如何评价小米mimo-V2.5 系列模型5月27日大降价?
早上起来后发现,身边的几个群里都在聊小米Mimo-V2.5系列大模型的大降价,而且不只降价,还把这个月大家用的返还给了用户,进行了一波重置,真的是“业界良心”。
AI发展到现在,已经逐渐从AI时代,进化成AI Agent时代了,如果你对大模型的时候,还只停留在和大模型对话的时代,那该转换一下思路了。
现在大家对于AI的使用,更多的是在Agent这块,如果你已经用上了Claude Code,或者Codex,那应该能体会到这一转变。

小米MiMo大模型的主要优势,不在于AI推理方面,而在于Agent执行方面,执行任务的成功率还是很高的,这使得很多日常消耗Token很多的资深用户,都对小米MiMo的慷慨和降价,非常开心。
有了量大管饱的Token,日常可以做的事情就更多了。消耗起来也不需要精打细算了,这真的是极好的。
这波新的调价,力度相当之大。最高降幅可达 99%,并且不再区分输入长度;Token Plan 也做了计费体系优化,用量提升到原来的 5 至 8 倍,现有有效期内 Token Plan 用户额度还会全量重置。
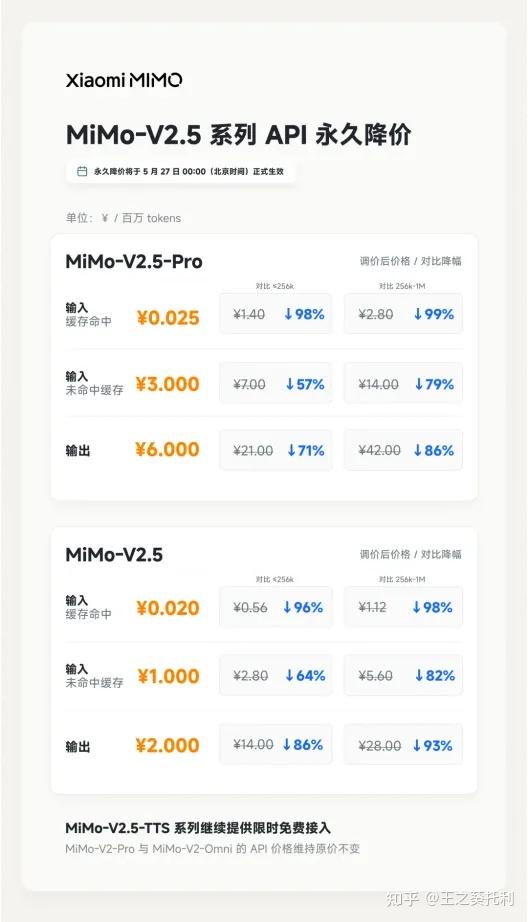
之所以小米能够进行如此大幅度的降价,背后的原因可能与以下几方面有关:
一是推理成本降下来了。大模型 API 的价格,本质上取决于单位 Token 的推理成本。
小米官方提到,这次降价背后有推理系统优化:基于 SGLang HiCache 完整支持 SWA,把 KV Cache 在 GPU 显存、CPU 内存、SSD 等多级存储之间的数据搬运量降低到优化前的近七分之一,并把可缓存 Token 数量提升到优化前的近五倍,从而提升缓存命中率和推理效率。同时,小米还优化了专家并行方案、输入长度分桶策略,提升集群输入吞吐能力。
说人话,就是通过对缓存体系和集群调度得优化,使得同样的算力可以服务更多 Token,单位成本自然下降,在成本降低后,小米将价格也降下来了。
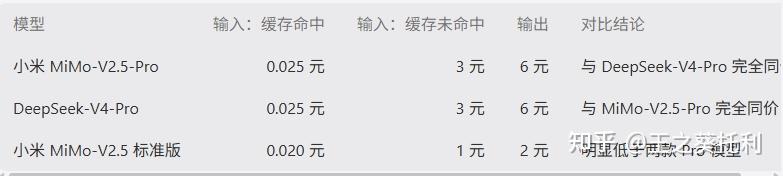
和DeepSeek V4 Pro对比,MiMo-V2.5-Pro 和 DeepSeek-V4-Pro 的 API 价格几乎打平:缓存命中输入都是 0.025 元/百万 Tokens,未命中输入都是 3 元/百万 Tokens,输出都是 6 元/百万 Tokens;但小米标准版 MiMo-V2.5 更便宜。
二是目前的大模型已经进入到了“能力接近、价格敏感”的阶段。早期模型竞争主要比谁更聪明,谁的 benchmark 更高;但当开源模型、国产模型、闭源 API 的能力差距逐渐缩小之后,开发者会越来越现实:同样完成一个 Agent 任务,谁更稳、谁更便宜、谁更容易接入,谁就更有机会被默认使用。
这也是为什么 Token 价格变得非常关键。对普通聊天场景来说,Token 成本可能只是几分钱、几毛钱的问题;但对 Agent、代码生成、企业流程自动化、长文档分析来说,一个任务消耗几十万甚至上百万 Token 并不夸张。一个模型贵一点,在单次调用上看不明显;一旦进入高频调用、自动化调用、批量处理场景,成本差距就会被指数级放大。
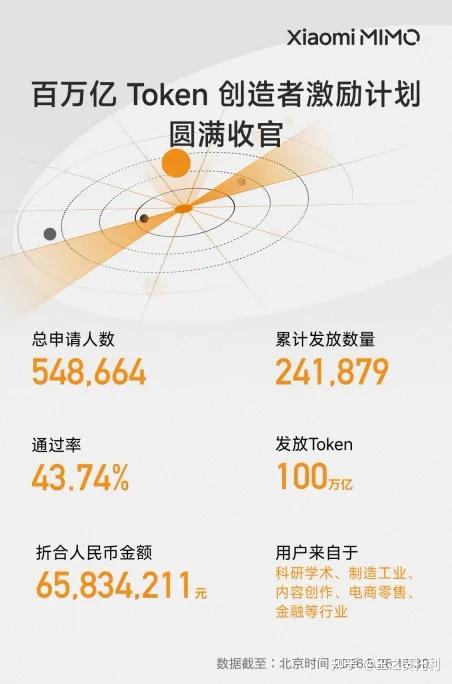
三是小米希望打造AI生态。MiMo-V2.5 系列此前已经走了开源、公测、Token 激励计划、Agent 生态合作等路线。通过让更多开发者使用小米MiMo大模型,形成小米MiMo的口碑。目前来看,小米前期的激励计划,确实给小米带来了很多资深用户。
这次新模型降价后,身边很多申请到小米MiMo的免费Token的朋友,都主动推荐大家使用,说明效果也很不错。
对一个后来进入大模型平台竞争的公司来说,最难的不是发布模型,而是让开发者把它放进真实项目里。
而小米MiMo在大模型方面,做的非常出色,每一步行动都很有效,很到位。小米这么卷,可能会逐渐抢走那些依靠模型性价比高的企业的生态位。
Token 价格正在变成 AI 时代的“电价”。
工业时代,电价决定了很多工业生产是否能规模化;
互联网时代,带宽和云服务器价格决定了很多应用能不能跑起来;
AI 时代,Token 价格决定了智能应用能不能从 Demo 变成日常基础设施。
无论是对于开发者,还是普通人,当你需要AI帮你执行任务时,你就需要Token,当你每天的Token消耗量起来后,你就需要便宜的,性价比高的Token。
而降价后的小米MiMo,是目前非常好的选择,大家如果日常对Token消耗比较大的话,可以考虑充一波小米MiMo,长期使用能够省不少钱[1]。
以上,邀请码见文末,试用后可获得10块钱体验金,感兴趣的可以试一下,以及该学Codex和Claude Code了~
