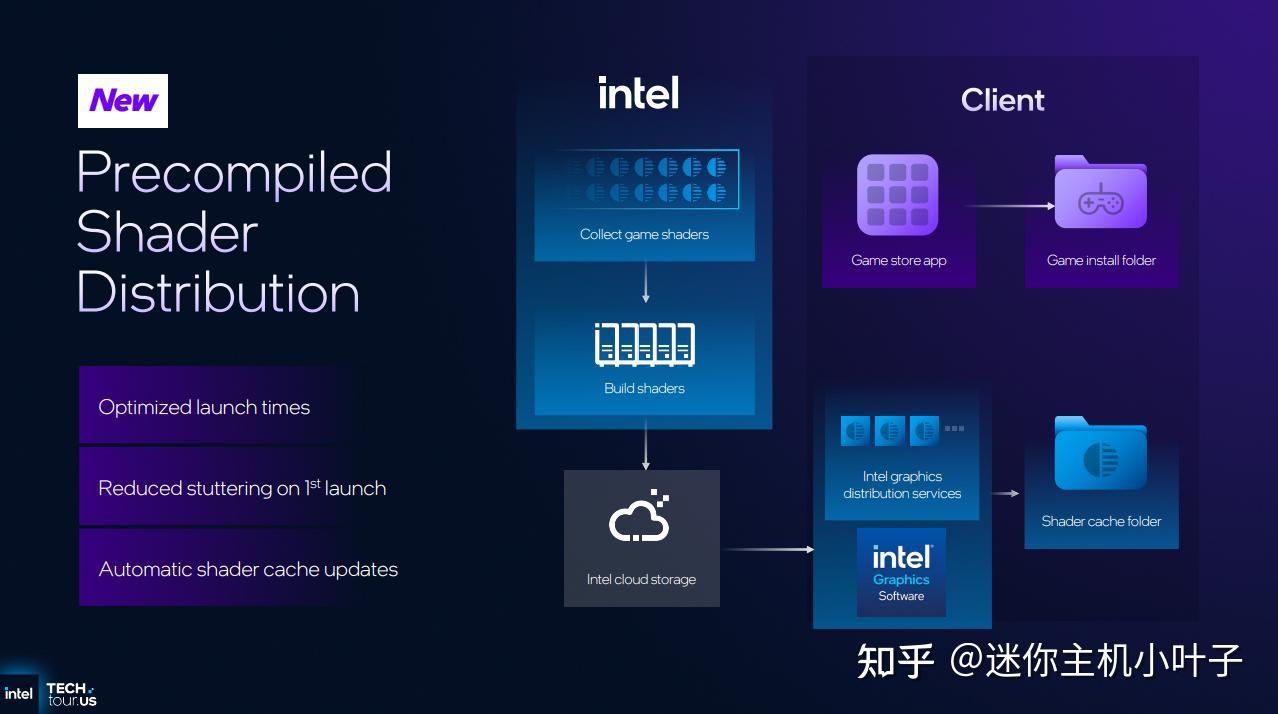
为了提高游戏加载速度和游戏流畅度,英特尔还计划开始通过英特尔图形软件实用程序,从云端向用户系统上已安装的兼容游戏分发预编译着色器。
任何玩过现代3A大作的人都知道,加载时间过长以及着色器首次编译时游戏画面卡顿的痛苦。英特尔似乎认为,投入云资源彻底解决这个问题是一项值得的投资。这虽然算不上颠覆性的变革,但对于Arc图形产品的用户来说,却是一项简单便捷的福利。
总体而言,我们对Xe3以及Panther Lake上更大的12核Xe3 GPU的初步体验令人鼓舞。至少目前来看,尽管英特尔最近与英伟达达成了一项意义重大的协议,但它仍然致力于Arc图形技术。